HNSW
HNSW
解决的问题:做高效率相似性查找。推荐系统中,如何找到与用户query最相近的几个item,然后推荐出去。
解决方法有:Annoy,KD-Tree, LSH, PQ,NSW, HNSW等。
近似最近邻搜索算法(Approximate Nearest Neighbor Search,ANNS)发展:
近邻图(Proximity Graph)--> NSW --> Skip List --> HNSW
1. 近邻图(Proximity Graph)
近邻图(Proximity Graph): 最朴素的图算法
思路: 构建一张图, 每一个顶点连接着最近的 N 个顶点。 Target (红点)是待查询的向量。在搜索时, 选择任意一个顶点出发。 首先遍历它的友节点, 找到距离与 Target 最近的某一节点, 将其设置为起始节点, 再从它的友节点出发进行遍历, 反复迭代, 不断逼近, 最后找到与 Target 距离最近的节点时搜索结束。
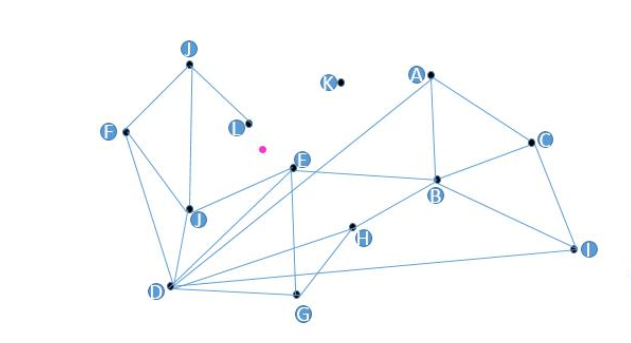
存在的问题:
- 图中的K点无法被查询到。
- 如果要查找距离Target (红点)最近的topK个点, 而如果点之间无连线, 将影响查找效率。
- D点有这么多友节点吗? 增加了构造复杂度。谁是谁的友节点如何确定?
- 如果初始点选择地不好(比如很远),将进行多步查找。
2. NSW算法原理
NSW,即没有分层的可导航小世界的结构(Navigable-Small-World-Graph )。
针对上面的问题,解决办法:
- 某些点无法被查询到 -> 规定构图时所有节点必须有友节点。
- 相似点不相邻的问题 -> 规定构图时所有距离相近到一定程度的节点必须互为友节点。
- 关于某些点有过多友节点的总是 -> 规定限制每个节点的友节点数量。
- 初始点选择地很远 -> 增加高速公路机制。
2.1 NSW构图算法
图中插入新节点时,通过随机存在的一个节点出发查找到距离新节点最近的m个节点(规定最多m个友节点,m由用户设置),连接新节点到这最近的m个节点。节点的友节点在新的节点插入的过程中会不断地被更新。
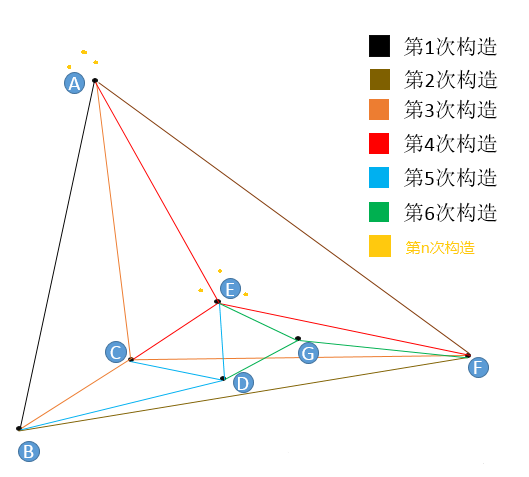
m=3(每个点在插入时找3个紧邻友点)。
第1次构造:图为空,随机插入A,初始点为A。图中只有A,故无法挑选友节点。插入B,B点只有A点可选,所以连接BA。
第2次构造:插入F,F只有A和B可以选,所以连接FA,FB。
第3次构造:插入C,C点只有A,B,F可选,连接CA,CB,CF。
第4次构造:插入E,从A,B,C,F任意一点出发,计算出发点与E的距离和出发点的所有“友节点”和E的距离,选出最近的一点作为新的出发点,如果选出的点就是出发点本身,那么看我们的m等于几,如果不够数,就继续找第二近的点或者第三近的点,本着不找重复点的原则,直到找到3个近点为止。找到了E的三个近点,连接EA,EC,EF。
第5次构造:插入D,与E点的插入一模一样,都是在“现成”的图中查找到3个最近的节点作为“友节点”,并做连接。
第6次构造:插入G,与E点的插入一模一样,都是在“现成”的图中查找到3个最近的节点作为“友节点”,并做连接。
在图构建的早期,很有可能构建出“高速公路”。
第n次构造:在这个图的基础上再插入6个点,这6个点有3个和E很近,有3个和A很近,那么距离E最近的3个点中没有A,距离A最近的3个点中也没有E,但因为A和E是构图早期添加的点,A和E有了连线,我们管这种连线叫“高速公路”,在查找时可以提高查找效率(当进入点为E,待查找距离A很近时,我们可以通过AE连线从E直接到达A,而不是一小步一小步分多次跳转到A)。
结论:一个点,越早插入就越容易形成与之相关的“高速公路”连接,越晚插入就越难形成与之相关的“高速公路”连接。
这个算法设计的妙处就在于扔掉德劳内三角构图法,改用“无脑添加”(NSW朴素插入算法),降低了构图算法时间复杂度的同时还带来了数量有限的“高速公路”,加速了查找。
2.2 NSW查找算法
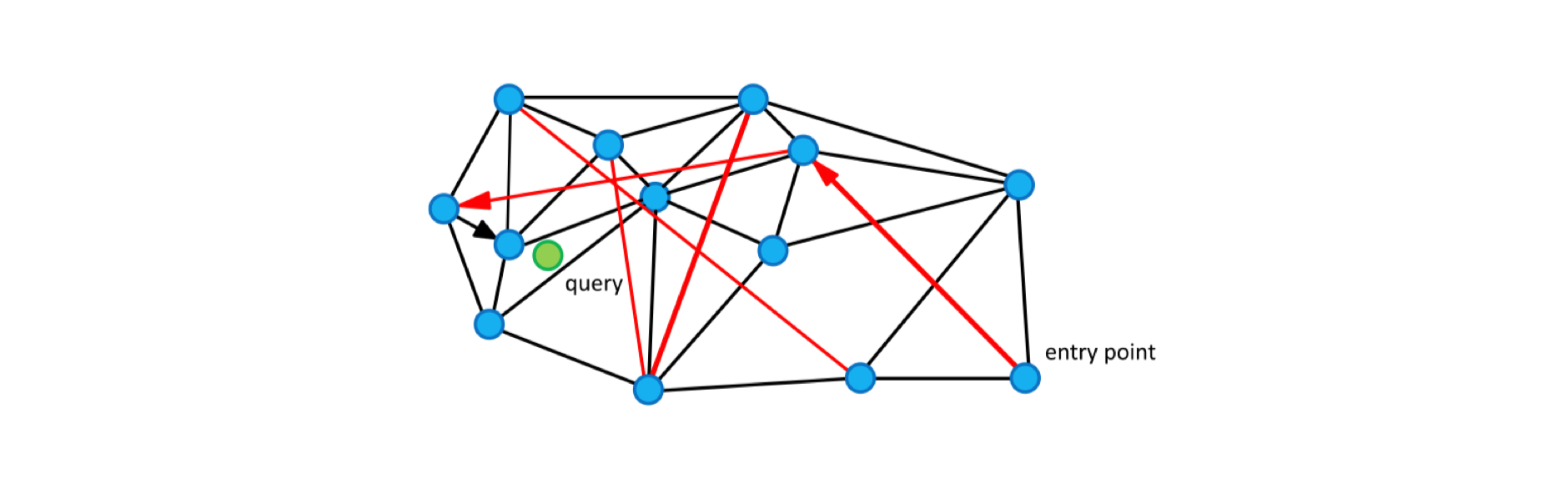
图中的边有两个不同的目的:
- Short-range edges,用作贪婪搜索算法所需的近似 Delaunay 图。
- Long-range edges,用于贪婪搜索的对数缩放。负责构造图形的可导航小世界(NSW)属性。
优化查找:
- 建立一个废弃列表visitedSet,在一次查找任务中遍历过的点不再遍历。
- 建立一个动态列表result,把距离查找点最近的n个点存储在表中,并行地对这n个点进行同时计算“友节点”和待查找点的距离,在这些“友节点”中选择n个点与动态列表中的n个点进行并集操作,在并集中选出n个最近的友点,更新动态列表。
NSW 中的贪婪搜索算法
- 算法计算从查询 q 到当前顶点的朋友列表的每个顶点的距离,然后选择具有最小距离的顶点。
- 如果查询与所选顶点之间的距离小于查询与当前元素之间的距离,则算法移动到所选顶点,并且它变为新的当前顶点。
- 算法在达到局部最小值时停止:一个顶点,其朋友列表不包含比顶点本身更接近查询的顶点。
Greedy_Search(object q, object: v_entry_point)
v_curr ← v_entry_point;
δ_min ← δ(q, v_curr); v_next ← NIL;
for each v_friend ∈ v_curr.getFriends() do:
δ_fr ← d(q, v_friend)
if δ_fr < δ_min then
δ_min ← δ_fr;
v_next ← v_friend;
if v_next == NIL then return v_curr;
else return Greedy_Search(q, v_next);
NSW中的K-NNSearch算法
假设待查询的q点的k个最近邻点。
- 随机选择一个点作为初始进入点entry point,建立空的废弃列表visitedSet和动态列表result(定长为s的列表(s>k)),将初始点放入result,准备result的影子列表tempRes(即备份result)。
- 对result中的所有点找出其“友节点”,查看这些“友节点”是否存储在visitedSet中,如果存在,则丢弃,如不存在,将这些剩余“友节点”记录在visitedSet中(以免后续重复查找,走冤枉路)。
- 并行计算这些剩余“友节点”距离待查找点q的距离,将这些点及其各自的距离信息放入result。
- 对动态列表result去重,然后按距离排序(升序),储存前s个点及其距离信息。
- 查看动态列表result和tempRes是否一样,如果一样,结束本次查找,返回动态列表中前k个结果。如果不一样,将tempRes的内容更新为result的内容,执行第2步。
K-NNSearch(object q, integer: m, k)
TreeSet [object] tempRes, candidates, visitedSet, result
/*
输入:
q: 新查询点
m: number of multi-searches, 多次搜索的数量
k: number of nearest neighbors, 最近邻的数量
*/
// 进行m次循环,避免随机性
for (i←0; i < m; i++) do:
put random entry point in candidates
tempRes←null
repeat:
// 利用上述提到的贪婪搜索算法找到距离q最近的点c
get element c closest from candidates to q
remove c from candidates
// 判断结束条件
if c is further than k-th element from result then
break repeat
// 更新后选择列表
for every element e from friends of c do:
if e is not in visitedSet then
add e to visitedSet, candidates, tempRes
end repeat
// 汇总结果
add objects from tempRes to result
end for
return best k elements from result
2.3 NSW插入算法
插入过程之前会先进行查找,所以优化查找过程就是在优化插入过程。
插入算法就是先用查找算法查找到k个与待插入点最近的点,连接它们。
Nearest_Neighbor_Insert(object q, integer: m, k)
// 查询新插入点q的k个近邻
neighbors ← K-NNSearch(object q, integer: m, k);
// 连接q与其近邻点
for (i ← 0; i < k; i++) do:
neighbors[i].connect(q);
q.connect(neighbors[i]);
3. 跳表结构
参考:https://blog.csdn.net/weixin_41462047/article/details/81253106
对一个有序链表(sorted linked list),有n个节点。从表头开始查找,查找第t(0<t<n)个节点,需要跳转几次?答案:t-1次(从1开始数)。
把n个节点分成n次查找,每个节点查找一遍,需跳转几次?答案:0+1+2+3+...+(n-1)=(n-1)(n-2)/2次。
链表查找的时间复杂度O(n),插入与删除的时间复杂度O(1)。
跳表结构:有序链表+分层连接指针构成的跳表。用空间换时间。
原始链表有n个节点,如果每两个节点抽取一个节点建立索引,第一级索引的节点数约n/2,第二级索引节点数约n/4,依次类推,第m级索引节点数约n/(2^m)。
如果有m级索引,第 m 级的结点数为两个,通过上边我们找到的规律,那么得出 n/(2^m)=2,从而求得 m=log(n)-1。如果加上原始链表,那么整个跳表的高度就是 log(n)。我们在查询跳表的时候,如果每一层都需要遍历 k 个结点,那么最终的时间复杂度就为 O(k*log(n))。
按照我们每两个结点提取一个基点建立索引的情况,我们每一级最多需要遍历两个个结点,所以 k=2。所以跳表的查询任意数据的时间复杂度为 O(log(n))。
插入:
- 新节点和各层索引节点逐一比较,确定原链表的插入位置。O(log(n))
- 把索引插入到原链表。O(1)
- 利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(log(n))
总体上,跳表插入操作的时间复杂度是O(log(n)),而这种数据结构所占空间是2n,既空间复杂度是 O(n)。
删除:
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(log(n))
- 删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(log(n))
总体上,跳表删除操作的时间复杂度是O(N)。
4. HNSW 算法原理
paper: Approximate nearest neighbor algorithm based on navigable small world graphs
paper: Skip Lists: A Probabilistic Alternative to Balanced Trees
关于HNSW的理解, 参考:
- https://www.ryanligod.com/2018/11/27/2018-11-27 HNSW 介绍/
- https://www.ryanligod.com/2018/11/29/2018-11-29 HNSW 主要算法/
- https://www.ryanligod.com/2019/07/23/2019-07-23 关于 HNSW 启发式算法的一些看法/
- https://blog.csdn.net/u011233351/article/details/85116719
- 该算法贪婪地遍历来自上层的元素,直到达到局部最小值。
- 之后,搜索切换到较低层(具有较短 link),从元素重新开始,该元素是前一层中的局部最小值,并且该过程重复。
- 通过采用层状结构,将边按特征半径进行分层,从而将 NSW 的计算复杂度由多重对数(Polylogarithmic)复杂度降到了对数(logarithmic)复杂度。
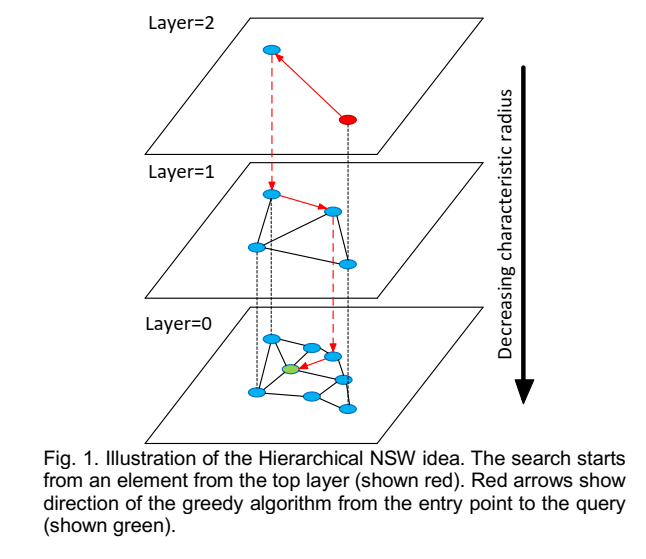
HNSW构图:插入新点时,先计算这个点可以深入到第几层,在每层的NSW图中查找t个最近邻点,分别连接它们,对每层图都进行如此操作。
对于每个插入的元素,将以指数衰减概率分布(通过\(m_L\)参数归一化)随机选择一个最大层\(l=\lfloor-ln(uniform(0,1))\cdot m_L\rfloor\)。
查找过程:
- 从顶层任意点开始查找,选择一个进入点enter point,将进入点最邻近的一些友节点储在定长的动态列表result中,并把它们也同样在废弃列表visitedSet中存一份,以防后面走冤枉路。
- 一般地,在第x次查找时,先计算动态列表result中所有点的友节点距离待查找点q的距离,在废弃列表visitedSet中记录过的友节点不要计算,计算完后更新废弃列表visitedSet,不走冤枉路,再把这些计算完的友节点存入动态列表result,去重排序,保留前k个点,看看这k个点和更新前的k个点是不是一样的,如果不是一样的,继续查找,如果是一样的,返回前m个结果。
4.1 插入算法
\(INSERT(hnsw, q, M, M_{max}, efConstruction, m_L)\):新元素q插入算法。
INSERT(hnsw, q, M, Mmax, efConstruction, mL)
/**
* 输入
* hnsw:q插入的目标图
* q:插入的新元素
* M:每个点需要与图中其他的点建立的连接数
* Mmax:最大的连接数,超过则需要进行缩减(shrink)
* efConstruction:动态候选元素集合大小
* mL:选择q的层数时用到的标准化因子
*/
Input:
multilayer graph hnsw,
new element q,
number of established connections M,
maximum number of connections for each element per layer Mmax,
size of the dynamic candidate list efConstruction,
normalization factor for level generation mL
/**
* 输出:新的hnsw图
*/
Output: update hnsw inserting element q
W ← ∅ // W:现在发现的最近邻元素集合
ep ← get enter point for hnsw
L ← level of ep
/**
* unif(0..1)是取0到1之中的随机数
* 根据mL获取新元素q的层数l
*/
l ← ⌊-ln(unif(0..1))∙mL⌋
/**
* 自顶层向q的层数l逼近搜索,一直到l+1,每层寻找当前层q最近邻的1个点
* 找到所有层中最近的一个点作为q插入到l层的入口点
*/
for lc ← L … l+1
W ← SEARCH_LAYER(q, ep, ef=1, lc)
ep ← get the nearest element from W to q
// 自l层向底层逼近搜索,每层寻找当前层q最近邻的efConstruction个点赋值到集合W
for lc ← min(L, l) … 0
W ← SEARCH_LAYER(q, ep, efConstruction, lc)
// 在W中选择q最近邻的M个点作为neighbors双向连接起来
neighbors ← SELECT_NEIGHBORS(q, W, M, lc)
add bidirectional connectionts from neighbors to q at layer lc
// 检查每个neighbors的连接数,如果大于Mmax,则需要缩减连接到最近邻的Mmax个
for each e ∈ neighbors
eConn ← neighbourhood(e) at layer lc
if │eConn│ > Mmax
eNewConn ← SELECT_NEIGHBORS(e, eConn, Mmax, lc)
set neighbourhood(e) at layer lc to eNewConn
ep ← W
if l > L
set enter point for hnsw to q
4.2 搜索当前层的最近邻
\(SEARCH\_LAYER(q, ep, ef, l_c)\):在第\(l_c\)层查找距离q最近邻的ef个元素。
SEARCH_LAYER(q, ep, ef, lc)
/**
* 输入
* q:插入的新元素
* ep:进入点 enter point
* ef:需要返回的近邻数量
* lc:层数
*/
Input:
query element q,
enter point ep,
number of nearest to q elements to return ef,
layer number lc
/**
* 输出:q的ef个最近邻
*/
Output: ef closest neighbors to q
v ← ep // v:设置访问过的元素 visited elements
C ← ep // C:设置候选元素 candidates
W ← ep // W:现在发现的最近邻元素集合
// 遍历每一个候选元素,包括遍历过程中不断加入的元素
while │C│ > 0
// 取出C中q的最近邻c
c ← extract nearest element from C to q
// 取出W中q的最远点f
f ← get furthest element from W to q
if distance(c, q) > distance(f, q)
break
/**
* 当c比f距离q更近时,则将c的每一个邻居e都进行遍历
* 如果e比w中距离q最远的f要更接近q,那就把e加入到W和候选元素C中
* 由此会不断地遍历图,直至达到局部最佳状态,c的所有邻居没有距离更近的了或者所有邻居都已经被遍历了
*/
for each e ∈ neighbourhood(c) at layer lc
if e ∉ v
v ← v ⋃ e
f ← get furthest element from W to q
if distance(e, q) < distance(f, q) or │W│ < ef
C ← C ⋃ e
W ← W ⋃ e
// 保证返回的数目不大于ef
if │W│ > ef
remove furthest element from W to q
return W
在 HNSW 中,SEARCH-LAYER(q, ep, ef, lc) 返回 efConstruction 个最近邻点,我们知道 efConstruction 的值是大于 M 的,那么怎么在这些点中选择 M 个来进行双向连接呢?这时候就有一个选择算法了。论文中提出了两种选择算法:
- 简单选择算法
SELECT-NEIGHBORS-SIMPLE(q, C, M),到最接近的elements的简单连接。 - 启发式选择算法
SELECT-NEIGHBORS-HEURISTIC(q, C, M, lc, extendCandidates, keepPrunedConnections),会考虑上candidate elements间距离,用来创建不同方
向(diverse directions)的连接。
4.3 截取集合中最近邻的M个结果
选择算法(简单选择或是启发式选择)的作用就是在集合 W 中选择 M(M<efConstruction) 个点与“新插入点”进行连接。
\(SELECT\_NEIGHBORS\_SIMPLE(q, C, M)\):在候选点集合C中选取距离q最近邻的M个元素。
SELECT_NEIGHBORS_SIMPLE(q, C, M)
/**
* 输入
* q:查询的点
* C:候选元素集合
* M:需要返回的数目
*/
Input:
base element q,
candidate elements C,
number of neighbors to return M
/**
* 输出:M个q的最近邻
*/
Output: M nearest elements to q
return M nearest elements from C to q
4.4 启发式寻找最近邻
\(SELECT\_NEIGHBORS\_HEURISTIC(q, C, M, l_c, extendCandidates, keepPrunedConnections)\):启发式寻找最近邻。
两个额外参数:
- extendCandidates:(缺省为false),它会扩展candidate set,只对极度聚集的数据有用
- keepPrunedConnections:允许每个element具有固定数目的connection
当被插入的elements的connections在zero layer被确立时,插入过程终止。
SELECT_NEIGHBORS_HEURISTIC(q, C, M, lc, extendCandidates, keepPrunedConnections)
/**
* 输入
* q:查询的点
* C:候选元素集合
* M:需要返回的数目
* lc:层数
* extendCandidates:指示是否扩展候选列表的标志
* keepPrunedConnections:指示是否添加丢弃元素的标志
*/
Input:
base element q,
candidate elements C,
number of neighbors to return M,
layer number lc,
flag indicating whether or not to extend candidate list extendCandidates,
flag indicating whether or not to add discarded elements keepPrunedConnections
/**
* 输出:探索得到M个元素
*/
Output: M elements selected by the heuristic
R ← ∅ // 记录结果
W ← C // W:候选元素的队列
if extendCandidates // 通过邻居来扩充候选元素
for each e ∈ C
for each e_adj ∈ neighbourhood(e) at layer lc
if e_adj ∉ W
W ← W ⋃ e_adj
Wd ← ∅ // 丢弃的候选元素的队列
/**
* 这里是关键,他的意思就是:
* 候选元素队列不为空且结果数量少于M时,在W中选择q最近邻e
* 如果e和q的距离比e和R中的其中一个元素的距离更小,就把e加入到R中,否则就把e加入Wd(丢弃)
* 可以理解成:如果R中存在点r,使distance(q,e)<distance(q,r),则加入点e到R
*/
while │W│ > 0 and │R│ < M
e ← extract nearest element from W to q
if e is closer to q compared to any element from R
R ← R ⋃ e
else
Wd ← Wd ⋃ e
/**
* 如果设置keepPrunedConnections为true,且R不满足M个,那就在丢弃队列中挑选最近邻填满R为M个
*/
if keepPrunedConnections
while │Wd│ > 0 and │R│ < M
R ← R ⋃ extract nearest element from Wd to q
return R
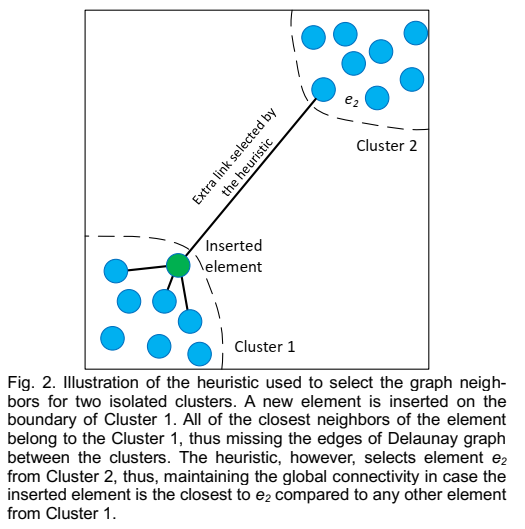
HNSW 的插入算法不是一个点一个点插入的吗,怎么会形成两个簇呢?其实论文中的图并不准确,实际上 HNSW 是可以保证图的全局连通性的。
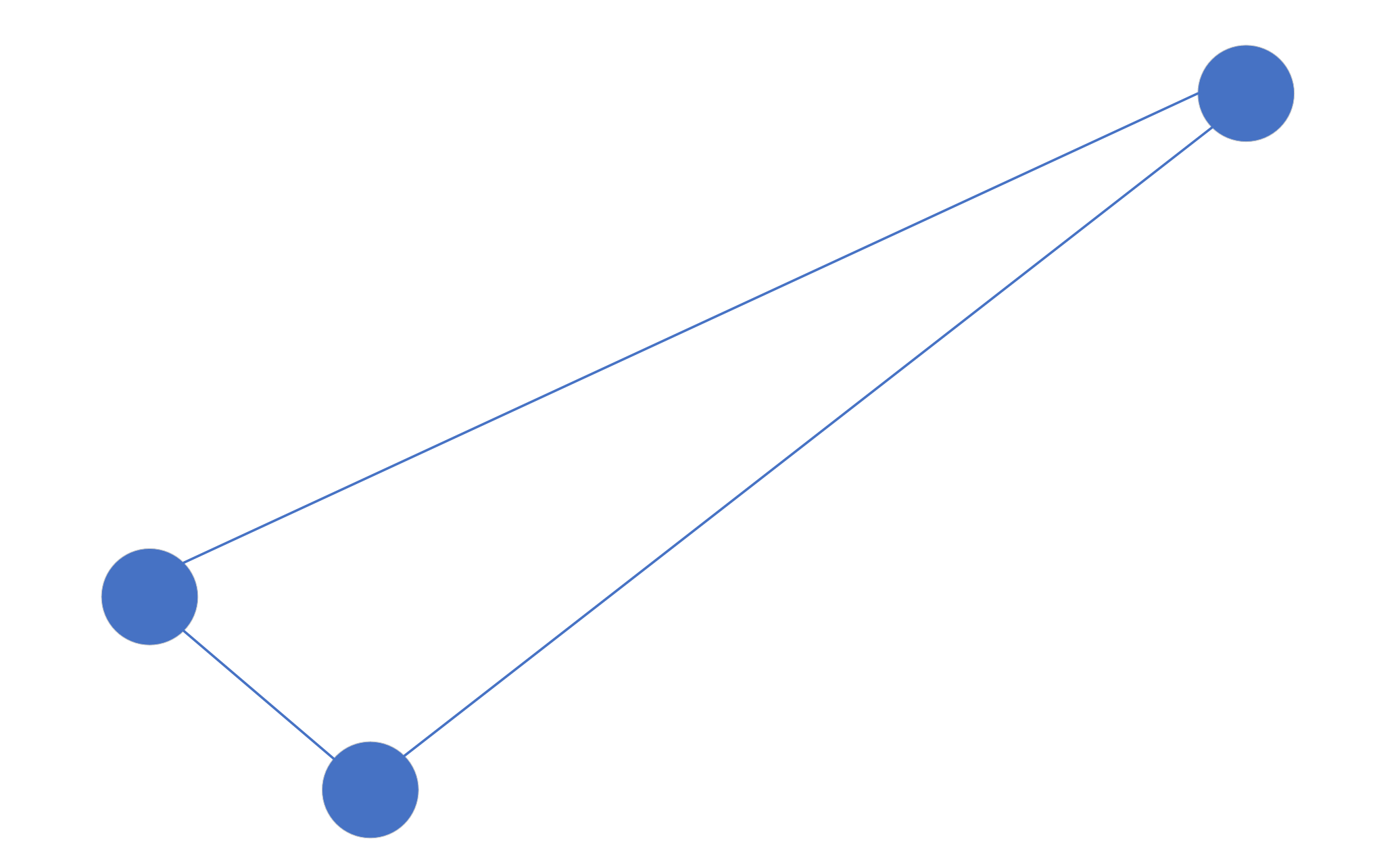
数据的前几个结点插入以后可能是这样的:
随着点的插入变多,可能变成这样:
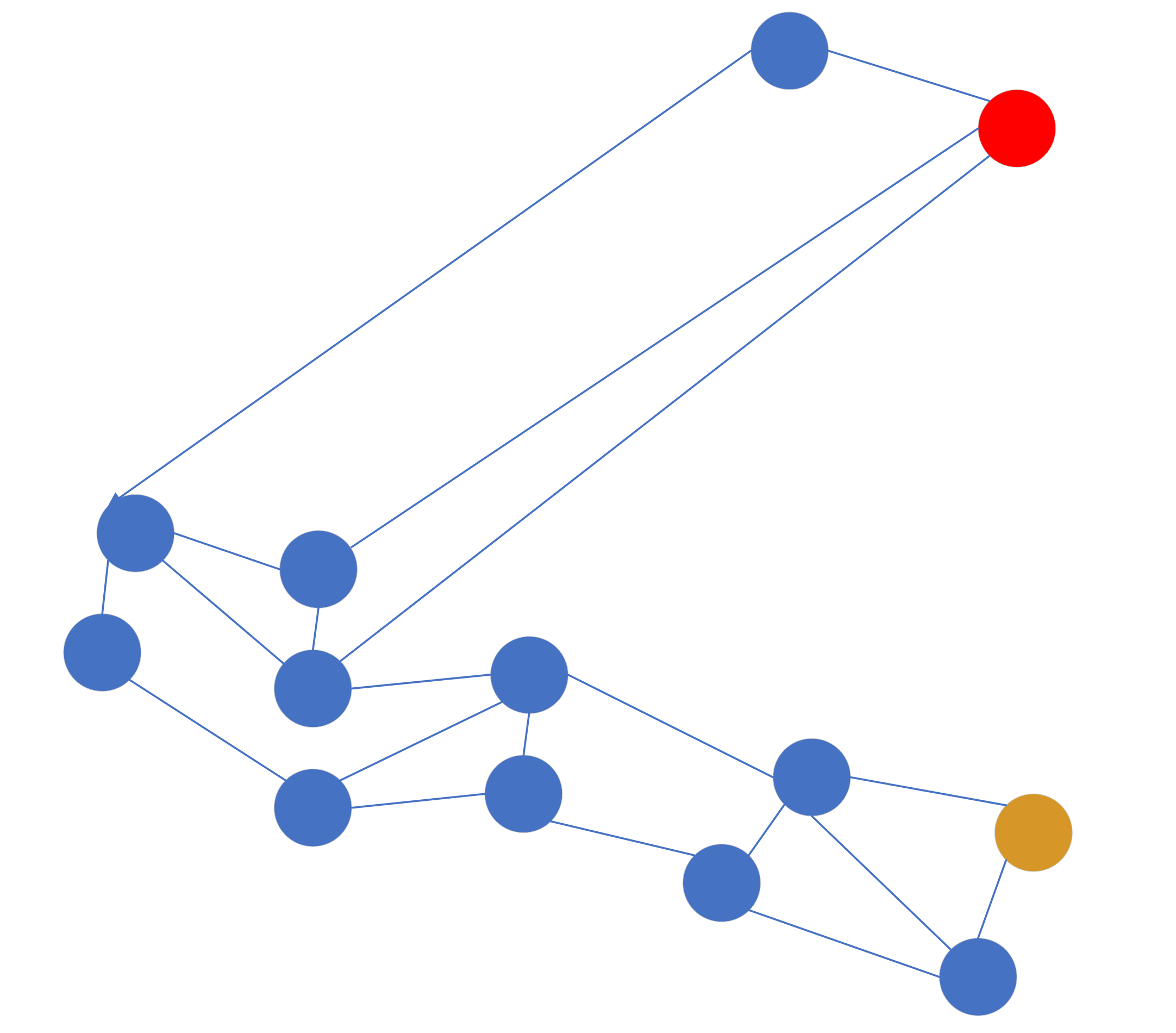
这样的图可能不是很准确,但是可以说明问题,每个点之间的间隔代表向量之间的距离。这时候假设我们的入口点是黄色点,目标查询点是红色点,那么按照贪婪算法出来的路径方向是这样的:
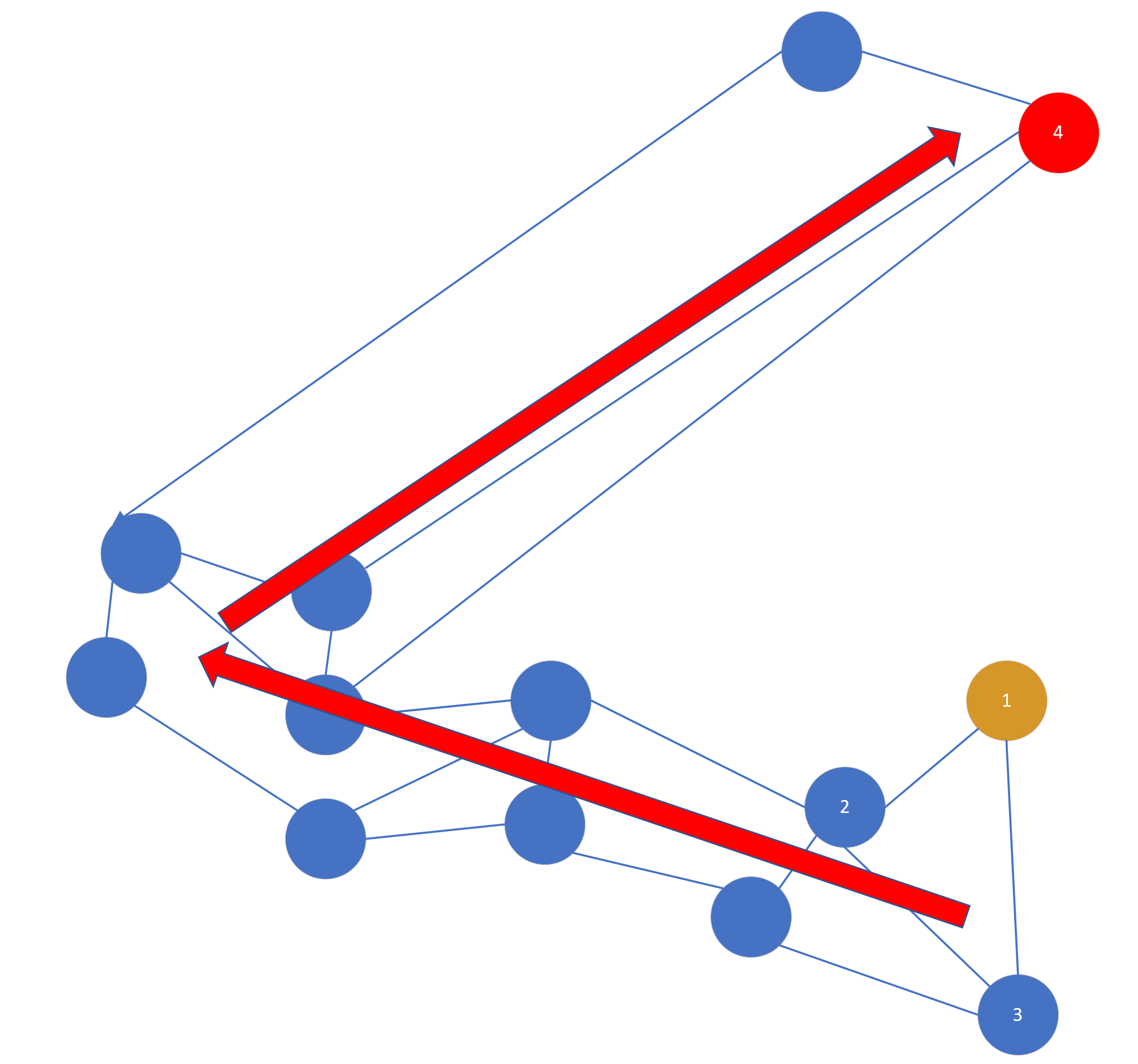
可以看到这个路径是绕了一圈的,那么怎么可以更直接地到红点所在的区域呢,如果按照简单搜索算法,明显黄点和红点距离很远,在黄点周围有很多点可以连接,是永远轮不到红点的,但是如果使用启发式选择,他的选择办法是:当目标点(红点4)和插入点(黄点1)的距离比目标点(红点4)到任意一个插入点已经连接的点(2或3)近,就把目标点(红点4)和插入点(黄点1)连接起来。这句话很绕,其实就是,如果 距离(1,4)< 距离(2,4) 或 距离(1,4)< 距离(3,4) ,就连接 1 和 4,如图所示,当然图中的 link 很随性不一定严谨。
4.5 KNN查询
\(K-NN-SEARCH(hnsw, q, K, ef)\):在 hnsw 索引中查询距离 q 最近邻的 K 个元素。
K-NN-SEARCH(hnsw, q, K, ef)
/**
* 输入
* hnsw:q插入的目标图
* q:查询元素
* K:返回的近邻数量
* ef:动态候选元素集合大小
*/
Input:
multilayer graph hnsw, query element q,
number of nearest neighbors to return K,
size of the dynamic candidate list ef
/**
* 输出:q的K个最近邻元素
*/
Output: K nearest elements to q
W ← ∅ // W:现在发现的最近邻元素集合
ep ← get enter point for hnsw
L ← level of ep
/**
* 自顶层向倒数第2层逼近搜索,每层寻找当前层q最近邻的1个点赋值到集合W
* 取W中最接近q的点作为底层的入口点,以便使搜索的时间成本最低
*/
for lc ← L … 1
W ← SEARCH_LAYER(q, ep, ef=1, lc)
ep ← get nearest element from W to q
// 从上一层得到的ep点开始搜索底层获得ef个q的最近邻
W ← SEARCH_LAYER(q, ep, ef, lc=0)
return K nearest elements from W to q
5. 算法复杂度分析
查找时间复杂度:\(O(log(n))\)
构图时间复杂度(插入所有元素):\(O(n\cdot log(n))\)
内存占用:每个元素的平均内存消耗为\((M_{max0} + m_L\cdot M_{max})\cdot bytes\_per\_link\),
\(M_{max0}\)是原始链表(第0层)每个元素的最大连接数,\(M_{max}\)是其他层每个元素的最大连接数。
6. HNSW应用工具
实现HNSW主要有两个package可选用:
- hnswlib:https://github.com/nmslib/hnswlib
- Faiss (Facebook AI Similarity Search): https://github.com/facebookresearch/faiss
相关资料:
- Faiss: Facebook AI Similarity Search
- HNSW demo: https://github.com/facebookresearch/faiss/blob/13a2d4ef8fcb4aa8b92718ef4b9cc211033e7318/benchs/bench_hnsw.py
- HNSW example demos: Visual search engine for 1M amazon products (MXNet + HNSW): website, code, demo by @ThomasDelteil

 浙公网安备 33010602011771号
浙公网安备 33010602011771号