Hive学习笔记
Hive 概述
什么是 Hive
- Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析 存储在 Hadoop 中的大规模数据的机制;
- Hive 可以将结构化的数据文件映射为一张数据库表,并定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作;
- Hive 是SQL(HQL)解析引擎,它将SQL语句转换成MapReduce Job程序,然后让程序在Hadoop上执行,并返回执行结果;
- Hive 没有专门的数据格式。它可以很好的工作在 Thrift 之上,可以控制分隔符,也允许用户指定数据格式。
- Hive的表其实就是HDFS中的目录/文件。
- Hive 优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析;
什么是数据仓库
数据仓库本质上就是一个数据库,但是它又有别于通常意义上的数据库。
数据仓库是一个面向主题的、集成的(分散数据经过加工处理满足要求后的数据集合)、不可更新的、随时间不变化的数据集合(只做查询),它用于支持企业或组织的决策分析处理。
数据仓库的结构和建立过程:

数据仓库中的数据模型:
- 星型模型(基本数据模型)
- 雪花模型(适用更复杂场景)

Hive 的适用场景
Hive 构建在基于静态批处理的 Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。
Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
OLTP(On-Line Transaction Processing)应用:联机事务处理,关注的是事物的处理,典型的OLTP应用是银行转账,一般操作频率会比较高;
OLAP(On-Line Analytical Processing)应用:联机分析处理,主要面向的是查询,典型的OLAP应用是商品推荐系统,一般不会做删除和更新,数据一般都是历史数据。
Hive 的特点
Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统例如(HDFS)。
Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到 HDFS 中 Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
- 支持索引,加快数据查询
- 支持不同的存储类型,例如,纯文本文件、HBase 中的文件。
- 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
- 可以直接使用存储在 Hadoop 文件系统中的数据。
- 内置大量用户函数 UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展 UDF 函数来完成内置函数无法实现的操作。
- 类 SQL 的查询方式,将 SQL 查询转换为 MapReduce 的 job 在Hadoop集群上执行。
Hive 的体系结构

Hive 是用 HDFS 进行数据存储,利用 MapReduce 对数据进行分析计算
Hive的元数据
- Hive将元数据存储在数据库中(MetaStore),支持mysql、derby、oracle等数据库。
- Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
HQL的执行过程
解释器、编译器、优化器完成HQL查询语句从 词法分析、语法分析、编译、优化以及查询计划(plan)的生产。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。

Hive 下载安装
下载地址:
hive.apache.org
archive.apache.org
安装准备:
- 先安装 hadoop,保证HDFS正常运行;
- 配置 ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
[root@centos hadoop-2.8.5]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> - 配置 ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> - 启动yarn服务
[root@centos hadoop-2.8.5]# sbin/start-yarn.sh

Hive安装模式
- 嵌入模式
- 元数据信息被存储在Hive自带的Derby数据库中
 - 只允许创建一个连接
同一时间只允许一个用户操作hive数据仓库中的数据(用于演示dome) - 多用于Demo
- 元数据信息被存储在Hive自带的Derby数据库中
- 本地模式
- 元数据信息被存储在MySql数据库中
- MySql数据库与Hive运行在同一台物理机器上
- 支持多个连接,多用于开发和测试
- 远程模式
- 元数据信息被存储在MySQL数据库中
- MySQL数据库与Hive 不在同一台物理机器上运行

 - 多用于实际生产运行环境
嵌入模式安装
- 上传Hive安装包至linux
- 解压安装
- 配置环境 ./base_profile
HIVE_HOME export PATH=$HIVE_HOME/bin:$PATH source ~/.base_profile - 启动
嵌入式模式下,在哪个目录下执行hive命令,就会在当前目录下生成一个metastore_db目录保存元数据信息和一个derby.log文件。
远程模式安装
-
解压安装tar包
[root@centos hadoop]# tar -zxvf apache-hive-2.3.5-bin.tar.gz -C /usr/myapp/dev/hadoop/ -
在conf目录下创建hive-site.xml文件,模板可参照hive-default.xml.template文件
-
配置hive-site.xml文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://183.6.116.12:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> </configuration> -
上传mysql驱动jar至hive解压后目录下的lib目录下
[root@centos apache-hive-2.3.5-bin]# cp /usr/myapp/dev/mysql/mysql-connector-java-8.0.17/mysql-connector-java-8.0.17.jar lib/ -
初始化元数据信息数据库
[root@centos bin]# ./schematool -initSchema -dbType mysql
出现上图内容,则初始化完成。 -
启动hive
- 单用户访问操作
[root@centos apache-hive-2.3.5-bin]# bin/hive - 多用户访问操作
# 1.启动服务 [root@centos apache-hive-2.3.5-bin]# ./bin/hiveserver2 # 2.链接服务 [root@centos apache-hive-2.3.5-bin]# ./bin/beeline -u jdbc:hive2://localhost:10000第二种启动方式如果报以下错误:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):User: root is not allowed to impersonate anonymous解决方式可尝试博文:https://blog.csdn.net/qq_43225978/article/details/97781612
在hive中创建一张表,可以在mysql的hive数据库中的tbls表中看到创建的表的元数据信息,在columns_v2表中可以看到创建的表的列元数据信息
使MySql数据库允许远程连接:
https://www.cnblogs.com/fnlingnzb-learner/p/5848405.html- 授权用户root使用密码sss512从任意主机连接到 mysql 服务器: 代码如下:
use mysql;
GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'jb51' WITH GRANT OPTION;
flush privileges;- 授权用户root使用密码root从指定 ip 为 42.157.128.206 的主机连接到mysql 服务器: 代码如下:
use mysql;
GRANT ALL PRIVILEGES ON . TO 'root'@'42.157.128.206' IDENTIFIED BYc 'root' WITH GRANT OPTION;
flush privileges;- 使用“select host,user from user;”查看修改是否成功。
- 单用户访问操作
本地模式安装
与远程模式相同,区别在于配置hive-site.xml文件时,将数据库的链接地址配置为本地。
Hive 的数据类型
官网释义:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
基本数据类型
- tinyint/smallint/int/bigint : 整数类型
- float/double : 浮点数类型
- boolean : 布尔类型
- string: 字符串类型
- varchar(10) (存储内容最大10字节) ,
- char(10) (存储内容一定是10字节,不满足则自动补足)
复杂数据类型
-
Array : 数组类型,由一系列相同数据类型的元素组成

数据插入格式:
-
Map : 集合类型,包含key -> value 键值对,可以通过key来访问元素

数据插入格式:
-
Struct : 结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素

数据插入格式:{1,{'张三',35,'男'}}
数组类型 与 集合类型 联合:

数据插入格式:
时间类型
官网释义:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types#LanguageManualTypes-timestamp
- Timestamp : 从Hive0.8.0 开始支持
- Date : 从Hive0.12.0 开始支持
- Interval(注意:仅从Hive 1.2.0开始提供)
Hive 的数据存储
- 没有专门的数据存储格式
- 创建表时,指定Hive数据的列分隔符与行分隔符
- 基于HDFS,Hive中的表对应HDFS中的目录
- 存储结构主要包括:数据库、文件、表、视图
- 可以直接加载文本文件(.txt文件等)
首先 Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
Hive的默认分隔符
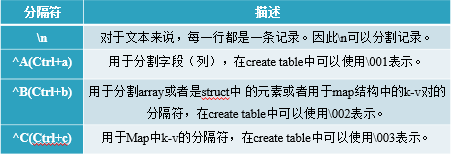
附注: 这里的
^A在VI编辑器下按住Ctrl+v ,Ctrl+a实现
其次 Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(内部表)(Table),外部表(External Table),分区表(Partition),桶表(Bucket),视图(View)。
Hive 的数据模型
数据库
1. 创建数据库
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
注意:其中
SCHEMA 和DATABASE是可以互换的(它们的含义是一样).CREATE DATABASE该语法在Hive 0.6被引入 .WITH DBPROPERTIES在Hive0.7版本被引入
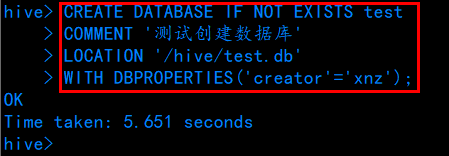
例:.
CREATE DATABASE IF NOT EXISTS test
COMMENT '测试创建数据库'
LOCATION '/hive/test.db'
WITH DBPROPERTIES('creator'='xnz');

2. 查看数据库
查看所有已存在数据库:
show databases;
语法:
(DESC|DESCRIBE) (DATABASE|SCHEMA) database_name ;
例:
DESCRIBE schema test;
或
desc database test;
3. 修改数据库
语法:
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
注意:其中
SCHEMA 和DATABASE是可以互换的(它们的含义是一样). SCHEMA 在Hive 0.14.0版本中被引入。 DATABASE其他属性均不可以被改变
例:
alter database test set owner user mysql;
或
ALTER DATABASE test SET DBPROPERTIES ('creator'='xnz1');

4. 删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
注意:其中
SCHEMA 和DATABASE是可以互换的(它们的含义是一样)。
DROP DATABASE 在Hive 0.6 被引入。
默认删除数据库是RESTRICT, 该种模式下如果删除的数据库不为空,DROP DATABASE 将会失败。
可以使用DROP DATABASE ... CASCADE实现删除表,其中 RESTRICT and CASCADE在 Hive 0.8支持该特性。
例:
# 删除数据库及表
DROP DATABASE IF EXISTS test CASCADE;
# 删除空数据库
drop database test;

5. 使用数据库
语法:
USE database_name;
USE DEFAULT;
USE为所有后续HiveQL语句设置当前数据库。
若要还原到默认数据库,请使用关键字“DEFAULT”而不是数据库名称。
要检查当前正在使用哪个数据库:选择current_database()(在Hive 0.13.0时)。
在Hive 0.6中添加了database_name。
例:
# 使用数据库
use test;
# 查看当前使用的数据库
select current_database();

表
表分类
1. Table 内部表及创建
- 与数据库中的 Table 在概念上是类似
- 在 Hive 中的每一个 Table 在HDFS中都有一个相应的目录存储数据
- 所有的 Table 数据(不包括 External Table)都保存在这个目录中,表的元数据信息存在于元信息数据库中(如:derby、mysql数据库)
- 删除表时,元数据与数据都会被删除
-
直接创建内部表
create table t1
(tid int,tname string,age int);此HQL会将这张表
默认创建至 HDFS 的/user/hive/warehouse目录下。 -
指定创建的表保存至 HDFS 中的目录位置
create table t2
(tid int,tname string,age int)
location '/user/hive/mytable/t2';此HQL会将这张表
主动创建至 HDFS 的/user/hive/mytable/t2目录下。 -
指定表数据在HDFS中以文件存储时的分隔符
create table t3
(tid int,tname string,age int)
row format delimited --- 格式分隔
fields terminated by ',' --- 字段以','结尾
collection items terminated by '|' --- 以“|”结尾的集合项
lines terminated by '\n'; --- 以“\n”结尾的行此HQL在创建这张表的同时指定表数据在 HDFS 中以文件存储时的分隔符。

如果含有map类型 则使用map keys terminated by '分隔符'限定。 -
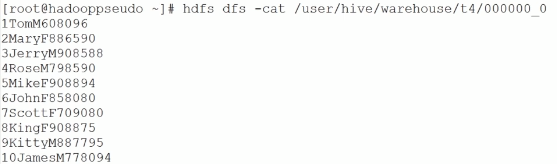
使用子查询的方式创建表
create table t4
as
select * from t_user;此HQL能够使用子查询创建表的同时将数据填入新表中。
hdfs dfs -cat /user/hive/warehouse/t4/000000_0
通过此命令可以查看t4表在HDFS文件中的内容
-
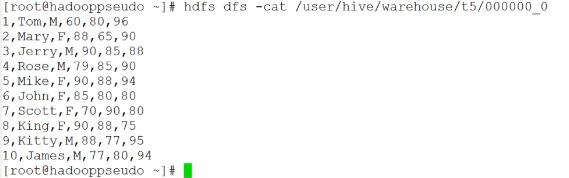
使用子查询的方式创建表,同时指定表数据在HDFS中以文件存储时列与列之间的分隔符
create table t5
row format delimited fields terminated by ',';
as
select * from t_user;此HQL能够使用子查询创建表的同时将数据填入新表中,并且指定表数据在HDFS中以文件存储时列与列之间的分隔符为“,”。
-
创建可以使用正则表达式制定数据映射规则的表
create table t_user_reg (
id int,name,
varchar(32),
sex boolean,
birth date
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex"="(^[0-9]*) ([a-z]*) (true|false) ([0-9]{4}-[0-9]{2}-[0-9]{2})"
);Hive只能解析简单的正则表达式,有特殊字符的正则表达式无法识别。
-
创建可以映射json格式数据的表
先执行以下命令,将json数据映射到hive的处理jar包添加到Hive的环境中:
hive>
ADD JAR /usr/myapp/dev/hadoop/apache-hive-2.3.5-bin/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar ;创建表:
create table t_user_json(
id int,
name varchar(32),
sex boolean,
birth date
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe';
2. Partition 分区表及创建
- Partition 对应于数据库的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。
- 在 Hive 中,分区表中的一个 Partition(分区) 对应于表下的一个分区目录,所有的 Partition(分区) 的数据都存储在对应的分区目录中。
-
查看分区
show partitions t_user; -
删除分区
alter table t_user drop partition(country='china',state='beijing');附注:对于内部表删除分区也会将数据删除,但是外部表再删除分区的时候分区的数据不会被删除。
-
添加分区
alter table t_user add partition(country='china',state='beijing');附注添加多个分区数据:
alter table t_user
add if not exists
partition(country='china',state='beijing')
location 'hive/database/baizhi.db/t_user/country=china/state=beijing' partition(country='china',state='shanghai')
location 'hive/database/baizhi.db/t_user/country=china/state=shanghai'如有表:

现在按性别进行分区。
首先创建一个分区表:create table partition_table
(sid int, sname string) -- 创建表
partitioned by (gender string) -- 指定按性别分区
row format delimited fields terminated by ','; -- 指定分隔符为 “,” 。
将 sample_data 表中的数据分区插入到分区表中:
insert into table partition_table partition(gender='M') select sid,sname from sample_data where gender='M';
insert into table partition_table partition(gender='F' ) select sid,sname from sample_data where gender='F';
执行以上两条HQL即可将 sample_data 表中数据按性别存入对应分区中,可通过HDFS的WEB管理界面查看分区目录。
export select * from partition_table where gender = ‘M’;
可以生成一条HQL的执行计划,可以对比未分区时的执行计划,可以看出分区后效率要高很多。
3. External Table 外部表及创建
-
指向已经在HDFS中存在的数据,可以创建 Partition 。
-
它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
-
外部表 只是一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅仅删除该链接。
创建三个文件 student01.txt、student02.txt、student03.txt ,并分别在三个文件中添加部分数据;
将三个文件上传到hdfs中;

创建外部表:create external table external_student
(sid int,sname string,age int)
row format delimited fields terminated by ',' -- 指定分隔符
location '/input'; -- 指定创建的表保存至HDFS中的'input'目录查询该外部表:

将hdfs上的三个文件删除一个,再查询:


将删除的文件重新上传至hdfs,再查询:


4. Bucket Table 桶表及创建
- 桶表是对数据进行哈希取值,然后放到不同文件中存储
- Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。
create table bucket_table1
(sid int,sname string,age int)
clustered by(sname) into 5 buckets; -- 指定以sname进行区分5个桶
5. 截断表
-
与delete from table效果相同
-
数据量大时删除速度比delete快
TRUNCATE TABLE table_name [PARTITION partition_spec]; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)删除表(指定分区)的数据,数据将会被移动到Trash中去。默认只可以truncate 管理表|native表,不可以对external表做截断。如果不指定 分区信息默认会将所有分区数据截断。

修改表
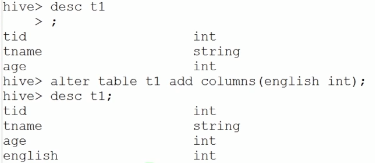
- 添加列
alter table t1 add columns(english int);
删除表
DROP TABLE [IF EXISTS] table_name [PURGE];
DROP TABLE 删除 metadata 如果配置了Trash该表的数据数据实际上移动到.Trash/Current 目录( 此时不可指定PURGE 参数). 当删除的是EXTERNAL表,系统的数据不会被删除。
其中PURGE选项是version 0.14.0添加的一个选项,如果加入了该参数,数据是不会移动到回收站的因此如果表被误删后数据是无法恢复。
drop table t1;

加载数据
-
创建本地数据文件
[root@centos ~]# vim test.txt 1^Azs^A17 2^Alisi^A18 3^Awangwu^A19使用默认的分隔符
-
上传至HDFS中
[root@centos ~]# hdfs dfs -mkdir /input [root@centos ~]# hdfs dfs -put test.txt /input/ -
加载数据到表中
hive> load data inpath 'hdfs://centos:9000/input/test.txt' into table t1;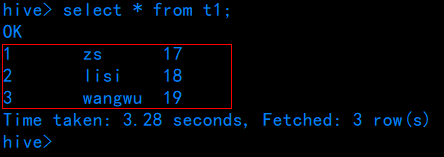
load data local(可略) inpath '/root/t_user' overwrite into table t_user;
当从本地文件加载数据时,需要local。
overwrite代表覆盖数据,如果没有这个关键词,重复执行加载数据的命令,则会将文件的内容追加到表中 -
使用hive进行统计查询
hive> select avg(age) from t1; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20190729181654_3935c1e2-29bb-47a5-a649-b26b6b86d9c6 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1564395285615_0002, Tracking URL = http://centos:8088/proxy/application_1564395285615_0002/ Kill Command = /usr/myapp/dev/hadoop/hadoop-2.8.5/bin/hadoop job -kill job_1564395285615_0002 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-07-29 18:17:06,276 Stage-1 map = 0%, reduce = 0% 2019-07-29 18:17:12,723 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.76 sec 2019-07-29 18:17:19,111 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.65 sec MapReduce Total cumulative CPU time: 3 seconds 650 msec Ended Job = job_1564395285615_0002 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.65 sec HDFS Read: 8190 HDFS Write: 104 SUCCESS Total MapReduce CPU Time Spent: 3 seconds 650 msec OK 18.0 Time taken: 26.691 seconds, Fetched: 1 row(s)
Hive SQL查询
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list] --- 分组
[ORDER BY col_list] --- 排序
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] ---分区
[LIMIT number] --- 限制返回结果条数
视图
- 视图是一种 虚表,是一个逻辑概念;可以跨越多张表
- 视图建立在已有表的基础上,视图赖以建立的这些表成为基表
- 视图可以简化复杂的查询
- 视图分为两种:
- 一种视图是不存数据的
- 一种视图可以存储数据 (即 物化视图)
--- Hive 不支持物化视图
--- Oracle 与 MySql 支持物化视图
创建视图:
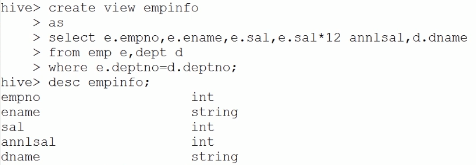
查询视图:

JAVA API操作Hive
package com.example.hivedemo;
import java.sql.*;
public class TestHive {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
String driverName = "org.apache.hive.jdbc.HiveDriver";
Class.forName(driverName);
Connection connection = DriverManager.getConnection("jdbc:hive2://42.157.128.205:10000/test","root","root");
String sql = "select avg(age) from t1";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()){
int anInt = resultSet.getInt(1);
System.out.println(anInt);
}
resultSet.close();
preparedStatement.close();
connection.close();
}
}
如果报错:
java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate anonymous
可以尝试博文:https://blog.csdn.net/qq_43225978/article/details/97781612

 浙公网安备 33010602011771号
浙公网安备 33010602011771号