

《显卡 4090 就能跑!小白也能炼出私有大模型》
一、引言:为什么大模型微调是AI落地的关键?
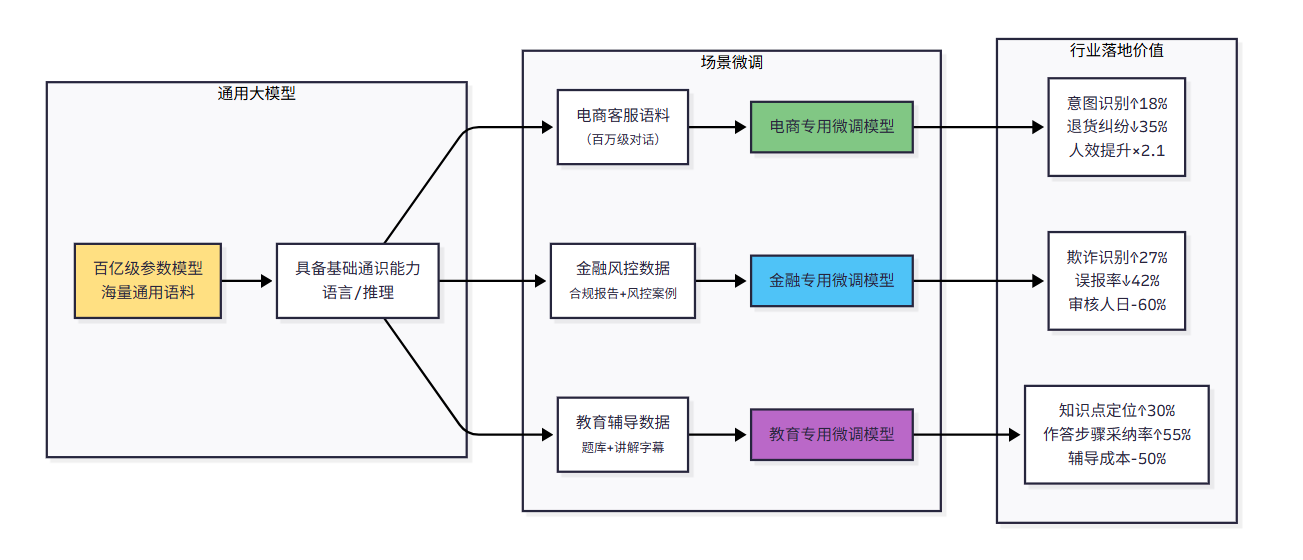
如今AI早已融入日常与工作场景——电商客服能精准响应售后咨询,法律助手可快速核查合同条款,写作助手甚至能复刻你的专属文风。但你大概率会发现,直接使用通用大模型时,“水土不服”的问题很常见:要么答非所问偏离主题,要么风格跳脱不符合需求,要么对行业专业术语一知半解。
这正是大模型微调技术的核心价值所在。若把通用大模型比作“全能学霸”,微调就相当于为这位学霸开展“专项特训”——通过针对性的训练,让它在特定领域从“会做”升级为“精通”。比如,给通用模型输入海量医疗文献,它就能转型为专业的医疗咨询助手;导入你的写作样本,它就能成为精准匹配你文风的专属文案助手。
更关键的是,微调已成为企业AI落地的核心支撑技术:电商行业用它提升客服响应效率,金融领域靠它分析财报风险点,教育行业借它定制个性化辅导方案。对于开发者而言,掌握微调技术,就等于拿到了跻身AI落地领域的“通行证”。接下来,这篇文章将从技术原理到实战操作,把大模型微调彻底讲透,让新手也能轻松上手实践。
二、技术原理:3个核心概念,搞懂微调本质
2.1 微调到底是什么?一句话讲明白
大模型微调,简单来说就是“给预训练模型做二次定向培训”。预训练模型如同刚毕业的大学生,具备扎实的通用知识储备,但缺乏特定岗位的实操经验;而微调,就是让这个“大学生”进入对应行业,通过完成针对性的工作任务(即标注数据学习),掌握特定岗位的专业技能。
这里要澄清一个常见误区:微调并非“给模型灌输新知识”,而是优化模型的能力适配性。它和另一种主流优化方案RAG(检索增强生成)的区别十分清晰:RAG相当于给模型“配备参考书”,遇到不会的问题时去查阅外部知识库;微调则是把“参考书的核心内容”内化为模型自身的知识,后续使用时无需额外查资料,响应速度更快、答案精准度更高。
还有个关键优势:微调的效果是永久的。一旦训练完成,模型的参数就改好了,后续使用不用再依赖任何外部工具,部署起来更简单。
2.2 两种微调方式:全量微调vs高效微调,该怎么选?
微调并非“一刀切”的模式,主要分为两种类型,它们的适用场景和成本差异极大,新手先理清这两种方式的区别,能有效避免走弯路。
2.2.1 全量微调:全盘重塑,成本高但效果极致
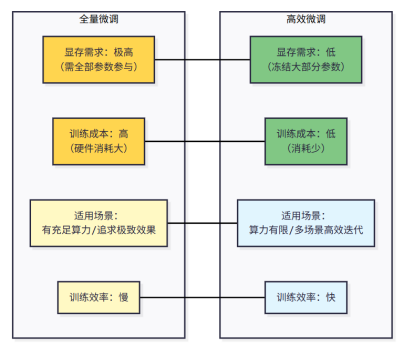
全量微调,顾名思义就是对模型的“所有知识体系”进行重新培训——将模型的每一个参数都重新优化一遍。这种方式的优势是效果极致,能够深度改造模型的核心能力,比如科研机构在研发专业领域的研究模型时,可能会采用全量微调。
但它的缺点也很突出:成本极高。一个70B参数的模型做全量微调,需要200GB以上的显存,光硬件成本就不是个人或小公司能承受的。所以对于大多数开发者和企业来说,全量微调基本不用考虑。
2.2.2 高效微调:精准特训,低成本易落地
高效微调是当前工业界的主流方案,核心思路是“不改动模型主体架构,只针对性优化关键部分”。这就像给大学生做专项技能培训,无需重新讲授所有基础课程,只需补充岗位必备的核心技能即可。具体来说,就是只调整模型中对任务影响关键的部分参数,比如Transformer结构中的注意力层、适配器层。
这种方式的优势十分突出:一是成本低,微调7B参数模型仅需16GB显存,普通消费级GPU(如RTX4090)就能满足需求;二是效率高,训练时间比全量微缩短3-5倍,支持快速迭代优化;三是兼容性强,能直接对接Hugging Face等主流AI生态工具。对于新手和企业落地场景而言,高效微调无疑是最优选择。
2.3 微调的收益与风险:提前厘清避坑点
任何技术都存在两面性,微调也不例外。提前理清它的优势与风险,才能在实践中有效避坑。
2.3.1 核心优势
•响应快:不用依赖外部知识库,直接输出结果,延迟更低;
•精度高:针对性优化后,在目标任务上的准确率显著提升;
•部署简单:优化效果固化在模型里,不用额外搭建工具链。
2.3.2 潜在风险与规避方法
最需要警惕的风险是“灾难性遗忘”——就像一个人过度专注于学习新技能,反而遗忘了原本掌握的基础能力。如果微调时数据集设计不合理,或者训练策略设置不当,模型可能会丢失预训练阶段习得的通用能力。比如原本能解答各类通用问题的模型,微调后只精通某一专业领域,面对其他问题时完全无法响应。
不过这一风险可通过科学方法规避:比如严格筛选高质量数据集、合理控制训练学习率、分多轮进行验证迭代等,这些措施都能有效防止模型“忘本”。
2.4 高效微调核心:LoRA和QLoRA是什么?
提到高效微调,就不得不提两个核心技术:LoRA和QLoRA。这两种方案是目前高效微调的主流选择,新手只要掌握它们的核心逻辑和使用场景,就能应对大部分微调需求。
2.4.1 LoRA:低门槛入门首选
LoRA的全称是“低秩适配”,听起来很专业,实则原理简单易懂:在模型的关键层(如Transformer的注意力层)中插入一个“小插件”(即适配器),训练过程中仅优化这个“小插件”的参数,而模型主体的参数保持不变。
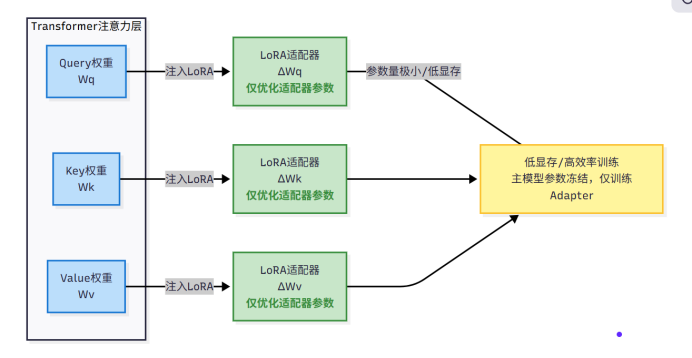
打个形象的比方,这就像给电脑安装功能插件,无需更换电脑硬件,只需加装对应插件就能实现新功能。这个“插件”的参数规模很小,能将原本需要训练的数十亿级参数量压缩到百万级,显存占用直接降低80%以上,普通消费级GPU就能轻松驾驭。
LoRA的优势很明确:操作简单、兼容性强,能对接Hugging Face等主流生态,训练完的“插件”还能和原始模型合并,部署的时候不增加额外延迟,新手入门优先选它。
2.4.2 QLoRA:极限压缩,低显存玩转大模型
QLoRA是LoRA的进阶优化版本,核心改进是引入了“量化”技术。什么是量化?简单来说,就是给模型的参数“瘦身”——将原本高精度的参数(如FP16)压缩为低精度(如INT4),相当于把一本厚书精简为一本小册子,既能大幅减少存储空间占用,也能降低显存消耗。
以INT4量化为例,它能将模型存储量压缩至原来的1/4,70B参数的大模型用QLoRA微调时,仅需48GB显存,单卡就能完成训练(而全量微调70B模型需要200GB以上显存)。更重要的是,QLoRA在压缩参数的同时,能最大限度保证模型性能,仅在极少数复杂推理任务中会出现轻微的精度损失。
如果你的GPU显存比较小(比如8GB、12GB),又想微调大模型,那QLoRA就是最佳选择。
2.4.3 LoRA与QLoRA核心差异对比
特性 LoRA QLoRA
核心技术 低秩适配器(无量化) 低秩适配器+INT4/INT8量化
显存需求 中等(7B模型约16GB) 极低(7B模型约6GB,70B模型约48GB)
适用场景 消费级GPU(RTX4090等)、中小模型 边缘设备、低显存GPU、超大模型(70B+)
训练难度 低(不用配置量化参数) 中(需要调整量化参数,避免精度损失)
推理速度 无额外延迟 更快,比LoRA提升20%-30%
三、微调效果评估:3个维度判断是否成功
很多新手微调完模型后,不清楚如何评估效果。其实核心只需关注两个维度:客观量化指标和主观使用体验,两者结合就能全面判断微调是否成功。
3.1 客观指标:用数据量化效果
对于有明确标准答案的任务(如专业问答、文本分类),可通过以下客观指标量化评估模型效果:
•准确率:模型回答正确的样本占总样本的比例;
•精确率/召回率:针对分类任务,比如判断“是否需要退换货”,精确率是模型判断需要退换货的样本中,实际需要的比例;召回率是实际需要退换货的样本中,模型判断正确的比例;
•困惑度(Perplexity):衡量模型生成文本的流畅度,困惑度越低,生成的文本越自然。
这些客观指标无需手动计算,可借助EvalScope评估框架自动生成,LLaMA-Factory Online. https://www.llamafactory.com.cn/register?utm_source=jslt_bky_ssn已内置该评估工具,训练完成后自动生成包含准确率、困惑度等指标的详细报告,还提供可视化图表展示效果差异,新手无需额外配置,直接查看报告就能判断模型效果,大幅降低评估门槛。EvalScope是阿里魔搭社区推出的开源评估工具,支持中英文多种任务类型,详细信息可参考其GitHub地址:https://github.com/modelscope/evalscope

3.2 主观体验:从用户视角判断效果
•风格一致性:模型的回复风格是否符合预期(比如客服的专业耐心);
•相关性:回复是否和用户问题相关,有没有答非所问;
•实用性:回复是否能解决用户的实际问题,比如客服回复是否给出了明确的操作步骤。
建议邀请3-5位测试者对模型回复打分(1-5分,分数越高效果越好),通过平均分判断模型的主观体验效果。打分时重点关注上述三个维度,确保评估结果全面客观。LLaMA-Factory Online内置了评分模板,可直接导出使用,无需手动制作打分表,进一步提升评估效率。
3.3 对比测试:和微调前做对比
最直观的评估方式是“前后对比测试”:用相同的测试问题,分别向微调前的通用模型和微调后的模型提问,对比两者的回复差异。比如询问“衣服尺码小了能换货吗?”,通用模型可能仅简单回复“可以换货”,而微调后的客服助手模型会详细说明换货条件、操作步骤等关键信息——这种差异直接证明微调有效。
四、总结与展望:新手进阶路径
4.1 核心要点总结
通过以上内容,我们从原理到实战完整梳理了大模型微调的核心知识,这里为大家总结3个关键要点:
•微调的本质是“专项特训”:让通用模型在特定领域更精通,效果永久固化,部署简单;
•新手首选高效微调:LoRA/QLoRA低成本、易落地,普通GPU就能搞定;
•数据集是核心关键:高质量、格式正确的数据集,比复杂的调参更能决定微调效果。
对于新手而言,无需一开始就追求复杂的大模型和参数调优,建议从7B参数模型、简单任务(如客服助手、笔记整理)入手,先熟悉完整的微调流程,积累实践经验后再逐步挑战更复杂的场景。
4.2 新手进阶建议与未来展望
从技术发展趋势来看,大模型微调未来将朝着“更低门槛、更高效率、多模态融合”的方向演进:未来可能无需编写代码,通过可视化界面拖拽操作就能完成微调;训练效率将进一步提升,微调时间从几小时缩短至几分钟;同时还会支持文本、图像、语音等多模态数据的联合微调,实现更复杂的跨模态任务。
想要紧跟微调技术的最新进展,快速提升实战能力,最直接的方式是借助成熟的工具平台积累经验,其中LLaMA-Factory Online就是新手进阶的优质载体:平台会实时同步LoRA/QLoRA等前沿技术,内置经筛选的高质量开源数据集和预训练模型,新手无需四处查找资源;专属开发者社区可交流避坑经验,遇到问题能快速获得解决方案;配套的在线实验环境无需任何本地配置,直接上手实操就能熟悉全流程,从基础的单模态微调到复杂的多模态训练,都能在平台上完成,助力新手从入门到精通快速进阶。
最后要强调的是,技术学习的核心在于实践。看完这篇指南后,建议大家直接通过LLaMA-Factory Online动手尝试——无需配置环境、不用编写代码,选择一个简单任务(如客服助手、笔记整理),跟着平台引导上传数据、启动训练,就能快速完成第一个专属模型的定制。只有亲身参与全流程操作,才能真正掌握微调技术的核心要点。如果在平台使用或实践过程中遇到问题,欢迎在评论区留言交流。
