


一 基本的数据库命令
-
注释: 单行注释 #+注释文字 / 单行注释 --+注释文字
1,链接mysql服务器: mysql -h 主机地址 用户名 -p密码
2,更改用户密码: mysqladmin -u 用户名 -p旧密码 password 新密码
3, 设置密码(前提没有设置密码): mysqladmin -u 用户名 password 密码
4,创建数据库: create database +数据库名称 例如:create database test1; 注:数据库名称有特殊字符需要加上' '反引号
5. 查看数据库:show databases;
6,删除数据库:drop database +数据库名字;
7.切换数据库: use +数据库名称
8,查看数据库中存在的表:show tables;
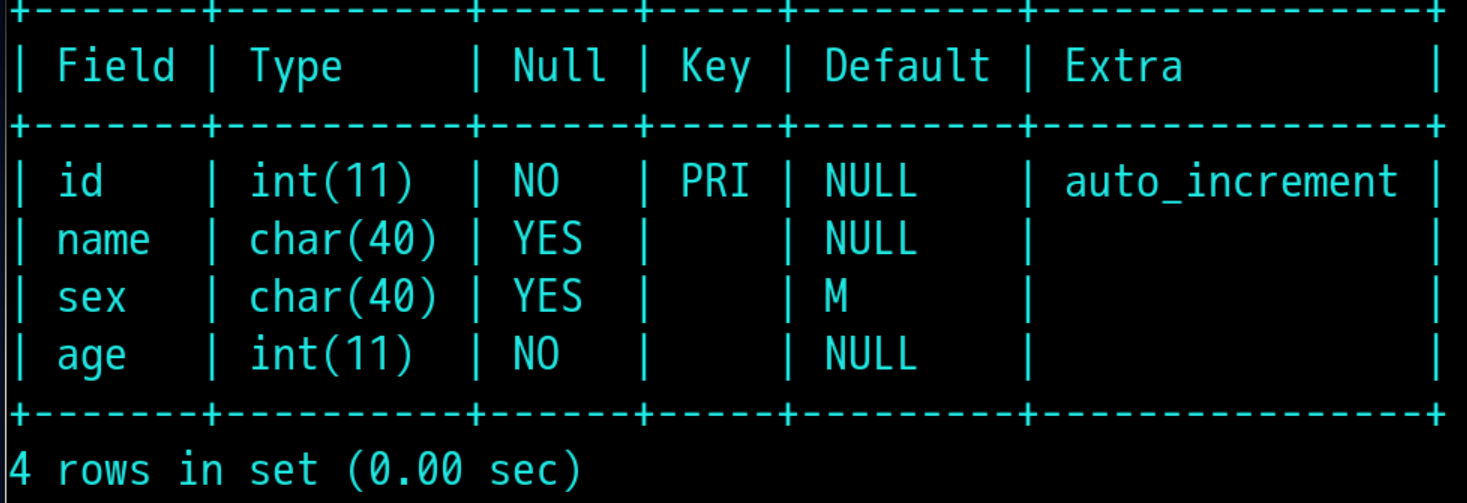
9,创建表:create table +表名(字段名1+数据类型,字段名2+数据类型,字段名n+数据类型); 一行代表记录,一列代表字段
例如: create table student(sex char(40),name char(40),age int(40));
tip1: 数据类型 : 分类有:数值型,字符串,日期时间类型
整数型分类: 整数 int 4B , small 2B , big int 8B
小数:float : 单精度浮点数(4k) double 双精度浮点数(8k)
字符串类型:char : 0~255 varchar 0~5535 可变长度字符串(根据字符串长度自动调整)
tip2: 列明的修饰:
auto increment(自增) default(默认值) comment(字段解释说明) not null(非空) primary key(主键) 例:create table student(id int primary key auto_increment ,name cahr(40) comment "姓名",sex char(40) default "男",age int not null);
例子:
create table mm(id int primary key auto_increment, name char(40) comment "xingming",sex char(40) default "M",age int not null);
二, 增删改查的使用方法:
TIP:
1# 主键 : 唯一表示一条记录,不能有重复的不能为空,主键只能有一个用来保证数据的完整性()
对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
例如,假设我们把name字段作为主键,那么通过名字小明或小红就能唯一确定一条记录。但是,这么设定,就没法存储同名的同学了,因为插入相同主键的两条记录是不被允许的。
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改,因为主键是用来唯一定位记录的,修改了主键,会造成一系列的影响。
由于主键的作用十分重要,如何选取主键会对业务开发产生重要影响。如果我们以学生的身份证号作为主键,似乎能唯一定位记录。然而,身份证号也是一种业务场景,如果身份证号升位了,或者需要变更,作为主键,不得不修改的时候,就会对业务产生严重影响。
所以,选取主键的一个基本原则是:不使用任何业务相关的字段作为主键。
因此,身份证号、手机号、邮箱地址这些看上去可以唯一的字段,均不可用作主键。
作为主键最好是完全业务无关的字段,我们一般把这个字段命名为id。常见的可作为id字段的类型有:
-
自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
-
全局唯一GUID类型:使用一种全局唯一的字符串作为主键,类似
8f55d96b-8acc-4636-8cb8-76bf8abc2f57。GUID算法通过网卡MAC地址、时间戳和随机数保证任意计算机在任意时间生成的字符串都是不同的,大部分编程语言都内置了GUID算法,可以自己预算出主键。 - 添加主键 create table 表名(字段名1 数据类型 primary key , 字段名2 数据类型 (新建立的表); 或者: alter table 表名 add primary key(字段名);
- 删除主键 alter table 表名 drop primary key; (表已经建立好的情况下,删除主键是不需要在后面添加字段名得);
-
PRI主键约束;
2# 外键: 表的外键是另一个表的主键,外键可以有重复的,可以是空值 一个表可以有多个外键
添加外键:create table 表2 (字段1 数据类型,字段2 数据类型,foreign key(字段2) references 表1(字段1))
删除外键: alter table 表名 frop foreign key ;
UNI唯一约束
MUL可以重复
增:
1. 向表中插入数据:
inert into 表名(字段名1 ,字段名2) value(值1,值2) : inert into class(class_name,student_name) value("2g2c","小米");
2.查看数据是否插入成功:
select *from 表名 ; 例如: select *from class;
3,删除表:drop table +表名;
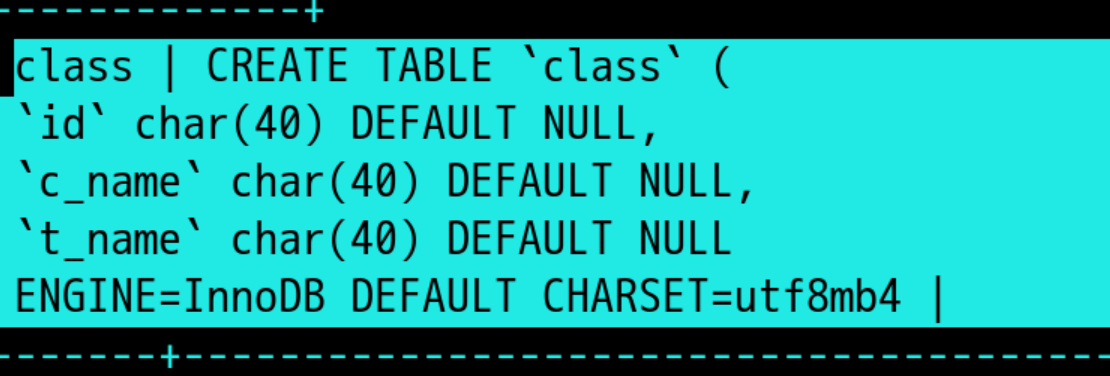
4,查看表的sql语句: show create table +表名;
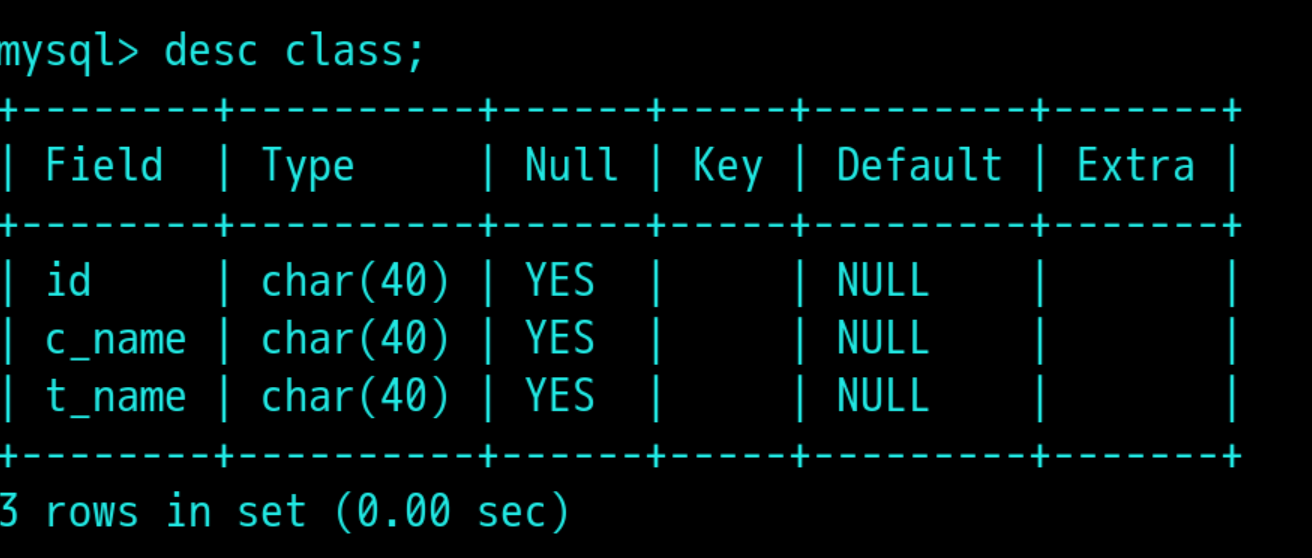
5,查看指定表的结构:desc +表名;
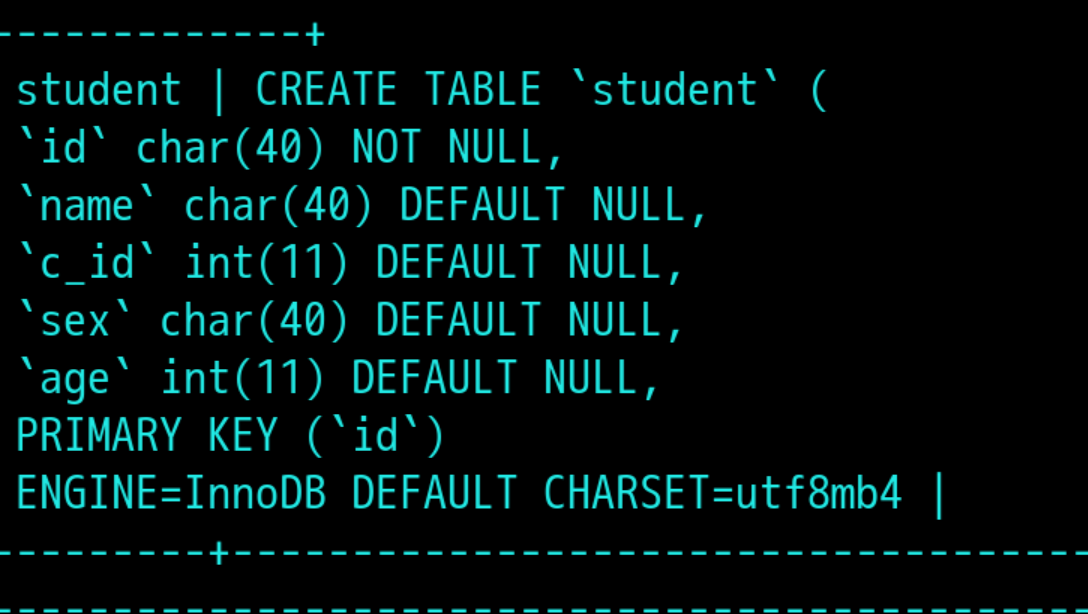
6,查看引擎:show create table student;
7,修改引擎
7.1 create teable 表名(字段名...) ENGINE =InnoDB 注 建表时不指定的话,默认用的配置文件里的引擎
7.2 alter table 表名 engine =innoDB;
删
删除表中的数据: delete from 表名 [where 条件]; ///// delete from 表名(清空整张表)
例: delete from 表名 where age =10;
delete from 表名 where name ='李四 and age is NULL; 注: 条件中字段取值为Null时,用字段名is NULL
改
修改表中的数据::update 表名 +set 字段名 =新增【字段】 where 条件;
例: update 表名 set age = age +10 ;
update 表名 set sex ='女', age =10 where name ='李四';
把年纪是10的李四性别改为n女: update 表名 set sex ='m' where name ='lisi' and age ='10';
修改表中某一字段: update 表名 set 字段名 = replace(字段名,‘原来值’,‘修改值’)+可以添加条件;
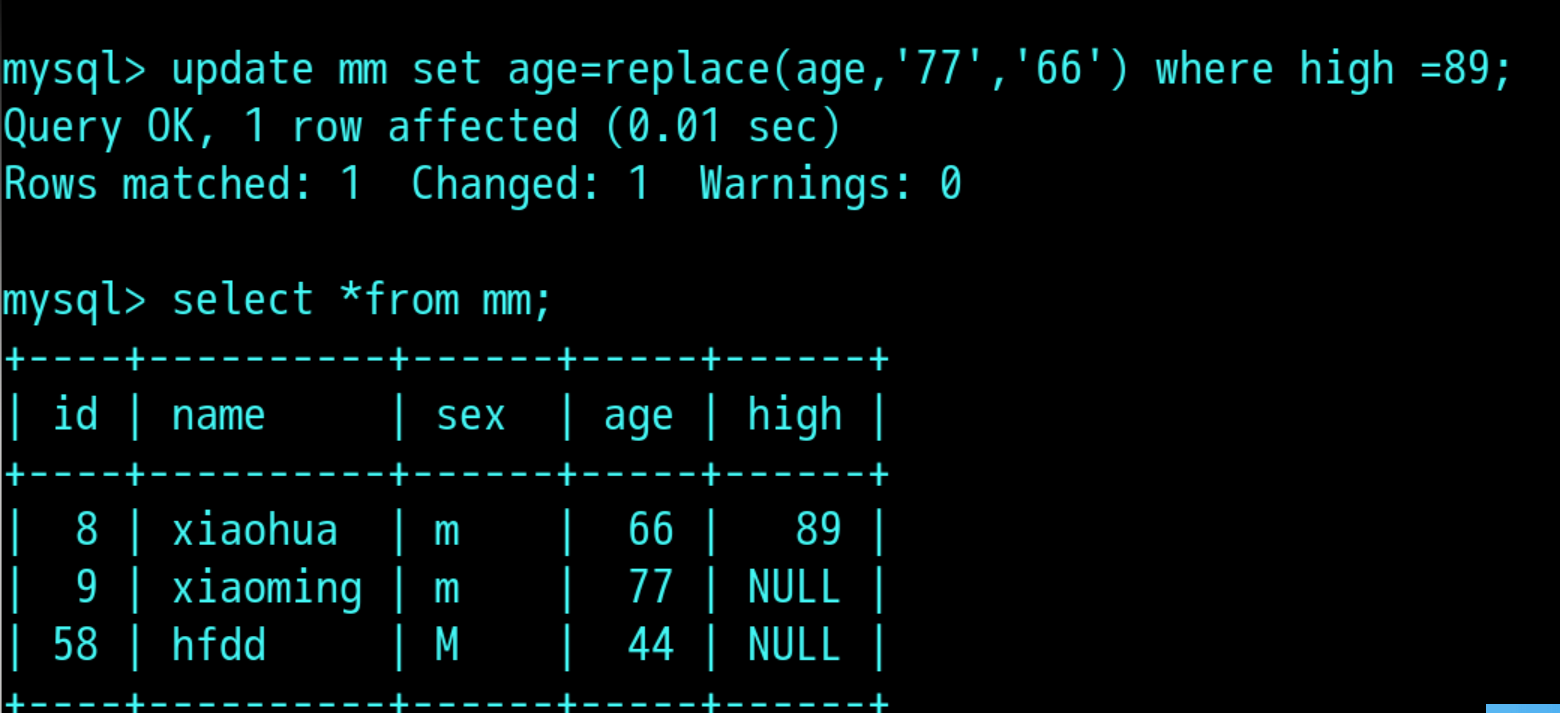
修改表中字段为NULL 或者同名的年纪值,可以通过添加条件来操做:

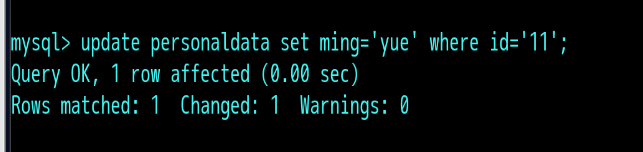
当表中遇到人姓名,性别,身高体重等都一样的话,怎么修改其中一个人的信息:可以通过where =id来区别:
五 修改表的结构
1 , 在表格中添加一个字段: alter table 表名 add 字段名 数据类型 first |after 字段名
alter table 表名 add 字段名 数据类型 字段名 : alter table student add sex char;(在表格的首行插入字段)
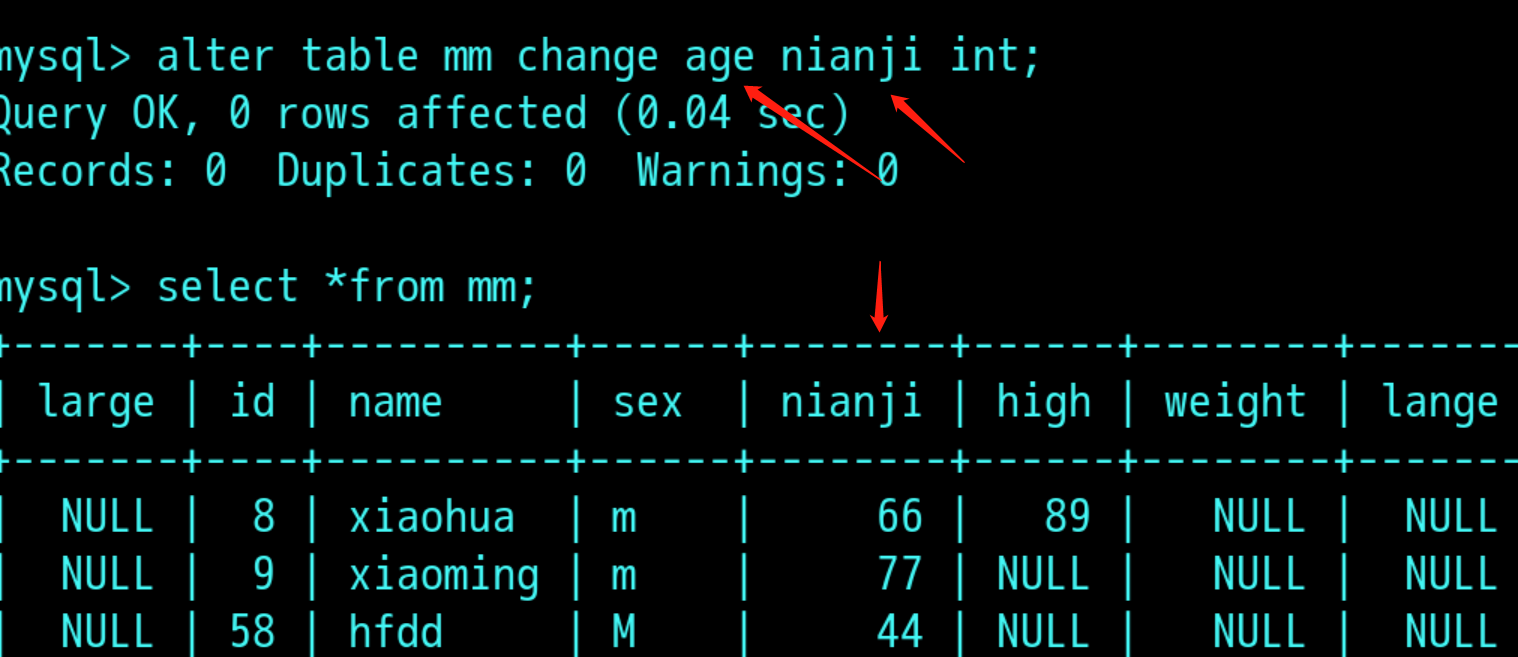
2, 修改字段名或字段对应的数据类型:alter table 表名 change 旧字段名 新字段名 数据类型;
例: 1.1 alter table 表名 change age nianji int;
alter table 表名 change name xingshi char(40);是字符的话,要加上字符大小
1.2 只改变数据类型,不改变字段的名字: alter table 表名 change age age char(30);
3 ,删除字段 :alter table 表名 drop 字段名:
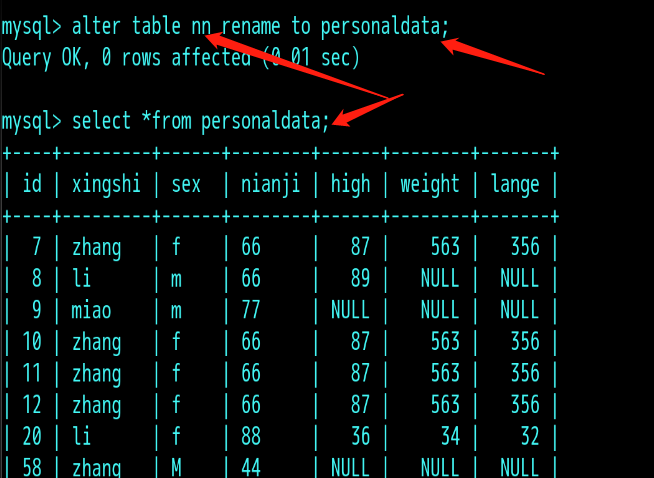
4 更改表名: alter table 旧表名 rename to 新表名;
5 ,查看编码方式 :show variables like "char%";
查
查询表中的数据: select 字段名1 ,字段名2 from 表名 +[where 条件];
会把指定的某个字段过滤出来:在不查询所有字段的时候,可以通过这样指定字段的形式按照顺序过滤出自己想要的字段值(图中使用的是着重号 不是单引号,方便读,可视性强 在键盘上数字1 左边的按键);
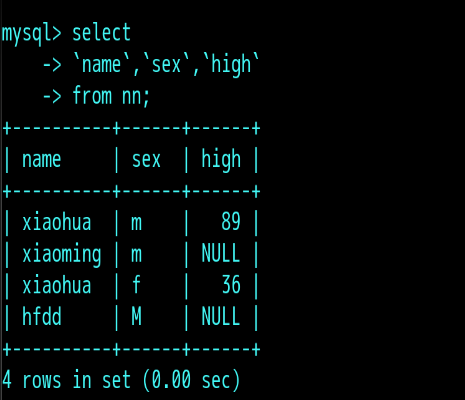
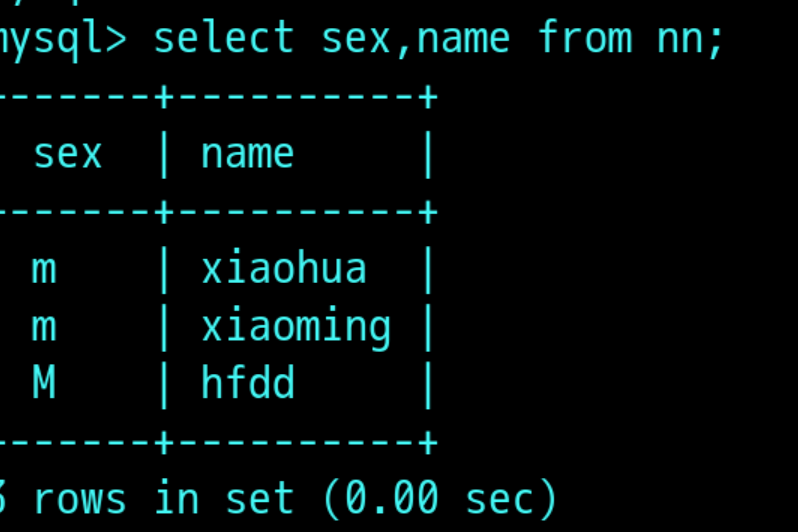
select *from 表名:查询表中所有数据,
selec 字段名 from 表名: +条件:
1,where +条件:
2,【group by 字段名 】 #分组
3,【having 条件】 #对分组的条件进行过滤
4,【order by 字段名 ASC/DESC】 #排序
5,【limit m,n】 #限制
一 :where 条件
条件中常用的运算符: < ,>,=,<>,<=,>= ,between ...and.... in | not in
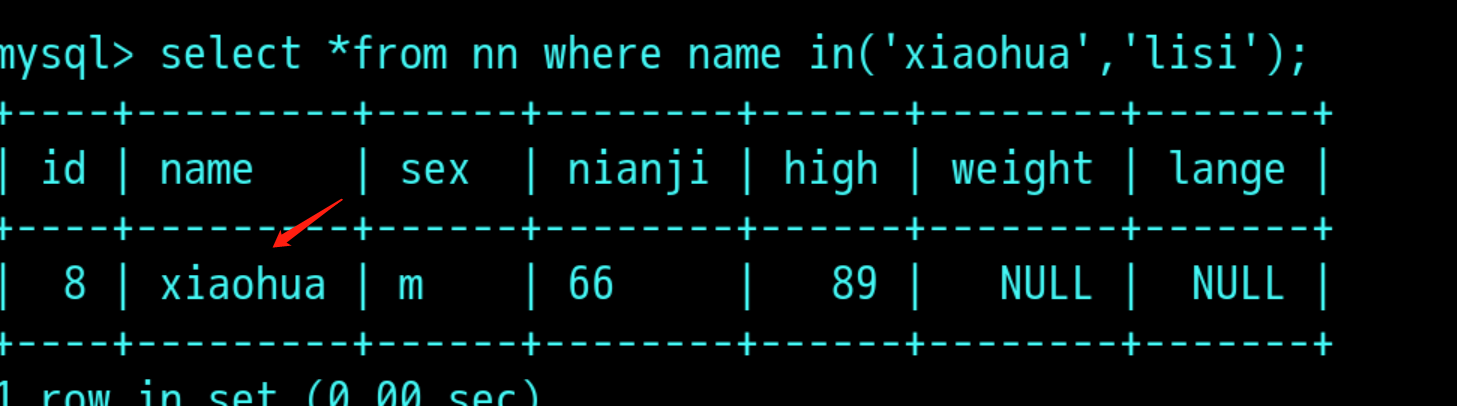
select *from nn where name in('xiaohua','xiaozhang'); 从表格中过滤出有xiaohua和lisi的字段 (lisi不在表中)
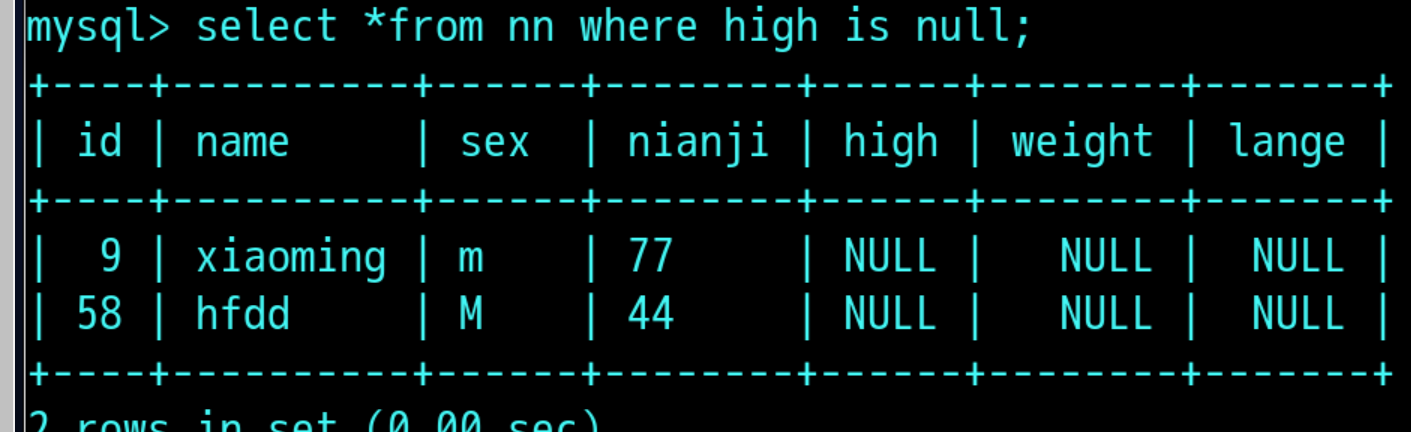
二 : is null /is not null
select *from nn where high is null; 过滤出high为null的字段
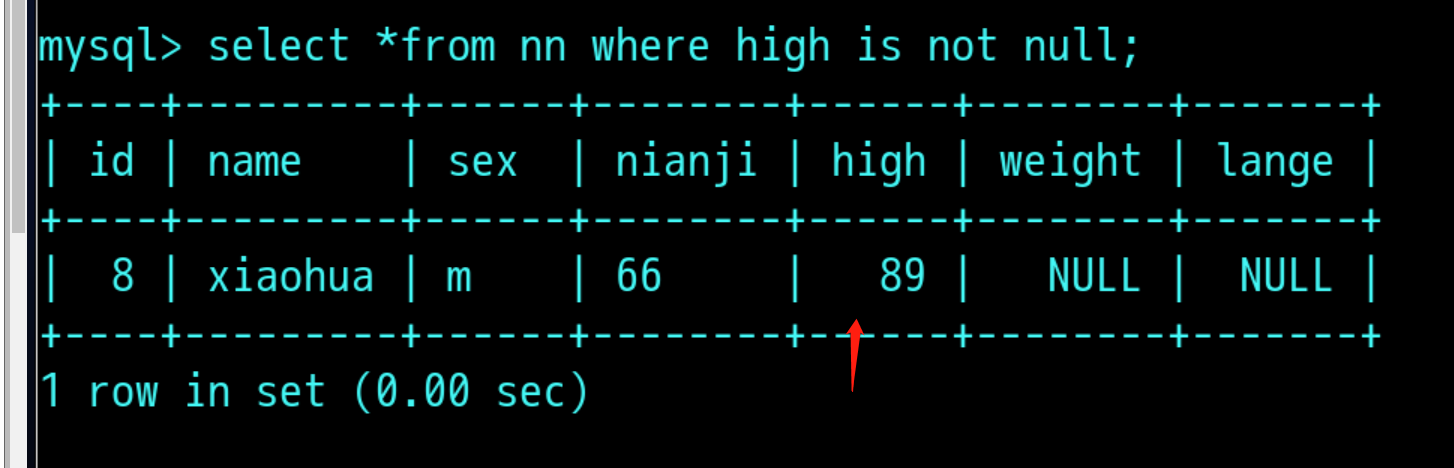
select *from nn where high is not null : 过滤出表中high值不为null的记录
三 模糊查询:like
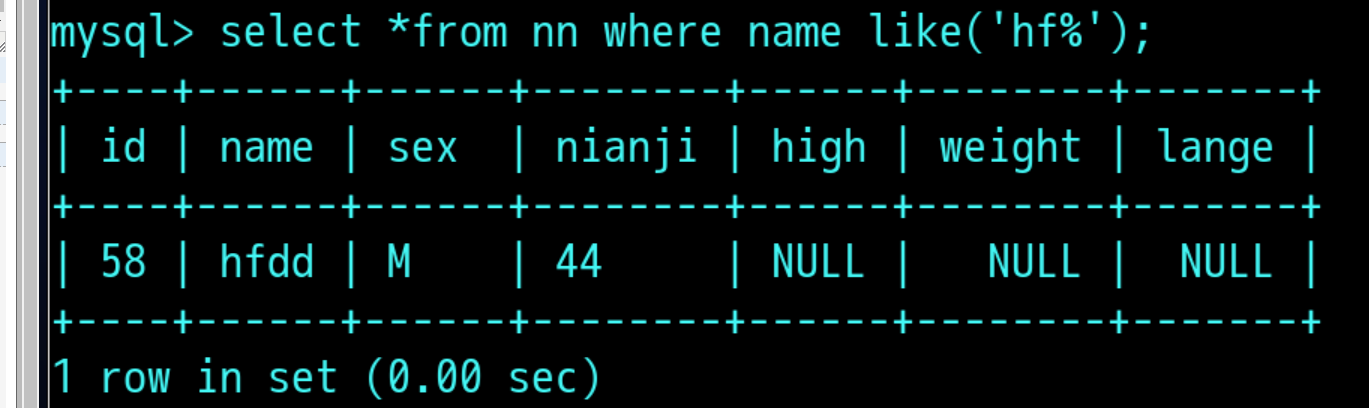
select *from nn where name like('张%'); 必须加%
四 多条件查询: and or (and 优先级高于or)
select *from 表名 where name ='xiaohua' and sex ="m";
聚合函数
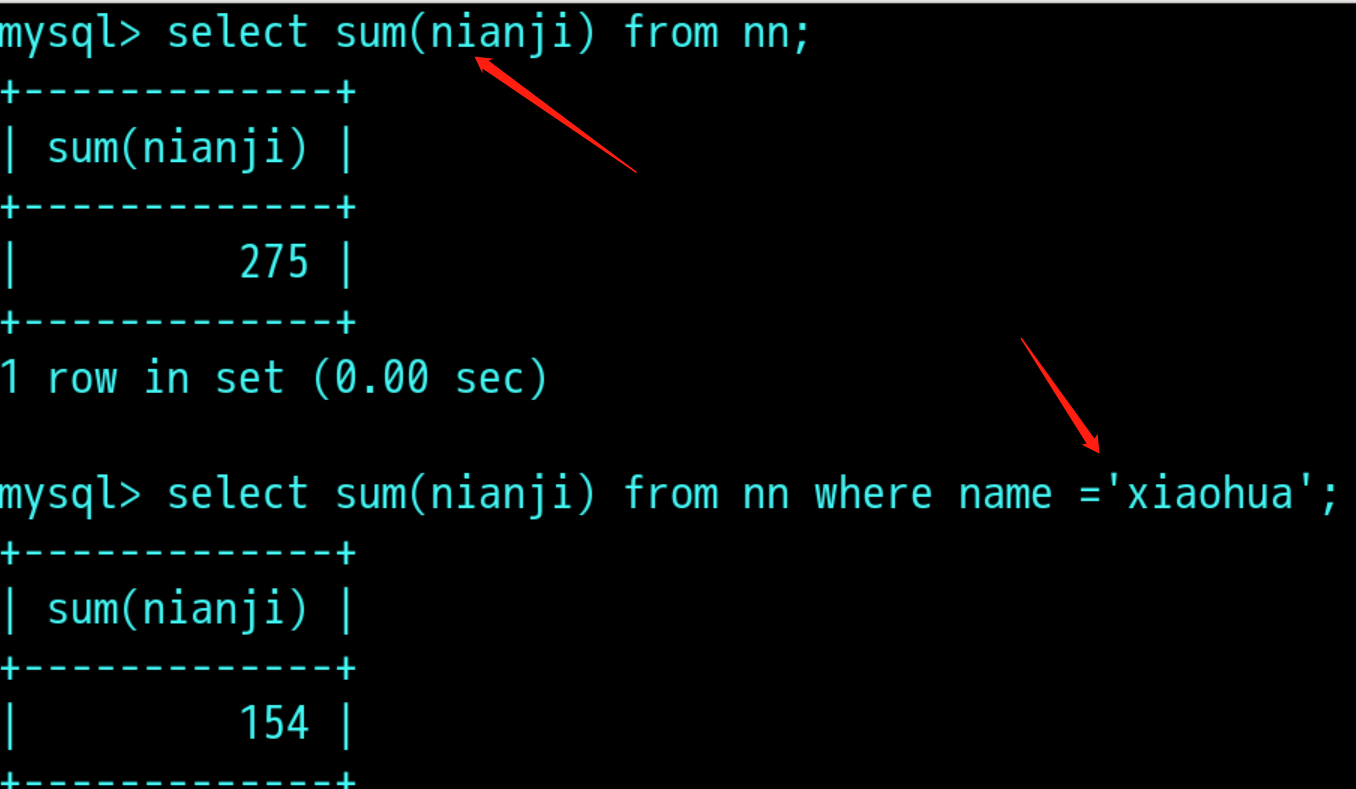
sum+字段名 : select sum(nianji) from nn: 从nn表中统计nianji值得合计值(还可以添加条件);
MAX 字段名 :求最大函数j
MIN字段名:求最小值函数
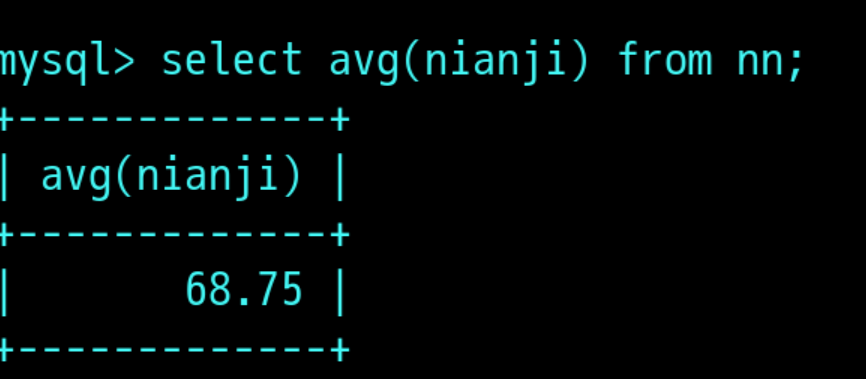
AVG字段名:求平均值函数
select avg(字段) from 表名;
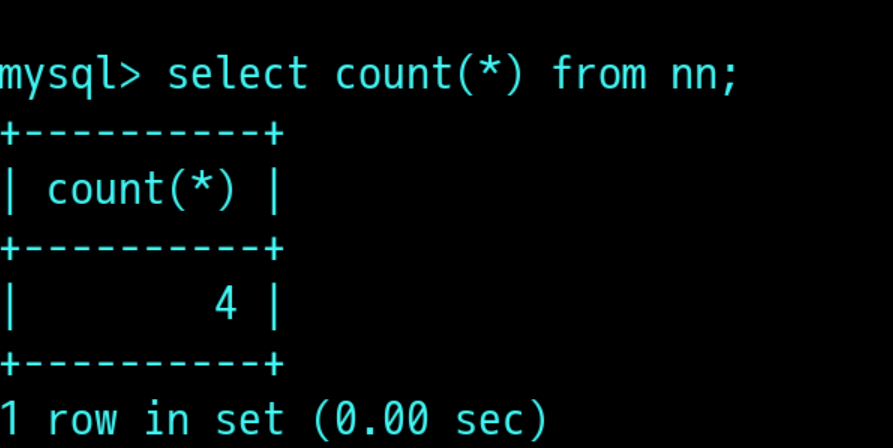
COUNT字段名:统计记录的个数函数
select count(*) from nn; 一共有4条记录
select count(字段名 from nn;该字段有几条
排序:order by 字段名[ ASC| DESC ]
select 字段 fom 表名 order by 字段 desc/ASC
select nianji from 表名 order by nianji desc: 查询年纪 通过值进行降序排列
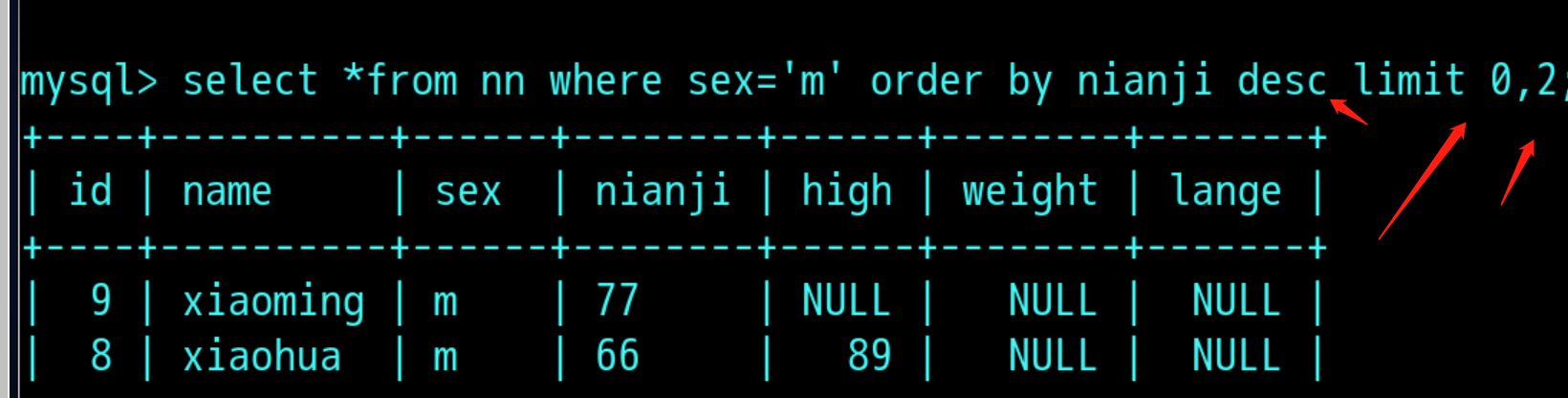
限制:limit m,n 注:m为偏移量,n是记录个数
select *from 表名 where sex="m" order by 年纪 limit 0,2 : 过滤出性别男 通过年纪进行排序 过滤出两行记录
分组查询:group by 字段名
一张表:
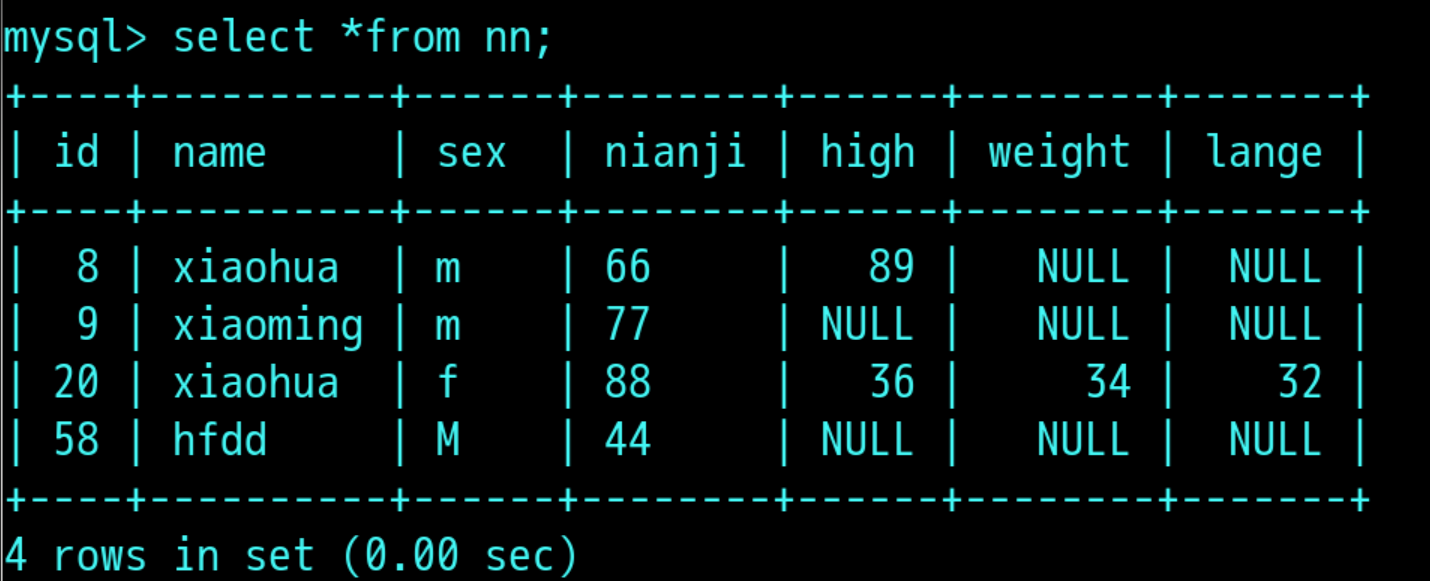
用group by 分组查询:
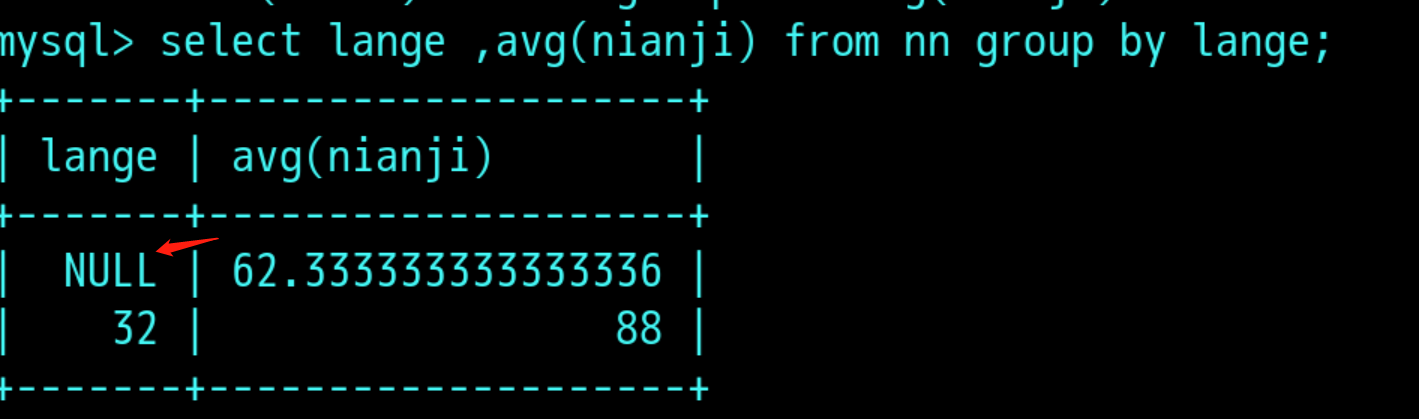
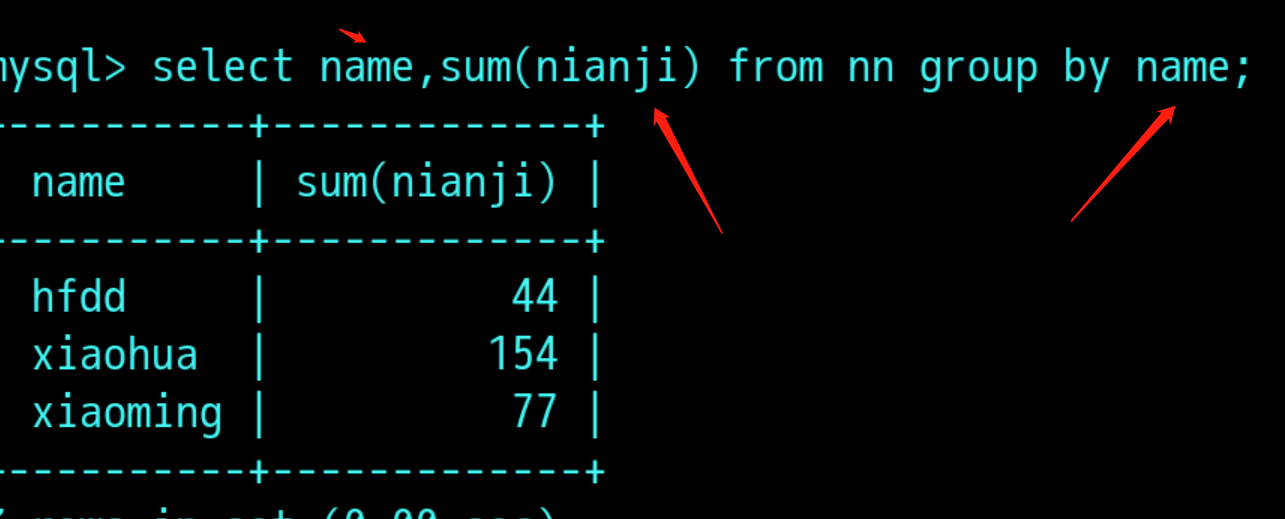
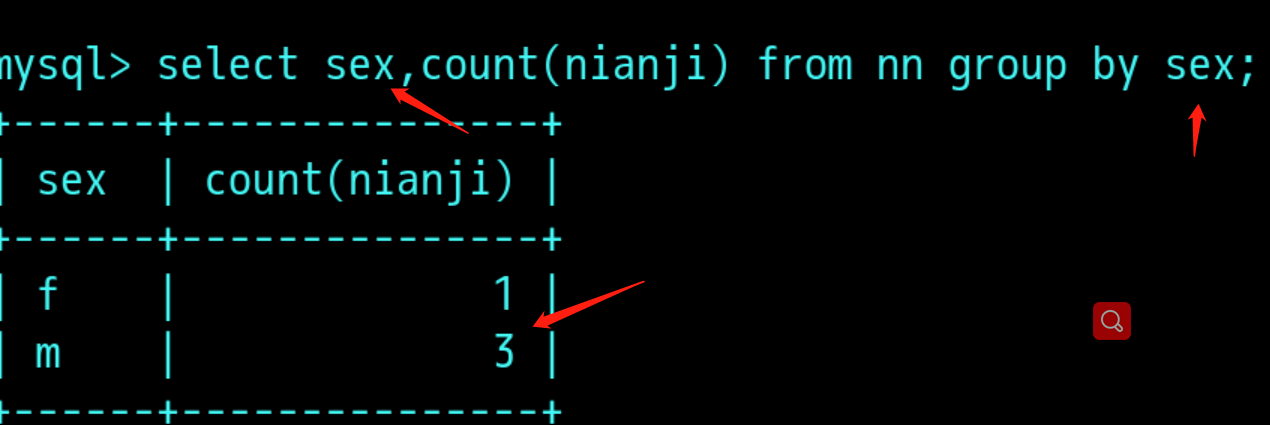
分组结果再过滤:having 条件通常与group by 连用;
having字句可以让我们筛选分组之后的各种数据,where 字句再聚合前先筛选记录,也就是说作用再group by和having字句前,而having字句再聚合后对记录进行筛选,,我得理解是真实表中没有此数据,这些数据是通过一些聚合函数产生的
表:
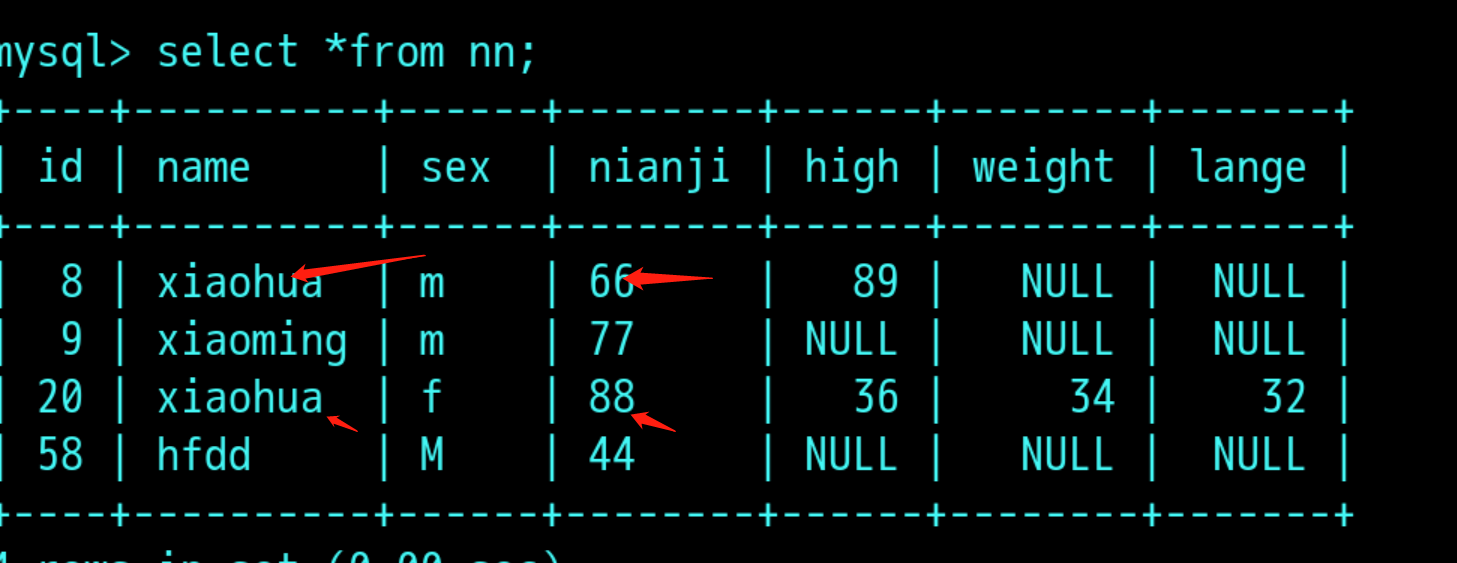
通过having过滤分组后nianji超过100的人
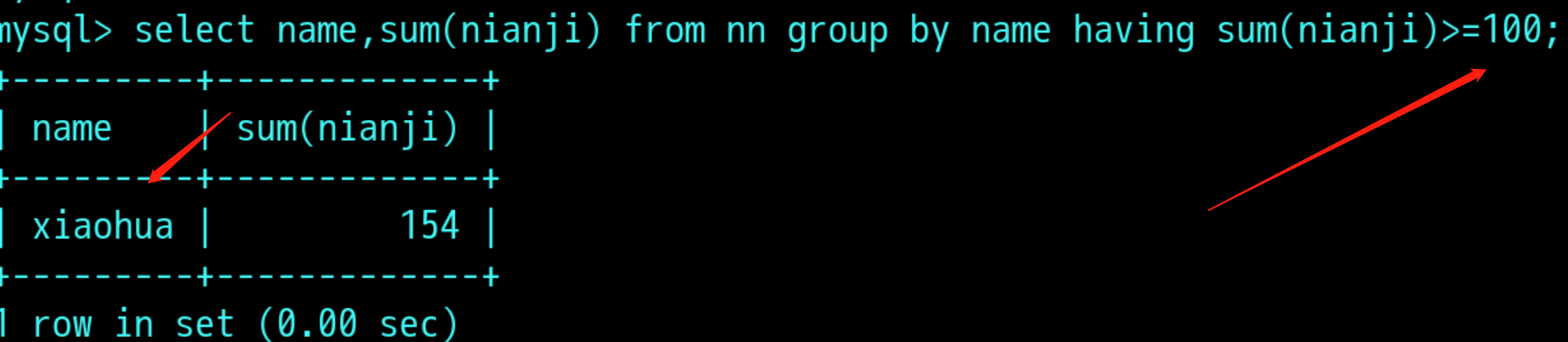
多表查询:
内链接
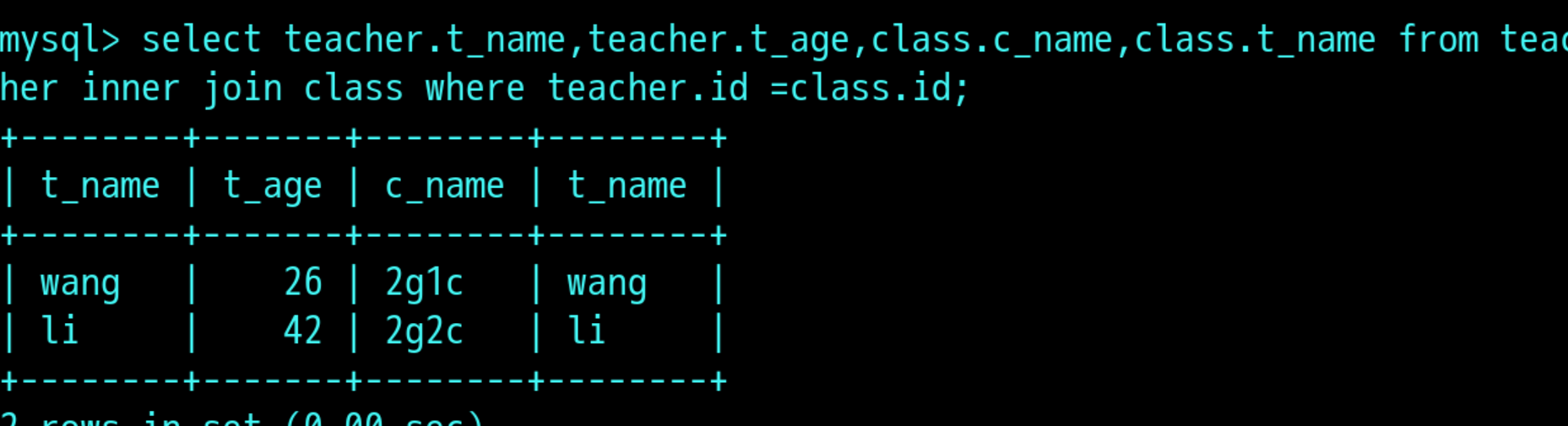
select 表名.字段名 , 表名.字段名 from 表1,表2 where 表1.字段名 =表2.字段名;
select teacher.t_name , class.c_name from teacher, class where teacher.id =class.id;
也可以写成: select teacher.t_name ,class.c_name from teacher inner join class where teache.id =class.id;
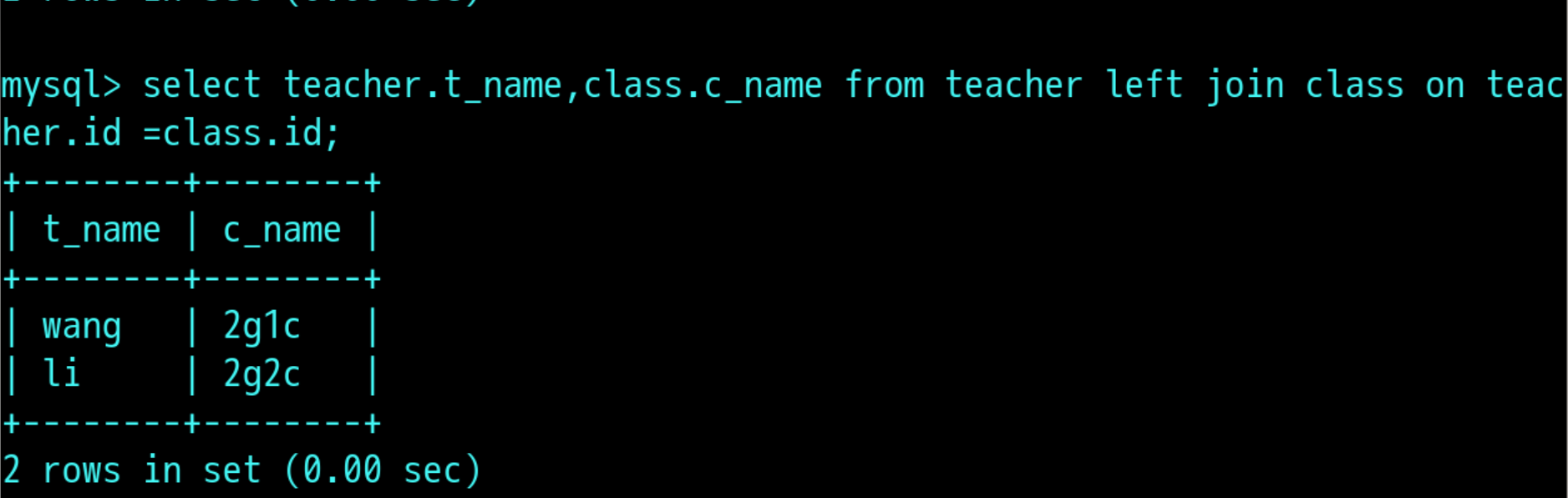
左连接:
select 表名1.字段名,表1.字段名2,表2.字段名1,表2.段名2 from 表1 left join 表2 on 表1.字段名=标2.字段名;(图中t_name 是teacher表中的字段,c_name是class表中的字段)
select teacher.t_name ,class.c_name from teacher left join class on teacher.id = class.id;
右连接:
select 表名1.字段名,表1.字段名2,表2.字段名1,表2.段名2 from 表1 right join 表2 on 表1.字段名 = 表2.字段名;
select teacher.t_name ,class.c_name from teacher right join class on teacher.id = class.id;
嵌套查询:
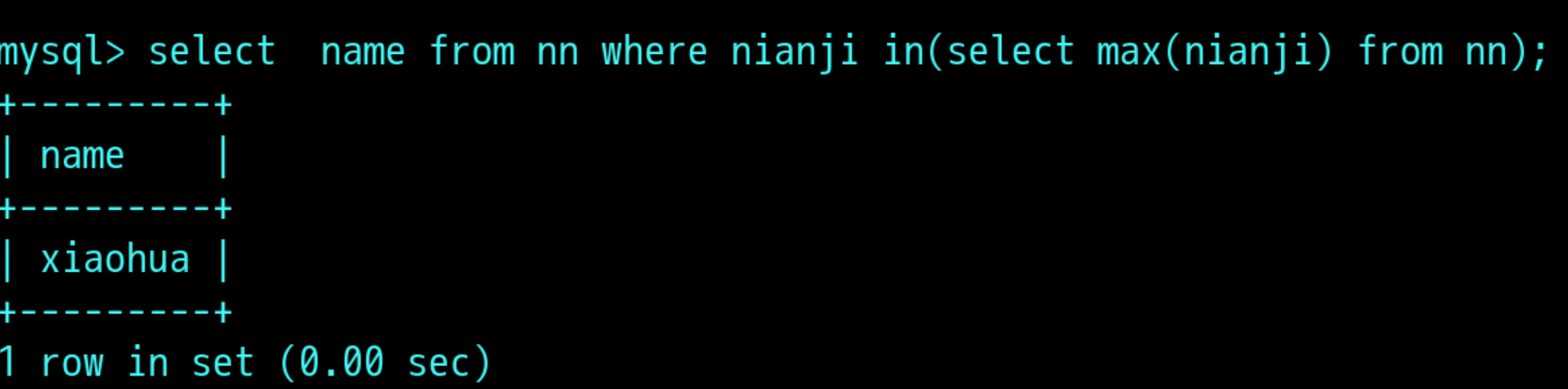
过滤出年纪大于hfdd的姓名和性别 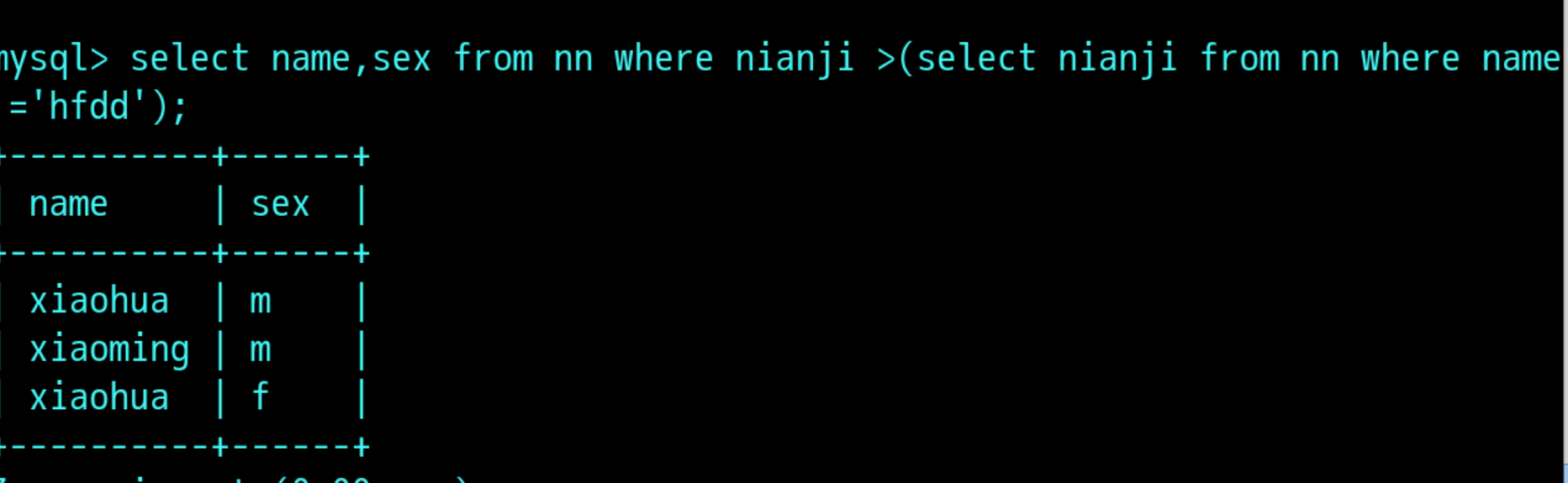
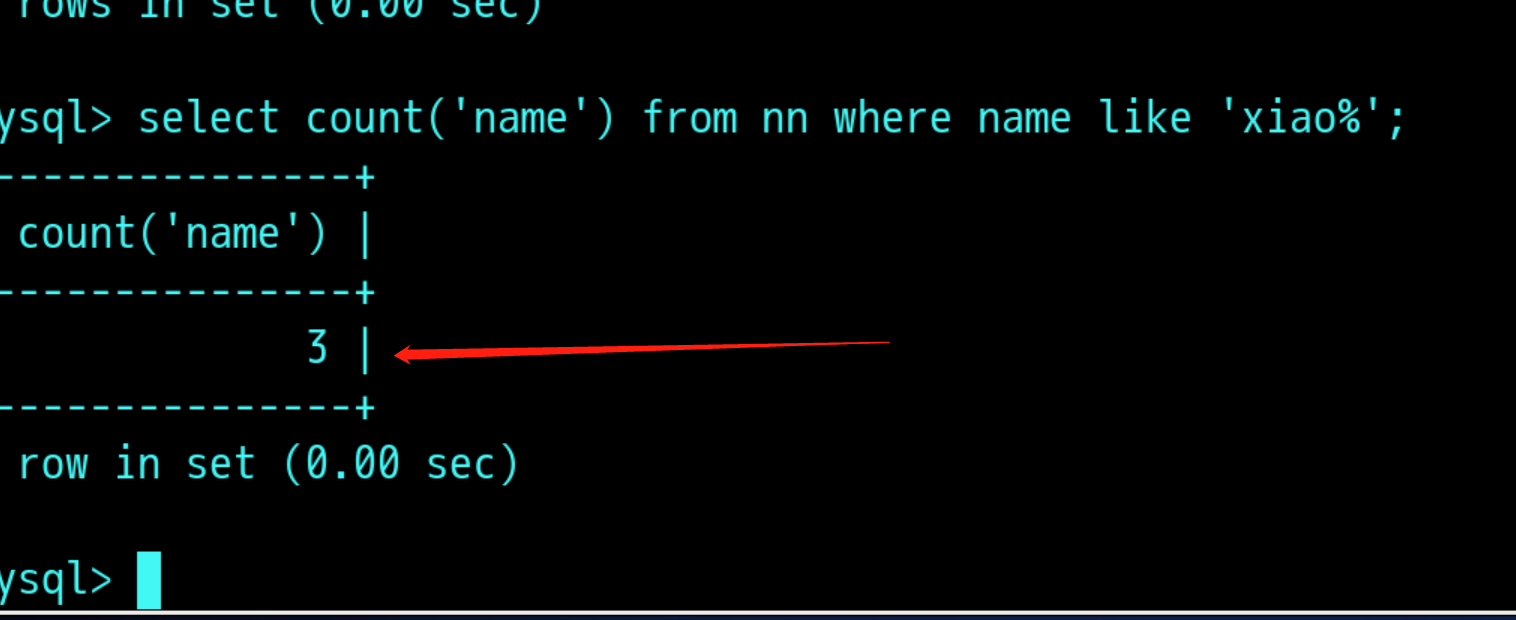
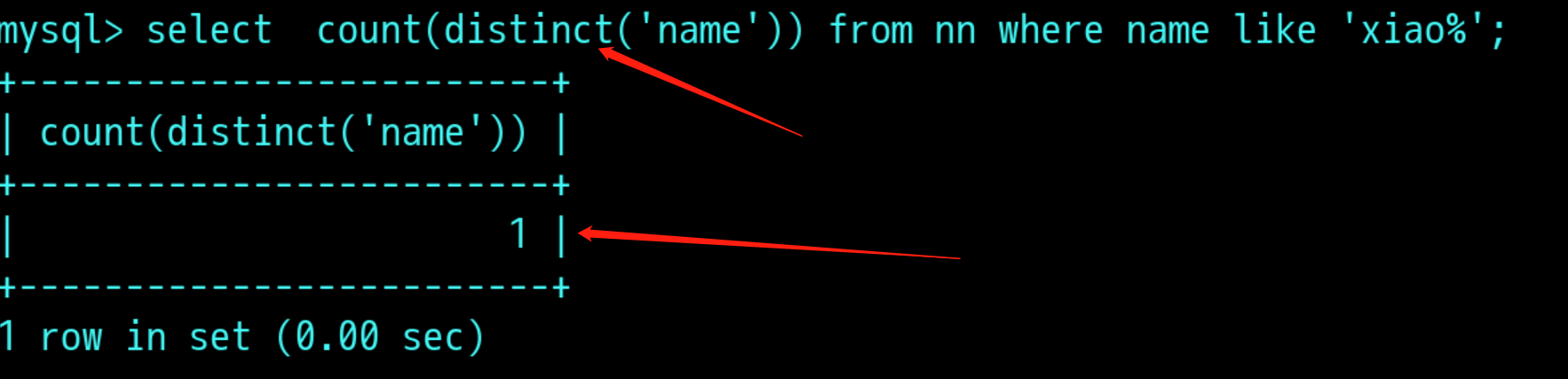
Distinct语句(去重复)
去掉表中重复的值
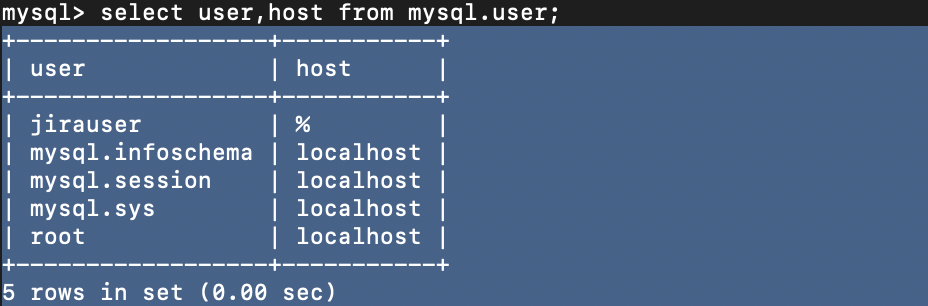
查看myql中的用户:
select user,host from mysql.user;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号