
分布式搜索的面试题1
1、面试题
es的分布式架构原理能说一下么(es是如何实现分布式的啊)?
2、面试官心里分析
在搜索这块,lucene是最流行的搜索库。几年前业内一般都问,你了解lucene吗?你知道倒排索引的原理吗?现在早已经out了,因为现在很多项目都是直接用基于lucene的分布式搜索引擎——elasticsearch,简称为es。
而现在分布式搜索基本已经成为大部分互联网行业的java系统的标配,其中尤为流行的就是es,前几年es没火的时候,大家一般用solr。但是这两年基本大部分企业和项目都开始转向es了。
所以互联网面试,肯定会跟你聊聊分布式搜索引擎,也就一定会聊聊es,如果你确实不知道,那你真的就out了。
如果面试官问你第一个问题,确实一般都会问你es的分布式架构设计能介绍一下么?就看看你对分布式搜索引擎架构的一个基本理解。
3、额外的友情提示
同学啊,如果你看到这里发现自己对es一无所知,没事儿,保持淡定,暂停一下课程。然后上百度搜一下es是啥?本机启动个es?然后写个es的hello world感受一下?然后搜个帖子把es常见的几个操作都执行一遍(聚合、常见搜索语法之类的)?ok了,1~2小时熟悉足够了,回来吧,继续看我们的课程。
4、面试题剖析
elasticsearch设计的理念就是分布式搜索引擎,底层其实还是基于lucene的。
核心思想就是在多台机器上启动多个es进程实例,组成了一个es集群。
es中存储数据的基本单位是索引,比如说你现在要在es中存储一些订单数据,你就应该在es中创建一个索引,order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是mysql里的一张表。index -> type -> mapping -> document -> field。
index:mysql里的一张表
type:没法跟mysql里去对比,一个index里可以有多个type,每个type的字段都是差不多的,但是有一些略微的差别。
好比说,有一个index,是订单index,里面专门是放订单数据的。就好比说你在mysql中建表,有些订单是实物商品的订单,就好比说一件衣服,一双鞋子;有些订单是虚拟商品的订单,就好比说游戏点卡,话费充值。就两种订单大部分字段是一样的,但是少部分字段可能有略微的一些差别。
所以就会在订单index里,建两个type,一个是实物商品订单type,一个是虚拟商品订单type,这两个type大部分字段是一样的,少部分字段是不一样的。
很多情况下,一个index里可能就一个type,但是确实如果说是一个index里有多个type的情况,你可以认为index是一个类别的表,具体的每个type代表了具体的一个mysql中的表
每个type有一个mapping,如果你认为一个type是一个具体的一个表,index代表了多个type的同属于的一个类型,mapping就是这个type的表结构定义,你在mysql中创建一个表,肯定是要定义表结构的,里面有哪些字段,每个字段是什么类型。。。
mapping就代表了这个type的表结构的定义,定义了这个type中每个字段名称,字段是什么类型的,然后还有这个字段的各种配置
实际上你往index里的一个type里面写的一条数据,叫做一条document,一条document就代表了mysql中某个表里的一行给,每个document有多个field,每个field就代表了这个document中的一个字段的值
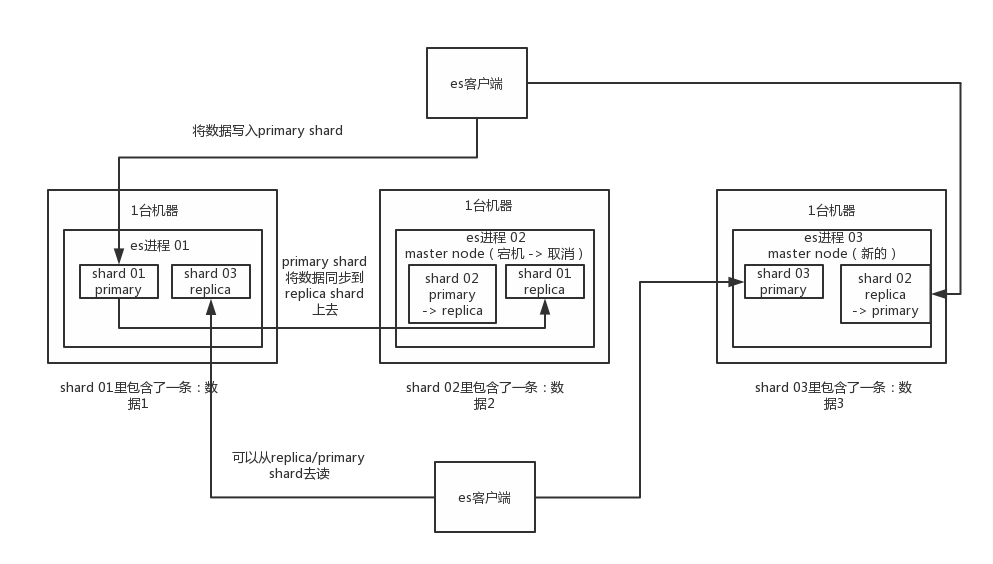
接着你搞一个索引,这个索引可以拆分成多个shard,每个shard存储部分数据。
接着就是这个shard的数据实际是有多个备份,就是说每个shard都有一个primary shard,负责写入数据,但是还有几个replica shard。primary shard写入数据之后,会将数据同步到其他几个replica shard上去。
通过这个replica的方案,每个shard的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。高可用了吧。
es集群多个节点,会自动选举一个节点为master节点,这个master节点其实就是干一些管理的工作的,比如维护索引元数据拉,负责切换primary shard和replica shard身份拉,之类的。
要是master节点宕机了,那么会重新选举一个节点为master节点。
如果是非master节点宕机了,那么会由master节点,让那个宕机节点上的primary shard的身份转移到其他机器上的replica shard。急着你要是修复了那个宕机机器,重启了之后,master节点会控制将缺失的replica shard分配过去,同步后续修改的数据之类的,让集群恢复正常。
其实上述就是elasticsearch作为一个分布式搜索引擎最基本的一个架构设计

 浙公网安备 33010602011771号
浙公网安备 33010602011771号