
<吴恩达老师深度学习笔记二>第一周,深度学习介绍
摘要: 本篇博客仅作为笔记,如有侵权,请联系,立即删除(网上找博客学习,然后手记笔记,因纸质笔记不便保存,所以保存到网络笔记)。
1.1 欢迎
深度学习常常运用于:读取X光图像、个性化教育、精准化农业、驾驶汽车等领域。深度学习处于AI分支中,学习如何建立神经网络(包含一个深度神经网络),以及如何在数据上面训练他们。(第一门课程主要识别猫)
1.2 什么是神经网络
深度学习-训练神经网络的过程,有时它指的是特别大规模的神经网络训练。神经网络的一部分神奇之处在于,当你实现它之后,你要做的只是输入x,就能得到输出y。它可以自己计算你训练集中样本的数目以及所有的中间过程。
值得注意的是神经网络给予了足够多的关于x和y的数据,给予了足够的训练样本有关x和y。
1.3 神经网络的监督学习
关于神经网络也有很多种类,考虑到它们的使用效果,有些使用起来恰到好处,但事实证明,到目前为止几乎所有由神经网络创造的经济价值,本质上都离不开一种叫做监督学习的机器学习类别。
计算机视觉在过去的几年里取得了长足的进步,这也多亏了深度学习。
深度学习最近在语音识别方面的进步也是非常令人兴奋的。
在自动驾驶技术中,你可以输入一幅图像,就好像一个信息雷达展示汽车前方有什么。
对于图像应用,我们经常在神经网络上使用卷积(Conclution Neural Network),通常缩写为CNN。对于序列数据,例如音频,有一个时间组件,随着时间的推移,音频被播放出来,所以音频是最自然的表现。作为一堆时间序列(两种英文说法one-dimensional time series/temporal sequence)。对于序列,经常使用RNN,一种递归神经网络(Recurrent Neural Network),语言,英语和汉语字母表或单词都是逐个出现的,所以语言也是自然的序列数据。因此更复杂的RNNs版本经常用于这些应用。
对于更复杂的应用比如自动驾驶,你有一张图片,可能会显式更多的CNN卷积神经网络结果,其中的雷达信息是完全不同的,你可能会有一个更定制的,或者一些更复杂的混合的神经网络。
机器学习对于结构化和非结构化数据的应用。例如在房价的预测中,你可能有一个数据库,有专门的几列数据告诉你卧室的大小和数量,这就是结构化数据。意思是每个特征,比如说房屋大小卧室数量,或者是一个用户的年龄,都有一个很好的定义,这就是结构化数据。
相反非结构化数据是指比如音频,原始音频或者你想要识别的图像或文本中的内容。这里的特征可能是图像中的像素值或文本中的单个单词。从历史经验上看,处理非结构化数据是很难的。与结构化数据比较,让计算机理解非结构化数据很难,而人类进化得非常善于理解音频信号和图像,文本也是一个更近代的发明,但是人们真的很擅长解读非结构化数据。神经网络的兴起就是这样最令人兴奋的事情之一,多亏了深度学习和神经网络,计算机现在能更好地解释非结构化数据。
神经网络对于结构化和非结构化数据都是有用处的。
1.4 为什么深度学习会兴起
推动深度学习变得如此热门的主要因素:数据规模、计算量以及算法的创新。
神经网络展示出的是,如果你训练一个小型的神经网络,那么这个性能可能会像下图黄色曲线;如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(下图蓝色曲线),它在某些数据上面的性能会更好一些;如果你训练一个非常大的神经网络,它会变成下图绿色曲线那样,并且保持变得越来越好。因此可以注意到两点:如果你想要获得较高的性能提现,那么你有两个条件要完成,第一个是你需要训练一个规模足够大的神经网络,以发挥数据规模巨大的优点,另外你需要能画到x轴的这个位置,所以你需要很多的数据。因此我们经常说规模一直在推动深度学习的进步,这里的规模指的也同时是神经网络的规模,我们需要一个带有许多隐藏单元的神经网络,也有许多的参数及关联性,就如同大规模的数据一样。事实上如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据,这只能在一定程度上起作用,因为最终你耗尽了数据,或者最终你的网络是如此大规模导致将要用太久的时间去训练,但这仅仅提升规模的的确确让我们在深度学习的世界中探索了很多时间。为了使这个图更加从技术上讲更精确一点,在x轴下面已经写明的数据量,这儿加上一个标签(label)量,通过添加这个标签量,也就是指在训练样本时,我们同时输入x和标签y,接下来引入一点符号,使用小写的字母m表示训练集规模,或者说训练样本的数量,这个小写字母m就横轴结合其他一些细节到这个图像中。
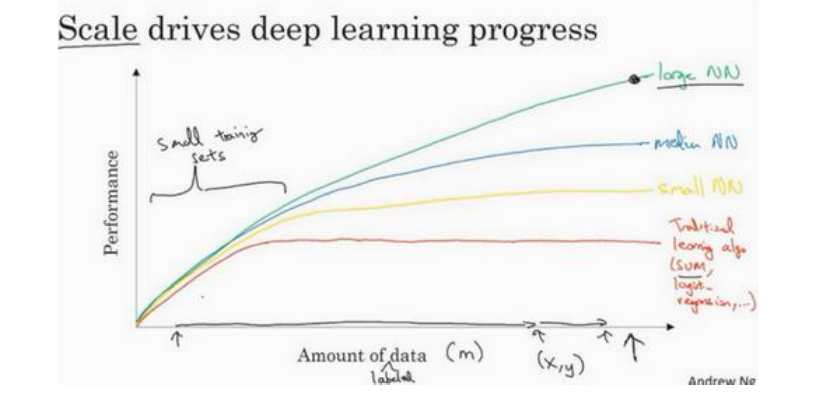
在图的左边,各种算法的优先级并不是定义的很明确,最终性能更多的是取决于你在用工程选择特征方面的以及算法处理方面的一些细节,只是在某些大数据规模非常庞大的训练集,也即是右边这个m会非常大时,我们能更加持续地看到更大的神经网络控制的其他方法。
所以可以这么说,在深度学习萌芽的初期,数据的规模以及计算量,局限在我们对于训练一个特别大的神经网络的能力,无论是在CPU还是GPU上面,那都使我们取得了巨大的进步。但是渐渐地,尤其是在最近几年,我们也见证了算法方面的极大创新。许多算法方面的创新,一直是在尝试着使得神经网络运行的更快。
训练你的神经网络的过程,很多时候是凭直觉的,往往你对神经网络构架有了一个想法,于是你尝试些代码实现你的想法,然后让你运行一个实验环境来告诉你,你的神经网络效果有多好,通过参考这个结果再返回去修改你的神经网络里面的一些细节,然后你不断的重复上面的操作,当你的神经网络需要很长时间去训练,需要很长时间重复这一循环,在这里就有很大区别,根据你的生产效率去构建更高效的神经网络。
1.5 关于这门课
这门课的细节:
第一周:关于深度学习的介绍。在一周的结尾也会有十多个选题来检验自己对材料的理解;
第二周:关于神经网络的编程知识,了解神经网络的结构,逐步完善算法并思考如何使得神经网络高效地实现。从第二周开始做一些编程训练,自己实现算法。
第三周:在学习了神经网络编程的框架后,你将可以编写一个隐藏层神经网络,所以需要学习所有必须的关键概念来实现神经网络的工作;
第四周:建立一个深层的神经网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号