1)本机系统设置
电脑设置虚拟缓存(设置为自动管理)

虚拟机设置内存和CPU
内存设置为8G(或以上)

CPU稍微设置高一点(三个虚拟化能开就开)

虚拟机系统配置阿里源
| wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo |
虚拟机更新包
| yum update |
(2)安装Docker
移除以前docker相关包
| sudo yum remove docker \ |
| docker-client \ |
| docker-client-latest \ |
| docker-common \ |
| docker-latest \ |
| docker-latest-logrotate \ |
| docker-logrotate \ |
| docker-engine |
添加yum源
| sudo yum install -y yum-utils | |
| sudo yum-config-manager \--add-repo \http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo |
安装docker
| sudo yum install -y docker-ce docker-ce-cli containerd.io |
启动Docker
| systemctl enable docker --now |
配置docker下载镜像
| sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF'{"registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"],"log-driver": "json-file","log-opts": {"max-size": "100m"},"storage-driver": "overlay2"}EOF sudo systemctl daemon-reload sudo systemctl restart docker |
(3)安装Hadoop
拉取hadoop镜像
docker pull registry.cn-shenzhen.aliyuncs.com/jonil/hadoop:base

(4)运行容器
指定docker内部网络
| docker network create --driver=bridge --subnet=172.19.0.0/16 hadoop(可配置也可不配置,因为docker启容器时会自己产生一个ip) |
创建时最好指定容器端口号映射。10000端口为hiveserver端口,后面本地客户端要通过beeline连接hive使用,有其他组件要安装的话可以提前把端口都映射出来,毕竟后面容器运行后再添加端口还是有点麻烦的。
建立Master容器
| docker run -it --network hadoop -h Master --name Master -p 9870:9870 -p 8088:8088 -p 10000:10000 registry.cn-shenzhen.aliyuncs.com/jonil/hadoop:base bash |
注意:标红处说明:如果你指定docker内部网络,那运行容器的时候就需要指定网络桥接,如果没有,就不需要增加
提示:CTRL + D 退出容器
docker exec -it [容器名] bash
建立Slave1容器
| docker run -it --network hadoop -h Slave1 --name Slave1 registry.cn-shenzhen.aliyuncs.com/jonil/hadoop:base bash |
建立Slave2容器
| docker run -it --network hadoop -h Slave2 --name Slave2 registry.cn-shenzhen.aliyuncs.com/jonil/hadoop:base bash |
三台机器修改hosts
| vim /etc/hosts |
| //修改为以下格式 172.17.0.2 Master 172.17.0.3 Slave1 172.17.0.4 Slave2 |
提示:每个容器的ip都需要通过命令ifconfig查看,或者在创建的时候通过‘ --ip ’指定ip地址
docker查看运行中的容器
docker ps
确保三个容器都在运行,不然后续的步骤无法进行,最好每个容器开一个终端

进入Master容器
| docker exec -it Master /bin/bash |
格式化hdfs
| hadoop namenode -format |
启动hadoop所有服务
| start-all.sh |
提示:虽然容器里面已经把 hadoop 路径配置在系统变量里面,但由于docker和linux的特殊性,每次进入需要运行以下命令才能生效使用。
| source /etc/profile |
每次重启docker或者机器重启,运行起来docker之后,一定要先执行一下:source /etc/profile

小黄象页面

文件网站

查看分布式文件分布状态
| hdfs dfsadmin -report |
运行结果
| Live datanodes (3): Name: 172.19.0.2:9866 (Master) Hostname: Master Decommission Status : Normal Configured Capacity: 19001245696 (17.70 GB) DFS Used: 4096 (4 KB) Non DFS Used: 7302295552 (6.80 GB) DFS Remaining: 11698946048 (10.90 GB) DFS Used%: 0.00% DFS Remaining%: 61.57% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sun Nov 07 02:27:39 GMT 2021 Last Block Report: Sun Nov 07 02:26:03 GMT 2021 Num of Blocks: 0 //其余节点省略 |
运行实例测试hadoop集群运行状况
分布式实例
| //创建目录 |
| hdfs dfs -mkdir -p /user/hadoop |
| //创建目录 |
| hdfs dfs -mkdir /input |
| //放置文件 |
| hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml /input |
| //运行mapreduce实例 |
| hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /input /output 'dfs[a-z.]+' |
| //查看结果 |
| hdfs dfs -cat /output/* |
运行结果
| 2021-11-07 02:45:31,924 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false |
| 1 dfsadmin |
| 1 dfs.replication |
| 1 dfs.namenode.name.dir |
| 1 dfs.namenode.data.dir |

(5)安装Hive
下载Hive-3.1.2
| https://dlcdn.apache.org/hive/hive-3.1.2/ |
将文件复制到虚拟机后上传到容器内
| docker cp apache-hive-3.1.2-bin.tar.gz Master:/usr/local |
进入Master容器,解压文件
| tar -zvxf apache-hive-3.1.2-bin.tar.gz |
修改配置文件
| cd /usr/local/apache-hive-3.1.2-bin/conf |
| cp hive-default.xml.template hive-site.xml |
| vim hive-site.xml |
追加文件内容,保存后退出
| <property> |
| <name>system:java.io.tmpdir</name> |
| <value>/tmp/hive/java</value> |
| </property> |
| <property> |
| <name>system:user.name</name> |
| <value>${user.name}</value> |
| </property> |

配置hive相关环境变量
| vim /etc/profile |
| export HIVE_HOME="/usr/local/apache-hive-3.1.2-bin" |
| export PATH=$PATH:$HIVE_HOME/bin |
最后刷新配置文件
| source /etc/profile |
(6)配置MySQL作为元数据库
拉取MySQL镜像
建立mysql容器(注意:这里的ip对应mysql_hive的ip)
| docker run --name mysql_hive -p 4306:3306 --net hadoop --ip 172.19.0.5 -v /root/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=abc123456 -d mysql:8.0.22 |
进入该容器
| docker exec -it mysql_hive bash |
进入mysql,密码是abc123456,可以在创建的时候通过“ -e MYSQL_ROOT_PASSWORD= ”更改
| mysql -uroot -p |
创建hive数据库
| create database hive; |
修改远程连接权限
| ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'abc123456'; |

返回Master容器
| docker exec -it Master bash |
修改关联数据库的配置
| vim /usr/local/apache-hive-3.1.2-bin/conf/hive-site.xml |
提示:hive配置文件里面使用 & 作为分隔,高版本mysql需要SSL验证,在这里设置关闭
- 设置数据库驱动
- 设置数据库地址
- 设置数据库用户
- 设置数据库密码
| <property> |
| <name>javax.jdo.option.ConnectionURL</name> |
| <value>jdbc:mysql://172.19.0.5:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> |
| <description>JDBC connect string for a JDBC metastore</description> |
| </property> |
| <property> |
| <name>javax.jdo.option.ConnectionDriverName</name> |
| <value>com.mysql.jdbc.Driver</value> |
| </property> |
| <property> |
| <name>javax.jdo.option.ConnectionUserName</name> |
| <value>root</value> |
| </property> |
| <property> |
| <name>javax.jdo.option.ConnectionPassword</name> |
| <value>abc123456</value> |
| </property> |
| <property> |
| <name>hive.metastore.schema.verification</name> |
| <value>false</value> |
| </property> |
下载MySQL驱动
| https://downloads.mysql.com/archives/c-j/ |
把下载的驱动解压,然后复制myslq驱动到hive的lib文件夹下
| docker cp mysql-connector-java-8.0.22.jar Master:usr/local/apache-hive-3.1.2-bin/lib |
确认jar包在对应的目录下

对hive的lib文件夹下部分文件做修改,防止初始化数据库的时候报错
slf4j这个包hadoop及hive两边只能有一个,这里删掉hive这边
| cd /usr/local/apache-hive-3.1.2-bin/lib |
| rm log4j-slf4j-impl-2.10.0.jar |
guava这个包hadoop及hive两边只删掉版本低的那个,把版本高的复制过去,这里删掉hive,复制hadoop的过去
| cd /usr/local/hadoop/share/hadoop/common/lib |
| cp guava-27.0-jre.jar /usr/local/apache-hive-3.1.2-bin/lib |
| rm /usr/local/apache-hive-3.1.2-bin/lib/guava-19.0.jar |
初始化元数据库
| cd /usr/local/apache-hive-3.1.2-bin/bin |
| ./schematool -dbType mysql -initSchema |

验证hive是否正确搭建
创建测试数据文件
| cd /usr/local |
| vim test.txt |
| //输入以下内容 |
| 1,jack |
| 2,ben |
| 3,sam |
进入hive交互界面
| hive |
创建表格
| create table test( |
| > id int,name string |
| > ) |
| > row format delimited |
| > fields terminated by ','; |

载入数据
| load data local inpath '/usr/local/test.txt' into table test; |
选择数据
| select * from test; |

注意:需要用外网的工具的连接需要下列操作:目录安装hadoop下(/usr/local/hadoop/etc/hadoop/core-site.xml)
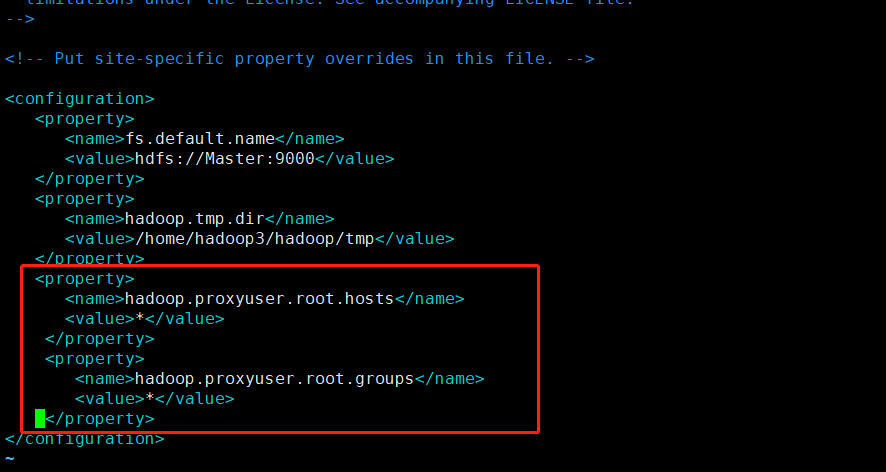
启动hive2: hive --service hiveserver2 &
(7)安装ZooKeeper
下载ZooKeeper
| https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/ |
在容器外复制到容器内
| docker cp apache-zookeeper-3.7.0-bin.tar.gz Master:/usr |
解压zookeeper压缩包
| tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz |
改名
| mv apache-zookeeper-3.7.0-bin/ zookeeper |
创建两个工作目录,并对两个工作目录进行权限开放
| cd /usr/zookeeper |
| mkdir zkdata |
| mkdir zkdatalog |
| chmod 777 zkdata |
| chmod 777 zkdatalog |
修改配置文件
| cd /usr/zookeeper/conf |
| mv zoo_sample.cfg zoo.cfg |
| vim zoo.cfg |
| //修改或追加以下内容 |
| dataDir=/usr/zookeeper/zkdata |
| dataLogDir=/usr/zookeeper/zkdatalog |
| server.1=Master:2888:3888 |
| server.2=Slave1:2888:3888 |
| server.3=Slave2:2888:3888 |
进入zkdata文件夹,创建文件myid
| cd zkdata |
| vim myid |
| 1 |
Slave1的myid为2
Slave2的myid为3


修改环境变量
| #zookeeper |
| export ZOOKEEPER_HOME=/usr/zookeeper |
| export PATH=$PATH:$ZOOKEEPER_HOME/bin |
刷新环境变量
| source /etc/profile |
其他两个容器也执行以上操作



启动zookeeper集群
| zkServer.sh start |
查看zookeeper集群状态
| zkServer.sh status |
关闭zookeeper集群
| zkServer.sh stop |



至此zookeeper安装完成
(8)安装HBase
下载HBase
| http://archive.apache.org/dist/hbase/2.2.6/ |
复制HBase镜像到Master容器
| docker cp hbase-2.2.6-bin.tar.gz Master:/usr/local |
配置HBase环境变量
| docker exec -ti Master bash |
| vim /etc/profile |
| 追加以下内容 |
| #hbase |
| export HBASE_HOME=/usr/local/hbase |
| export PATH=$HBASE_HOME/bin:$PATH |
刷新源文件
| source /etc/profile |

复制/usr/local/hadoop/etc/hadoop下的core-site.xml和hdfs-site.xml到/usr/local/hbase/conf文件夹下
| cd /usr/local/hadoop/etc/hadoop |
| cp core-site.xml /usr/local/hbase/conf/ |
| cp hdfs-site.xml /usr/local/hbase/conf/ |
| cd /usr/local/hbase/conf |
| vim hbase-site.xml |
配置hbase-site.xml
提示:hbase.zookeeper.property.dataDir这里配置自己的文件地址,不要直接复制这里的
| <property> |
| <name>hbase.rootdir</name> |
| <value>hdfs://Master:9000/hbase</value> |
| </property> |
| <property> |
| <name>hbase.cluster.distributed</name> |
| <value>true</value> |
| </property> |
| <property> |
| <name>hbase.zookeeper.quorum</name> |
| <value>Master,Slave1,Slave2</value> |
| </property> |
| <property> |
| <name>hbase.zookeeper.property.dataDir</name> |
| <value>/usr/zookeeper/zkdata</value> |
| </property> |
| <property> |
| <name>hbase.unsafe.stream.capability.enforce</name> |
| <value>false</value> |
| </property> |
| <property> |
| <name>hbase.master</name> |
| <value>hdfs://Master:6000</value> |
| </property> |

设置hbase的JAVA_HOME和zookeeper
| cd /usr/local/hbase/conf |
| vim hbase-env.sh |
| //修改或追加以下内容 |
| //如果你用自己安装的zookeeper,这里设置为false(反之为true),但是启动之前要先启动zookeeper集群 |
| export HBASE_MANAGES_ZK=false |
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 |


移除冲突jar包,防止报错
| cd /usr/local/hbase/lib/client-facing-thirdparty/ |
| //可以直接rm删除,也可以mv改名,我这里选择改名 |
| mv slf4j-log4j12-1.7.25.jar slf4j-log4j12-1.7.25.jar.bak |
其他容器进行相同操作(省略)
调试一下hbase看看能不能运行
| start-all.sh |
| start-hbase.sh |
| hbase shell |
尝试创建个test表
| hbase(main):001:0> create 'test','id' |
| Created table test |
| Took 3.9776 seconds |
| => Hbase::Table - test |
(9)安装Scala
下载scala
| https://www.scala-lang.org/download/2.12.12.html |
复制到docker容器内
| docker cp scala-2.12.12.tgz Master:/usr/local/ |
解压scala压缩包
| tar -zxvf scala-2.12.12.tgz |
配置环境变量
| vim /etc/profile |
| //追加以下内容 |
| #scala |
| export SCALA_HOME=/usr/local/scala-2.12.12 |
| export PATH=$SCALA_HOME/bin:$PATH |

刷新环境变量
| source /etc/profile |
查看Scala版本
| scala -version |
| Scala code runner version 2.12.12 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc. |
(10)安装Spark
下载Spark
| http://archive.apache.org/dist/spark/spark-3.0.1/ |
复制Spark压缩包到容器
| docker cp spark-3.0.1-bin-hadoop3.2.tgz Master:/usr/local |
进入容器,解压spark压缩包
| tar -zxvf spark-3.0.1-bin-hadoop3.2.tgz |
文件夹改名
| mv spark-3.0.1-bin-hadoop3.2 spark-3.0.1 |
mv spark-3.0.1-bin-hadoop3.2 spark-3.0.1
| cd /usr/local/spark-3.0.1/conf |
| cp spark-env.sh.template spark-env.sh |
| vim spark-env.sh |
| //修改或追加以下内容 |
| #spark |
| export SPARK_MASTER_HOST=Master |
| export SPARK_MEM=1G |
| export SPARK_MASTER_PORT=7077 |
| export SPARK_WORKER_MEMORY=1G |
| #java |
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 |
| export SCALA_HOME=/usr/local/scala-2.12.12 |
| #hadoop |
| export HADOOP_HOME=/usr/local/hadoop |
| export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop |
| export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native |
修改slaves文件
| cp slaves.template slaves |
| vim slaves |
| //修改如下 |
| Slave1 |
| Slave2 |

配置Spark环境变量
| vim /etc/profile |
| //追加以下内容 |
| #spark |
| export SPARK_HOME=/usr/local/spark-3.0.1 |
| export PATH=$SPARK_HOME/bin:$PATH |
刷新源文件
| source /etc/profile |
其他节点也如上配置spark
最后在Master节点启动Spark
| start-all.sh |


运行简单操作
| val textFile = sc.textFile("file:///usr/local/spark-3.0.1/README.md") |
| //scala操作 |
| //获取RDD文件textFile的第一行内容 |
| textFile.first() |
| //获取RDD文件textFile所有项的计数 |
| textFile.count() |
| //抽取含有“Spark”的行,返回一个新的RDD |
| val lineWithSpark = textFile.filter(line => line.contains("Spark")) |
| //统计新的RDD的行数 |
| lineWithSpark.count() |
| //找出文本中每行的最多单词数 |
| textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) |
| //退出spark-shell |
| :quit |

关闭所有程序
| stop-all.sh |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号