
从零开始学Flink:Flink SQL 极简入门
 无需Java/Scala代码!本文基于Flink 1.20.1版本,手把手教你在WSL2 Ubuntu环境下搭建开发环境,使用SQL Client体验实时流计算的魅力,轻松跑通第一个数据流任务。
无需Java/Scala代码!本文基于Flink 1.20.1版本,手把手教你在WSL2 Ubuntu环境下搭建开发环境,使用SQL Client体验实时流计算的魅力,轻松跑通第一个数据流任务。
Flink SQL 是 Apache Flink 的核心模块之一,它让开发者可以使用标准的 SQL 语法来编写流处理和批处理作业。对于不想深究 Java/Scala 复杂 API 的“小白”来说,Flink SQL 是进入实时计算领域的最佳敲门砖。
本文将基于 Flink 1.20.1 版本,手把手教你在 WSL2 (Ubuntu) 环境下搭建环境,并运行你的第一个 Flink SQL 任务。
一、为什么选择 Flink SQL?
- 低门槛:会写 SQL 就能开发实时任务。
- 统一性:批流一体,同一套 SQL 既可以跑历史数据(批),也可以跑实时数据(流)。
- 生态丰富:内置了大量的 Connector(连接器),轻松连接 Kafka、MySQL、Hive 等主流组件。
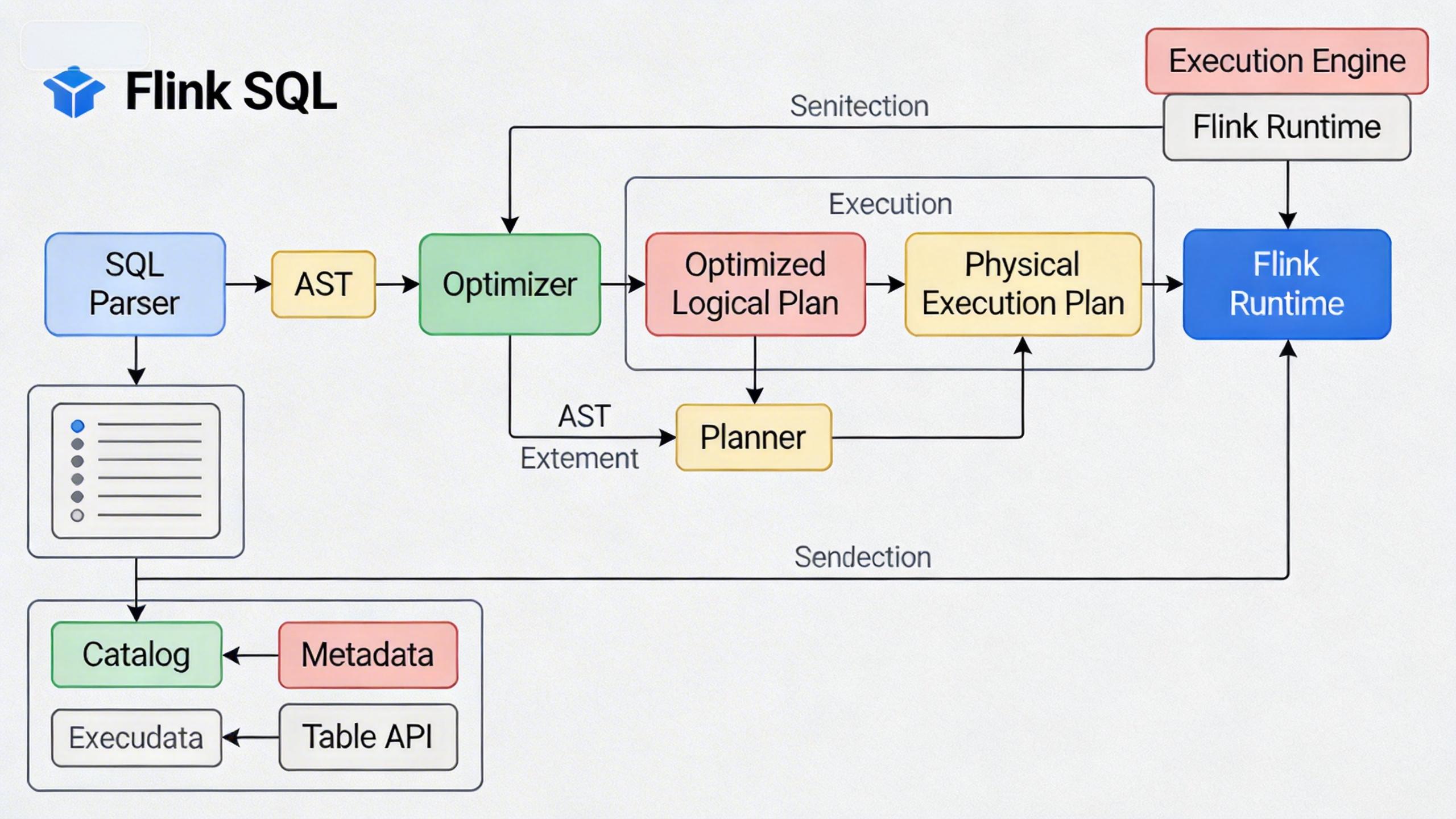
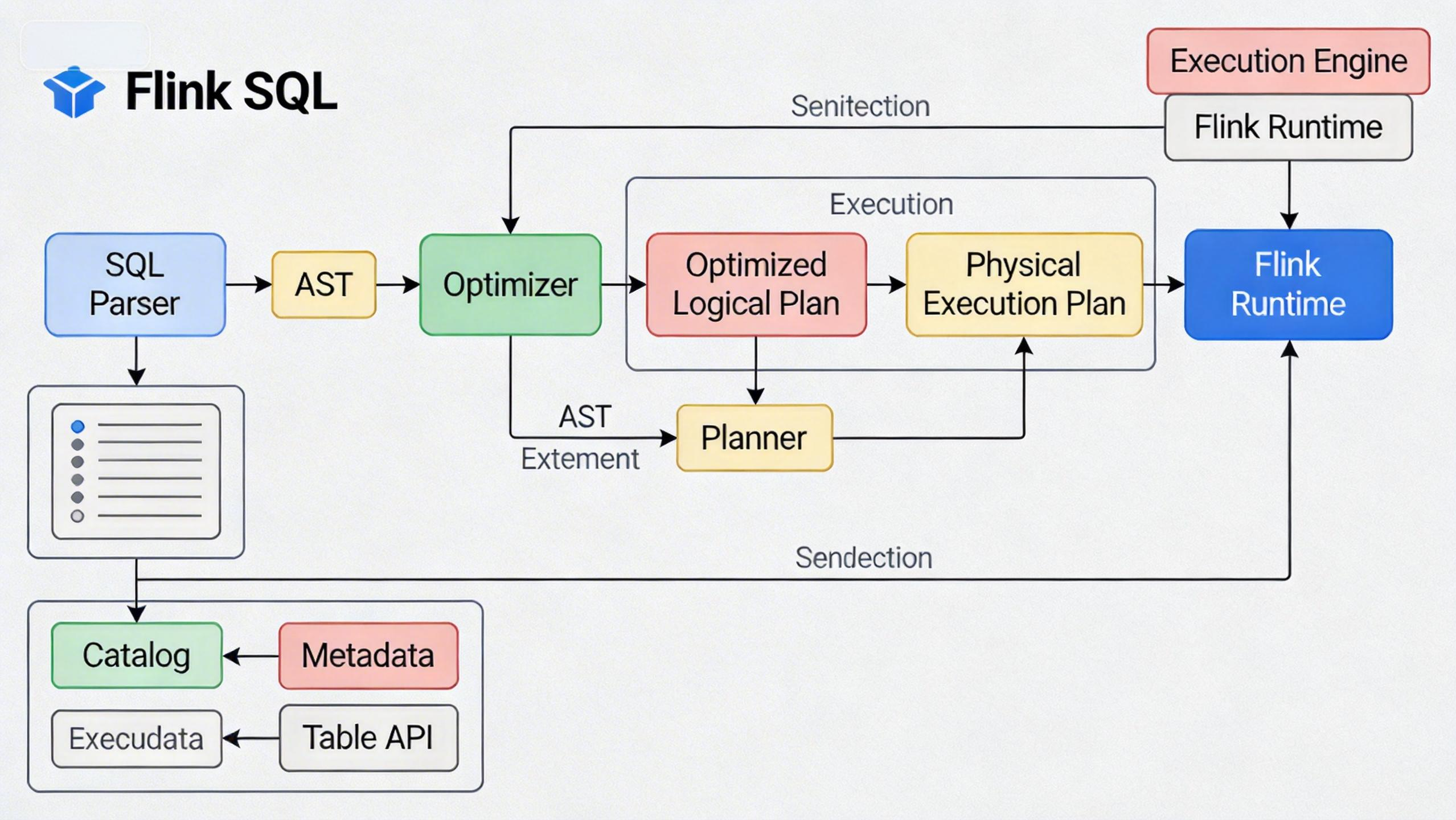
(图:Flink SQL 架构示意图,展示 SQL 解析、优化到执行的过程)
二、环境准备 (WSL2 Ubuntu)
本教程演示环境为 Windows 下的 WSL2 (Ubuntu 20.04/22.04),这是目前 Windows 用户体验 Linux 开发环境的最佳姿势。
参考以前些的文章从零开始学Flink:揭开实时计算的神秘面纱,搭建好 Flink 环境。
三、体验 Flink SQL Client
Flink 提供了一个交互式的命令行工具:SQL Client。它允许你直接在终端编写和提交 SQL 任务。
1. 启动 SQL Client
如果没有启动Flink集群,则先启动flink集群:
./bin/start-cluster.sh
,然后在 Flink 目录下执行:
./bin/sql-client.sh
你将看到那只著名的松鼠 LOGO:
(图:SQL Client 启动欢迎界面)
2. Hello World:数据生成与打印
我们不依赖任何外部组件(如 Kafka),直接使用 Flink 内置的 datagen 连接器生成模拟数据,并用 print 连接器打印结果。
第一步:创建源表 (Source Table)
复制以下 SQL 到 SQL Client 中执行:
CREATE TABLE source_table (
id INT,
name STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen', -- 使用数据生成器
'rows-per-second' = '1', -- 每秒生成1条数据
'fields.id.kind' = 'sequence', -- id 字段为序列
'fields.id.start' = '1', -- id 从1开始
'fields.id.end' = '100' -- id 到100结束
);
执行后显示 [INFO] Execute statement succeed.。
第二步:创建结果表 (Sink Table)
CREATE TABLE print_table (
id INT,
name STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'print' -- 使用控制台打印连接器
);
第三步:提交任务
将源表的数据插入到结果表:
INSERT INTO print_table SELECT * FROM source_table;
此时,SQL Client 会提交一个异步任务到集群。你会看到类似 Job ID 的输出。
3. 查看运行结果
由于我们使用的是 print 连接器,在 Standalone 模式下,输出会打印到 TaskManager 的日志文件中。
打开一个新的 WSL2 终端窗口,进入 Flink 目录查看日志:
# 进入 log 目录
cd log
# 查看最新的 .out 文件 (文件名包含 taskexecutor)
tail -f flink-*-taskexecutor-*.out
你应该能看到屏幕上不断跳动的数据流:
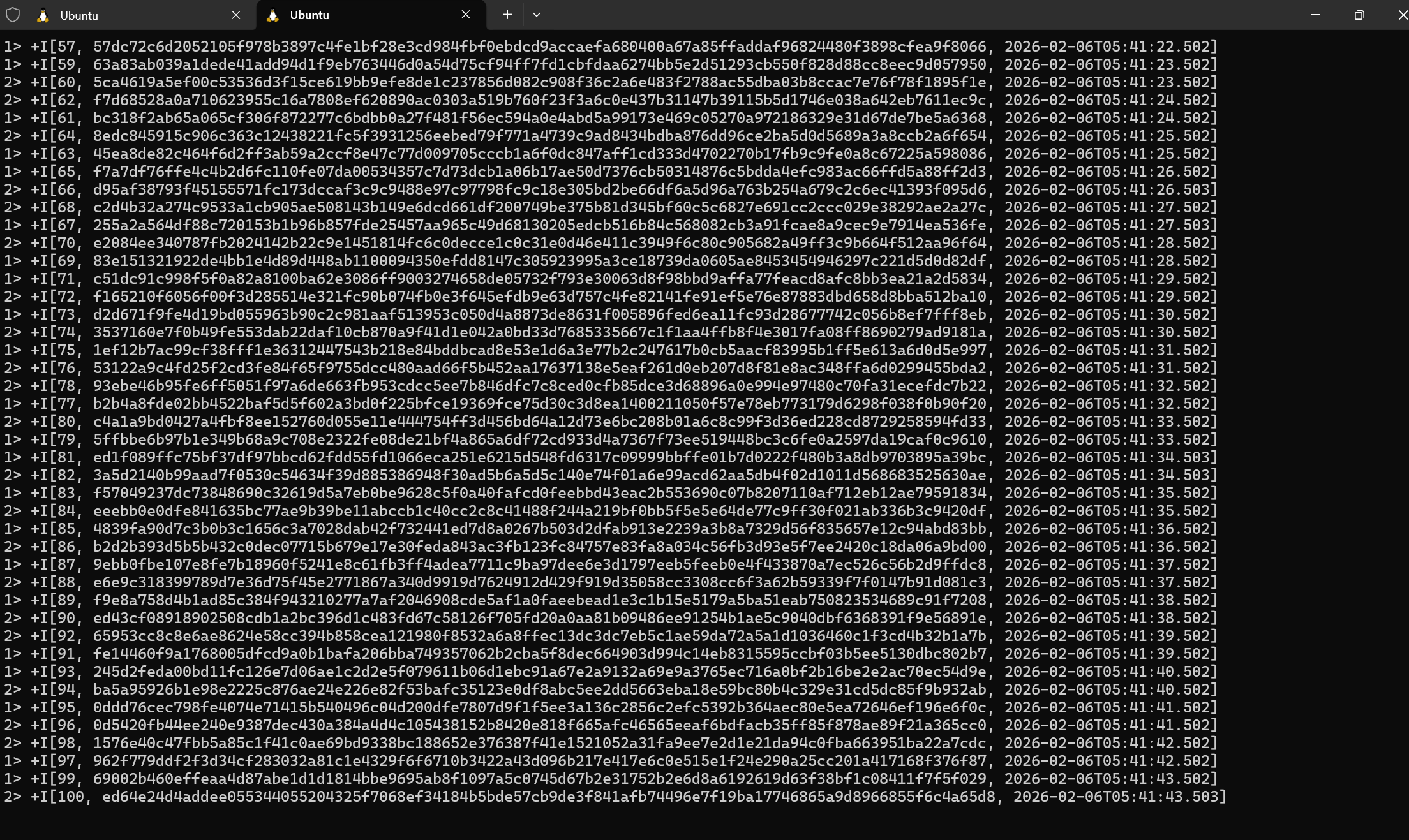
(图:终端 tail -f 命令看到的实时数据输出)
四、常用命令速查
在 SQL Client 中,你可以使用以下命令:
HELP: 查看帮助。SHOW TABLES: 查看当前创建的表。SHOW JOBS: 查看运行中的作业。DESCRIBE table_name: 查看表结构。QUIT: 退出 SQL Client。
五、总结
恭喜你!你已经成功运行了人生中第一个 Flink SQL 任务。
通过本文,我们完成了:
- WSL2 下 Java 和 Flink 1.20.1 的安装。
- 启动了 Flink 本地集群。
- 使用 SQL Client 创建了 Source 和 Sink 表,并跑通了数据流。
下一篇,我们将深入讲解 Flink SQL 中的窗口(Window)操作,看看如何处理“过去5分钟的订单总额”这类经典需求。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号