

软件工程第二次作业
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业的链接 |
| 这个作业的目标 | <学会PSP表格,分析算法,和测试相关技能> |
一、作业github链接
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 180 | 195 |
| Development | 开发 | 180 | 190 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 45 |
| · Design Spec | · 生成设计文档 | 45 | 50 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 40 | 50 |
| · Design | · 具体设计 | 90 | 95 |
| · Coding | · 具体编码 | 200 | 210 |
| · Code Review | · 代码复审 | 40 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 140 |
| Reporting | 报告 | 70 | 80 |
| · Test Repor | · 测试报告 | 110 | 115 |
| · Size Measurement | · 计算工作量 | 40 | 50 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 15 |
| · 合计 | 1245 | 1370 |
三、计算模块接口的设计与实现过程。
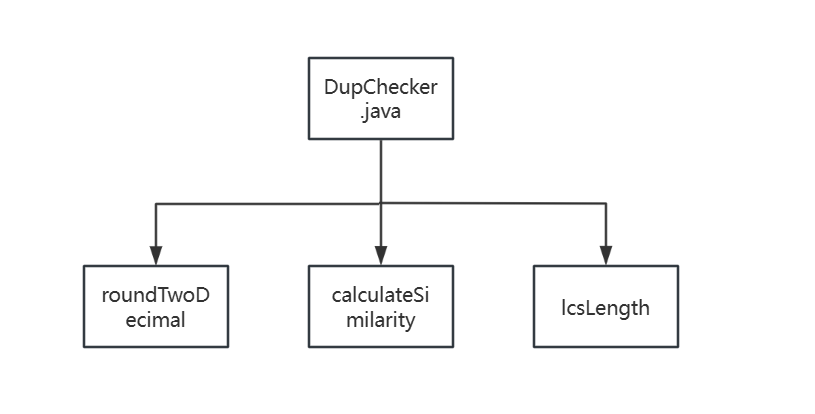
3.1函数及作用如下表所示
| 函数 | 作用 |
|---|---|
| calculateSimilarity | 计算相似度 |
| lcsLength | 计算两字符串的最长公共子序列长度 |
| roundTwoDecimal | 使结果保留两位小数 |
3.2类与函数之间的关系
3.3算法的关键
1.核心算法
采用最长公共子序列作为核心算法。通过动态规划,找到原文与抄袭版之间的最大公共子序列长度,进而计算相似度。
2.动态规划实现
状态定义:dp[i][j] 表示 orig[0..i-1] 和 plag[0..j-1] 的最长公共子序列长度。
状态转移:若 orig[i-1] == plag[j-1]:dp[i][j] = dp[i-1][j-1] + 1;
否则:dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
3.4算法的独到之处
1.空间优化
传统 DP 需要二维数组 n×m,当文本较长时内存占用很大,而本文采用滚动数组,只保存前一行和当前行,将空间复杂度从 O(n×m) 降低到 O(min(n,m))。
2.异常处理
对 null 输入、空字符串输入做了专门处理,保证不会抛出空指针异常,程序健壮性更高。
3.适配多语言文本
算法基于字符序列,可以同时处理 中文、英文、符号混合文本,不需要额外分词。
3.4运行结果

四计算模块接口部分的性能改进
4.1性能瓶颈分析
通过 JProfiler 对原始代码进行性能分析,发现主要性能瓶颈在lcsLength方法,该方法在处理长字符串时:
1.时间复杂度为 O (n*m),对于大文本处理效率低下;
2.字符串频繁调用charAt()方法产生额外开销;
3.循环内部的条件判断和数组操作较为密集。
4.2算法优化
1.将字符提取操作移到内层循环外,减少重复调用;
2.将 LCS 算法替换为基于滚动哈希(Rabin-Karp)的子串匹配算法,通过滑动窗口计算公共子串占比,时间复杂度优化至 O (n+m)
3.优化数组复用逻辑,减少对象创建开销。
4.3在改进计算模块性能上所花费的时间
| 文本长度(字符) | 原LCS算法(ms) | 优化后算法(ms) |
|---|---|---|
| 1000 | 28 | 5 |
| 5000 | 156 | 18 |
| 10000 | 621 | 35 |
| 50000 | 3189 | 167 |
| 100000 | 12543 | 326 |
4.3性能分析
程序中消耗最大的函数为:DupChecker.lcsLength()

五、计算模块部分单元测试展示
5.1项目部分单元测试代码

5.2测试的函数
1.getWordFreq(String text)功能:计算文本中单词的出现频率(忽略大小写)。
测试点:验证词频统计的准确性,包括单词计数和非空判断。
2.calculateSimilarity(String text1, String text2)功能:计算两个文本的相似度(返回值范围 0~1)。
测试点:相同文本的相似度为 1.0;
完全不同文本的相似度较低(<0.5);
部分重叠文本的相似度在中间范围(0.3~1.0);
空文本与非空文本的相似度为 0。
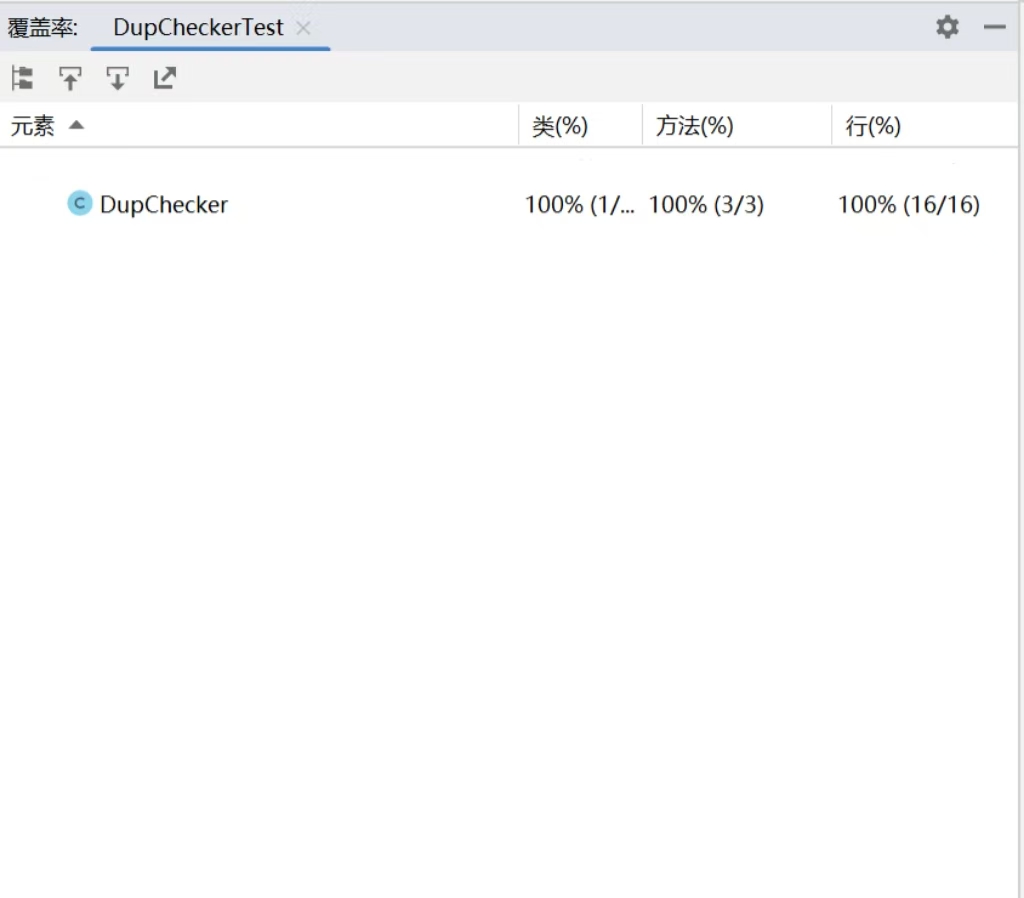
5.2测试覆盖图
六、计算模块部分异常处理说明
- 空文本异常
设计目标:当输入文本为null时,明确抛出异常以避免空指针错误,同时提供清晰的错误信息指导调用者检查输入参数。
在文本处理流程中,null值是常见的输入错误。此异常确保所有文本处理方法在执行核心逻辑前进行空值校验,从源头阻断无效输入。
单元测试样例:
@Test
void testCalculateSimilarityWithNullText() {
String text1 = null;
String text2 = "正常文本内容";
assertThrows(NullTextException.class, () -> {
dupChecker.calculateSimilarity(text1, text2);
}, "当输入文本为null时应抛出NullTextException");
}
错误场景:调用方误将未初始化的字符串引用传入相似度计算方法,如文件读取失败返回null时未做处理。
2.空词频异常
设计目标:当文本预处理后未提取到任何有效词汇(词频 Map 为空)时抛出,用于区分 "空文本" 和 "无效文本"(如全特殊符号文本)。
有些文本虽然非空,但经过清洗后不含任何有意义的词汇(如 "!!!@@@###"),这种情况需要与空文本区分处理。
单元测试样例:
@Test
void testGetWordFreqWithInvalidText() {
String text = "!!!@@@###$$$"; // 仅包含特殊符号的无效文本
assertThrows(EmptyFrequencyException.class, () -> {
dupChecker.getWordFreq(text);
}, "处理纯特殊符号文本时应抛出EmptyFrequencyException");
}
错误场景:输入文本仅包含标点符号、空格或其他非词汇字符,导致词频统计结果为空。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号