MySQL 自增主键用完了怎么办?
自增主键用完的后果:当自增 ID 达到数据类型的最大值后,再次插入数据会报错 Duplicate entry 'xxx' for key 'PRIMARY',新的数据无法写入。
各整数类型的主键容量:
| 数据类型 | 字节数 | 最大值 | 容量级 |
|---|---|---|---|
TINYINT |
1 | 127(有符号)/ 255(无符号) | 百级 |
SMALLINT |
2 | 32767 / 65535 | 万级 |
MEDIUMINT |
3 | 8388607 / 16777215 | 百万级 |
INT |
4 | 2147483647 / 4294967295 | 21 亿 / 42 亿 |
BIGINT |
8 | 9223372036854775807 / ... | 922 亿亿 |
一句话总结:主键用完会导致插入失败,解决方案有 改用更大的类型(BIGINT) 或 使用分布式 ID(雪花算法)。
深度解析
一、自增主键用完会发生什么?
当自增 ID 达到上限后,MySQL 的行为如下:
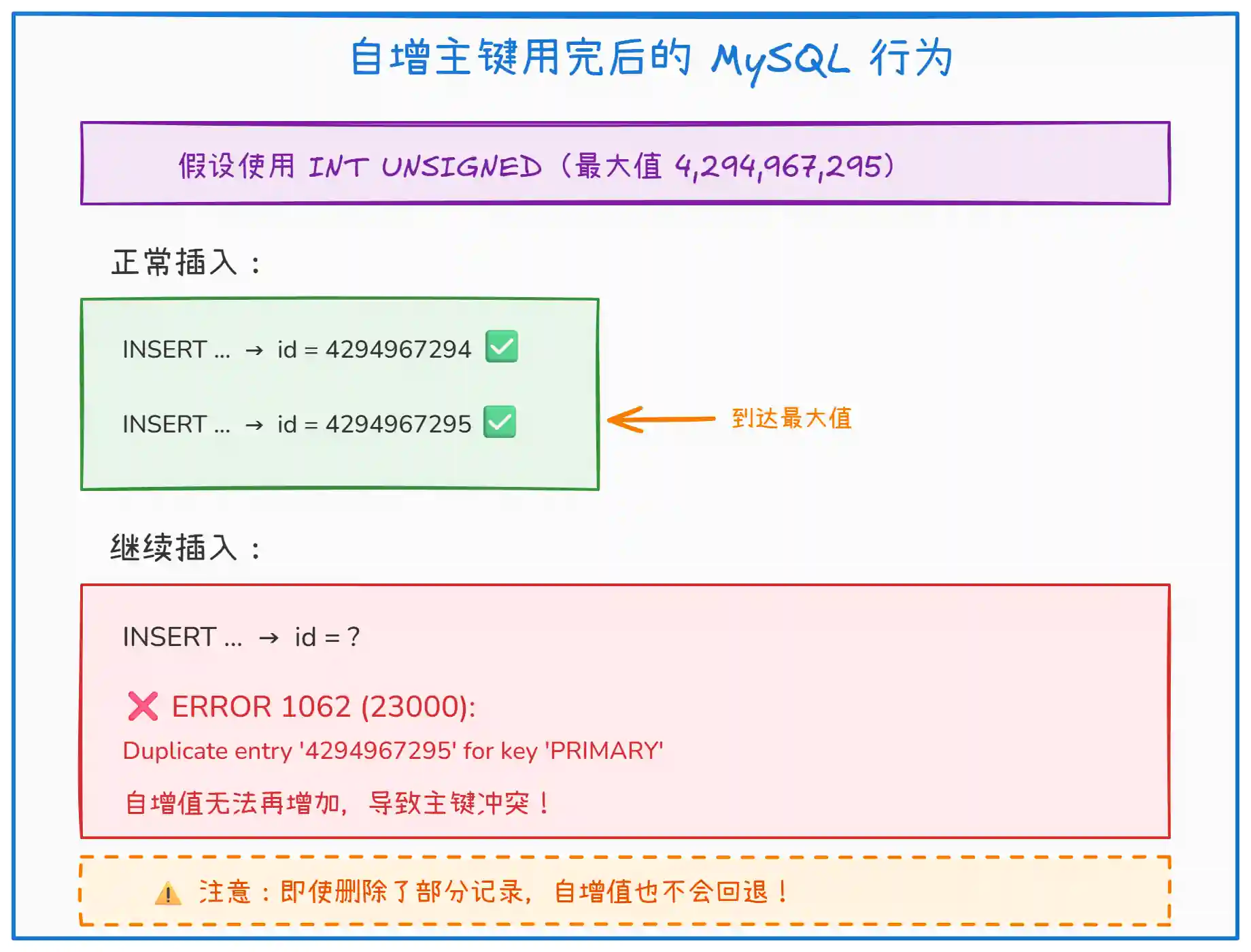
上图展示了自增主键用完后的情况。关键点说明:
- 自增到最大值:当
AUTO_INCREMENT达到数据类型的上限时,无法继续递增 - 插入失败:MySQL 尝试使用最大值插入,但该值已存在,导致主键冲突
- 删除不回退:即使删除了中间的记录,
AUTO_INCREMENT值也不会变小 - 影响范围:所有依赖自增主键的插入操作都会失败
二、解决方案一:改用更大的数据类型
最简单直接的方案:将 INT 改为 BIGINT。
-- 修改前:INT 最大约 21 亿(有符号)或 42 亿(无符号)
CREATE TABLE orders (
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
order_no VARCHAR(32)
);
-- 修改后:BIGINT 最大约 922 亿亿
ALTER TABLE orders MODIFY id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY;BIGINT 有多大?

注意事项:
- 修改字段类型会锁表,大表操作需要谨慎(使用
pt-online-schema-change等工具) - 建议新表设计时就直接使用
BIGINT,省去后续迁移的麻烦
三、解决方案二:使用分布式 ID —— 雪花算法(Snowflake)
对于分布式系统,单机自增主键不够用或存在冲突风险,推荐使用 雪花算法 生成分布式 ID。
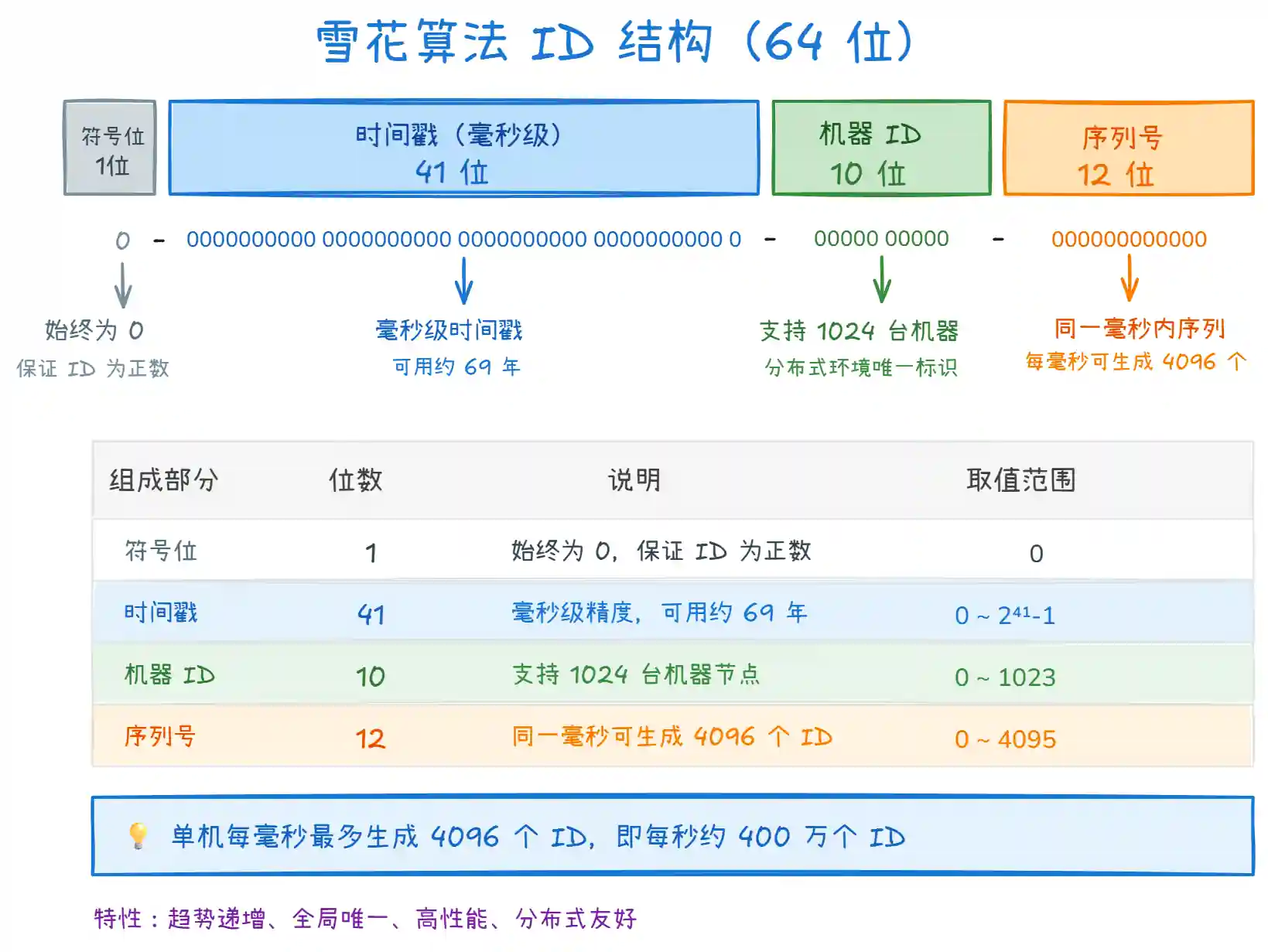
上图展示了雪花算法的 ID 结构。核心优势在于:
- 全局唯一:通过机器 ID 区分不同节点,保证分布式环境下的唯一性
- 趋势递增:基于时间戳生成,ID 大致按时间递增,利于索引
- 高性能:本地生成,不依赖数据库,单机每秒可生成 400 万个 ID
- 无需协调:各节点独立生成,不需要分布式锁或中心化服务
Java 实现示例:
public class SnowflakeIdGenerator {
// 起始时间戳(2024-01-01)
private final long twepoch = 1704038400000L;
// 机器 ID 所占位数
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
// 序列号所占位数
private final long sequenceBits = 12L;
// 机器 ID 最大值:31
private final long maxWorkerId = ~(-1L << workerIdBits);
// 序列号最大值:4095
private final long sequenceMask = ~(-1L << sequenceBits);
// 机器 ID 左移位数
private final long workerIdShift = sequenceBits;
// 时间戳左移位数
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final long workerId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("worker Id error");
}
this.workerId = workerId;
}
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
// 时钟回拨检测
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards!");
}
// 同一毫秒内,序列号递增
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 序列号溢出,等待下一毫秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// 组装 ID
return ((timestamp - twepoch) << timestampLeftShift)
| (workerId << workerIdShift)
| sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}
四、各种 ID 生成方案对比
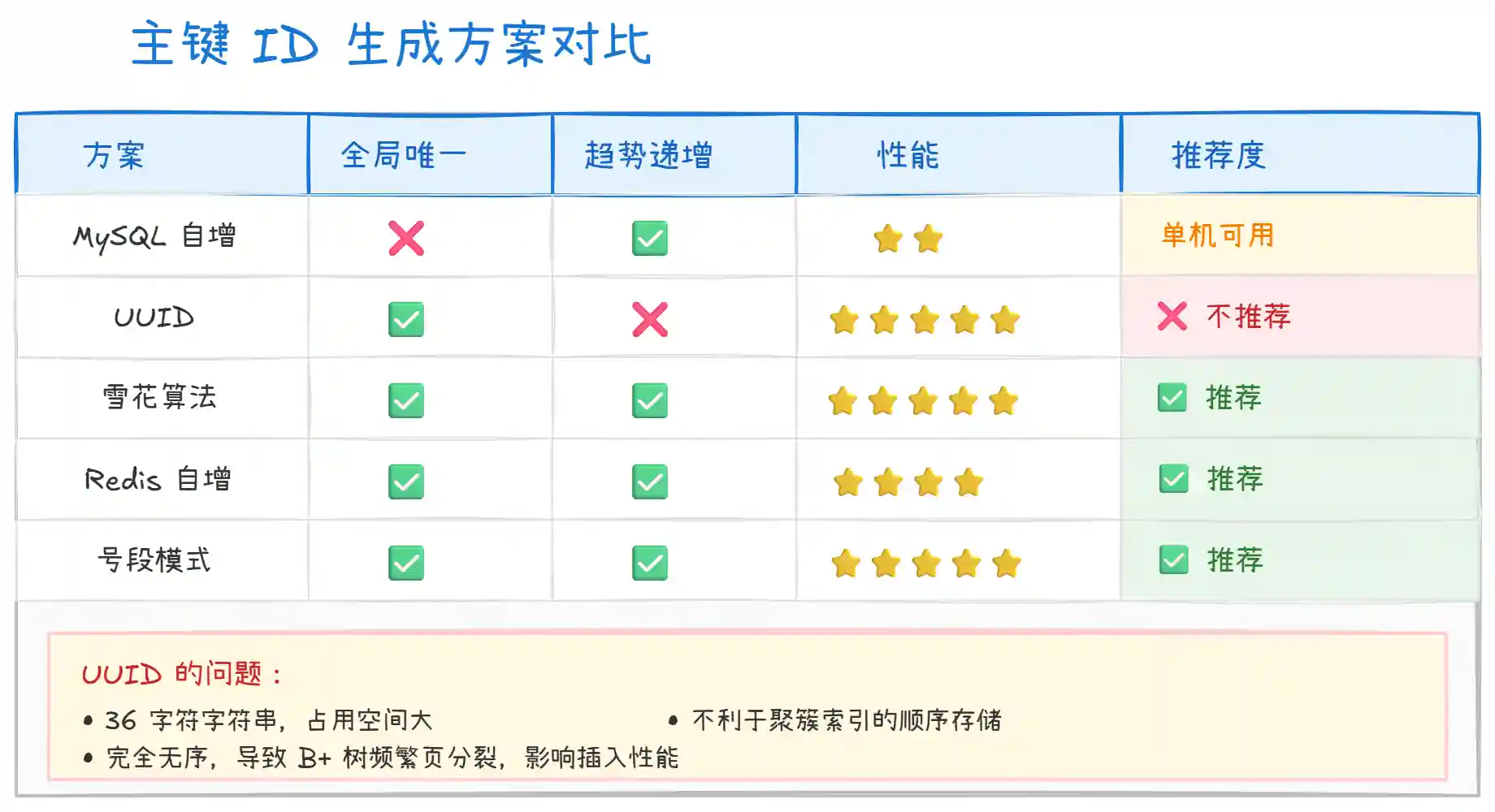
为什么 UUID 不推荐作为主键?
- 页分裂问题:UUID 是无序的,插入时会导致 B+ 树频繁分裂
- 存储空间大:36 字符 vs 8 字节的 BIGINT
- 索引效率低:无序 ID 导致缓存命中率下降
五、最佳实践建议
1. 新表设计直接用 BIGINT
-- 推荐写法
CREATE TABLE orders (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
-- 其他字段...
) ENGINE=InnoDB;2. 分布式系统用雪花算法
// 使用成熟的开源实现
// 如:Mybatis-Plus 的 IdWorker、百度 UidGenerator、美团 Leaf
@IdType(type = IdType.ASSIGN_ID) // Mybatis-Plus 雪花算法
private Long id;3. 设置合理的自增起始值和步长
-- 多主架构下,避免 ID 冲突
-- 服务器 1:起始值 1,步长 2(生成 1, 3, 5, ...)
SET GLOBAL auto_increment_offset = 1;
SET GLOBAL auto_increment_increment = 2;
-- 服务器 2:起始值 2,步长 2(生成 2, 4, 6, ...)
SET GLOBAL auto_increment_offset = 2;
SET GLOBAL auto_increment_increment = 2;
 浙公网安备 33010602011771号
浙公网安备 33010602011771号