Spark Streaming学习笔记
Spark Streaming 编程学习笔记
简介
spark stream 基于spark 核心API扩展而来,提供了一种具有规模可伸缩、高吞吐、错误恢复的处理实时数据流的流式处理方法。数据来源可以从本地文件,hadoop等接受,可以使用该机函数类似map、reduce、window等函数进行处理。数据结果同样可以进行多种形式的存储。

在spark stream内部,将接收到的实时数据进行切分成不同的数据段,然后处理引擎对一个个的数据快进行处理然后输出相应的结果。
这个地方有点疑问:如果原始数据被切分开,比如说,原始数据是“Hello, my boys", 但是在spark数据接收端对数据块进行切分时,从中间切分开来使"Hello"和", my boys"成为了两个数据块,这内部怎么保证切分永远是合理的??
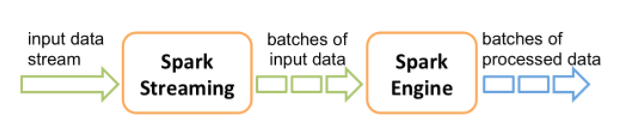
上面的流程图中的batches,spark将其抽象成一种数据结构叫做DStream(discretized stream),Dstream既可以有输入的实时数据流创建,也可以由其他的函数对已有的DStream操作后得到。DStream在spark内部就是一系列的RDD的集合。
一个简单的例子
以下的例子是一个简单的wordCount的程序,改程序从TCP端口接收数据,然后统计接受到数据的文字的个数。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
//采用的核数至少要大于1,否则spark没有办法去一边接受数据一边处理数据,会报错block input --- instead 0 peers,表示spark没有足够资源
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1)) //对于使用交互模式的,由于只能有一个SparkContext, 此时可以采用 val ssc = new StreamingContext(sc, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
基础概念
初始化SparkStreaming
SparkStreaming 对象是整个spark实时数据处理的入口点,初始化的方法可以使用SparkConf作为参数进行创建:
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
需要注意的是,上述的初始化过程中同样生成了一个SparkContext对象,此对象可以通过ssc.sparkContext进行访问,同样在交互模式中由于默认已经存在一个SparkContext对象,因此初始化StreamingContext的话可以采用上面的例子中的方式
未完,明日继续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号