
统计学习方法--提升树模型(Boosting Tree)与梯度提升树(GBDT)
1、主要内容
介绍提升树模型以及梯度提升树的算法流程
2、Boosting Tree
提升树模型采用加法模型(基函数的线性组合)与前向分步算法,同时基函数采用决策树算法,对待分类问题采用二叉分类树,对于回归问题采用二叉回归树。提升树模型可以看作是决策树的加法模型:
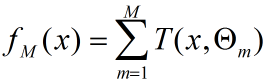
其中T()表示决策树,M为树的个数, Θ表示决策树的参数;
提升树算法采用前向分部算法。首先确定f0(x) = 0,第m步的模型是:
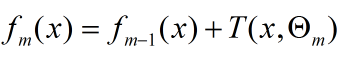
对决策树的参数Θ的确定采用经验风险最小化来确定:
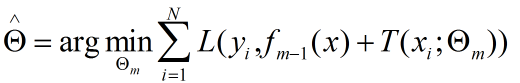
对于不同的问题采用的损失函数不同,在决策树中使用的就是0/1损失函数,这部分的推导和前面的adaBoost中的关于分类的推导相同,不做详细介绍。对与回归问题来说,一般采用平方误差函数。
对于回归问题,关于回归树的生成可以参考CART算法中回归树的生成。对于以下问题:
输入:
输出:fM(x)
对于一颗回归树可以表示为:
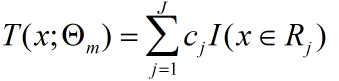
那么在前向分步算法的第m步中也就是求解第m个回归树模型时,为了确定参数需要求解:
当采用平方误差损失函数时,损失函数为:
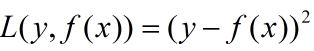
将上面的待求解式子带入到下面的平方误差函数中可以得到以下表达式:
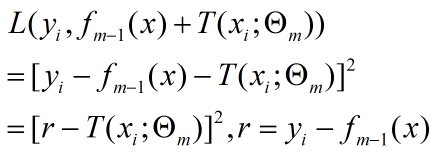
这就表明每一次进行回归树生成时采用的训练数据都是上次预测结果与训练数据值之间的残差。这个残差会逐渐的减小。
算法流程:
(1)、初始化f0(x) = 0;
(2)、对于m=1,2,...,M
(a)按照 r= yi - fm-1(x)计算残差作为新的训练数据的 y
(b) 拟合残差 r 学习一颗回归树,得到这一轮的回归树![]()
(c) 更新 ![]()
(3) 得到回归提升树:
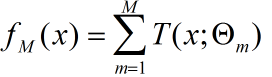
3、GBDT梯度提升树
对于梯度提升树其学习流程与提升树类似只是不再使用残差作为新的训练数据而是使用损失函数的梯度作为新的新的训练数据的y值,具体的来说就是使用损失函数对f(x)求梯度然后带入fm-1(x)计算:
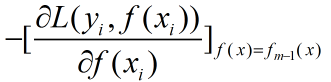
GDBT与提升树之间的关系:
提升树模型每一次的提升都是靠上次的预测结果与训练数据的label值差值作为新的训练数据进行重新训练,GDBT则是将残差计算替换成了损失函数的梯度方向,将上一次的预测结果带入梯度中求出本轮的训练数据,这两种模型就是在生成新的训练数据时采用了不同的方法,那么在这个背后有啥区别?使用残差有啥不好?
李航老师《统计学习方法》中提到了在使用平方误差损失函数和指数损失函数时,提升树的残差求解比较简单,但是在使用一般的损失误差函数时,残差求解起来不是那么容易,所以就是用损失函数的负梯度在当前模型的值作为回归问题中残差的近似值。 这是不是说一般的损失函数的梯度也得好求才可以啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号