20204314 2020-2021 《Python程序设计》实验四报告
20204314 2020-2021《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2043
姓名: 钟浩然
学号:20204314
实验教师:王志强
实验日期:2021年6月24日
必修/选修: 公选课
一、实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
二、实验过程
1.网络爬虫实战
抓取豆瓣电影Top250电影信息。
url:https://movie.douban.com/top250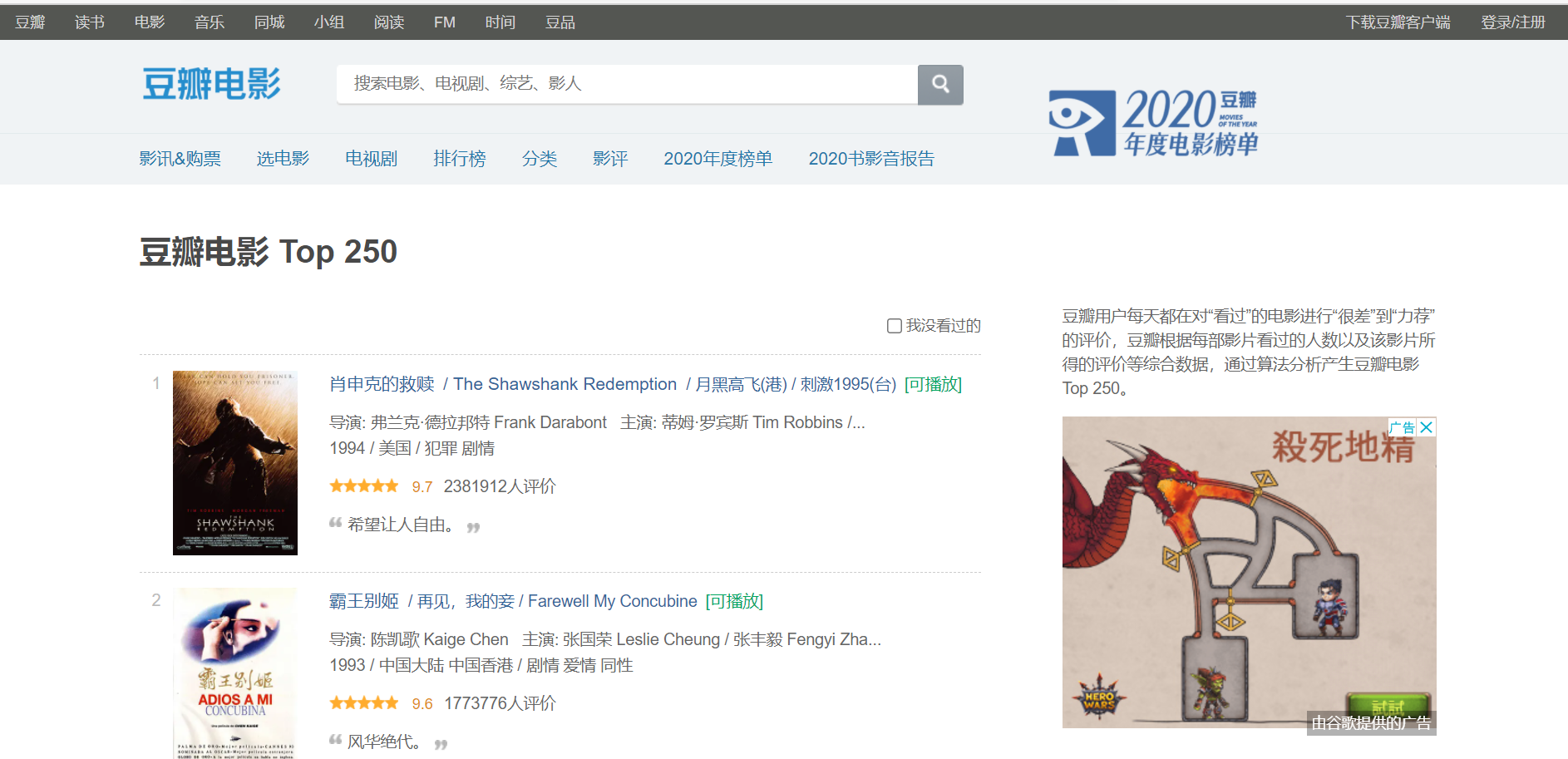
代码
# 引入库
import re
import pandas as pd
import time
import urllib.request
from lxml.html import fromstring
from bs4 import BeautifulSoup
# 下载链接
def download(url):
print('Downloading:', url)
request = urllib.request.Request(url)
request.add_header('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36') #进行伪装
resp = urllib.request.urlopen(request)
html = resp.read().decode('utf-8')
return html
# 待爬取内容
name = []
year = []
rate = []
director = []
scriptwriter = []
protagonist = []
genre = []
country = []
language = []
length = []
# 循环爬取每页内容
for k in range(10):
url = download('https://movie.douban.com/top250?start={}&filter='.format(k*25))
time.sleep(5) #间隔5s,防止被封禁
#找出该页所有电影链接
Links = re.findall('https://movie\.douban\.com/subject/[0-9]+/', url)
movie_list = sorted(set(Links),key=Links.index)
for movie in movie_list:
url = download(movie)
time.sleep(5)
tree = fromstring(url)
soup = BeautifulSoup(url)
#利用正则表达式定位爬取
name.append(re.search('(?<=(<span property="v:itemreviewed">)).*(?=(</span>))',url).group())
year.append(re.search('(?<=(<span class="year">\()).*(?=(\)</span>))', url).group())
rate.append(re.search('(?<=(<strong class="ll rating_num" property="v:average">)).*(?=(</strong>))', url).group())
#利用xpath定位爬取
director.append(tree.xpath('//*[@id="info"]/span[1]')[0].text_content())
scriptwriter.append(tree.xpath('//*[@id="info"]/span[2]')[0].text_content())
protagonist.append(tree.xpath('//*[@id="info"]/span[3]')[0].text_content())
#利用find_all爬取
genres = soup.find_all('span',{'property':'v:genre'})
#将类型用'/'拼接
temp = []
for each in genres:
temp.append(each.get_text())
genre.append('/'.join(temp))
#利用find定位爬取
country.append(soup.find(text='制片国家/地区:').parent.next_sibling) #兄弟节点
language.append(soup.find(text='语言:').parent.next_sibling)
length.append(soup.find('span',{'property':'v:runtime'}).get_text())
# 将list转化为dataframe
name_pd = pd.DataFrame(name)
year_pd = pd.DataFrame(year)
rate_pd = pd.DataFrame(rate)
director_pd = pd.DataFrame(director)
scriptwriter_pd = pd.DataFrame(scriptwriter)
protagonist_pd = pd.DataFrame(protagonist)
genre_pd = pd.DataFrame(genre)
country_pd = pd.DataFrame(country)
language_pd = pd.DataFrame(language)
length_pd = pd.DataFrame(length)
# 拼接
movie_data = pd.concat([name_pd,year_pd,rate_pd,director_pd,scriptwriter_pd,protagonist_pd,genre_pd,country_pd,language_pd,length_pd],axis=1)
movie_data.columns=['电影','年份','评分','导演','编剧','主演','类型','国家/地区','语言','时长']
#保留电影中文名
f = lambda x: re.split(' ',x)[0]
movie_data['电影'] = movie_data['电影'].apply(f)
#删去冗余部分
g = lambda x: x[4:-1] + x[-1]
movie_data['导演'] = movie_data['导演'].apply(g)
movie_data['编剧'] = movie_data['编剧'].apply(g)
movie_data['主演'] = movie_data['主演'].apply(g)
movie_data.head()
# 输出
outputpath='c:/Users/zxw/Desktop/
movie_data.to_csv(outputpath,sep=',',index=False,header=True,encoding='utf_8_sig')
爬虫结果

2.实验过程中遇到的问题及解决过程
- 问题1:对爬虫技术不熟悉导致无从下手
问题1解决方案:自己在网络上查看相关知识
3. 其他(感悟、思考等)
1.上课没认真听,没跟上,下课要花时间学习,但爬虫还是很厉害。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号