
03损失函数和优化
损失函数作用
损失函数是一个衡量预测值和真实值之间差异的函数
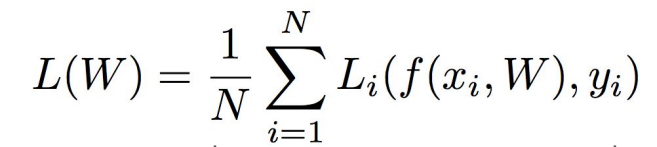
Li表示第 i 张图片,预测值的十个输出与真实值之间的差异
1. hinge 损失函数(应用于SVM)
- 基本思想
- 理想的输出的结果 对应的真实标签的得分应该是很高的, 比其他所有类别都高出一定的阈值,这样才好,此时损失值为0
- 否则的话就要受到惩罚

-
符号说明:Li表示第i张图片预测值(10个)与真实值产生的误差S 表示 输出的预测的得分,S_y_i表示输出的真实值对应的得分,S_j表示其他类别的得分
-
特性
- 最小为0(得分最高,且超出一定阈值),最大为无穷(得分为负无穷)
- 对结果的轻微扰动不敏感,如car类4.9时已经损失值为0,轻微改变仍是0
- 训练最开始时损失函数为 c-1 (c表示种类数,此例c=10){训练最开始W一般为0-1之前很小的均匀分布的值,第一次输出得到的打分也大概相等,这样c-1 次max(0,$s_j - s_{yi}$+1) = c-1}
- 使得loss==0的W不唯一,但根据奥斯卡姆剃刀原理,我们选取最简单的W,为此可以加上一些惩罚项(正则项)。损失函数变为
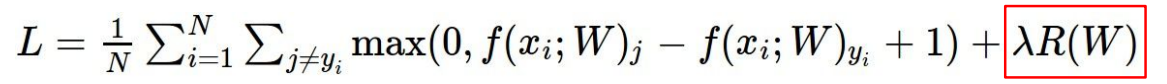
- 如何衡量W简单与否呢?可以使用L1范数、L2范数等等
- 向量化实现

2. 交叉熵损失函数(应用于Softmax loss)
-
基本思想
真实出现的一定是概率最大的,所以真实值对应的标签概率化后概率应该尽可能大
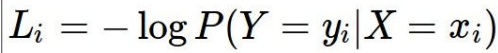
-
计算过程

-
特性
- 最小是0,最大是无穷
- 对打分的 小的扰动敏感
- 初始损失函数 -log(1/c)=log(c),c表示种类
----------------------------------------------------------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号