参考资料:
https://www.cnblogs.com/wkfvawl/p/15815370.html
https://www.cnblogs.com/Polar-sunshine/p/16542132.html
准备
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`age` int(3) NOT NULL,
`salary` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');
create index idx_emp_age_salary on emp(age,salary);
一、order by 优化
分析
查询语句经常需要通过 ORDER BY ⼦句按照某种规则进⾏排序。⼀般情况下,会把记录都加载到内存中,再⽤⼀些排序算法,在内存中对这些记录进⾏排序,有的时候可能查询的结果集太⼤需要借助磁盘的空间来存放中间结果,把这种在内存中或者磁盘上进⾏排序的⽅式统称为⽂件排序(filesort),所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。如果 ORDER BY ⼦句⾥使⽤到了索引列,就有可能省去在内存或⽂件中排序的步骤,因为这个索引本身就是排好序的。
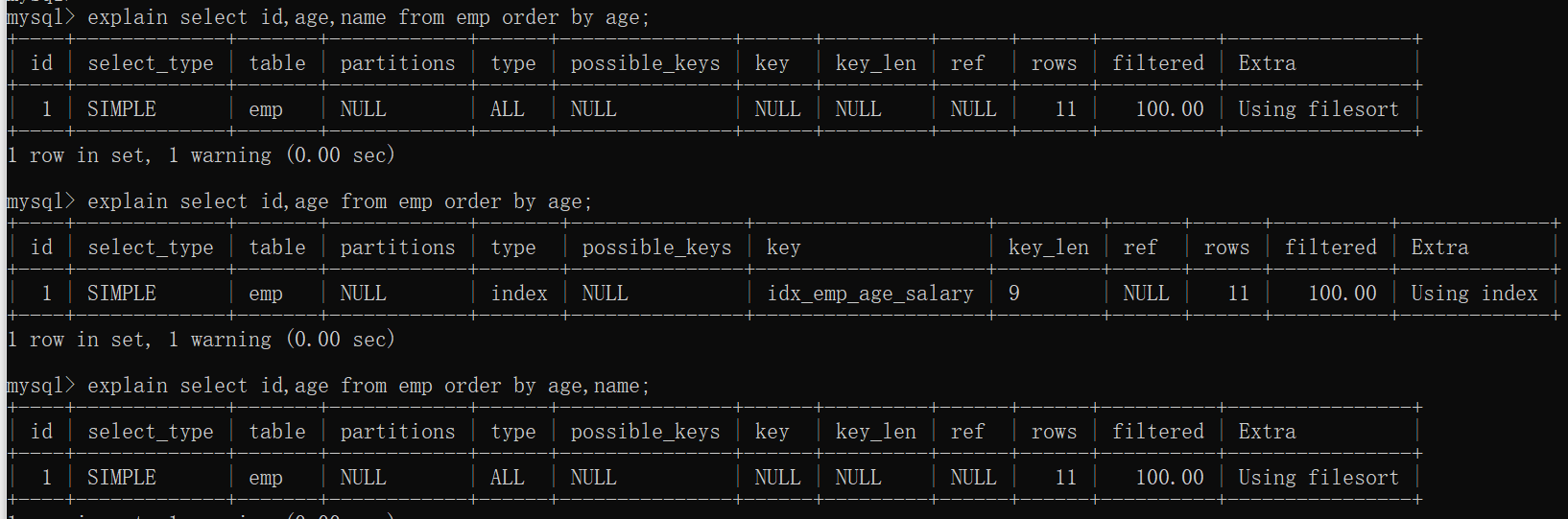
不可以使⽤索引进⾏排序的⼏种情况
ASC、DESC混⽤
想想这个 idx_emp_age_salary 联合索引中记录的结构:
- 1、先按照记录的age列的值进⾏升序排列。
- 2、如果记录的age列的值相同,再按照salary列的值进⾏升序排列。

WHERE⼦句中出现⾮排序使⽤到的索引列
因为第一个查询只能先把符合搜索条件name = 'Luci'的记录提取出来后再进⾏排序,是使⽤不到索引。

排序列包含⾮同⼀个索引的列
添加新的索引列 dept_name
alter table emp add dept_name varchar(50) default '开发部';
create index idx_emp_dept_name on emp(dept_name);

排序列使⽤了复杂的表达式

联合索引排序错误
对于联合索引,ORDER BY的⼦句后边的列的顺序也必须按照索引列的顺序给出,如果给出 ORDER BY age, salary 的顺序,那也是⽤不了索引

二、group by 优化
group by 执行过程
有表
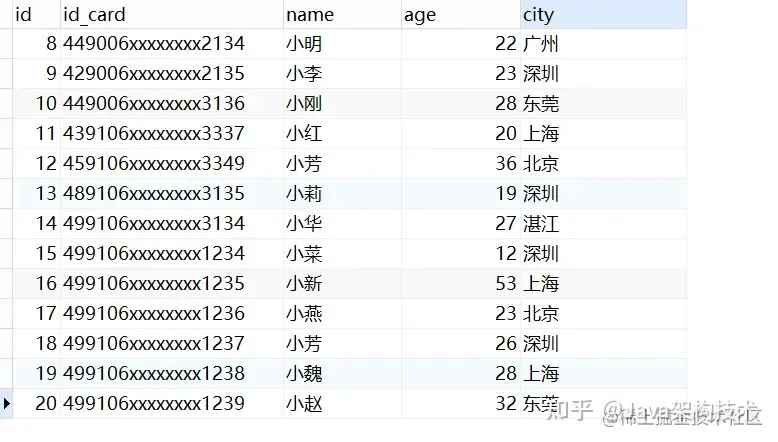
先用explain查看一下执行计划
explain select city ,count(*) as num from staff group by city;

- Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表
- Extra 这个字段的Using filesort表示使用了排序
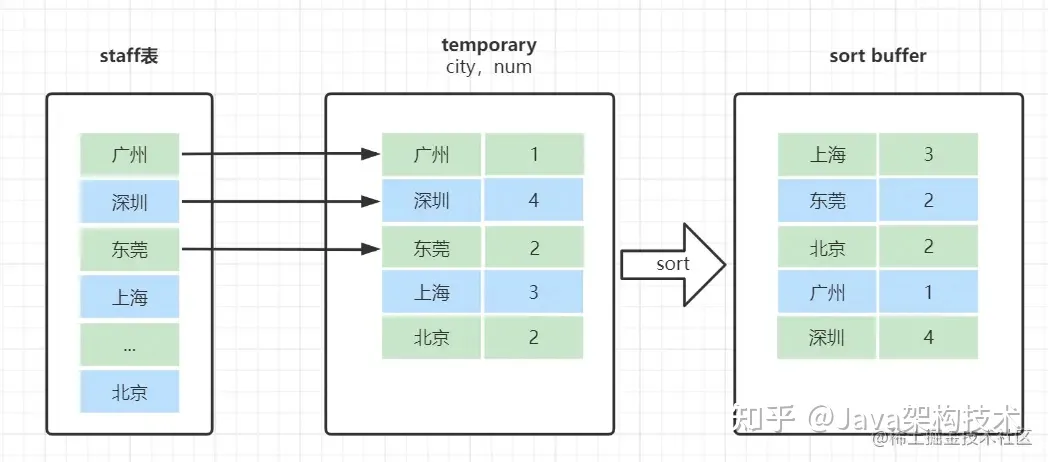
先看一下SQL的执行流程:
- 1、创建内存临时表,表里有两个字段city和num;
- 2、全表扫描staff的记录,依次取出city = 'X'的记录。
-
判断临时表中是否有为 city='X'的行,没有就插入一个记录 (X,1);
-
如果临时表中有city='X'的行的行,就将x 这一行的num值加 1;
-
遍历完成后,再根据字段city做排序,得到结果集返回给客户端。
这个流程的执行图如下:
优化方案
从哪些方向去优化呢?
-
方向1: 既然它默认会排序,我们不给它排是不是就行啦。
-
方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
group by 后面的字段加索引
执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果。
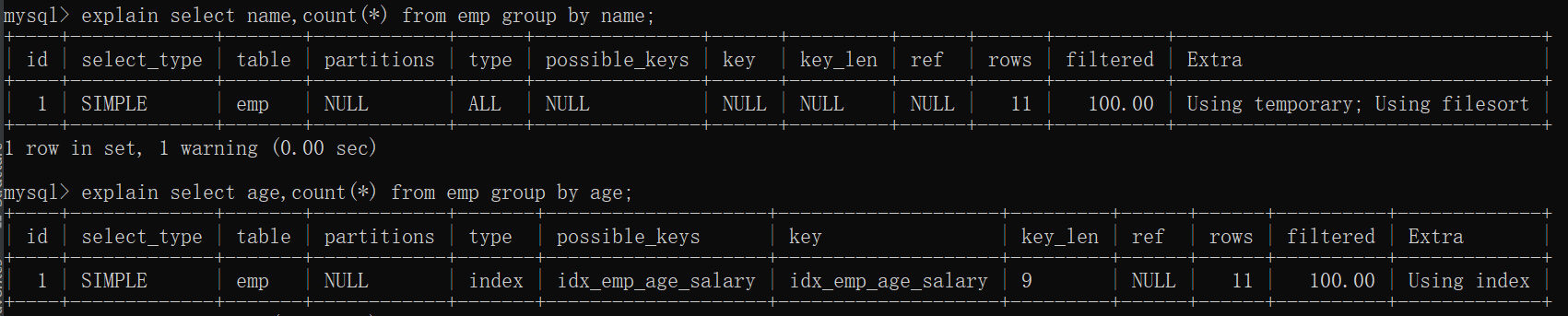
order by null 不用排序
并不是所有场景都适合加索引的,如果碰上不适合创建索引的场景,我们如何优化呢?
如果你的需求并不需要对结果集进行排序,可以使用order by null。执行计划如下,已经没有filesort了

尽量只使用内存临时表
如果group by需要统计的数据不多,我们可以尽量只使用内存临时表;因为如果group by 的过程因为数据放不下,导致用到磁盘临时表的话,是比较耗时的。因此可以适当调大 tmp_table_size 参数,来避免用到磁盘临时表。
三、limit M,N 分页查询优化
select id,name from t limit 866613, 20
使用上述sql语句做分页的时候,随着表数据量的增加,直接使用limit分页查询会越来越慢。
对于 limit m, n 的分页查询,越往后面翻页(即m越大的情况下)SQL的耗时会越来越长,对于这种应该先取出主键id,然后通过主键id跟原表进行Join关联查询。因为MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。
使用索引覆盖+子查询优化
因为我们有主键 id,并且在上面建了索引,所以可以先在索引树中找到开始位置的 id 值,再根据找到的 id 值查询行数据。sql可以采用如下的写法:
select feild1,feild2... from T where id > (select id from T order by id limit M-1, 1) limit N
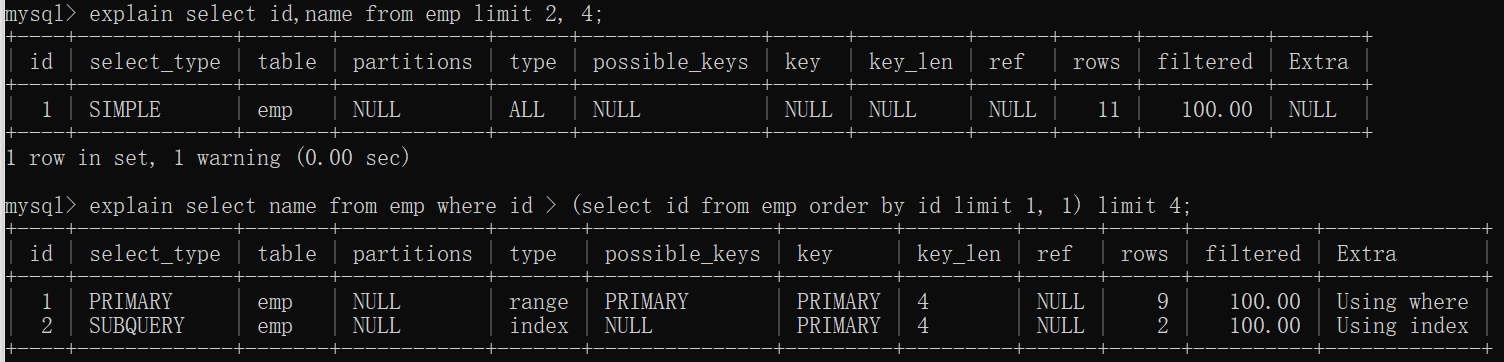
起始位置重定义(效率最高,但是要记住ID值)
可以取前一页的最大行数的id(将上次遍历到的最末尾的数据ID传给数据库,然后直接定位到该ID处,再往后面遍历数据),然后根据这个最大的id来限制下一页的起点。比如此列中,上一页最大的id是866612。sql可以采用如下的写法:
select id,name from table_name where id > 866612 limit 20;
四、总和查询可以禁止排重用 union all 优化
-
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
-
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
所以一般是我们明确知道不会出现重复数据的时候建议使用 union all 提高速度。
五、in和exists
select * from 表A where id in (select id from 表B)`
上面的语句相当于:
select * from 表A where exists(select 1 from 表B where 表B.id=表A.b_id)
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
另外,in查询在某些情况下有可能会查询返回错误的结果,因此,通常是建议在确定且有限的集合时,可以使用in。如 IN (0,1,2)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号