
【译】图解Transformer
本文翻译自Jay Alammar的博文The Illustrated Transformer
注意力是一个有助于提高神经机器翻译模型性能的机制。在这篇文章中,我们将着眼于Transformer——一个利用注意力来提高模型训练速度的模型。Transformer在特定任务中的性能优于Google之前的神经机器翻译模型。然而,最大的好处来自于Transformer如何使自己适合于并行化计算。实际上,Google Cloud推荐使用Transformer作为参考模型来使用他们的云TPU产品。那么,让我们试着把模型拆开看看它是如何工作的。
Transformer是在论文Attention is All You Need中提出的。它的TensorFlow实现已经加入到Tensor2tTensor包中。哈佛大学的NLP小组用PyTorch实现了该模型(连接:The Annotated Transformer)。在这篇文章中,我们将试图把事情简单化一点,并逐一介绍这些概念,希望没有还没有深入了解的人更容易理解这些概念。
从宏观上看Transformer
让我们从将模型看作一个单独的黑盒开始。在机器翻译中,输入是一种语言的句子,输出是翻译后的另一种语言对应的句子。

进一步深入Transformer这个黑盒,我们看到一个编码组件,一个解码组件,以及它们之间的联系。
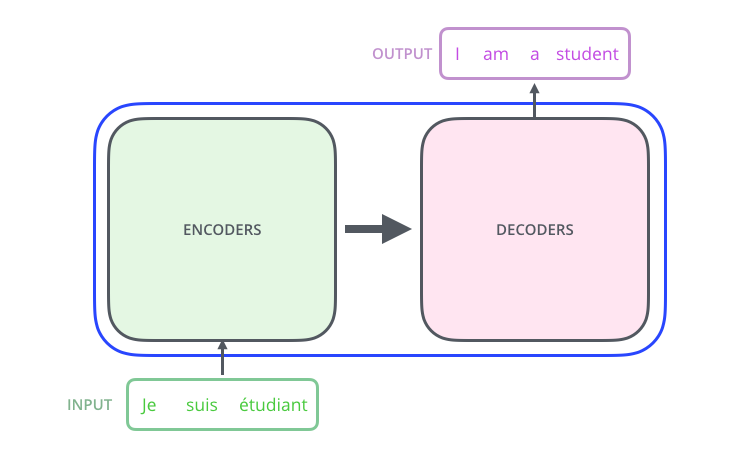
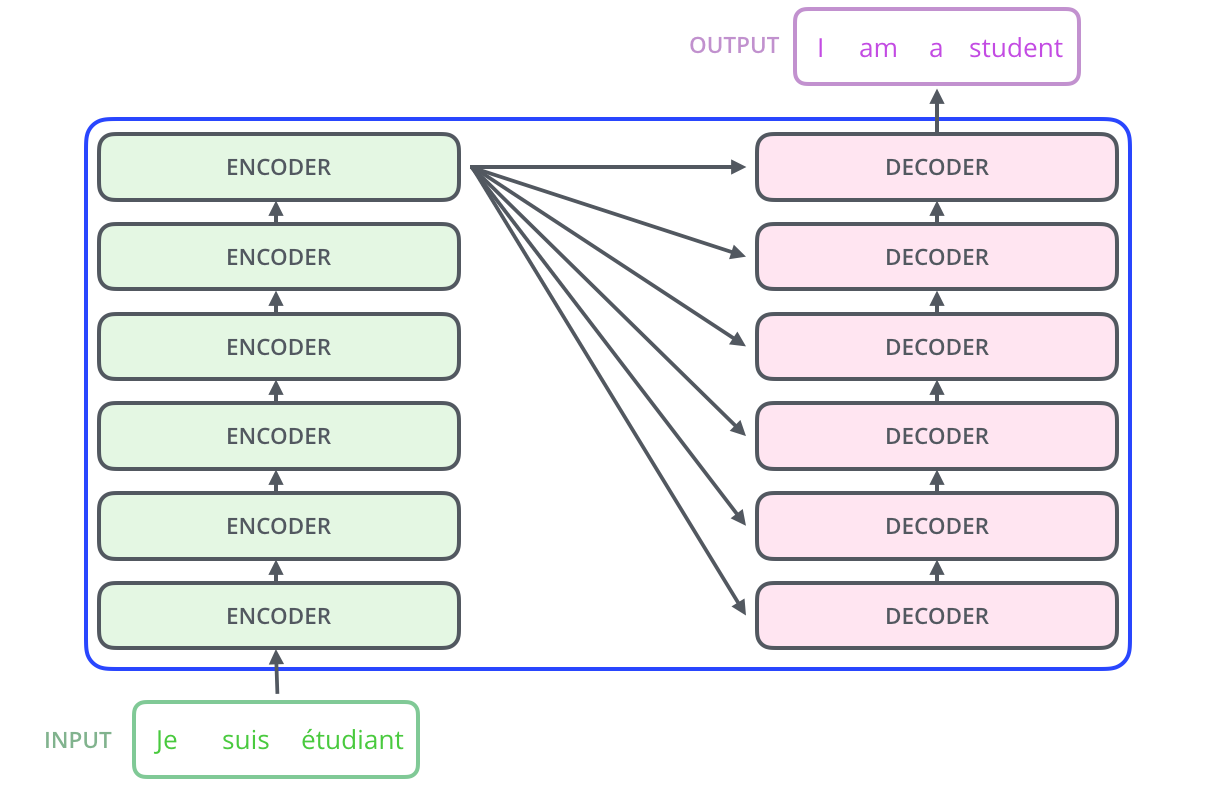
编码组件是一堆编码器(论文中将6个编码器叠在一起——数字6没有什么特别之处,你可以尝试更多或更少的个数)。解码组件是相同数量的解码器组成的栈。
编码器在结构上是相同的(但是它们不共享权重)。每一个又由两个子层组成:
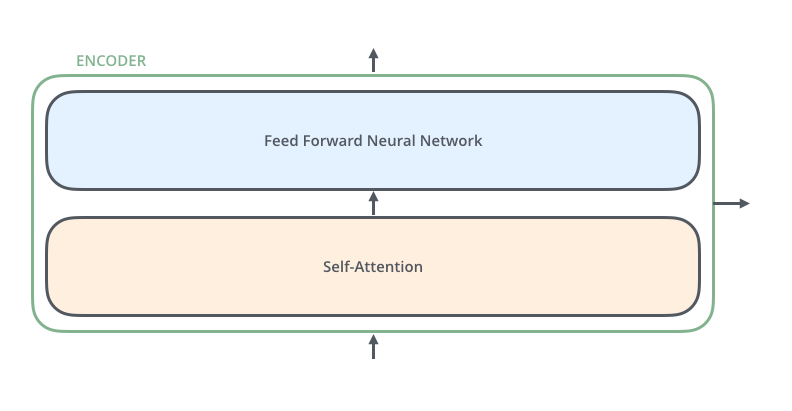
编码器的输入首先通过一个自注意力层——这个层帮助编码器在对特定单词进行编码时照顾到输入的句子中的其他单词。我们将在稍后的文章中更深入地研究自注意力机制。
自注意力层的输出被输入到前馈神经网络。完全相同的前馈网络分别应用于各个编码器中。
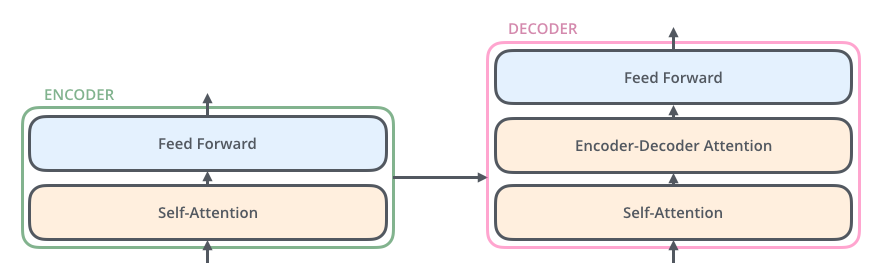
解码器也有编码器中的那两层,但在这两层之间还多了一层注意力层,它帮助解码器将注意力集中在输入句子的相关部分(类似于注意力在seq2seq模型中的作用)。
把张量画出来
现在我们已经了解了模型的主要组件,让我们开始研究各种向量/张量,以及它们如何在这些组件之间流动,从而将经过训练的模型的输入转换为输出。
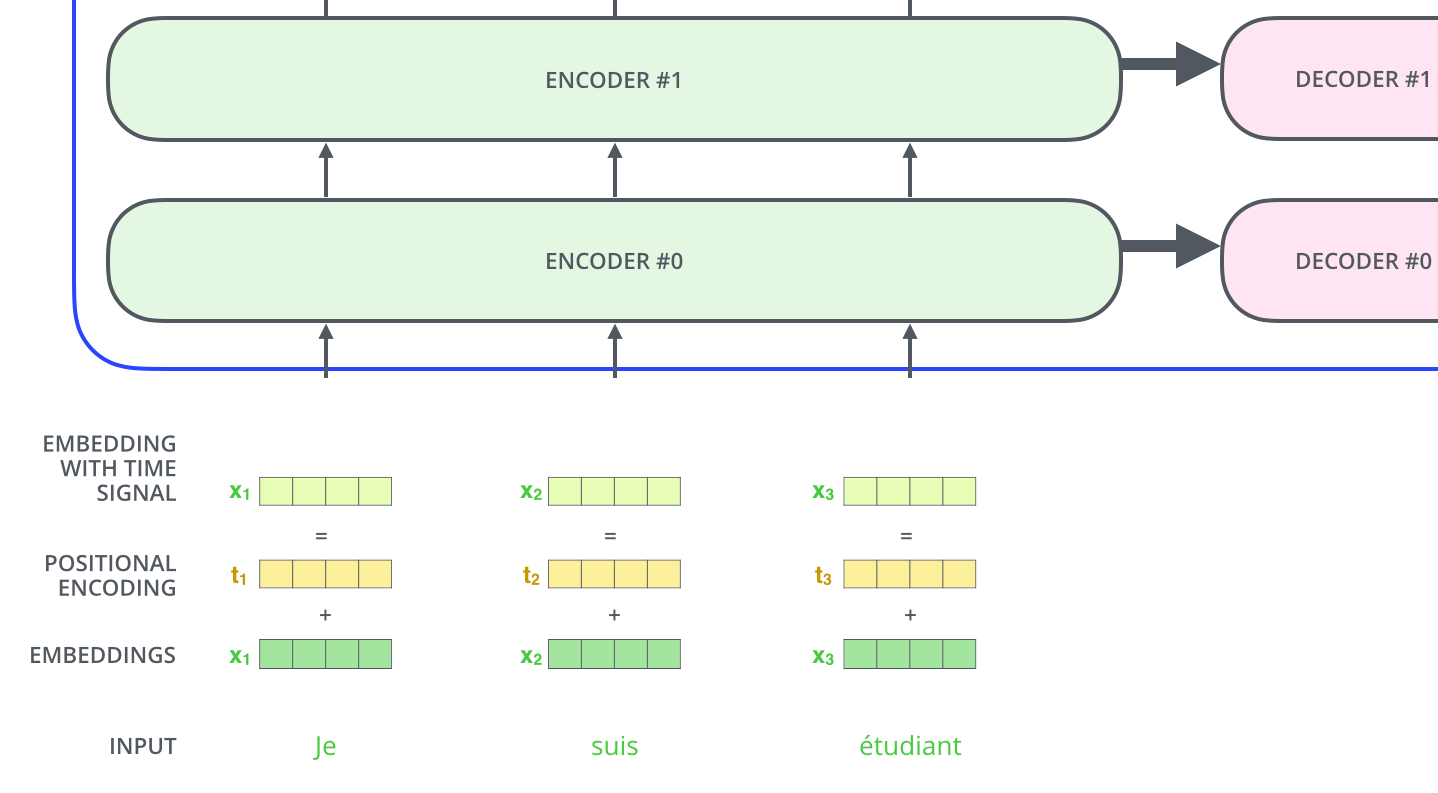
与一般NLP模型的情况一样,我们首先使用嵌入算法将每个输入单词转换为一个向量。

每一个单词被转换为一个512维的向量
词嵌入仅用于最底部的编码器。所有编码器都会以一个向量列表为输入(每个向量有512维),最底部的编码器接收的是词嵌入,但其他编码器中接收的是在其下面的编码器的输出。这个列表的大小是超参数——基本上它是我们的训练数据集中最长的句子的长度。
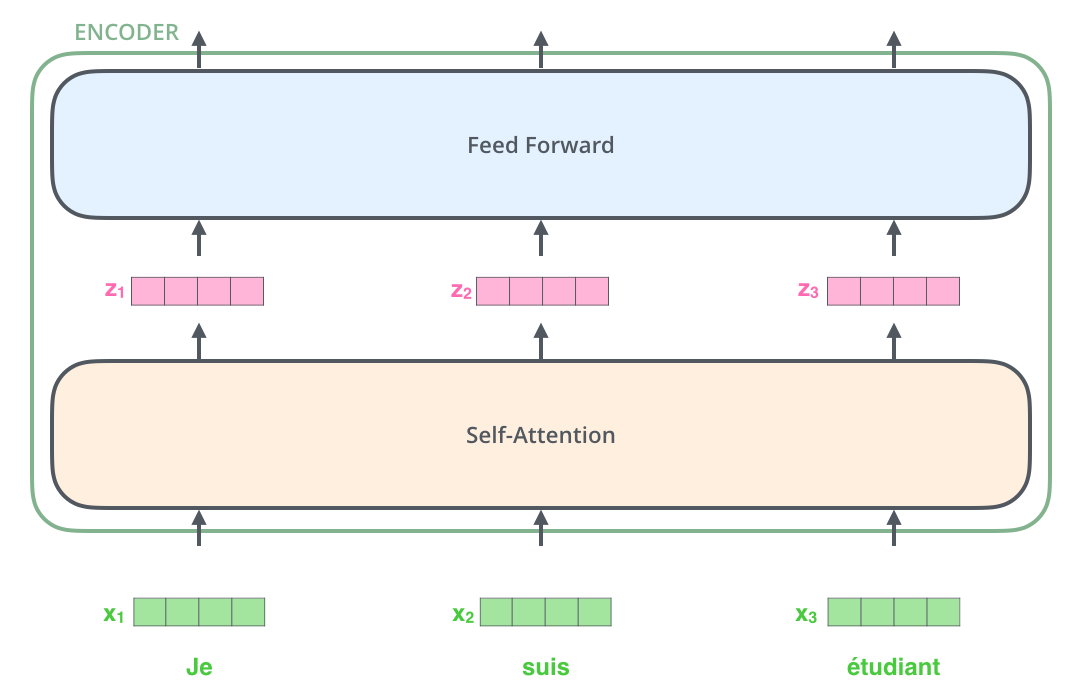
在这里,我们开始看到转换器的一个关键特性,即每个位置上的单词在编码器中沿着自己的路径流动。在自注意力层中,这些路径之间存在依赖关系。但是,前馈层不能捕捉这种依赖关系,因此各个词在流经前馈层时可以并行计算。
接下来,我们将以一个较短的句子为例,看看在编码器中每个子层中都发生了什么。
开始编码!
正如我们已经提到的,编码器接收一个向量列表作为输入。它通过将这些向量传递到一个自注意力层,然后转入前馈神经网络,最后将输出送入到下一个编码器。

从宏观上看自注意力
让我们提炼一下自注意力如何工作的。
假设下面的句子是我们想要翻译的句子:
“The animal didn't cross the street because it was too tired”
这句话中的“it”指代的是什么?是街道还是动物?这对人类来说是一个简单的问题,但对算法来说就不那么简单了。
当模型处理“it”这个词时,自注意力就能够将“it”与“动物”联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力能够捕捉该单词与输入序列中的其他位置上的单词的联系来寻找线索,以帮助更好地编码该单词。
如果你熟悉RNN,想想一个隐藏状态何以将RNN已处理的前一个单词/向量的表示与它正在处理的当前单词/向量结合起来。Transformer就是用自注意力来将其他相关单词的“理解”转化为我们正在处理的单词的。

在第五个编码器在编码it这个单词时,注意力机制让模型更多地关注到“The animal"
你可以在Tensor2Tensor的notebook中载入Transformer,然后用可视化工具看看。
自注意力的细节
首先让我们先看看如何用向量计算自注意力,然后再看看它是如何用矩阵运算实现这一过程。
计算自注意力的第一步是从编码器的每个输入向量中创建三个向量(在本例中,是每个单词的嵌入)。因此,对于每个单词,我们创建一个Query向量、一个Key向量和一个Value向量。这些向量是通过将词嵌入与3个训练后的矩阵相乘得到的。
注意这些新的向量在维数上比嵌入向量小。它们的维数为64,而词嵌入和编码器的输入/输出向量的维数为512。把向量维度降低仅仅是一种处于架构考虑的选择,从而使多头注意力(multi-headed attention)计算保持维度上的固定。
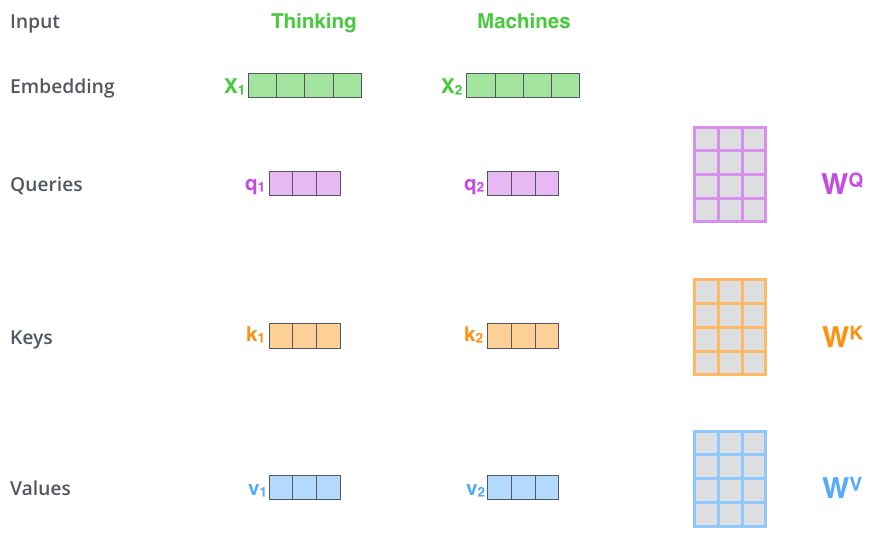
$X_ 1$与权重矩阵$W^Q$相乘得到相应的query向量$q_1$, 同样可以得到输入序列中每个单词对应的$W^K$和$W^V$ 。
**什么是“query向量”、“key向量”和“value向量”? 它们是用来计算注意力的。通过阅读下面的内容,你就会知道这些向量的作用。
{x_1} 它们是对计算和思考注意力有用的抽象概念。一旦你继续阅读下面如何计算注意力,你就会知道所有你需要知道的关于这些向量所扮演的角色。
计算自注意力的第二步是计算注意力得分。假设我们要计算本例中第一个单词“Thinking”的自注意力得分。我们需要对输入句子中的每个单词进行打分。这个分数决定了我们在编码某个位置上的单词时,对其他单词的关注程度。
这个得分是通过计算query向量与各个单词的key向量的点积得到的。所以如果我们要计算位置1上的单词的自注意力得分,那么第一个分数就是$q_1$和$k_1$的点积。第二个分数是$q_1$和$k_2$的点积。

第三步和第四步是将得分除以8(key向量的维数(64)的平方根,是默认值。这能让梯度更新的过程更加稳定),然后将结果进行softmax操作。Softmax将分数标准化,使它们都是正数,加起来等于1。
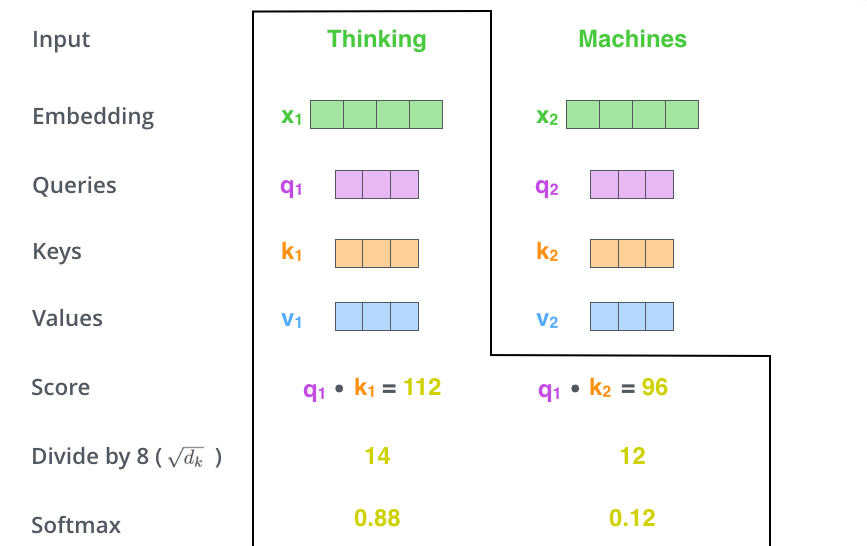
softmax的结果决定了每个单词在这个位置(1)上的相关程度(译者注:相当于权重)。显然,1这个位置的单词会有最高的softmax得分。
第五步是将每个value向量乘以softmax的结果(为求和做准备)。这里的思想是尽量保持我们想要关注的单词的value值不变,而掩盖掉那些不相关的单词(例如将它们乘以很小的数字)。
第六步是将带权重的各个value向量加起来。就此,产生在这个位置上(第一个单词)的self-attention层的输出。

这就是自注意力的计算过程。得到的输出向量可以送入前馈神经网络。但是在实际的实现中,为了更快的处理,这种计算是以矩阵形式进行的。
自注意力的矩阵计算
第一步是计算Query矩阵、Key矩阵和Value矩阵。我们把词嵌入矩阵X乘以训练得到的的权重矩阵($W^Q$, $W^K$, $W^V$)
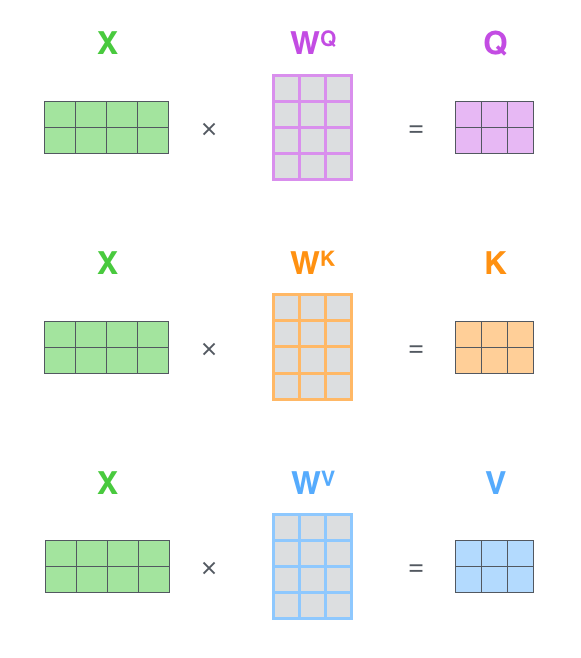
X的每一行代表一个单词
最后,由于我们处理的是矩阵,我们可以将第二部到第六步合并为一个公式中计算自注意力层的输出。
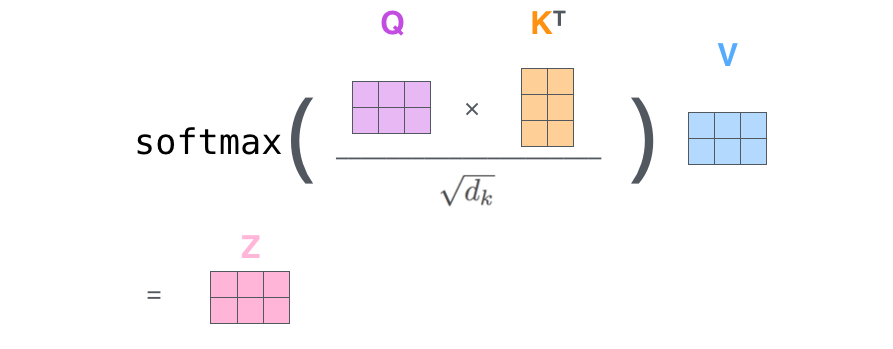
“多头”自注意力
论文进一步细化了自注意力层,增加了“多头”注意力机制。这从两个方面提高了自注意力层的性能:
- 它扩展了模型关注不同位置的能力。正如在上面的例子中,$z_1$包含了一些其他单词的编码,但是它自身的权重显然是最大的。如果我们翻译像“The animal didn't cross the street because it was too tired”这样的句子,它会很有用,因为我们想知道“it”是指代的是哪个单词。
- 它给了自注意力层多个“表示子空间”。正如我们接下来将看到的,对于多头自注意力,我们有不止一组Query/Key/Value权重矩阵,而是有多组(Transformer使用8个"头"(即8组),所以每个编码器/解码器使用8个“头”)。每一个都是随机初始化的。然后,经过训练,每个权重矩阵被用来将输入向量投射到不同的表示子空间。
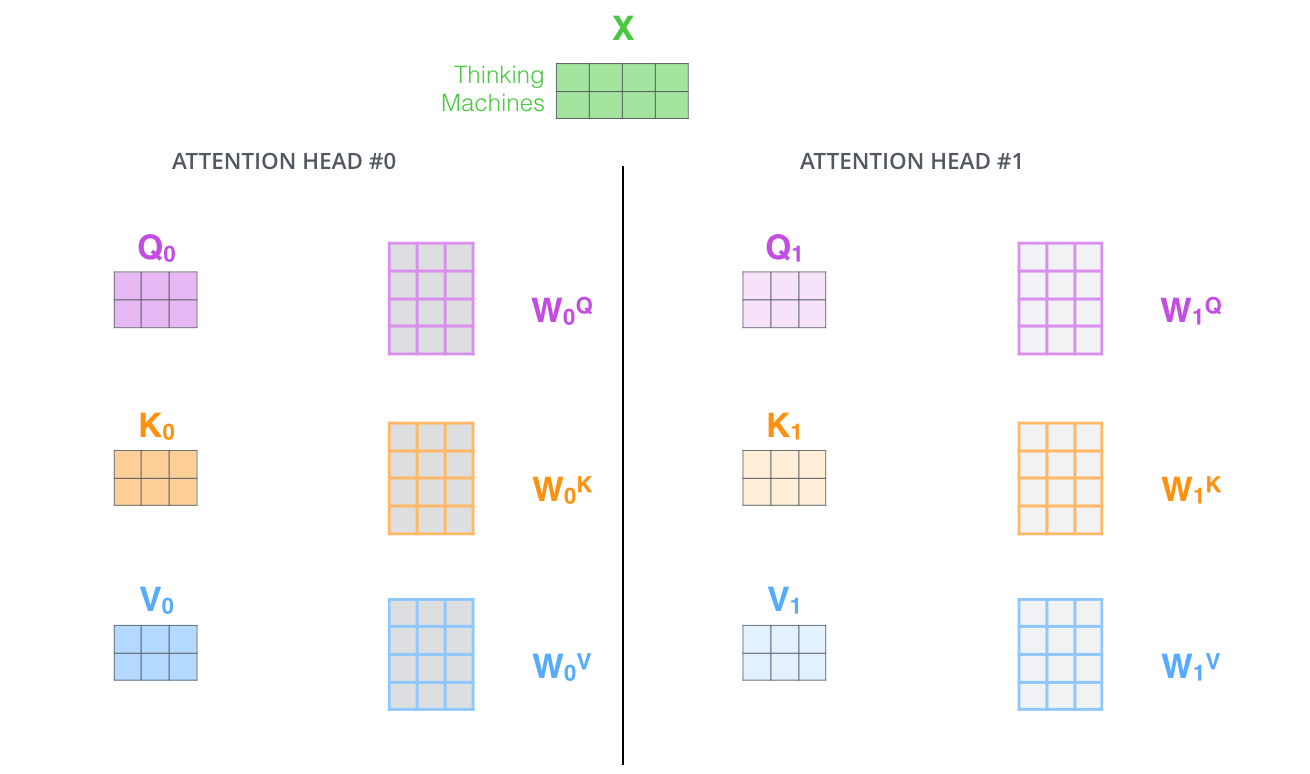
用不同的权重矩阵做8次不同的计算,我们最终得到8个不同的Z矩阵。

这给我们留下了一点挑战。前馈层不需要八个矩阵——它只需要一个矩阵(每个单词对应一个向量)。所以我们需要一种方法把这8个压缩成一个矩阵。
我们怎么做呢?我们把这些矩阵拼接起来然后用一个额外的权重矩阵与之相乘。
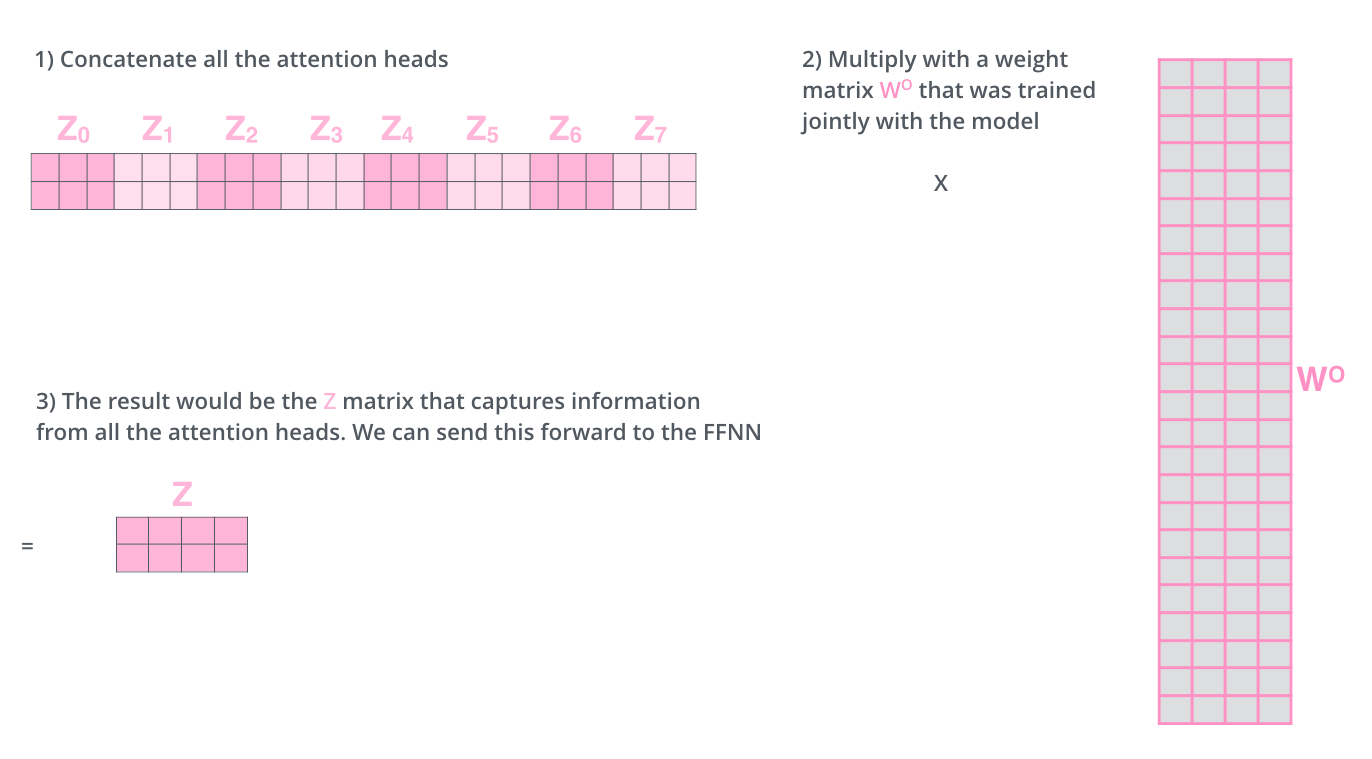
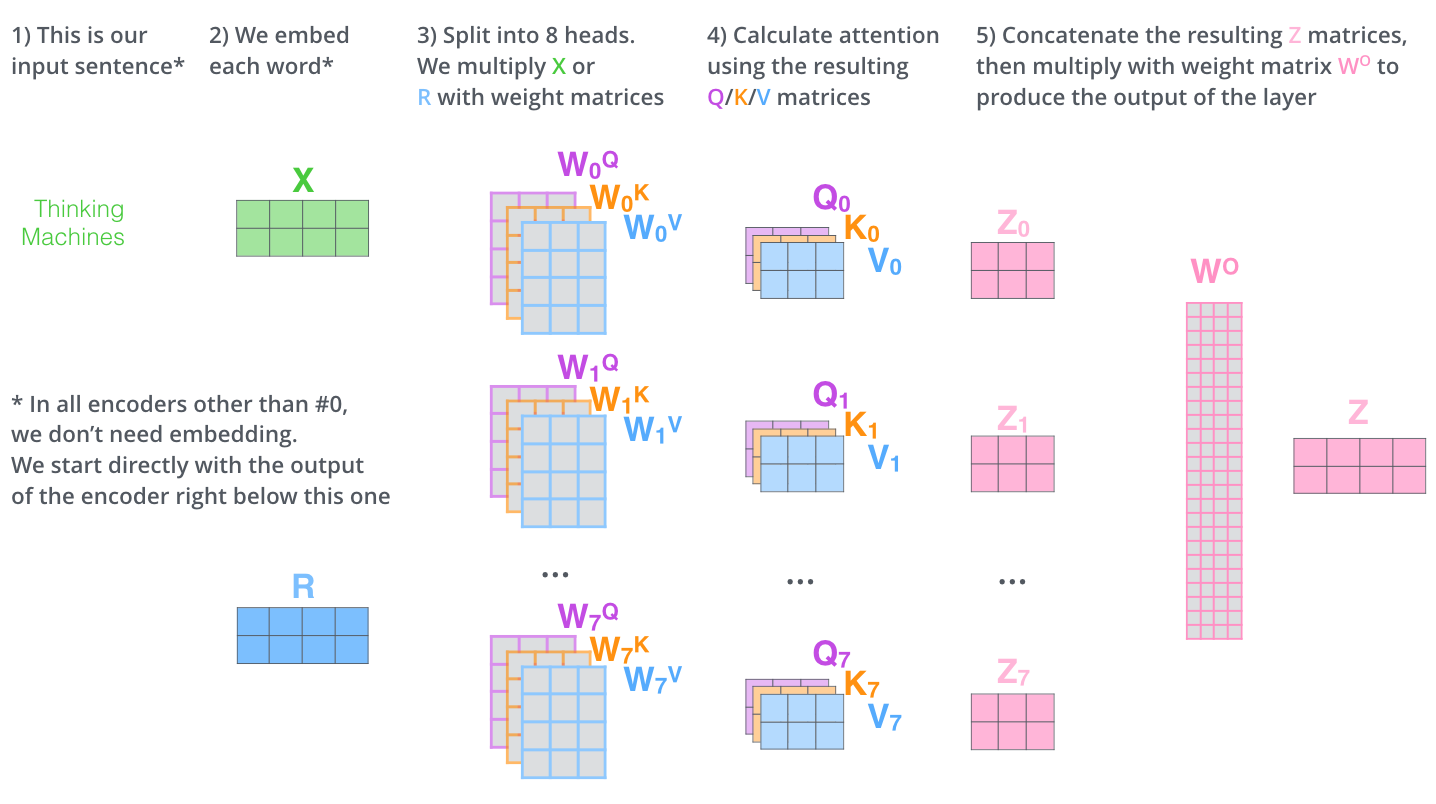
这就是多头自注意力的全部内容。让我们试着把这么多矩阵放在一张图上看看。
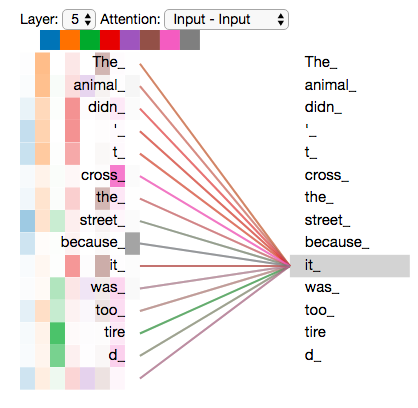
让我们回顾一下之前的例子,看看当我们在例句中编码单词“it”时,不同的注意力头把焦点放到了哪里:

当我们编码“it"这个词时,有的“头”(橘黄色部分)计算的结果认为其与“the animal“关系比较密切,而有的(绿色部分)认为和“tired”关系更近 ——那么便把“The animal” 和“tire”的信息更多地编码到了it中。
然而,如果我们把所有的注意力都集中在这幅图上,事情就会变得难以理解:
用位置编码表示序列的顺序
还有一件事没有讲到,就是模型如何编码输入序列中单词顺序。
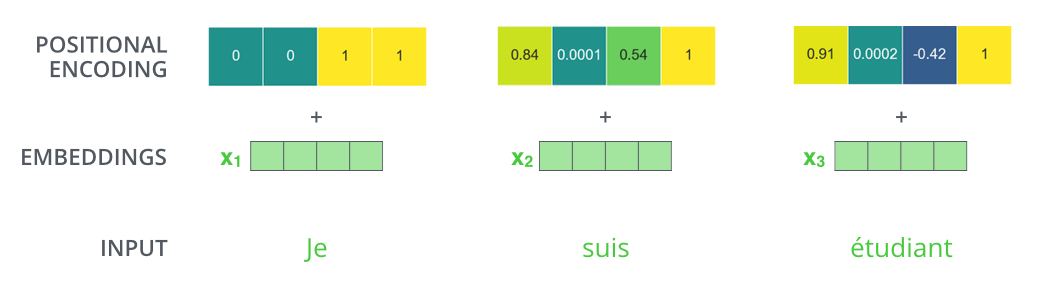
为了解决这个问题,Transformer在每个词嵌入向量上加了一个向量。这些向量遵循模型学习到的特定模式,这有助于模型确定每个单词的位置,或序列中不同单词之间的距离。其中的思想是,将这些值与词嵌入向量相加能够得到经过Q/K/V投射后的词嵌入向量和计算自注意力得分时的向量间的距离。
为了在模型中加入词序,论文增加了位置编码向量,其值是由特定的式子计算得到的。
假设词嵌入的维数为4,那么实际的位置编码应该是这样的:
这种模式可能是什么样的?
在下面的图中,每一行对应一个向量的位置编码。所以第一行就是与一个单词的词嵌入矩阵相加的位置编码向量。每行包含512个值——每个值在1到-1之间。我们用颜色标记了它们。
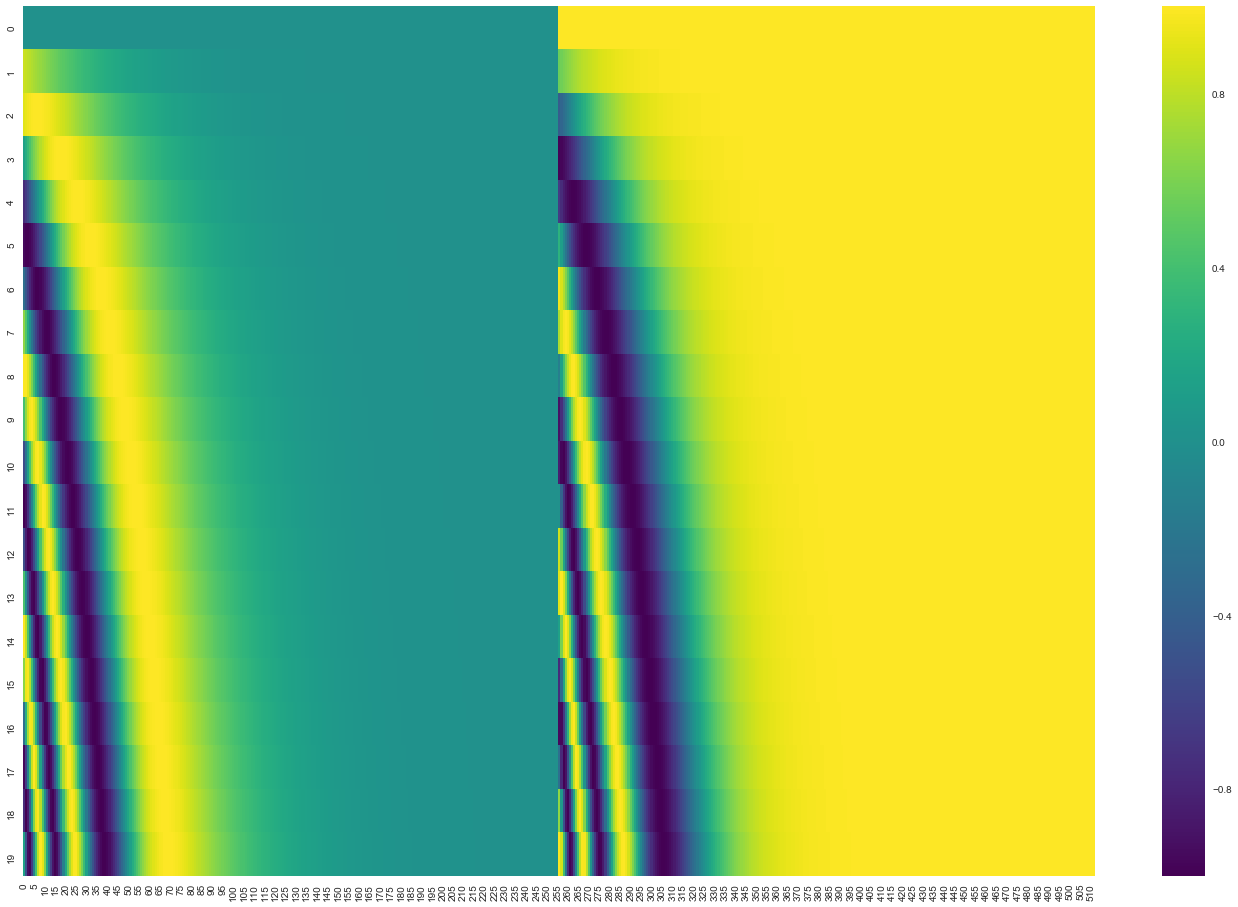
一个实际的例子:20个词的序列(行数),每个词的嵌入向量有512维(列数)。从图中可以看到出现了左右各半两个部分。这是因为向量左边的数值和右边的数值使用的是不同的函数得到的,左边使用的是正弦sin,右边使用的是余弦cos。通过拼接两种函数得到的向量得到每一个位置编码向量。
位置编码向量的计算公式在论文中有给出,你也可以参考生成位置编码的代码 get_timing_signal_1d(). 当然,这不是唯一的编码位置信息的方法。但是这种方法的好处之一就是对于不定长度的序列,模型也能够处理(例如模型要翻译一句长度比训练数据都要长的句子时,模型也能完成)。
残差
在继续之前,我们需要说说编码器架构中的一个细节,即每个编码器中的每个子层(self-attention, ffnn)在其周围都有一个残差连接(编者注:shortcut),同时还伴随着一个规范化步骤。
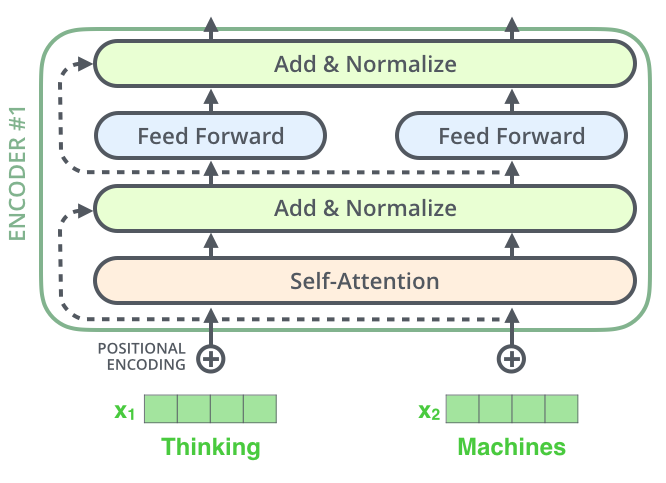
更形象的表示如下:
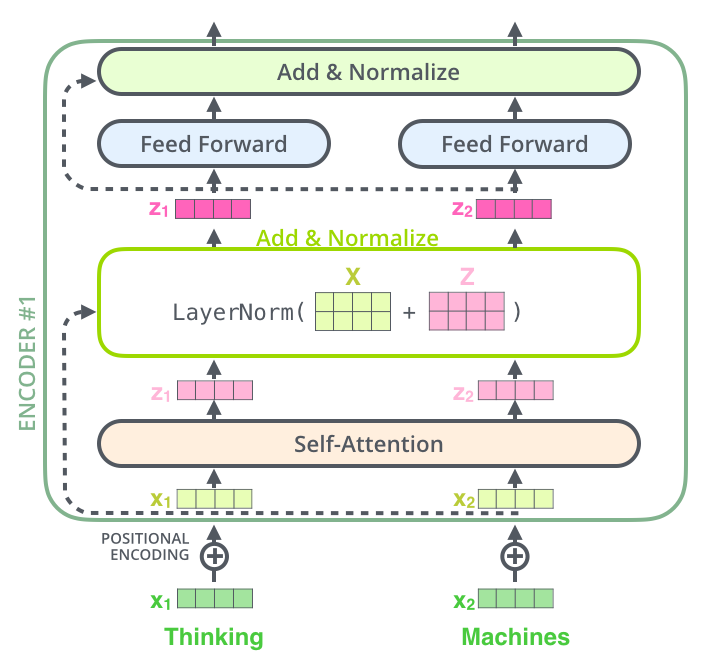
这也适用于解码器的子层。如果我们仅考虑一个由两个编码器和两个解码器组成的Transformer,它看起来是这样的:

解码器
现在我们已经介绍了编码器端的大多数概念,我们基本上也知道解码器的组件是如何工作的。但让我们看看它们是如何协同工作的。
编码器从处理输入序列开始,然后将上面编码器的输出转换成一组注意向量K和V,这些将由每个解码器在其“编码器-译码器注意力”层(encoder-decoder attention)中使用,帮助解码器将注意力集中在输入序列的适当位置:

在完成编码过程之后,开始解码过程。每一个时间步,解码器会输出翻译后的一个单词。
重复这样的解码过程知道出现代表结束的特殊符号。每一时间步的输出都会在下一个时间步解码的时候的时候反馈给底层解码器,解码器就会像编码器一样,将该层的解码结果想更高层传递。就像我们对编码器输入所做的那样,我们将位置编码也加入到解码器输入中以指示每个单词的位置。
解码器中的自注意力层与编码器中的自注意力层的工作方式略有不同:
在解码器中,自注意力层只允许关注到输出序列中较前的位置。这是通过在自注意力计算的softmax步骤之前用掩码mask遮罩序列中后面的位置(将它们设置为为负无穷)来实现的。
编码器-解码器注意力层的工作原理与多头自注意力层类似,只是它从下面的网络层创建Query矩阵,并从编码器栈的输出中获取Key矩阵和Value矩阵。
最后的线性和Softmax层
解码器栈输出一个浮点型向量。我们怎么把它变成一个词呢?这是最后一个线性层的工作,其后接上一个Softmax层。
线性层是一个简单的全连接神经网络,它将解码器栈产生的向量投影到一个更高维向量(logits)上。
假设我们的模型知道10,000个从它的训练数据集中学习的惟一英语单词(我们的模型的“输出词汇”)。那么logits 就有10,000个维度,每个维度对应一个惟一的单词的得分。
之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出。
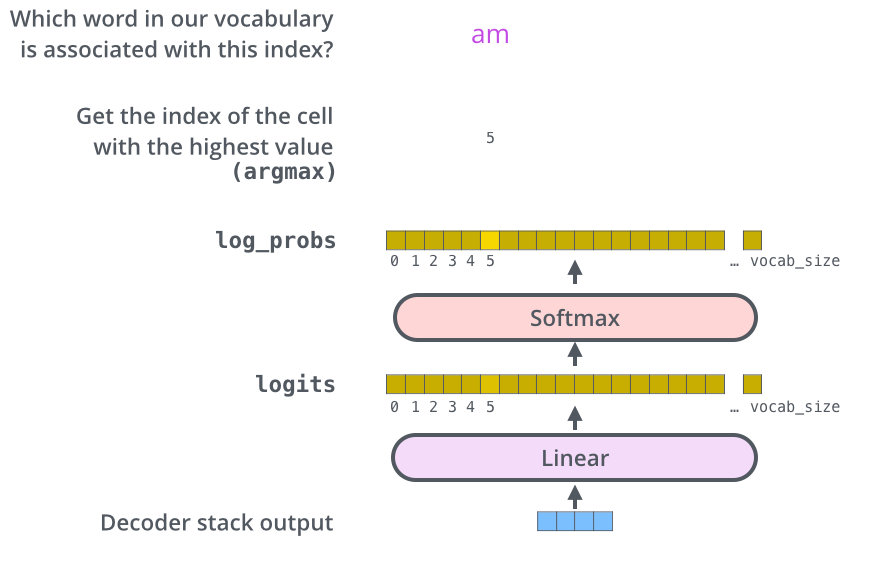
编码器栈的输出向量经过线性层和softmax得到概率分布
损失函数
现在,我们介绍了Transformer的整个正向传递过程。
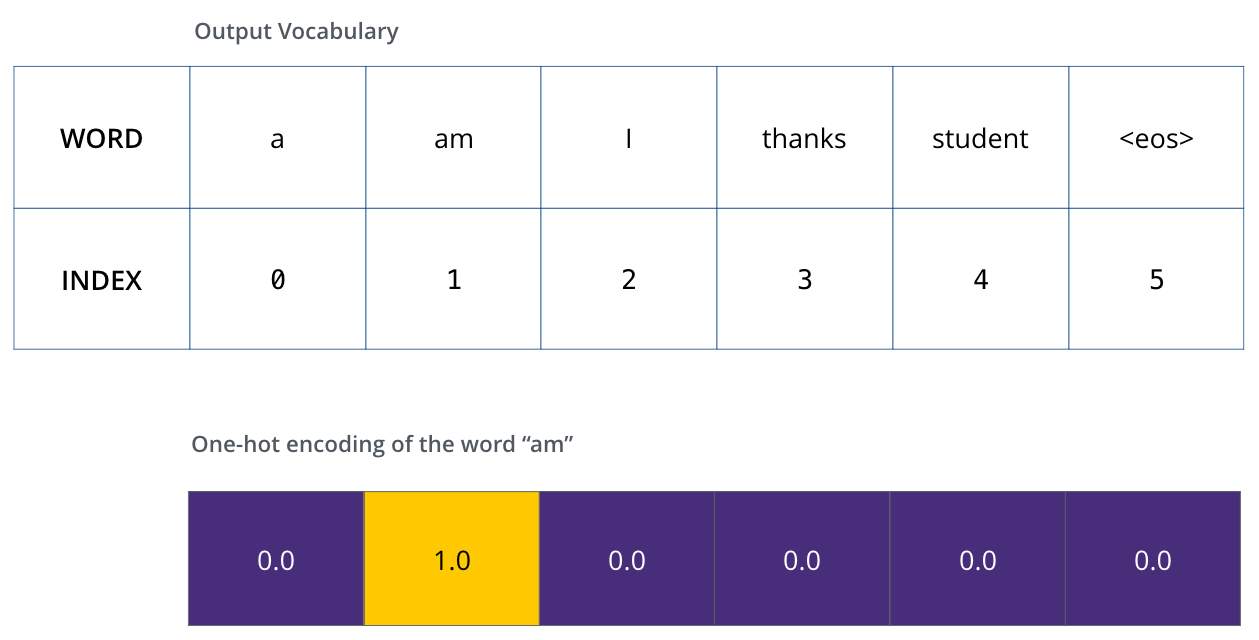
假设我们的输出词汇表只包含六个单词(“a”、“am”、“i”、“thanks”、“student”和“
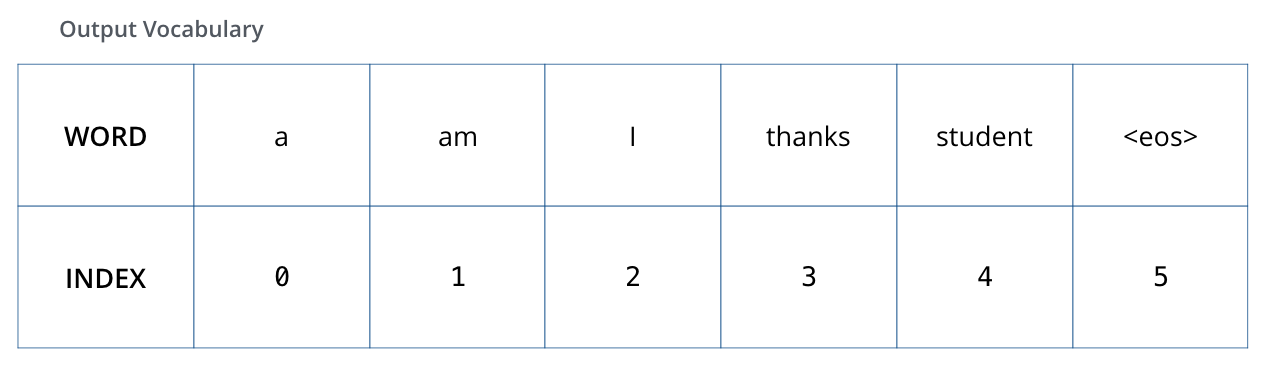
一旦定义了输出词汇表,就可以使用相同维度的向量来表示词汇表中的每个单词。这也称为one-hot编码。例如,我们可以用下面的向量来表示“am”这个词:
我们用一个简单的例子进行训练——将“merci”翻译成“thanks”。
我们希望输出是一个表示“thanks”的概率分布。但是由于这个模型还没有经过充分的训练,所以现在还不太可能实现。
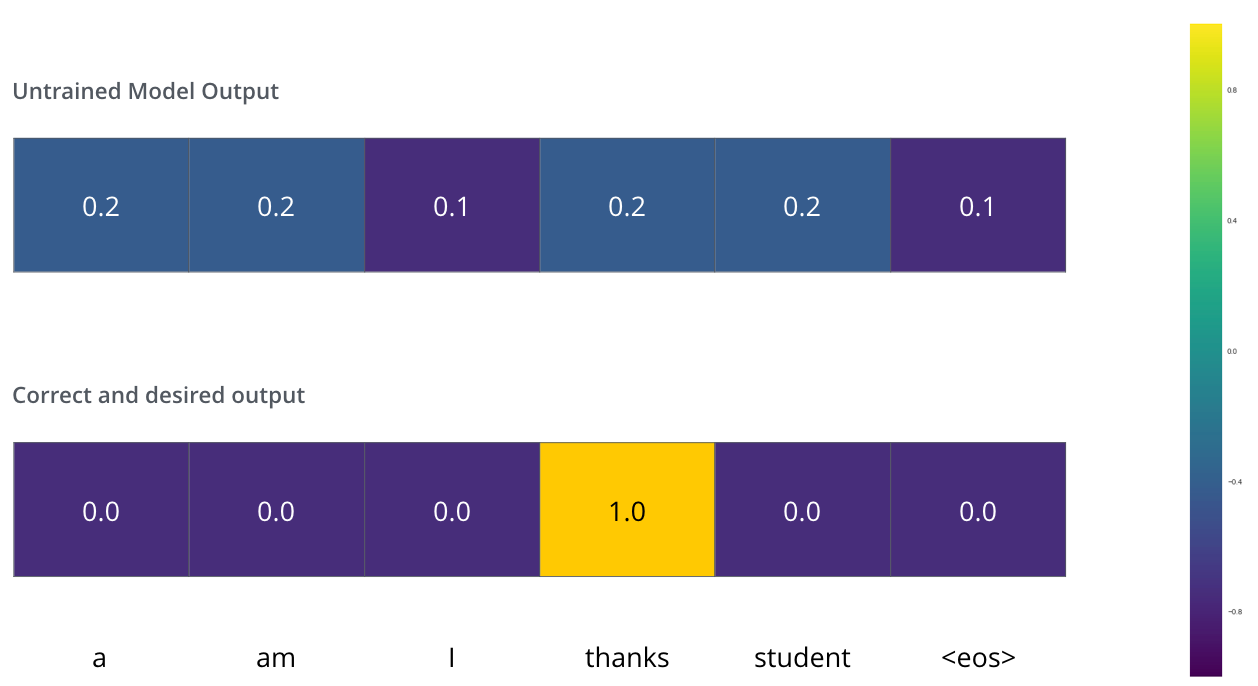
由于模型参数是随机初始化的,在刚开始训练的时候,输出的概率分布也是没有意义的。通过与正确的翻译结果进行比较,用反向传播更新模型的权重,让模型逼近正确的翻译结果。
如何比较两个概率分布?我们只要从另一个中减去一个。要了解更多细节,请查看交叉熵 and KL散度.。
但请注意,这是一个过于简化的示例。更实际一点,我们将使用一个句子,而不是一个单词。例如,输入:“je suis etudiant”和期望输出:“i am a student”。这真正的意思是,我们想要我们的模型连续输出概率分布,其中:
-
每一个概率分布由一个维度等于词表大小的向量所表示
-
在例子中,第一个概率分布中概率最大的那一维对应的是单词“I” 的索引号
-
在例子中,第一个概率分布中概率最大的那一维对应的是单词“am” 的索引号
-
一直重复直到输出的概率分布对应的是 ‘
<end of sentence>’ 符号

目标概率分布作为监督信号来训练模型
在对模型进行足够长时间的大数据集训练之后,我们希望得到的概率分布是这样的:

现在,因为这个模型每次产生一个输出,我们可以假设这个模型从概率分布中选择概率最大的单词,然后扔掉其余的。这是一种方法(称为贪婪解码)。另一个方法是前两个单词(说,比如“I”和“a”),然后在下一个时间步中,运行模型两次:一次假设第一个输出位置是“I”这个词,而另一个假设第一个输出位置是‘me’这个词,和哪个版本产生更少的错误考虑# 1和# 2保存位置。我们对2号和3号位置重复这个。这种方法称为“beam search”,在我们的例子中,beam_size是2(因为我们在计算位置#1和#2的beam之后比较了结果),top_beam也是2(因为我们保留了两个单词)。这两个超参数都可以进行实验。
下一步
我希望你可以从这里开始了解Transformer的主要概念。如果你想深入了解,我建议参考以下步骤:
- 阅读 Attention Is All You Need 原文, Transformer官方博文 (Transformer: A Novel Neural Network Architecture for Language Understanding),以及一个代码时间Tensor2Tensor announcement.
- 观看 Łukasz Kaiser’s talk 视频解读
- 玩一玩 Jupyter Notebook
- 探索一下 Tensor2Tensor在github上的一系列实现.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号