

[深度探索C++对象模型] 第三章 数据语意学
碎碎念一下,这一章比之前的更抽象了,有好多地方没看懂,有些内容写的语焉不详,翻译的也很奇怪,还有些内容可能和当今的开发环境不太一样了。总之,看了个大概吧。
1. 在虚拟继承的钻石结构中,每个类都是空的,但是类对象的大小却不相同,这是因为什么?
如下图所示代码:
class X {}; class Y : virtual public X {}; class Z : virtual public X {}; class A : public Y, public Z {}; int main() { auto x = new X(); auto y = new Y(); auto z = new Z(); auto a = new A(); cout << sizeof(*x) << endl; cout << sizeof(*y) << endl; cout << sizeof(*z) << endl; cout << sizeof(*a) << endl; return 0; }
在我的开发环境中(Win10x64, VS2017)输出为1,4,4,8
x大小不能为0,因为一个类对象不能为0,故有一个字节的占位符。x和y则是因为有虚函数表,a则是包含了x和y的内容。
注意,这个结构和对象的数据结构可能会根据编译器的不同和平台的不同而不同。
2. 非静态数据成员在类对象中的排列顺序和其声明的顺序是一致的。
静态数据类型会被放在数据段,与声明无关。
数据成员会因为数据对齐的原因被填充一些占位符,设计类时要注意。
访问控制关键字对内存占用不构成影响
3. 因为静态数据成员被放在数据段,故其存取不需要经过类对象,也没有效率问题。
如果有2个class声明了同名的静态数据成员,当他们被放在数据段时会导致重名冲突,此时编译器会自动为他们生成唯一的名字以避免冲突。
4. 非静态数据成员保存在每个类对象中。
对非静态数据成员的读写都是通过this指针完成(但是this指针并非数据,不占用内存)。在读写操作时,编译器会根据类对象的数据成员偏移量进行操作,偏移量在编译时就可以确定,无需等到运行时。
5. 通过类对象和类指针存取一个非静态数据成员时,效率是否会有不同?或者有何区别?
通过指针进行操作时,效率可能会更慢一些。
举例来说,通过类对象,即A.b这种方式,数据成员的偏移量在编译时即可确定,只要计算offset即可。
通过指针时,按照书中所说,若该类为派生类,即考虑多态的情况,真实的指针类型(具体的类)在运行时才能确定,即在运行时才能计算得到偏移量,故效率可能要略低。不过,我觉得即使是派生类,对于基类中的非静态数据成员,其位置也应该是固定的,没有必要先确定基类的指针。与直接使用类对象不同的时,使用指针时会多出一步进行寻址。
p->y = 0x64; 007D1B84 mov eax,dword ptr [p] 007D1B87 mov dword ptr [eax+4],64h Base p2; p2.y = 0x128; 007D1B8E mov dword ptr [ebp-14h],128h
这是我写的一段代码,在VS2017上进行反汇编,可以看到,使用指针的时候需要先进行寻址操作。不知道书中是不是这个意思。
6. 考虑以下代码中,类对象所占用内存
class C1 { private: int val; char bit1; }; class C2 : public C1 { private: char bit2; }; class C3 : public C2 { private: char bit3; }; class C4 { private: int val; char bit1; char bit2; char bit3; }; auto s1 = sizeof(c1); // 8 auto s2 = sizeof(c2); // 12 auto s3 = sizeof(c3); // 16 auto s4 = sizeof(c4); // 8
测试环境: Win10x64 VS2017
存在这种内存大小的差异是因为没有多态的继承关系中,派生类直接继承了基类对象的内存布局。
为什么要这么设计呢?而不是不需要内存对齐,直接将派生类的数据成员放在基类的数据成员之后?考虑这样一个情况,若不采用该设计,即派生类不使用基类的内存对齐,若将一个基类对象复制给派生类对象时,基类的内存对齐部分会将派生类的数据覆盖
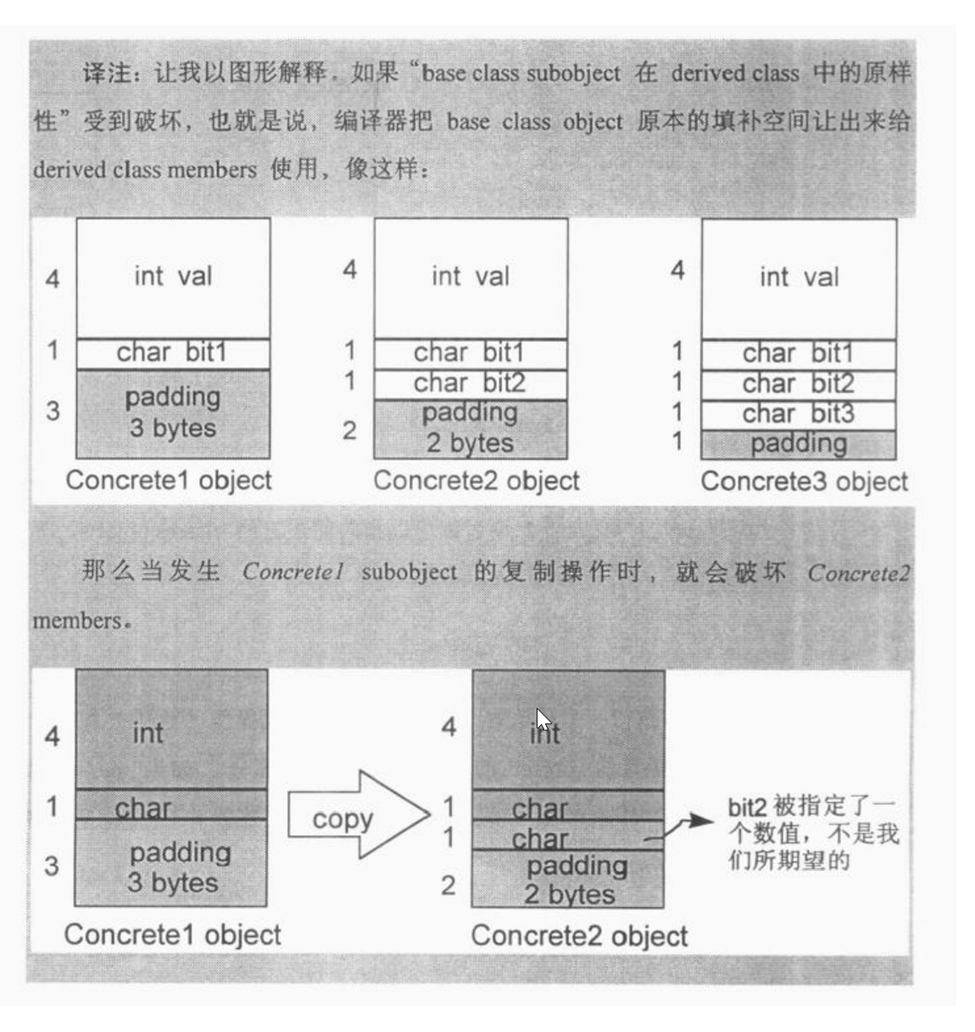
在设计类的继承关系时要考虑到内存膨胀问题。
7. 在有继承关系的类对象中,虚函数表指针所在的位置可能根据编译的不同而不同,不过目前经验表明,虚函数变指针放在对象头和尾都不太合适。比较好的做法是派生类对象直接沿用基类内存布局。
8. 含有虚拟继承关系的类对象,其内容一般会被分割成不变局部内容和共享局部内容。对于不变局部内容,无论继承关系如何,其内存布局(即offset)总是不变的。而对于共享局部内容,即虚基类中的数据(考虑钻石结构继承关系)会因为每次派生操作而变化,因此只能间接读写。不同编译器的实现亦有所不同。
(这一部分不是很懂)
微软的编译器中会在类对象中添加一个类似虚函数表的虚基类表(virtual base class table)
9. 对于虚基类,最好的运用方式是作为完全抽象的虚基类,即不含数据成员。
10. 单一继承关系中,在读写数据成员时没有效率上的影响,因为数据成员的偏移量在编译时已经确定。
编译器的‘优化’功能并不能保证总是提高运行效率,不要总是依赖编译器来进行代码的优化。
存在数据成员的虚拟继承中,执行效率会有所降低,因为读写数据是间接的,需要进行寻址。(?)
(这一部分说的主要是编译器开启优化功能对效率的影响,在debug模式下,优化没有开启,各种情况下执行效率差别不大,但是开启了优化之后,复杂的继承关系对执行效率的影响就比较明显了。这个和编译器的实现有关,不同的编译器可能结论不同)
11. 去数据成员偏移量示例
printf("&Point3d::x = %p\n", &Point3d::x);
书中说为了区分指向对象中第一个数据的指针和指向类对象的指针,每一个数据成员的偏移量会加1,但是我暂时没想出合适的代码进行验证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号