


Apache seaTunnel 数据集成平台
为什么我们需要 seatunnel
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,同时我们也发现了我们的机会 —— 通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到seatunnel这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
除了大大简化分布式数据处理难度外,seatunnel尽所能为您解决可能遇到的问题:
- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
"seatunnel" 的中文是“水滴”,来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
seatunnel 使用场景
- 海量数据ETL
- 海量数据聚合
- 多源数据处理
seatunnel 的特性
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
- Spark Structured Streaming
- 支持Spark 2.x
seatunnel 的工作流程
Input/Source[数据源输入] -> Filter/Transform[数据处理] -> Output/Sink[结果输出]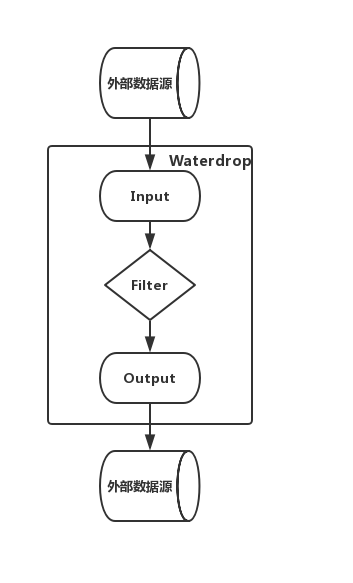
多个Filter构建了数据处理的Pipeline,满足各种各样的数据处理需求,如果您熟悉SQL,也可以直接通过SQL构建数据处理的Pipeline,简单高效。目前seatunnel支持的Filter列表, 仍然在不断扩充中。您也可以开发自己的数据处理插件,整个系统是易于扩展的。
seatunnel 支持的插件
- Input/Source plugin
Fake, File, Hdfs, Kafka, S3, Socket, 自行开发的Input plugin
- Filter/Transform plugin
Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, 自行开发的Filter plugin
- Output/Sink plugin
Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, 自行开发的Output plugin
环境依赖
-
java运行环境,java >= 8
-
如果您要在集群环境中运行seatunnel,那么需要以下Spark集群环境的任意一种:
- Spark on Yarn
- Spark Standalone
- Spark on Mesos
如果您的数据量较小或者只是做功能验证,也可以仅使用local模式启动,无需集群环境,seatunnel支持单机运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号