


第4次作业-结对编程之实验室程序实现
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11277 |
| 这个作业的目标 | 学习并使用html+css+JavaScript,并进一步体验结对编程 |
| 学号 | <031802404陈振东,031802138张雷> |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| Estimate | 估计这个任务需要多少时间 | ||
| Development | 开发 | 300 | 500 |
| Analysis | 需求分析 (包括学习新技术) | 720 | 720 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 60 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 60 | 120 |
| Coding | 具体编码 | 300 | 600 |
| Code Review | 代码复审 | 60 | 75 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 200 |
| Reporting | 报告 | 30 | 40 |
| Test Report | 测试报告 | 60 | 0 |
| Size Measurement | 计算工作量 | 15 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 45 | 120 |
| 合计 | 1710 | 2450 |
链接地址
| 结对同学的博客链接 | https://www.cnblogs.com/serioushaha/p/13780946.html |
| 本作业博客的链接| https://www.cnblogs.com/czdtcl/p/13796323.html |
| 你们队创建的仓库的GitHub项目地址 | https://github.com/936043895/031802404-031802138 |
分工
我负责 JavaScript编码实现部分,张雷同学负责用CSS页面美化设计部分。
解题思路与设计实现描述
- 代码实现思路
首先是对数据进行处理,通过群里得知数据的文本格式为每组数据间隔两行,题目要求的组内个人信息与技能树和公司经历距离为一行。
用extarea标签设置多行的文本输入,用.val()方法来处理表单元素的值,用它来获取输入文本域中的全部内容,并存储在text变量中;
多组师生信息的输入是以“\n\n\n"三个换行为标志来切分树与树,储存在text1;
在切分好的同一颗树内,用"\n\n"两个换行实现个人信息模块与技能树和公司经历的划分,储存在text2;
用"\n"一个换行区分身份标签和名字信息,储存在arry中,逐行处理,以“:”为标志进行切分,多个名字之间按照”、“标志进行切分,在切分之后,将相应的信息存储到对应的具体变量中;
我认为比较核心的一点:通过arry的长度来判断文本内容是个人信息还是技能树或公司经历,如果长度大于1为个人信息,否则为技能树或公司经历。
代码注释写的比较详细了,直接贴在下面了。
for(var tree_num = 0; tree_num < text1.length; tree_num++)
{
var text2 = text1[tree_num].split("\n\n");//对单棵树的内容进行分组,将人员信息和技能树或所在公司历程分开
//document.write("人员信息与技能树块数" + text2.length + "<br />");
for (var k = 0; k < text2.length; k++) //text1.length用于得到树的数量
{
var arry = text2[k].split("\n");//针对每一组数据,以“\n"为关键字进行分组,得到每行的信息
//document.write(arry.length);
if(arry.length > 1)//当数据内容为人员信息时,arry的长度会大于1,对人员信息先处理后再添加技能树与公司历程
{
var teacher =
{
name: '',
children: []
} //定义导师节点
//document.write("个人信息行数" + arry.length + "<br />");
for (var i = 0; i < arry.length; i++)//逐行分析
{
var newarr = arry[i].split(":");//以“:”为关键字进行分组,可得到身份标签和个人信息
var type = [];//学生节点
var type1 = [];//导师节点
var _id = newarr[0]; //newarr[0]储存的是身份标签,如导师、博士生、研究生、本科生,保存在_id变量
//document.write(_id + "<br />");
if (_id != "导师")
{
type1.name = _id;
}//记录学生身份标签
var _namearr = newarr[1];//newarr[1]储存的是名字,如天一、王二、吴五等,保存在_namearr变量
//document.write(_namearr + "<br />");
var _name = _namearr.split("、");//针对一组的多个身份信息_namearr,以“、”为关键字进行切分,得到每个人的名字信息_name
for (var j = 0; j < _name.length; j++) //_name.length用于得到每条身份信息里名字的数量
{
// document.write(_id[j]);
var student = {};
if (_id == "导师")
{
teacher.name = _name[j];
}
if (_id != "导师")
{
student.name = _name[j];
type.push(student);
}
}
if (_id != "导师")
{
type1.children = type;
teacher.children.push(type1);
}
}
}
//console.log(teacher.children[0]);
//document.write(teacher.children[0].children.length);
else //添加技能树或公司经历
- 将处理好的数据以树形结构呈现:
这个算法的实现超出了我的能力初步学习了前端的一些有关知识我还是不知道如何下手。最后,在网上查阅了相关的实现方法之后,决定利用d3.js库来实现树形结构,d3.js是一个JavaScript库,用于根据数据来处理文档,实现数据可视化。
流程图展示
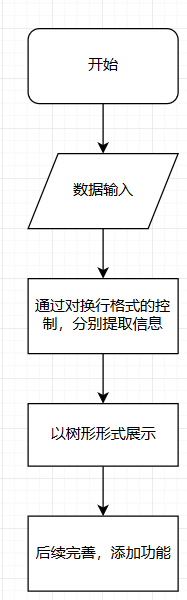
附加特点设计与展示
设计的创意独到之处:
用户在输入个人信息时不必在第一行输入导师,可以将人员信息之间乱序输入。
设计的创意独到之处,这个设计的意义:
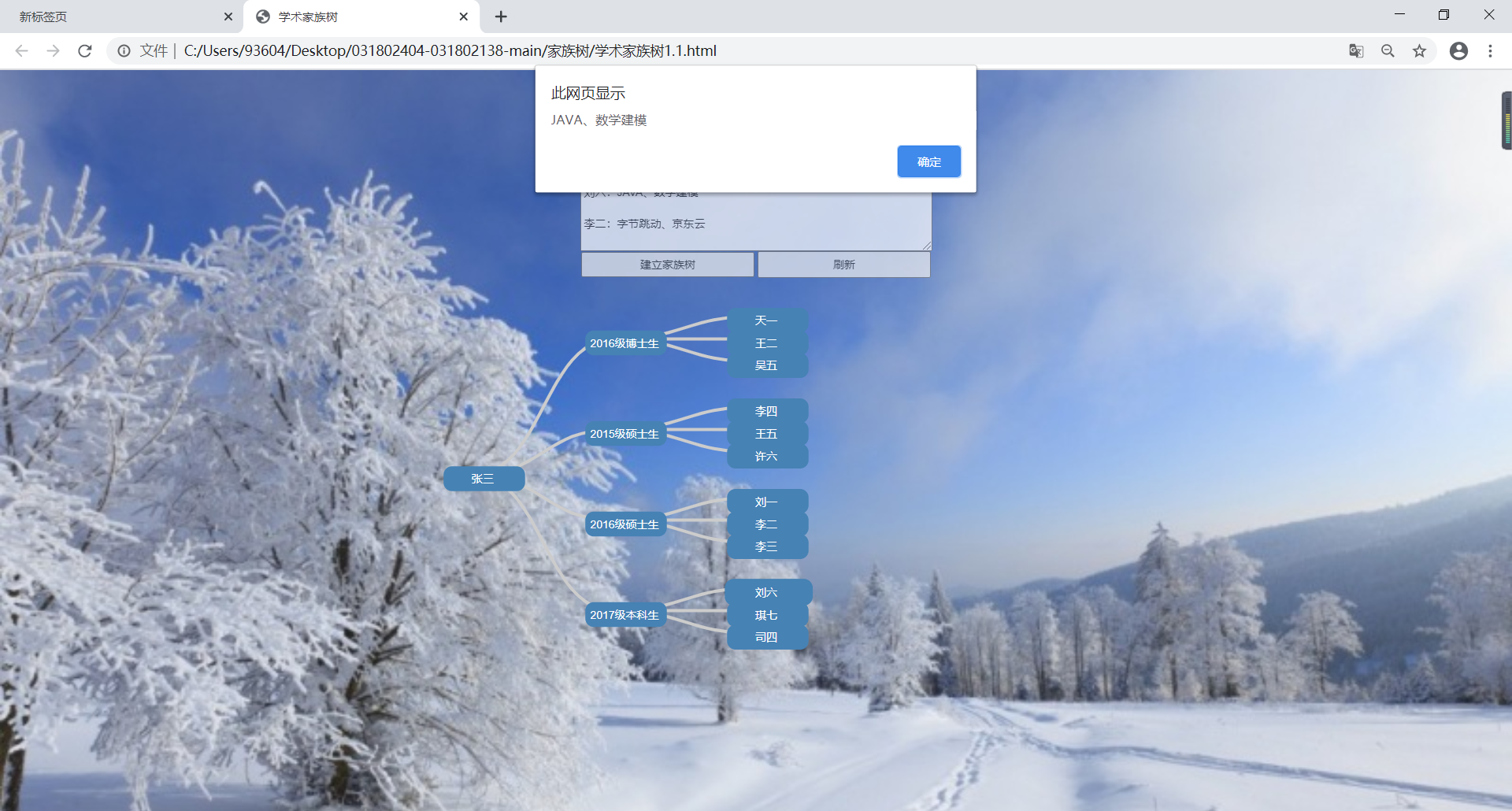
鼠标触碰到树结构的每个部分都有动画显示。使得用户获得反馈感。
输入框透明度30%,使得背景图片不被完全遮盖,视界良好。
实现思路:
hover 实现;
opacity 属性;
贴出你认为重要的/有价值的代码片段,并解释:

鼠标触碰时使节点中的文本放大到1.05倍。

由opacity属性值决定不透明度。
实现成果展示:




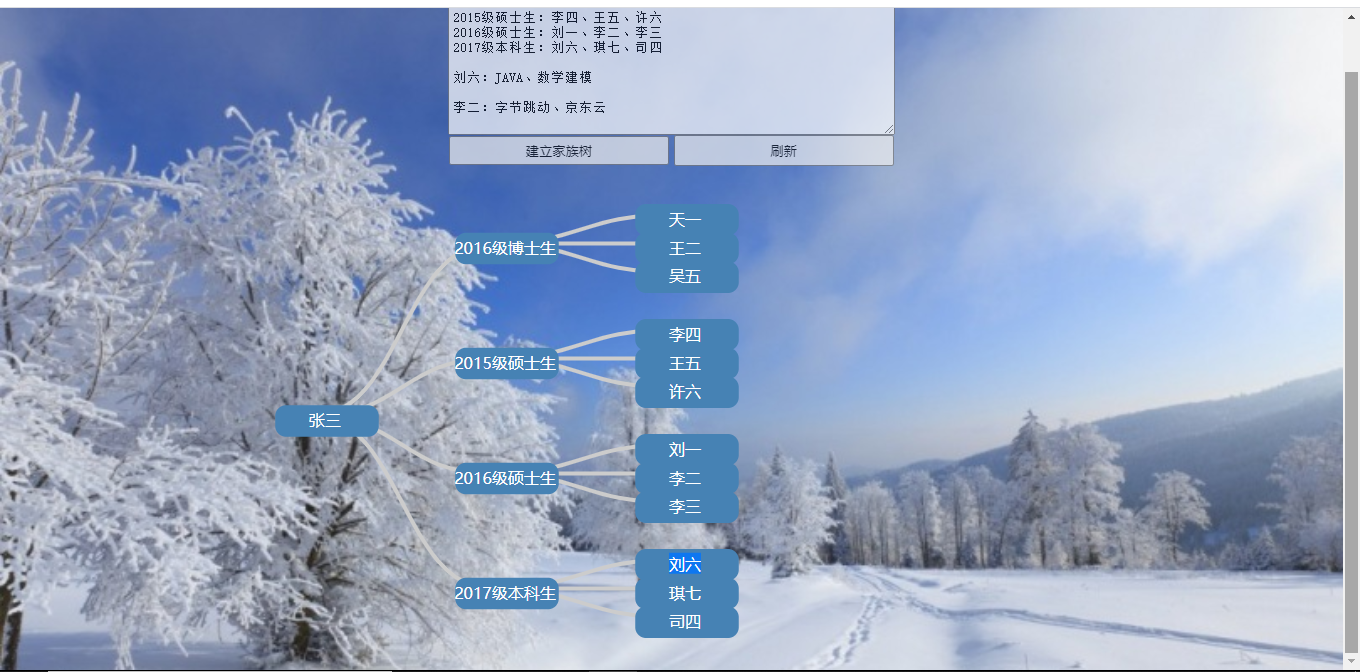
目录说明和使用说明
说明你的目录是如何组织的:
readme 放在首页,家族树文件夹中包含 HTML 文件、css 文件和背景图片,引用到的框架等都在js文件夹中。
测试人员如何运行你的网页:
下载解压后直接点击最新版本的 HTML 文件,使用 chrome 浏览器进入网页后按格式要求输入信息即可生成学术家族树。
例:
导师:张三
2016级博士生:天一、王二、吴五
2015级硕士生:李四、王五、许六
(空一行)
刘六:JAVA、数学建模
(空两行)
导师:王五
2018级本科生:刘七、张八
其中,"导师:","级博士生:","级硕士生:","级本科生:","学生名字:"和"、"当做关键词处理;
Github的代码签入记录截图

单元测试
遇到的代码模块异常或结对困难及解决方法
问题描述
1、在往已经生成好的树中添加子节点时,无法实现节点的遍历。
尝试方法:用document.write()尝试得到内容,结果发现节点没有定义。后来才了解到可以用console.log()调试,甚至能直接在控制台查看自己的json数据。逐行调试输出之后找出了原因。
是否解决:是。
2、将个人技能树与公司经历添加到节点后,无法在页面正确渲染。

解决方法:在点击交互的函数位置不采用children节点,另外单独给节点命名。
是否解决:是
有何收获:调试工具真的很有用,一开始不懂得用,浪费了好多时间,同时也清楚的意识到自己编码动手能力的薄弱,应该只是个小bug,自己花了很长时间一直没弄出来。
评价队友
值得学习的地方:有时候会有一些建设性的想法
需要改进的地方:需要一起加强学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号