
MySQL:对库、表、记录的操作 + 数据类型 + 完整的约束性 + 外键的三种关系
sql语言
sql语言是强类型的语言
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型: 1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
MySQL的各种操作
对库的操作(文件夹)
#查看所有数据库 show databases; #查看当前库 db1为数据库名 show create database db1; #查看所在的数据库 select database(); #选择数据库 use db1;
1、创建数据库
create database db1 charset utf8; help create database; #求救语法
2、查
# 查看当前创建的数据库 show create database db1; # 查看所有的数据库 show databases;
3、改
alter database db1 charset gbk;
4、删
drop database db1;
一、系统数据库
执行如下命令,查看系统库
show databases;
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
二、数据库命名规则
可以由字母、数字、下划线、@、#、$ 区分大小写 唯一性 不能使用关键字如 create select 不能单独使用数字 最长128位 # 基本上跟python或者js的命名规则一样
对表的操作(文件)
create database db1 charset utf8; #对表操作要先创建数据库,表是存储在数据库中的
use db1; #切换数据库(文件夹),对表进行操作时首先要切换到表所在的数据库 select database(); #查看当前所在数据库(文件夹)
1、创建表
#语法:
create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的
create table t1( id int, name varchar(50), age int(3) ); create table t2(id int,name char(5));
2、查
#查看当前的这张t1表 show create table t1; # 查看所有的表 show tables; # 查看t1表的详细信息 desc t1;
3、改
# modify修改的意思 alter table t1 modify name char(6); # 改变name为大写的NAME alter table t1 change name NAMA char(7);
4、删
drop table t1;
5、插入表记录(插入数据)
insert into a1 values(1,'mjj',18),(2,'wusir',28);
注意:以分号;结束作为mysql的结束语
6、查询表的数据和结构
(1)查询 t1表中的存储数据
select * from t1;
(2)查看 t1 表的结构
desc t1;
(3)查看 t1 表的详细结构
show create table t1\G;
7、复制表
需求,在新创建的数据库(db2)中,赋值数据库(db1)中的 t1表
create database db2 charset utf8; #创建数据库 db2 use db2; #选择(使用)数据库db2 create table t1 select * from db1.t1; # 复制了 db1.t1 表结构和记录 create table t2 select * from db1.t1 where 1>2; #条件不成立时,只复制表结构,不要记录, create table t3 like db1.t1; #同样只复制表结构,不复制记录
对记录的操作(数据)
1、插入数据
insert t1(id,name) values(1,"mjj01"),(2,"mjj02"),(3,"mjj03"); insert t1 values(1,"chen"),(2,"zhang"); #如果表 t1 后没有说明字段则是为所有的字段赋值
2、查看数据
select id from db1.t1; # 查看字段id, 在db1数据库中的t1表内 select id,name from t1; # 查看多字段,用逗号隔开,不写db1,指的是当前所在的数据库中的 t1 select * from db1.t1; # 查看 t1中的所有字段和记录
3、改
update db1.t1 set name="zhangsan"; update db1.t1 set name="lisi" where id=2;
4、删
delete from t1; # 删除t1中的所有记录,对于自增的会保留原来的主键 delete from t1 where id=2; # 删除 id 为2 的记录
truncate table t1; # 清空表t1中的记录,不会保留原来的主键,插入后会从1开始,清空列表时常用该方法
数据类型
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的
详细参考链接:http://www.runoob.com/mysql/mysql-data-types.html
mysql常用数据类型概括:
#1. 数字: 整型:tinyint int bigint 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) 精准 内部原理是以字符串形式去存 #2. 字符串: char(10):简单粗暴,浪费空间,存取速度快 root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。 #3. 时间类型: 最常用:datetime #4. 枚举类型与集合类型 enum 和set
一、整数型
多用于存储:年龄、等级、id、各种号码等
1、语法
======================================== tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号: ~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 ======================================== int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: ~ 4294967295 ======================================== bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: ~ 18446744073709551615
2、int类型后面有括号的话,里面的数字指的是显示的宽度,而不是存储数据的宽度


mysql> create table t3(id int(1) unsigned); #插入255555记录也是可以的 mysql> insert into t3 values(255555); mysql> select * from t3; +--------+ | id | +--------+ | 255555 | +--------+ ps:以上操作还不能够验证,再来一张表验证用zerofill 用0填充 # zerofill 用0填充 mysql> create table t4(id int(5) unsigned zerofill); mysql> insert into t4 value(1); Query OK, 1 row affected (0.00 sec) #插入的记录是1,但是显示的宽度是00001 mysql> select * from t4; +-------+ | id | +-------+ | 00001 | +-------+ row in set (0.00 sec)
注意:int类型指定宽度,为该类型指定宽度时,仅仅是指定查询结果的显示宽度,与存储范围无关
int类型的存储位数默认是10位,则显示的宽度最大值的基础上加1,是10+1 (11)
整型类型,其实没有必要指定显示的宽度,使用默认的就ok了
3、mysql中没有boolean值,使用tinyint(1)构造
二、浮点型
float double decimal
多用于存储:薪资、身高、体重、体质参数等
| MySQL数据类型 |
含义 |
| float(m,d) |
单精度浮点型 8位精度(4字节) m总个数,d小数位 |
| double(m,d) |
双精度浮点型 16位精度(8字节) m总个数,d小数位 |
| decimal(m,d) |
参数 m<65 是总个数,d<30 且 d<m 是小数位。 |
语法:
-------------------------FLOAT------------------- FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释:单精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 #无符号: 1.175494351E-38 to 3.402823466E+38 #精确度: **** 随着小数的增多,精度变得不准确 **** -------------------------DOUBLE----------------------- DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] #参数解释: 双精度浮点数(非准确小数值),M是全长,D是小数点后个数。M最大值为255,D最大值为30 #有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 #无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 #精确度: ****随着小数的增多,精度比float要高,但也会变得不准确 **** ====================================== --------------------DECIMAL------------------------ decimal[(m[,d])] [unsigned] [zerofill] #参数解释:准确的小数值,M是整数部分总个数(负号不算),D是小数点后个数。 M最大值为65,D最大值为30。 #精确度: **** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。
设一个字段定义为 float(5,3),如果插入一个数 123.45678,实际数据库里存的是 123.457,但总个数还以实际为准,即 6 位。
float double在数据库中存放的是近似值,而 decimal 类型在数据库中存放的是精确值。
三、日期类型
year date time datetime
多用于存储:用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
语法: YEAR YYYY(1901/2155) DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS('-838:59:59'/'838:59:59') DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
若定义一个字段为timestamp(了解即可),这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
示例: create table t8(born_year year) insert into t8 values (2001),(1995); #连续插入为两行,一个括号代表的是一行 insert into t8 values (2156); # 错误,超出范
注意:now() 的内置函数会自动获取当前的时间
1、datatime 和 timesstamp的区别
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。 下面就来总结一下两种日期类型的区别。 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器, 操作系统以及客户端连接都有时区的设置。 3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。 4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP), 如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
2、 注意事项
============注意啦,注意啦,注意啦=========== #1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 #2. 插入年份时,尽量使用4位值 #3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 create table t12(y year); insert into t12 values (50),(71); select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+
3、综合练习
需求:创建一张学生表(student),要求有id,姓名,出生年份,出生的年月日,进班的时间,以及来老男孩学习的现在具体时间。
mysql> create table student( -> id int, -> name varchar(20), -> born_year year, -> birth date, -> class_time time, -> reg_time datetime -> ); Query OK, 0 rows affected (0.02 sec) mysql> insert into student values -> (1,'alex',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"), -> (2,'egon',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"), -> (3,'wsb',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13"); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from student; +------+------+-----------+------------+------------+---------------------+ | id | name | born_year | birth | class_time | reg_time | +------+------+-----------+------------+------------+---------------------+ | 1 | alex | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 | | 2 | egon | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 | | 3 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 | +------+------+-----------+------------+------------+---------------------+ rows in set (0.00 sec)
四、字符类型(char varchar)
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html #注意:char和varchar括号内的参数指的都是字符的长度
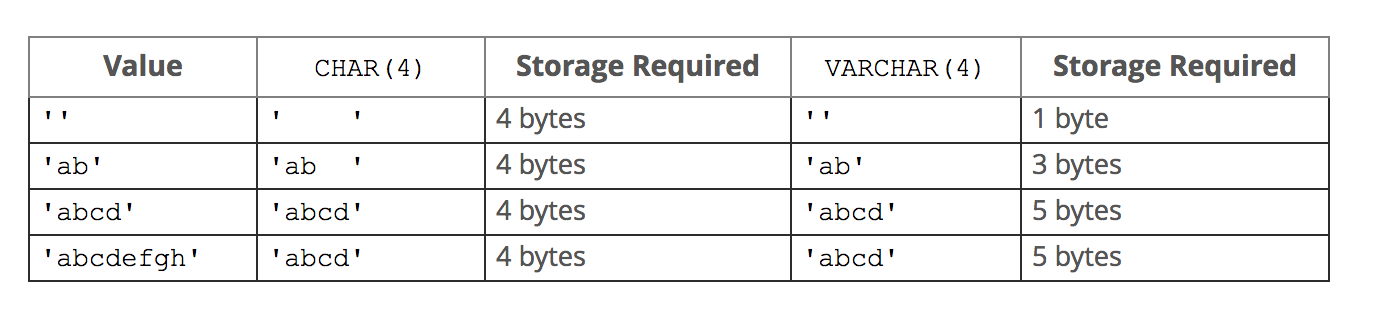
#char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(设置SQL模式:SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; 查询sql的默认模式:select @@sql_mode;)
#varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
1、官方解释
验证:
length():查看字节数
char_length():查看字符数
2、char填充空格来满足固定长度,但是在查询的时候却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形。
验证:了解
# 创建t1表,分别指明字段x为char类型,字段y为varchar类型 mysql> create table t1(x char(5),y varchar(4)); Query OK, 0 rows affected (0.16 sec) # char存放的是5个字符,而varchar存4个字符 mysql> insert into t1 values('你瞅啥 ','你瞅啥 '); Query OK, 1 row affected (0.01 sec) # 在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少 mysql> select x,char_length(x),y,char_length(y) from t1; +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 你瞅啥 | 3 | 你瞅啥 | 4 | +-----------+----------------+------------+----------------+ row in set (0.02 sec) #略施小计,让char现原形 mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) #查看当前mysql的mode模式 mysql> select @@sql_mode; +-------------------------+ | @@sql_mode | +-------------------------+ | PAD_CHAR_TO_FULL_LENGTH | +-------------------------+ row in set (0.00 sec) #原形毕露了吧。。。。 mysql> select x,char_length(x) y,char_length(y) from t1; +-------------+------+----------------+ | x | y | char_length(y) | +-------------+------+----------------+ | 你瞅啥 | 5 | 4 | +-------------+------+----------------+ row in set (0.00 sec) # 查看字节数 #char类型:3个中文字符+2个空格=11Bytes #varchar类型:3个中文字符+1个空格=10Bytes mysql> select x,length(x),y,length(y) from t1; +-------------+-----------+------------+-----------+ | x | length(x) | y | length(y) | +-------------+-----------+------------+-----------+ | 你瞅啥 | 11 | 你瞅啥 | 10 | +-------------+-----------+------------+-----------+ row in set (0.02 sec)
3、总结
#常用字符串系列:char与varchar 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
#其他字符串系列(效率:char>varchar>text) TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB BINARY系列 BINARY VARBINARY text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
五、枚举类型和集合类型
字段的值只能在给定范围中选择,如单选框,多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
mysql> create table consumer( -> id int, -> name varchar(50), -> sex enum('male','female','other'), -> level enum('vip1','vip2','vip3','vip4'),#在指定范围内,多选一 -> fav set('play','music','read','study') #在指定范围内,多选多 -> ); Query OK, 0 rows affected (0.03 sec)
mysql> insert into consumer values -> (1,'赵云','male','vip2','read,study'), -> (2,'赵云2','other','vip4','play'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from consumer; +------+---------+-------+-------+------------+ | id | name | sex | level | fav | +------+---------+-------+-------+------------+ | 1 | 赵云 | male | vip2 | read,study | | 2 | 赵云2 | other | vip4 | play | +------+---------+-------+-------+------------+ rows in set (0.00 sec)
完整性的约束
-
not null 与 default
-
unique
-
primary key
-
auto_increment
-
foreign key
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) #标识该字段为该表的主键,可以唯一的标识记录 FOREIGN KEY (FK) #标识该字段为该表的外键 NOT NULL #标识该字段不能为空 UNIQUE KEY (UK) #标识该字段的值是唯一的 AUTO_INCREMENT #标识该字段的值自动增长(整数类型,而且为主键) DEFAULT #为该字段设置默认值 UNSIGNED #无符号 ZEROFILL #使用0填充
说明:
#1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值 #2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值 sex enum('male','female') not null default 'male'; #sex字段,枚举类型不能为空,如果没有赋值,则为male #必须为正值(无符号) 不允许为空 默认是20 age int unsigned NOT NULL default 20
# 3. 是否是key 主键 primary key 外键 foreign key 索引 (index,unique...)
一、not null 和 default
是否为空,null表示空,非字符串
not null - 不可为空
null - 可以为空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1( nid int not null defalut 2, num int not null );
总结:
默认值可以为空
设置 not null,插入的值不能为空,会报错
设置 id 字段有默认值后,无论是null 还是 not null,都可以插入空值,插入空默认填入default指定的默认值处
二、unique
1、单列唯一
示例:需求,创建公司部门表(每个公司都有唯一的一个部门)
#第一种创建unique的方式 #例子1: create table department( id int, name char(10) unique ); mysql> insert into department values(1,'it'),(2,'it'); ERROR 1062 (23000): Duplicate entry 'it' for key 'name'
#例子2: create table department( id int unique, name char(10) unique ); insert into department values(1,'it'),(2,'sale');
#第二种创建unique的方式 create table department( id int, name char(10) , unique(id), unique(name) ); insert into department values(1,'it'),(2,'sale');
总结:
id int unique; 单列唯一,id必须是唯一的name也必须是唯一的
unique(id);
2、联合唯一
# 创建services表 mysql> create table services( -> id int, -> ip char(15), -> port int, -> unique(id), -> unique(ip,port) -> ); Query OK, 0 rows affected (0.05 sec) mysql> desc services; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | YES | UNI | NULL | | | ip | char(15) | YES | MUL | NULL | | | port | int(11) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ rows in set (0.01 sec)
#联合唯一,只要两列记录,有一列不同,既符合联合唯一的约束 mysql> insert into services values -> (1,'192,168,11,23',80), -> (2,'192,168,11,23',81), -> (3,'192,168,11,25',80); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from services; +------+---------------+------+ | id | ip | port | +------+---------------+------+ | 1 | 192,168,11,23 | 80 | | 2 | 192,168,11,23 | 81 | | 3 | 192,168,11,25 | 80 | +------+---------------+------+ rows in set (0.00 sec) mysql> insert into services values (4,'192,168,11,23',80); # 不能有两个记录中的组合联合字段,完全一样 ERROR 1062 (23000): Duplicate entry '192,168,11,23-80' for key 'ip'
总结:
unique(ip,port); 组合唯一,只要两列记录,有一列不同,既符合联合唯一的约束
也就是两条记录中,不能存在组合唯一字段(ip port)中的值完全一样
三、primary key
一个表中可以,单列做主键,也可以多列做主键(复合主键)
约束:等价于 not null unique,字段的值不能为空且唯一
存储的引擎默认是 innodb, 对于innodb来说,一张表只能有一个主键,因此,符合主键不常用
1、单列主键
# 创建t14表,为id字段设置主键,唯一的不同的记录 create table t14( id int primary key, name char(16) ); insert into t14 values (1,'xiaoma'), (2,'xiaohong'); mysql> insert into t14 values(2,'wxxx'); ERROR 1062 (23000): Duplicate entry '6' for key 'PRIMARY'
# not null + unique的化学反应,相当于给id设置primary key create table t15( id int not null unique, name char(16) ); mysql> create table t15( -> id int not null unique, -> name char(16) -> ); Query OK, 0 rows affected (0.01 sec) mysql> desc t15; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | char(16) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ rows in set (0.02 sec)
2、复合主键
create table t16( ip char(15), port int, primary key(ip,port) ); insert into t16 values ('1.1.1.2',80), ('1.1.1.2',81); #正确可以运行 验证复合主键的使用
四、auto_increment
约束的字段为自动增长,约束的字段必须同时被key约束,即和 primary key 等连用
重点验证:
1、不指定id, id会自动增长
# 创建student create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> desc student; +-------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | YES | | male | | +-------+-----------------------+------+-----+---------+----------------+ rows in set (0.17 sec) #插入记录 mysql> insert into student(name) values ('老白'),('小白'); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from student; +----+--------+------+ | id | name | sex | +----+--------+------+ | 1 | 老白 | male | | 2 | 小白 | male | +----+--------+------+ rows in set (0.00 sec) 不指定id,则自动增长
2、也可以指定id, id可以隔几个指定,比如之间有1,2 插入的还是可以指定id是4,
但是再次插入的时候如果不指定id的话,会在最大的 id(4)的基础上依次增加
mysql> insert into student values(4,'asb','female'); Query OK, 1 row affected (0.00 sec) mysql> insert into student values(7,'wsb','female'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+--------+--------+ | id | name | sex | +----+--------+--------+ | 1 | 老白 | male | | 2 | 小白 | male | | 4 | asb | female | | 7 | wsb | female | +----+--------+--------+ rows in set (0.00 sec) # 再次插入一条不指定id的记录,会在之前的最后一条记录继续增长 mysql> insert into student(name) values ('大白'); Query OK, 1 row affected (0.00 sec) mysql> select * from student; +----+--------+--------+ | id | name | sex | +----+--------+--------+ | 1 | 老白 | male | | 2 | 小白 | male | | 4 | asb | female | | 7 | wsb | female | | 8 | 大白 | male | +----+--------+--------+ rows in set (0.00 sec) 也可以指定id
3、对于自增的字段,在用delete删除之后,再插入值,该字段仍然按照删除前的顺序继续增长,删除以后将不会再有该值,比如删除了3,但是插入的时候如果指定是3,是可以添加成功的
mysql> delete from student; Query OK, 5 rows affected (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> insert into student(name) values('ysb'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 9 | ysb | male | +----+------+------+ row in set (0.00 sec) #应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它 mysql> truncate student; Query OK, 0 rows affected (0.03 sec) mysql> insert into student(name) values('xiaobai'); Query OK, 1 row affected (0.00 sec) mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | +----+---------+------+ row in set (0.00 sec) mysql> 对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
4、了解 auto_increment_increment 和 auto_increment_offset
查看可用的 开头auto_inc的词 mysql> show variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ rows in set (0.02 sec) # 步长auto_increment_increment,默认为1 # 起始的偏移量auto_increment_offset, 默认是1 # 设置步长 为会话设置,只在本次连接中有效 set session auto_increment_increment=5; #全局设置步长 都有效。 set global auto_increment_increment=5; # 设置起始偏移量 set global auto_increment_offset=3; #强调:If the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored. 翻译:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 # 设置完起始偏移量和步长之后,再次执行show variables like'auto_inc%'; 发现跟之前一样,必须先exit,再登录才有效。 mysql> show variables like'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 5 | | auto_increment_offset | 3 | +--------------------------+-------+ rows in set (0.00 sec) #因为之前有一条记录id=1 mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | +----+---------+------+ row in set (0.00 sec) # 下次插入的时候,从起始位置3开始,每次插入记录id+5 mysql> insert into student(name) values('ma1'),('ma2'),('ma3'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | | 3 | ma1 | male | | 8 | ma2 | male | | 13 | ma3 | male | +----+---------+------+ auto_increment_increment和 auto_increment_offset
5、清空列表 delete和truncate的区别
delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。 truncate table t1;数据量大,删除速度比上一条快,且直接从零开始。
五、foreign key
外键,用于建立表与表之间的联系
1、分析
之前创建表的时候都是在一张表中添加记录,比如如下表:
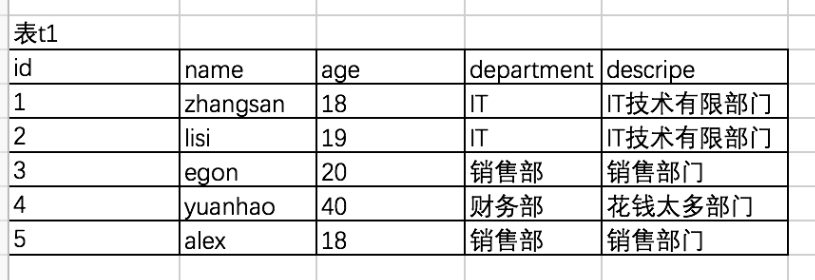
如果公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费。
这个时候,解决方法:
我们完全可以定义一个部门表
然后让员工信息表关联该表,如何关联,即foreign key
我们可以将上表改为如下结构:

此时有两张表,一张是employee表,简称emp表(关联表,也就从表)。一张是department表,简称dep表(被关联表,也叫主表)。
2、创建两张表操作
(1)创建表时先创建被关联表,再创建关联表
# 先创建被关联表(dep表) create table dep( id int primary key, name varchar(20) not null, descripe varchar(20) not null ); #再创建关联表(emp表) create table emp( id int primary key, name varchar(20) not null, age int not null, dep_id int, constraint fk_dep foreign key(dep_id) references dep(id) );
(2)向表中插入记录的时候,先往被关联表中插入记录,再往关联表中插入记录
# 先创建被关联表(dep表) create table dep( id int primary key, name varchar(20) not null, descripe varchar(20) not null ); #再创建关联表(emp表) create table emp( id int primary key, name varchar(20) not null, age int not null, dep_id int, constraint fk_dep foreign key(dep_id) references dep(id) );
(3)删除表,一般的来说,删除了部门表中的某个部门,员工表中的有关联的记录也会相继删除,但是没有设置同步更新,同步删除的话,直接删除部门是删除不掉的,除非没有员工记录,也就是,先删除员工表中记录之后,再删除当前部门就没有任何的问题
#按道理来说,删除了部门表中的某个部门,员工表的有关联的记录相继删除。 mysql> delete from dep where id=3; ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`db5`.`emp`, CONSTRAINT `fk_name` FOREIGN KEY (`dep_id`) REFERENCES `dep` (`id`)) #但是先删除员工表的记录之后,再删除当前部门就没有任何问题 mysql> delete from emp where dep =3; Query OK, 1 row affected (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 18 | 1 | | 3 | egon | 20 | 2 | | 5 | alex | 18 | 2 | +----+----------+-----+--------+ 4 rows in set (0.00 sec) mysql> delete from dep where id=3; Query OK, 1 row affected (0.00 sec) mysql> select * from dep; +----+-----------+----------------------+ | id | name | descripe | +----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 2 | 销售部 | 销售部门 | +----+-----------+----------------------+ 2 rows in set (0.00 sec)
3、同步删除、同步更新
上面的删除表记录的操作比较繁琐,按道理讲,裁掉一个部门,该部门的员工也会被裁掉。其实呢,在建表的时候还有个很重要的内容,叫同步删除,同步更新
接下来将刚建好的两张表全部删除,先删除关联表(emp),再删除被关联表(dep)
接下来:重复上面的操作建表,
注意:在关联表中要加入 on delete cascade #同步删除
on update cascade #同步更新
修改emp表(关联表):
create table emp( id int primary key, name varchar(20) not null, age int not null, dep_id int, constraint fk_dep foreign key(dep_id) references dep(id) on delete cascade #同步删除 on update cascade #同步更新 );
接下来的验证,就符合正常生活中的情况了:
#再去删被关联表(dep)的记录,关联表(emp)中的记录也跟着删除 mysql> delete from dep where id=3; Query OK, 1 row affected (0.00 sec) mysql> select * from dep; +----+-----------+----------------------+ | id | name | descripe | +----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 2 | 销售部 | 销售部门 | +----+-----------+----------------------+ rows in set (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 19 | 1 | | 3 | egon | 20 | 2 | | 5 | alex | 18 | 2 | +----+----------+-----+--------+ rows in set (0.00 sec)
#再去更改被关联表(dep)的记录,关联表(emp)中的记录也跟着更改 mysql> update dep set id=222 where id=2; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0
# 赶紧去查看一下两张表是否都被删除了,是否都被更改了 mysql> select * from dep; +-----+-----------+----------------------+ | id | name | descripe | +-----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 222 | 销售部 | 销售部门 | +-----+-----------+----------------------+ rows in set (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 19 | 1 | | 3 | egon | 20 | 222 | | 5 | alex | 18 | 222 | +----+----------+-----+--------+ rows in set (0.00 sec)
外键的变种 三种关系
一、介绍
因为有foreign key的约束,使得两张表形成了三种了关系:
- 多对一
- 多对多
- 一对一
二、重点理解如何找出两种表之间的关系
分析步骤: #1、先站在左表的角度去找 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找 是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#3、总结: #多对一: 如果只有步骤1成立,则是左表多对一右表 如果只有步骤2成立,则是右表多对一左表 #多对多 如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系 #一对一: 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
三、表的三种关系
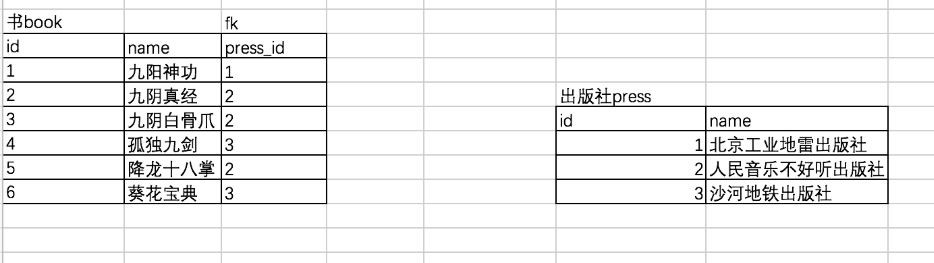
1、书和出版社
一对多(或多对一,出版社和书):一个出版社可以出版多本书,一本书只能被一个出版社出版(盗版除外),
关联的方式: foreign key
创建表的操作:
书和出版社(一对多):
# 关联的语句,要记住
constraint fk_book_press foreign key(press_id) references press(id) on delete cascade on update cascade
create table press( id int primary key auto_increment, name varchar(20) ); create table book( id int primary key auto_increment, name varchar(20), press_id int not null, constraint fk_book_press foreign key(press_id) references press(id) on delete cascade on update cascade ); # 先往被关联表中插入记录 insert into press(name) values ('北京工业地雷出版社'), ('人民音乐不好听出版社'), ('知识产权没有用出版社') ; # 再往关联表中插入记录 insert into book(name,press_id) values ('九阳神功',1), ('九阴真经',2), ('九阴白骨爪',2), ('独孤九剑',3), ('降龙十巴掌',2), ('葵花宝典',3) ; 查询结果: mysql> select * from book; +----+-----------------+----------+ | id | name | press_id | +----+-----------------+----------+ | 1 | 九阳神功 | 1 | | 2 | 九阴真经 | 2 | | 3 | 九阴白骨爪 | 2 | | 4 | 独孤九剑 | 3 | | 5 | 降龙十巴掌 | 2 | | 6 | 葵花宝典 | 3 | +----+-----------------+----------+ rows in set (0.00 sec) mysql> select * from press; +----+--------------------------------+ | id | name | +----+--------------------------------+ | 1 | 北京工业地雷出版社 | | 2 | 人民音乐不好听出版社 | | 3 | 知识产权没有用出版社 | +----+--------------------------------+ rows in set (0.00 sec) 书和出版社(多对一)
2、作者和书籍
多对多:一个作者可以写很多本书,一本书,也可以有多个作者,双向的一对多,就是多对多。
关联方式:foreign key + 一张新的表

创建表的操作:
作者和书籍的关系(多对多)
# 创建被关联表author表,之前的book表在讲多对一的关系已创建 create table author( id int primary key auto_increment, name varchar(20) ); #这张表就存放了author表和book表的关系,即查询二者的关系查这表就可以了 create table author2book( id int not null unique auto_increment, author_id int not null, book_id int not null, constraint fk_author foreign key(author_id) references author(id) on delete cascade on update cascade, constraint fk_book foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(author_id,book_id) ); #插入四个作者,id依次排开 insert into author(name) values('egon'),('alex'),('wusir'),('yuanhao'); # 每个作者的代表作 egon: 九阳神功、九阴真经、九阴白骨爪、独孤九剑、降龙十巴掌、葵花宝典 alex: 九阳神功、葵花宝典 wusir:独孤九剑、降龙十巴掌、葵花宝典 yuanhao:九阳神功 # 在author2book表中插入相应的数据 insert into author2book(author_id,book_id) values (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (2,1), (2,6), (3,4), (3,5), (3,6), (4,1) ; # 现在就可以查author2book对应的作者和书的关系了 mysql> select * from author2book; +----+-----------+---------+ | id | author_id | book_id | +----+-----------+---------+ | 1 | 1 | 1 | | 2 | 1 | 2 | | 3 | 1 | 3 | | 4 | 1 | 4 | | 5 | 1 | 5 | | 6 | 1 | 6 | | 7 | 2 | 1 | | 8 | 2 | 6 | | 9 | 3 | 4 | | 10 | 3 | 5 | | 11 | 3 | 6 | | 12 | 4 | 1 | +----+-----------+---------+ rows in set (0.00 sec) 作者与书籍关系(多对多)
3、用户和博客
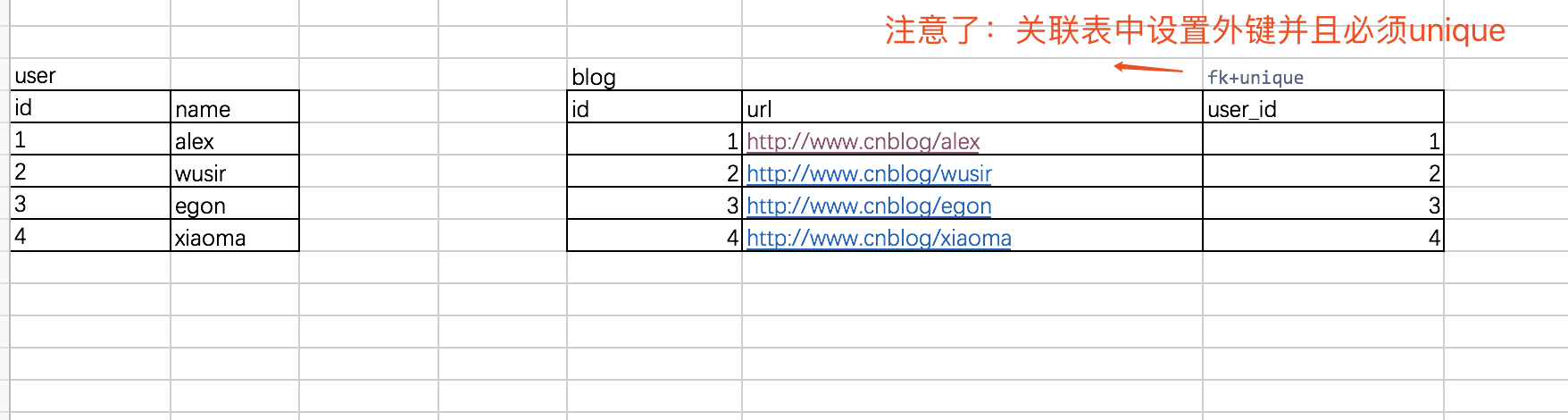
一对一:一个用户只能注册一各博客账号,一个博客账号也只能有一个用户,即一对一的关系。
关联方式:foreign key + unique
创建表的操作
用户和博客,一对一的操作
#例如: 一个用户只能注册一个博客 #两张表: 用户表 (user)和 博客表(blog) # 创建用户表 create table user( id int primary key auto_increment, name varchar(20) ); # 创建博客表 create table blog( id int primary key auto_increment, url varchar(100), user_id int unique, constraint fk_user foreign key(user_id) references user(id) on delete cascade on update cascade ); #插入用户表中的记录 insert into user(name) values ('alex'), ('wusir'), ('egon'), ('xiaoma') ; # 插入博客表的记录 insert into blog(url,user_id) values ('http://www.cnblog/alex',1), ('http://www.cnblog/wusir',2), ('http://www.cnblog/egon',3), ('http://www.cnblog/xiaoma',4) ; # 查询wusir的博客地址 select url from blog where user_id=2; 用户和博客(一对一)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号