
操作系统/应用程序 + 并发/并行 + 线程/进程 + python中的线程编写


总结: 1. 应用程序/进程/线程的关系? *****(面试题:进程/线程/协程的区别?) 2. 为什么要创建线程? 由于线程是cpu工作的最小单元,创建线程可以利用多核优势实现并行操作(Java/C#)。 注意:线程是为了工作。 3. 为什么要创建进程? 进程和进程之间做数据隔离(Java/C#)。 注意:进程是为了提供环境让线程工作。 4. Python a. Python中存在一个GIL锁。 ***** - 造成:多线程无法利用多核优势。 - 解决:开多进程处理(浪费资源) 总结: IO密集型:多线程 计算密集型:多进程 b. 线程的创建 - Thread ***** - MyThread c. 其他 - join ***** - setDeanon ***** - setName ***** - threading.current_thread() ***** d. 锁 - 获得 - 释放
操作系统/应用程序
1. 硬件
硬盘 CPU 主板 显卡 内存 电源
2. 装系统
系统是一个由程序员写出来的软件,该软件用于控制计算机的硬件,让他们之间进行相互配合.
3. 安装软件
安装的是应用程序 例如: QQ 百度云 pycharm 等.
并发/并行
并发和并行是针对操作系统:
并发: 伪, 由于执行的速度特别的快,人感觉不到停顿
并行: 真, 创建多个同时操作
线程/进程
1. 什么是线程, 为什么创建线程?
线程是CUP工作的最小单元,创建线程可以利用多核的优势实现并行操作. (Java/C#)
线程是为了工作, 在python中,创建线程并不能利用多核的优势.
2. 什么是进程, 为什么创建进程?
进程是为了提供环境让线程工作, 为线程提供一个资源共享的空间.
创建多个进程,是为了独立开辟内存, 进程和进程之间做数据隔离. (Java/C#)
注意: python本身没有线程和进程, 是调用操作系统的线程和进程.
3. 单进程 / 单线程 的应用
平常写的程序: 如 print(666) 就会一个简单的单线程和单进程的应用.
4. 单进程 / 多线程 的应用
import threading print('666') def func(arg): print(arg) t = threading.Thread(target=func) # 创建线程 t.start() print('end')
总结:
1. 一个应用程序(软件), 可以有多个进程,(默认有一个进程), 其中,一个进程中(默认有一个主线程),也可以创建多个线程.
2. 操作系统帮助开发人者操作硬件, 程序员写好的代码在操作系统上运行,需要依赖解释器.
当任务非常多时:
import requests import uuid url_list = [ 'https://www3.autoimg.cn/newsdfs/g28/M05/F9/98/120x90_0_autohomecar__ChsEnluQmUmARAhAAAFES6mpmTM281.jpg', 'https://www2.autoimg.cn/newsdfs/g28/M09/FC/06/120x90_0_autohomecar__ChcCR1uQlD6AT4P3AAGRMJX7834274.jpg', 'https://www2.autoimg.cn/newsdfs/g3/M00/C6/A9/120x90_0_autohomecar__ChsEkVuPsdqAQz3zAAEYvWuAspI061.jpg', ] def task(url): """""" """ 1. DNS解析,根据域名解析出IP 2. 创建socket客户端 sk = socket.socket() 3. 向服务端发起连接请求 sk.connect() 4. 发送数据(我要图片) sk.send(...) 5. 接收数据 sk.recv(8096) 接收到数据后写入文件。 """ ret = requests.get(url) file_name = str(uuid.uuid4()) + '.jpg' with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: task() """ - 你写好代码 - 交给解释器运行: python s1.py - 解释器读取代码,再交给操作系统去执行,根据你的代码去选择创建多少个线程/进程去执行(单进程/单线程)。 - 操作系统调用硬件:硬盘、cpu、网卡.... """
import threading import requests import uuid url_list = [ 'https://www3.autoimg.cn/newsdfs/g28/M05/F9/98/120x90_0_autohomecar__ChsEnluQmUmARAhAAAFES6mpmTM281.jpg', 'https://www2.autoimg.cn/newsdfs/g28/M09/FC/06/120x90_0_autohomecar__ChcCR1uQlD6AT4P3AAGRMJX7834274.jpg', 'https://www2.autoimg.cn/newsdfs/g3/M00/C6/A9/120x90_0_autohomecar__ChsEkVuPsdqAQz3zAAEYvWuAspI061.jpg', ] def task(url): """""" """ 1. DNS解析,根据域名解析出IP 2. 创建socket客户端 sk = socket.socket() 3. 向服务端发起连接请求 sk.connect() 4. 发送数据(我要图片) sk.send(...) 5. 接收数据 sk.recv(8096) 接收到数据后写入文件。 """ ret = requests.get(url) file_name = str(uuid.uuid4()) + '.jpg' with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: t = threading.Thread(target=task, args=(url,)) # 创建线程 t.start() """ - 你写好代码 - 交给解释器运行: python s2.py - 解释器读取代码,再交给操作系统去执行,根据你的代码去选择创建多少个线程/进程去执行(单进程/4线程)。 - 操作系统调用硬件:硬盘、cpu、网卡.... """
5. 其他语言 (java c#) 中的线程和进程
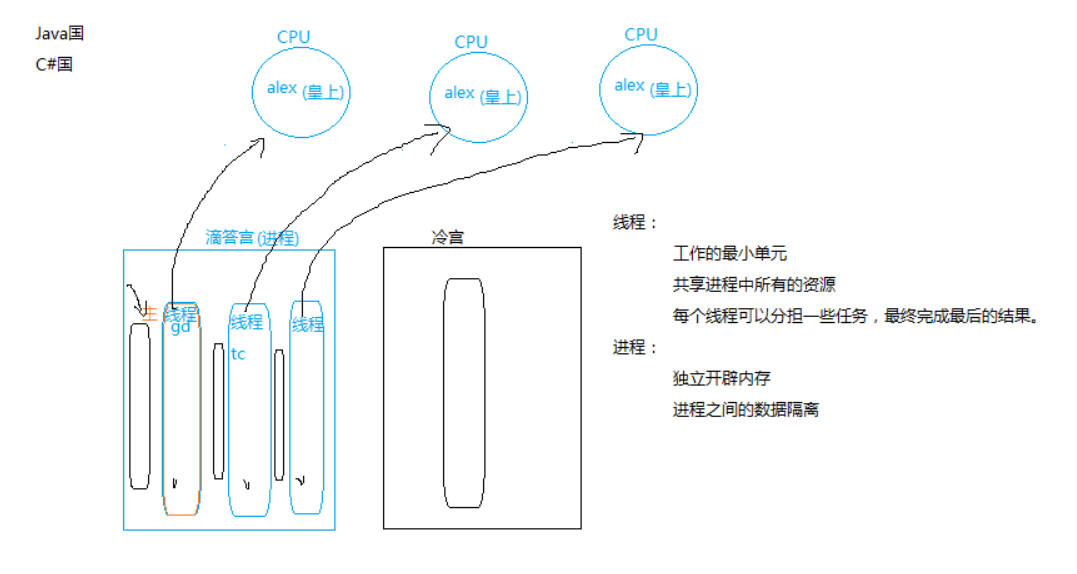
结论:
多核指有多个CPU, 在 java和c# 中:
同一个进程中的多个线程, 可以同时被多个cpu调度, 效率高, 充分发挥多核的优势.
因此不必创建多个进程,避免浪费资源.
6. python 中的线程和进程
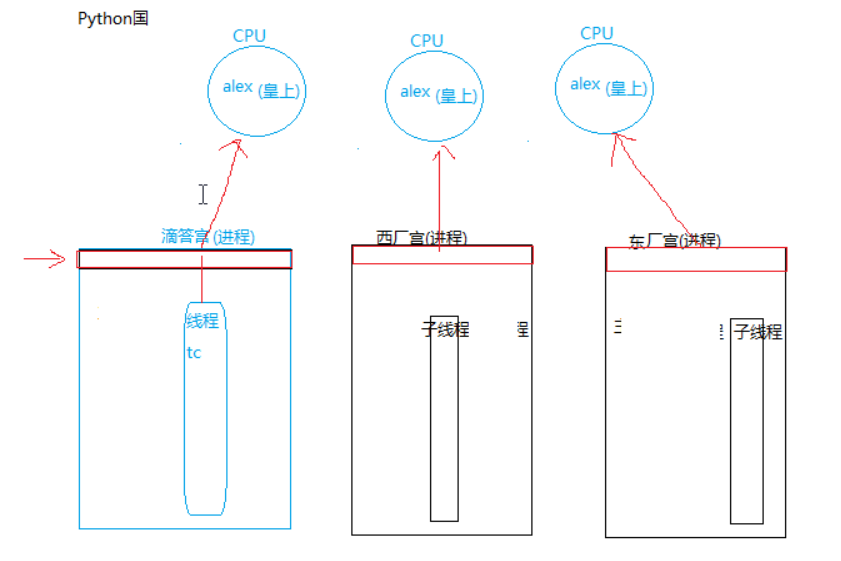
结论:
多核指有多个CPU, 在 python 中:
一个进程中的同一时刻只能有一个线程被CPU调度, 当进程中存在多个线程时, cpu会每个线程调度一会(一会具体指的是100个指令),
查看cpu调度 gil切换指令,多少用如下方法:
import sys v1 = sys.getcheckinterval() print(v1) # 100
1. 造成这种 一个进程中的同一时刻只能有一个线程被CPU调度 的原因?
在python语言中,进程中含有GIL锁,全局解释器锁, 用于限制一个进程同意时刻只有一个线程被CPU调度.
默认GIL锁在执行100个cpu指令(过期), 切换到另外的线程.
2. 什么是GIL锁?
GIL锁是python内置的一个全局解释器锁, 锁的作用是保证同一时刻一个进程中只有一个线程被调度.
3. 为什么会有GIL锁?
python 语言的创始人在开发这门语言的时候,目的是快速的把语言开发出来,如果加上GIL锁(c语言加锁), 切换时按照100条指令来进行线程间的切换.
4. 线程创建的越多越好吗?
不是的, 线程之间进行切换时, 要做上下文的管理,(在切换的时候要把被切换的线程的状态记录下来)
总结:
Python多线程情况下:
- 计算密集型操作:效率低。(GIL锁)
- IO操作: 效率高
Python多进程的情况下:
- 计算密集型操作:效率高(浪费资源)。 不得已而为之。
- IO操作: 效率高 (浪费资源)。
以后写Python时:
IO密集型用多线程: 文件/输入输出/socket网络通信
计算密集型用多进程。
扩展:
Java多线程情况下:
- 计算密集型操作:效率高。
- IO操作: 效率高
Python多进程的情况下:
- 计算密集型操作:效率高(浪费资源)。
- IO操作: 效率高 浪费资源)。
python 线程编写
需要 import threading
一、线程的使用
.join(n)
.setName()
.getName()
threading.current_thread()
1. 线程的基本使用
def func(arg): print(arg) t = threading.Thread(target=func,args=(11,)) # 创建线程 t.start() print(123)
# 11 # 123
2. 主线程默认等子线程执行完毕后结束
import threading import time def func(arg): time.sleep(arg) # 睡arg秒后执行 print(arg) t1 = threading.Thread(target=func,args=(3,)) t1.start() t2 = threading.Thread(target=func,args=(9,)) t2.start() print(123) # 123 # 3 # 9
3. 主线程不再等, 主线程终止则所有的子程序也会终止,不管子程序有没有执行都会停止.
import threading import time def func(arg): time.sleep(2) # 2秒后执行 print(arg) t1 = threading.Thread(target=func,args=(3,)) t1.setDaemon(True) t1.start() t2 = threading.Thread(target=func,args=(9,)) t2.setDaemon(True) t2.start() print(123) # 123
4. 开发者可以控制主线程等待子线程的 最多等待时间
t1.join() # 没有参数时, 让主线程等着,等子线程t1执行完, 再往下继续走.
t1.join(2) # 有参数时, 指最多等待n秒钟, n秒后无论子线程t1是否执行完, 都会继续往下走.
import threading import time def func(arg): time.sleep(0.01) # 子程序 0.01秒执行 print(arg) print('创建子线程t1') t1 = threading.Thread(target=func,args=(3,)) t1.start() # 无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。 # 有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。 t1.join(2) print('创建子线程t2') t2 = threading.Thread(target=func,args=(9,)) t2.start() t2.join(2) # 让主线程在这里等着,等到子线程t2执行完毕,才可以继续往下走。 print(123) # 创建子线程t1 # 3 # 创建子线程t2 # 9 # 123
5. 设置/获取 线程的名称
t = threading.current_thread() # 获取当前线程
name = t.getName() # 获取当前线程的名称
t1.setName("线程1") # 设置 t1 线程的名称
import threading def func(arg): # 获取当前执行该函数的线程的对象 t = threading.current_thread() # 根据当前线程对象获取当前线程名称 name = t.getName() print(name,arg) t1 = threading.Thread(target=func,args=(11,)) t1.setName('asd') t1.start() t2 = threading.Thread(target=func,args=(22,)) t2.setName('zxc') t2.start() print(123) # asd 11 # zxc 22 # 123
6. 线程的本质
线程中: t1.start() 并不是开始运行线程,只是告知CPU已准备好,可以被调度, 至于什么时候执行是看CPU自己什么时候调度.
# 先打印:11?123? import threading def func(arg): print(arg) t1 = threading.Thread(target=func,args=(11,)) t1.start() # start 是开始运行线程吗?不是 # start 告诉cpu,我已经准备就绪,你可以调度我了。 print(123) # 11 # 123
7. 补充: 面想对象的多线程
import threading # 多线程方式:1 (常见)普通版本 def func(arg): print(arg) t1 = threading.Thread(target=func,args=(11,)) t1.start() # 11 # 多线程方式:2 面向对象版本 class MyThread(threading.Thread): # 定义自己的线程类 继承 threading.Thread def run(self): # strat() 时,会执行run()方法 print(11111,self._args,self._kwargs) t1 = MyThread(args=(11,)) t1.start() t2 = MyThread(args=(22,)) t2.start() print('end') # 11111 (11,) {} # 11111 (22,) {} # end
二、python 中 IO操作/计算密集型 的多线程
1. 计算密集型 多线程是无用的
在python中,一个进程中只允许调用一个线程,计算密集型,采用多线程,cpu需要来回切换有可能还会使得计算的值不准确,不会提高效率,
计算密集型的 需要创建多进程较好,
对于 计算密集型 多线程用不用都是一样的
示例: 将v1中的值都加1 , v2中的值都加100
import threading v1 = [11,22,33] # +1 v2 = [44,55,66] # 100 def func(data,plus): for i in range(len(data)): data[i] = data[i] + plus t1 = threading.Thread(target=func,args=(v1,1)) t1.start() t2 = threading.Thread(target=func,args=(v2,100)) t2.start()
2. IO操作 多线程是有用的
在IO操作中,都是流程性的, 不占用cpu, 采用多线程 是可以提高效率的.
示例: 小爬虫, 从网上下载图片,之前也有所介绍过
import threading import requests import uuid url_list = [ 'https://www3.autoimg.cn/newsdfs/g28/M05/F9/98/120x90_0_autohomecar__ChsEnluQmUmARAhAAAFES6mpmTM281.jpg', 'https://www2.autoimg.cn/newsdfs/g28/M09/FC/06/120x90_0_autohomecar__ChcCR1uQlD6AT4P3AAGRMJX7834274.jpg', 'https://www2.autoimg.cn/newsdfs/g3/M00/C6/A9/120x90_0_autohomecar__ChsEkVuPsdqAQz3zAAEYvWuAspI061.jpg', ] def task(url): ret = requests.get(url) file_name = str(uuid.uuid4()) + '.jpg' with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: t = threading.Thread(target=task,args=(url,)) t.start()
三、多线程的问题 (加锁)
python 中多线程是 cpu 执行一会便切换到别的线程, 一会之后又切换回来, 为防止 多个线程同时对全局变量有操作,最后的得到的结果不准确. 会在线程中加锁, 在该线程中被锁定的代码,会被一起执行, 执行后才会切换到别的线程.
lock = threading.RLock() # 创建锁
lock.acquire() # 加锁
lock.release() # 释放锁
import time import threading lock = threading.RLock() # 创建锁 n = 10 def task(i): print('这段代码不加锁',i) lock.acquire() # 加锁,此区域的代码同一时刻只能有一个线程执行 global n print('当前线程',i,'读取到的n值为:',n) n = i time.sleep(1) print('当前线程',i,'修改n值为:',n) lock.release() # 释放锁 for i in range(5): t = threading.Thread(target=task,args=(i,)) t.start() # 这段代码不加锁 0 # 当前线程 0 读取到的n值为: 10 # 这段代码不加锁 1 # 这段代码不加锁 2 # 这段代码不加锁 3 # 这段代码不加锁 4 # 当前线程 0 修改n值为: 0 # 当前线程 1 读取到的n值为: 0 # 当前线程 1 修改n值为: 1 # 当前线程 2 读取到的n值为: 1 # 当前线程 2 修改n值为: 2 # 当前线程 3 读取到的n值为: 2 # 当前线程 3 修改n值为: 3 # 当前线程 4 读取到的n值为: 3 # 当前线程 4 修改n值为: 4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号