数据采集作业五
作业①
1)实验要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架爬取京东商城某类商品信息及图片。
- 候选网站:http://www.jd.com/
- 关键词:学生自由选择
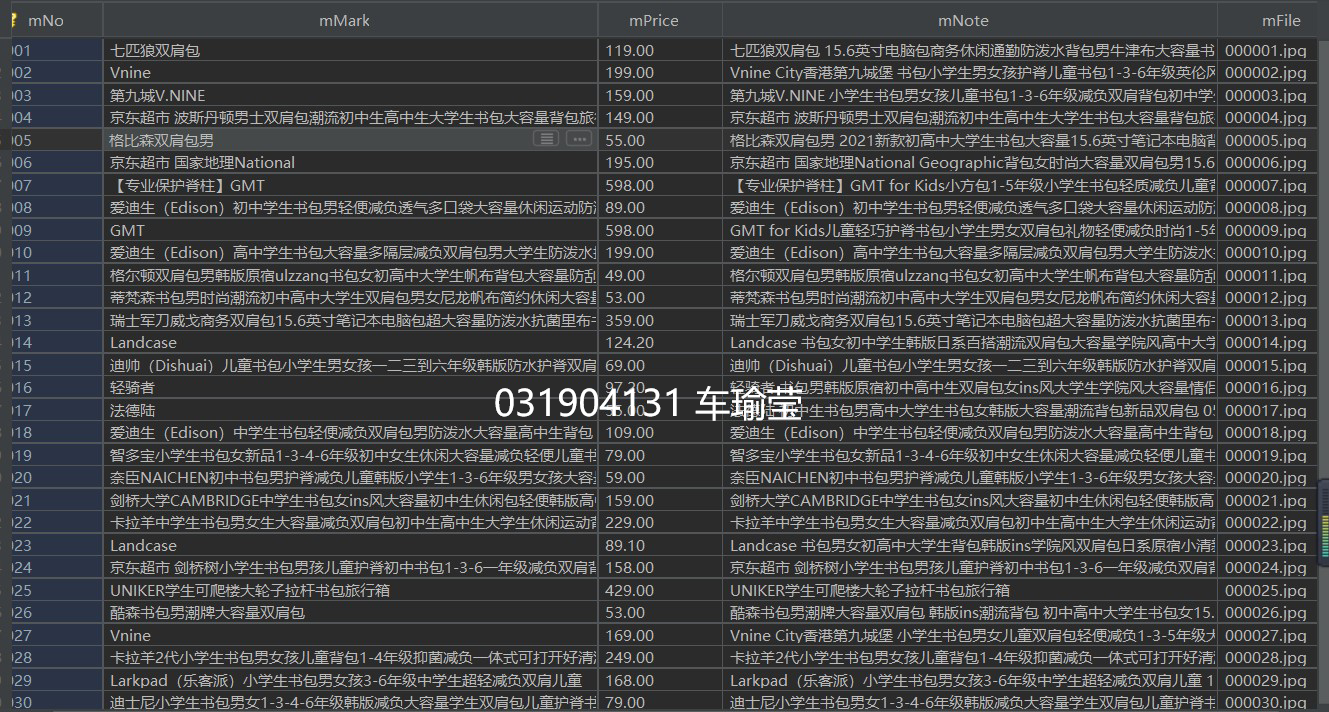
- 输出信息: MySQL数据库存储和输出格式如下
| mNo | mMark | mPrice | mNote | mFile |
|---|---|---|---|---|
| 000001 | 三星Galaxy | 9199.00 | 三星Galaxy Note20 Ultra 5G... | 000001.jpg |
| 000002...... |
2)思路分析
分析网页,寻找对应的信息
搜索框
商品列表,每一个都对应一个商品信息

对应商品信息

翻页

然后是代码部分(因为是复现,所以就全放了)
from selenium import webdriver from selenium.webdriver.chrome.options import Options import urllib.request import threading import sqlite3 import os import datetime from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time class MySpider: headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43 " } # 保存图片的文件夹 imagePath = "D:/数据采集/images" def startUp(self, url, key): # Initializing Chrome browser chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome() self.threads = [] self.No = 0 self.imgNo = 0 try: self.con = sqlite3.connect("phones.db") self.cursor = self.con.cursor() try: # 如果有表就删除 self.cursor.execute("drop table phones") except: pass try: # 建立新的表 sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))" self.cursor.execute(sql) except: pass except Exception as err: print(err) # Initializing images folder try: if not os.path.exists(MySpider.imagePath): os.mkdir(MySpider.imagePath) images = os.listdir(MySpider.imagePath) for img in images: s = os.path.join(MySpider.imagePath, img) os.remove(s) except Exception as err: print(err) self.driver.get(url) keyInput = self.driver.find_element(By.ID,"key") keyInput.send_keys(key) keyInput.send_keys(Keys.ENTER) def closeUp(self): try: self.con.commit() self.con.close() self.driver.close() except Exception as err: print(err) def insertDB(self, mNo, mMark, mPrice, mNote, mFile): try: sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)" self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile)) except Exception as err: print(err) def showDB(self): try: con = sqlite3.connect("phones.db") cursor = con.cursor() print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note")) cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo") rows = cursor.fetchall() for row in rows: print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4])) con.close() except Exception as err: print(err) def download(self, src1, src2, mFile): data = None if src1: try: req = urllib.request.Request(src1, headers=MySpider.headers) resp = urllib.request.urlopen(req, timeout=10) data = resp.read() except: pass if not data and src2: try: req = urllib.request.Request(src2, headers=MySpider.headers) resp = urllib.request.urlopen(req, timeout=10) data = resp.read() except: pass if data: print("download begin", mFile) fobj = open(MySpider.imagePath + "\\" + mFile, "wb") fobj.write(data) fobj.close() print("download finish", mFile) def processSpider(self): try: time.sleep(1) print(self.driver.current_url) lis = self.driver.find_elements(By.XPATH,"//div[@id='J_goodsList']//li[@class='gl-item']") for li in lis: try: src1 = li.find_element(By.XPATH,".//div[@class='p-img']//a//img").get_attribute("src") except: src1 = "" try: src2 = li.find_element(By.XPATH,".//div[@class='p-img']//a//img").get_attribute("data-lazy-img") except: src2 = "" try: price = li.find_element(By.XPATH,".//div[@class='p-price']//i").text except: price = "0" try: note = li.find_element(By.XPATH,".//div[@class='p-name p-name-type-2']//a//em").text mark = note.split(" ")[0] mark = mark.replace("爱心东东\n", "") mark = mark.replace(",", "") note = note.replace("爱心东东\n", "") note = note.replace(",", "") except: note = "" mark = "" src2 = "" self.No = self.No + 1 no = str(self.No) while len(no) < 6: no = "0" + no print(no, mark, price) if src1: src1 = urllib.request.urljoin(self.driver.current_url, src1) p = src1.rfind(".") mFile = no + src1[p:] elif src2: src2 = urllib.request.urljoin(self.driver.current_url, src2) p = src2.rfind(".") mFile = no + src2[p:] if src1 or src2: T = threading.Thread(target=self.download, args=(src1, src2, mFile)) T.setDaemon(False) T.start() self.threads.append(T) else: mFile = "" self.insertDB(no, mark, price, note, mFile) try: self.driver.find_element(By.XPATH,"//span[@class='p-num']//a[@class='pn-prev disabled']") except: nextPage = self.driver.find_elements(By.XPATH,"//span[@class='p-num']//a[@class='pn-next']") time.sleep(10) nextPage.click() self.processSpider() except Exception as err: print(err) def executeSpider(self, url, key): starttime = datetime.datetime.now() print("Spider starting......") self.startUp(url, key) print("Spider processing......") self.processSpider() print("Spider closing......") self.closeUp() for t in self.threads: t.join() print("Spider completed......") endtime = datetime.datetime.now() elapsed = (endtime - starttime).seconds print("Total ", elapsed, " seconds elapsed") url = "http://www.jd.com" spider = MySpider() while True: print("1.爬取") print("2.显示") print("3.退出") s = input("请选择(1,2,3):") if s == "1": spider.executeSpider(url, "书包") continue elif s == "2": spider.showDB() continue elif s == "3": break
输出结果
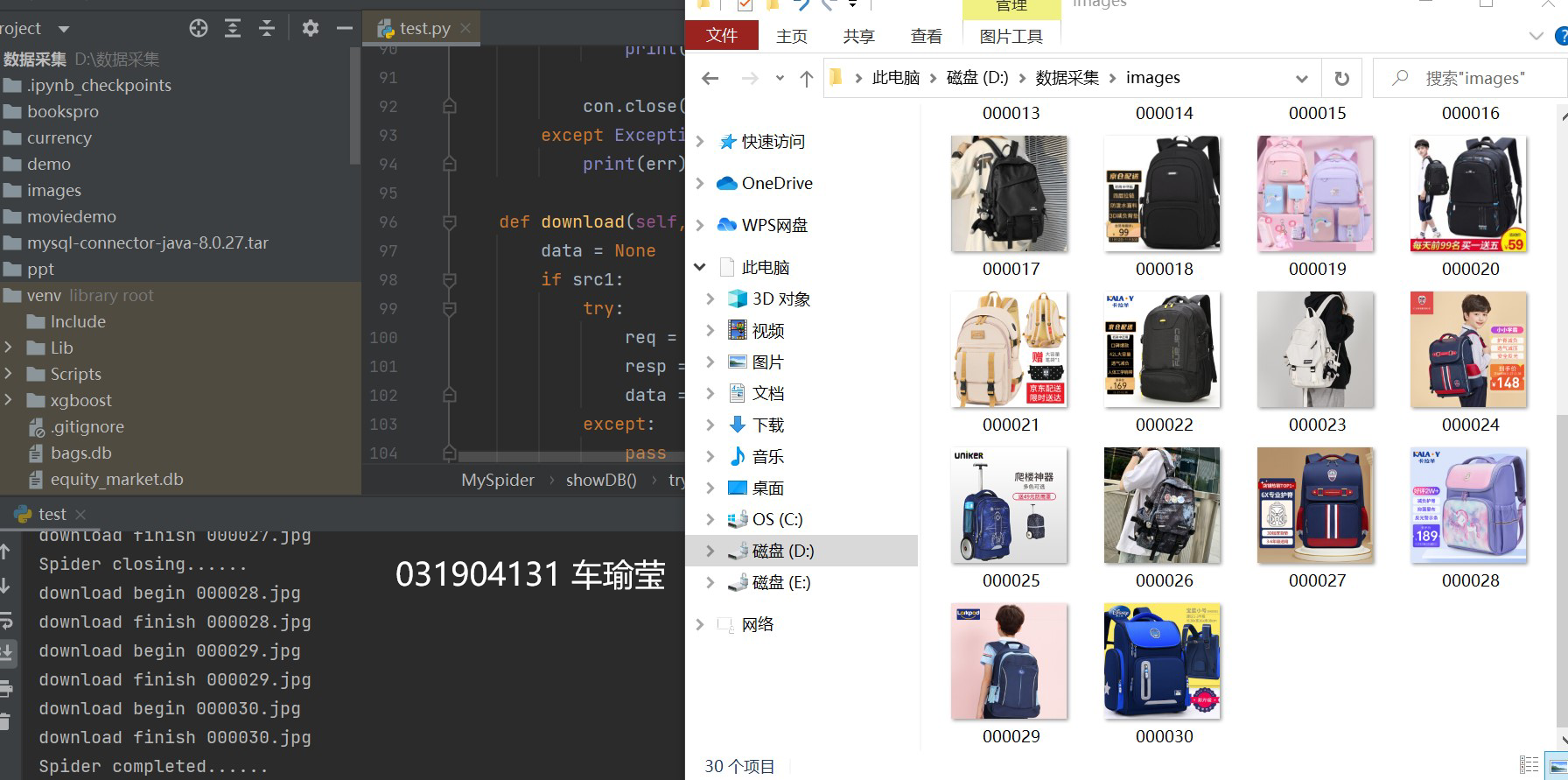
3)心得体会
这次实验主要是复现,代码方面没有什么问题,就是在查找网页相关信息的时候有些不熟练,还是要多加练习,主要是网站相应的时间比较长,感觉有些卡,还没有研究出来是哪方面的原因。
作业②
1)实验要求
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
- 候选网站:中国mooc网:https://www.icourse163.org
- 输出信息:MYSQL数据库存储和输出格式
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python网络爬虫与信息提取 | 北京理工大学 | 已学3/18课时 | 2021年5月18日已结束 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
2)思路分析
分析网页,获得所需要的信息
因为这次作业要求进入个人中心,我们要先查看登录页面的信息 ,使用其他方式登录:手机号码登录

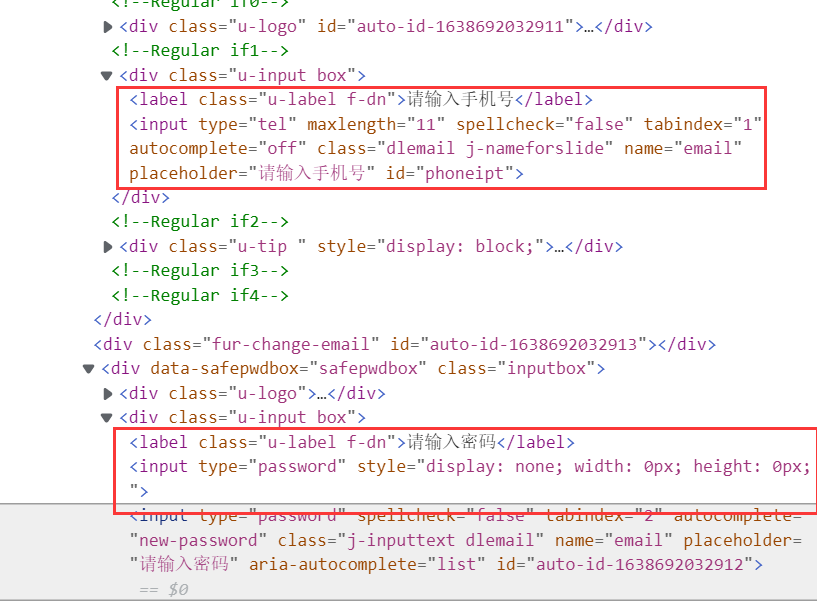

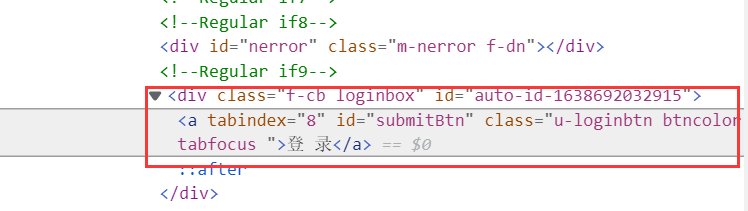
相关代码
use = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div') # 点击登录 useway = driver.find_element(By.XPATH, '//div[@class="ux-login-set-scan-code_ft"]/span') # 选择其他方式登录 way = driver.find_element(By.XPATH, '//ul[@class="ux-tabs-underline_hd"]/li[2]') # 选择电话号码登录 temp_iframe_id = driver.find_elements(By.TAG_NAME, 'iframe')[1].get_attribute('id') # 切换至页面弹窗driver.switch_to.frame(temp_iframe_id) driver.find_element(By.XPATH,'//input[@type="tel"]').send_keys('') # 输入账号 driver.find_element(By.XPATH, '//input[@class="j-inputtext dlemail"]').send_keys('') # 输入密码(这里就不告诉你们了) time.sleep(1) load_in = driver.find_element(By.XPATH, '//*[@id="submitBtn"]') # 点击登录
进入个人中心,查看相关信息
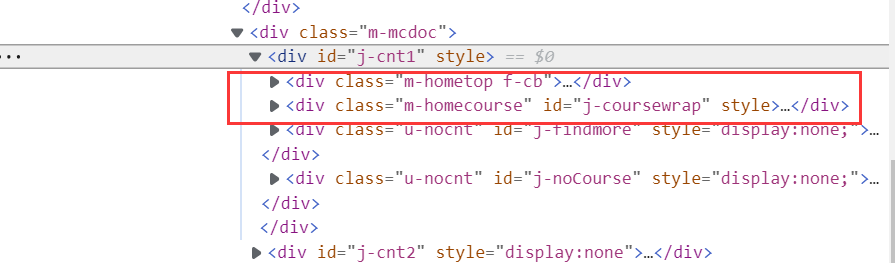

相关代码
def processspider(self): try: search_handle = self.driver.current_window_handle #判断当前有无元素Located WebDriverWait(self.driver, 1000).until(EC.presence_of_all_elements_located((By.XPATH, "//div[@class='m-course-list']/div/div[@class]"))) spans = self.driver.find_elements_by_xpath("//div[@class='m-course-list']/div/div[@class]") while i>=5: for span in spans: self.count=self.count+1 course = span.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']/a/span").text college = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']/a[@class='t21 f-fc9']").text teacher = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']/a[@class='f-fc9']").text team = span.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0 margin-top0']/span[@class='hot']").text process = span.find_element_by_xpath(".//span[@class='txt']").text brief = span.find_element_by_xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']").text print(self.count,course,college,teacher,team,process,brief) # 爬取之后输出到控制台 self.insertdb(self.count,course,college,teacher,team,process,brief) i=i-1 except Exception as err: print(err)
模拟浏览器并存入数据库
def startup(self, url): # 初始化谷歌浏览器 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=chrome_options) self.count=0 try: self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="yy0426cc..", db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) try: # 如果有表就删除 self.cursor.execute("drop table mooc") except: pass try: # 建立新的表 sql_1 = "create table mooc (Id varchar(2048) , cCourse varchar(2048), cCollege varchar(2048), cTeacher varchar(2048), cTeam varchar(2048), cProcess varchar(2048), cBrief text)" self.cursor.execute(sql_1) except: pass except Exception as err: print(err) self.driver.get(url)
输出结果

3)心得体会
这一道题是对上一题的升华,同时还加入了MySQL的使用,感觉这道题最难的部分就是进入到个人中心那部分,要经过登录等步骤,刚开始很难做出来。还有一点就是,这次网页响应的时间格外长,长到我以为是代码出现了问题,可能是哪里设置有点问题,后续还要再看看。
作业③
1)实验要求
- 掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建:
- 任务一:开通MapReduce服务
- 实时分析开发实战:
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
- 任务三:安装Flume客户端
- 任务四:配置Flume采集数据
2)实验步骤
开通MapReduce服务(具体步骤不放了)
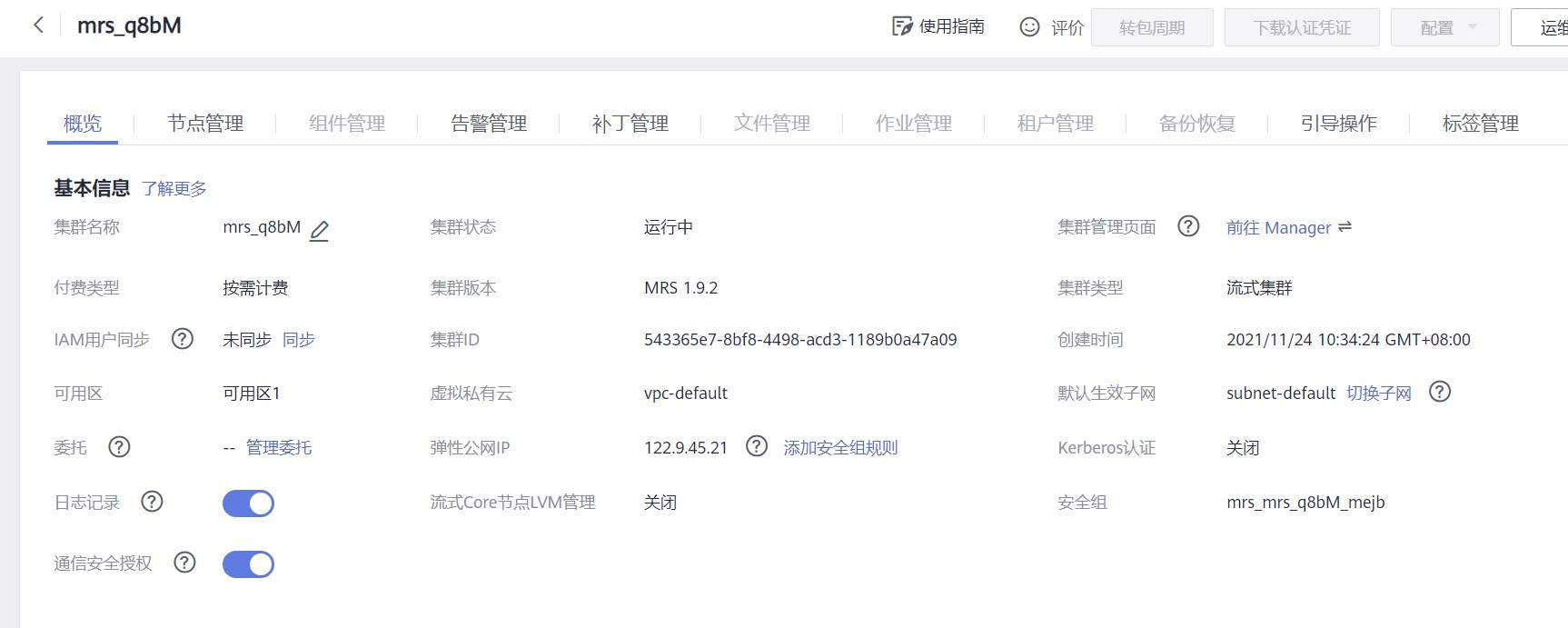
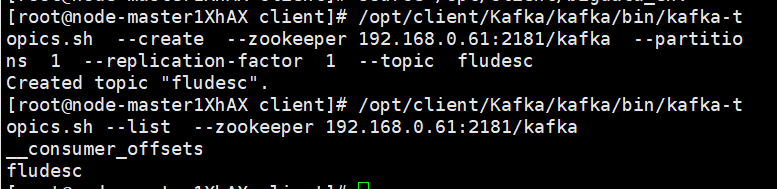
Python脚本生成测试数据(执行python命令,并查看数据)
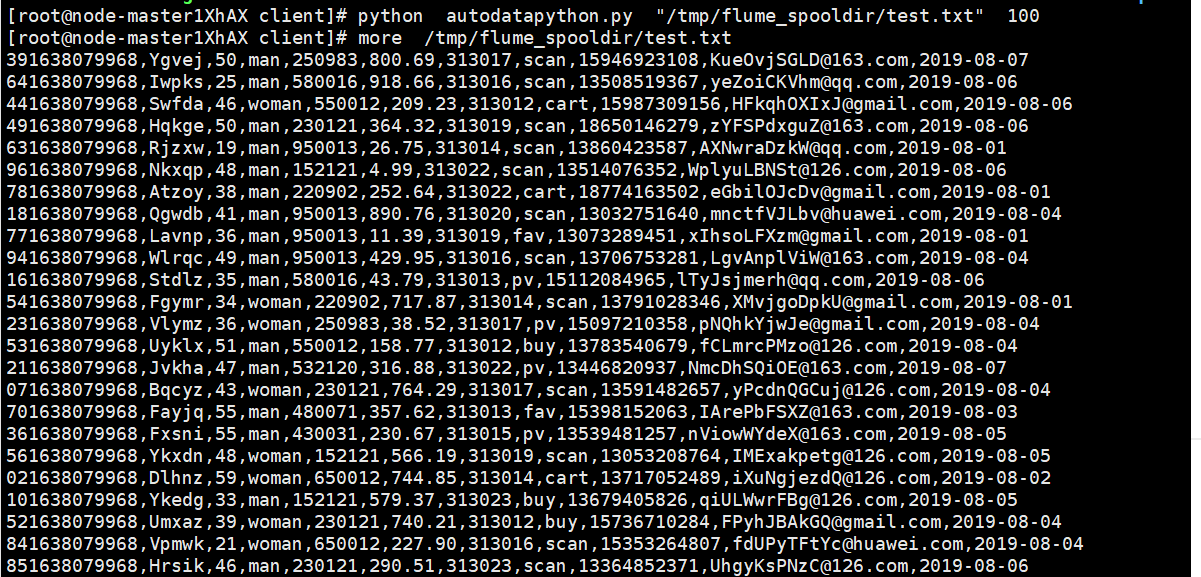
配置Kafka(在kafka中创建topic,查看topic信息)
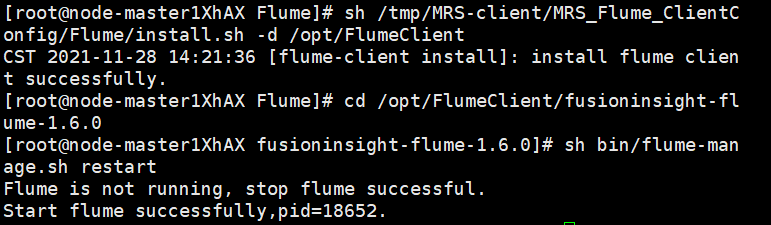
安装Flume客户端(安装Flume客户端成成功并重启Flume服务)
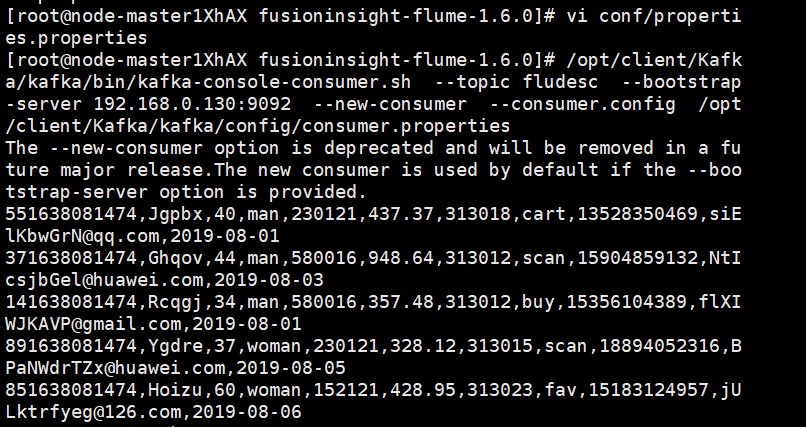
配置Flume采集数据(创建消费者消费kafka中的数据并查看)
3)心得体会
这个实验按照步骤做就可以,过程没有出现很多的错误。之前一门课也有使用过华为云这类的服务器,但是这次也是开辟了一个新的知识点,学会了如何使用Flume进行实时流前端数据采集,但其实还是有点迷糊,希望以后能加强这方面学习。
代码地址:
