数据采集作业一
作业①
1)实验要求
- 用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812)的数据。
- 输出信息
| 2020排名 | 全部层次 | 学校类型 | 总分 |
| 1 | 前2% | 清华大学 | 1069.0 |
| ... |
2)思路与分析
首先获取网页信息
header ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31"}
url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812'
req= urllib.request.Request(url,headers=header)
reqs=urllib.request.urlopen(req)#发送请求
html = reqs.read().decode().replace('\n','')#解析成中文并去掉回车
进入网页分析信息,整个表格存在于tbody中
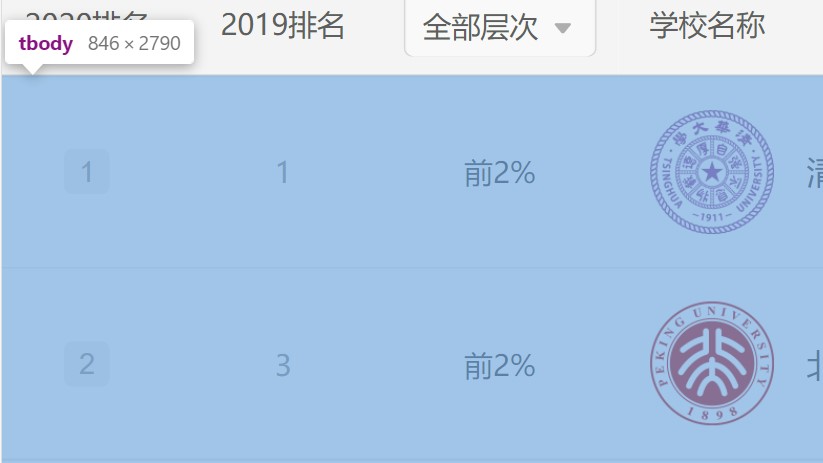


由此可以得到正则表达式
rate=re.findall(r'<div class="ranking" data-v-68e330ae>(.*?)</div>',html) level=re.findall(r'<td data-v-68e330ae.*?>(.*?)</td>',html) level=re.findall(r'[\u4e00-\u9fa5]\d+.',str(level)) name=re.findall(r'class="name-cn" data-v-b80b4d60>(.*?)</a>',html) score=re.findall(r'<td data-v-68e330ae> (.*?)</td>',html) score=re.findall(r'\d+\.\d',str(score))
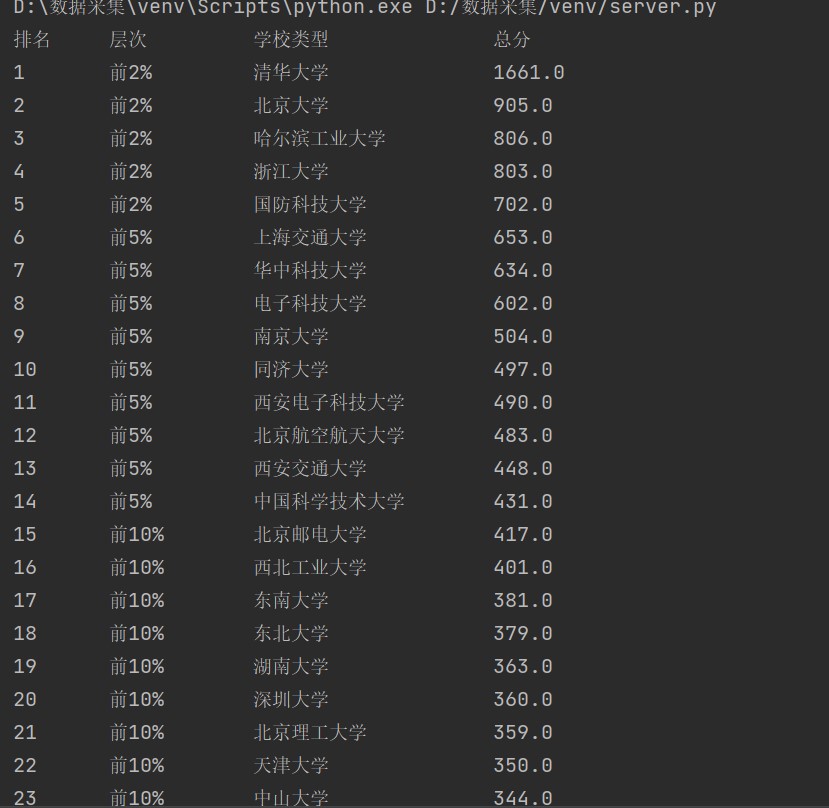
最后输出获取的信息
tplt = "{}\t\t{:4}\t\t{:10}\t\t{:4}" print(tplt.format("排名", "层次", "学校类型", "总分", chr(12288))) Rate=[] Level=[] Name=[] Score=[] for i in range(len(rate)): Rate = int(rate[i])#数字形式输出 Level = level[i].strip() Name = name[i].strip() Score = score[i].strip() print(tplt.format(Rate,Level,Name,Score,chr(12288)))#中英文混排需要chr(12288)
得到结果
3)心得体会
正则用法太太太不熟练了,刚开始练习时一直是乱码。层次和总分也要找方法分开,研究了非常久,以后正则表达式方面要多加练习。
作业②
1)实验要求
- 用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
- 输出信息
| 序号 | 城市 | AQI | PM2.5 | SO2 | NO2 | CO | 首要污染物 |
| 1 | 北京 | .. | |||||
| ... |
2)思路与分析
获取网页信息
def getHTML(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
打开网页进行分析

整个信息存在于tbody中,可以得到我们想要获取的信息
def fillUList(ulist, html): soup = BeautifulSoup(html, "html.parser") count=1#为了输出前面的序号 for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag): tds = tr.find_all('td') ulist.append([str(count),tds[0].text.strip(), tds[1].string.strip(), tds[2].text.strip(), tds[4].text.strip(),tds[5].text.strip(),tds[6].text.strip(),tds[8].text.strip()]) count+=1
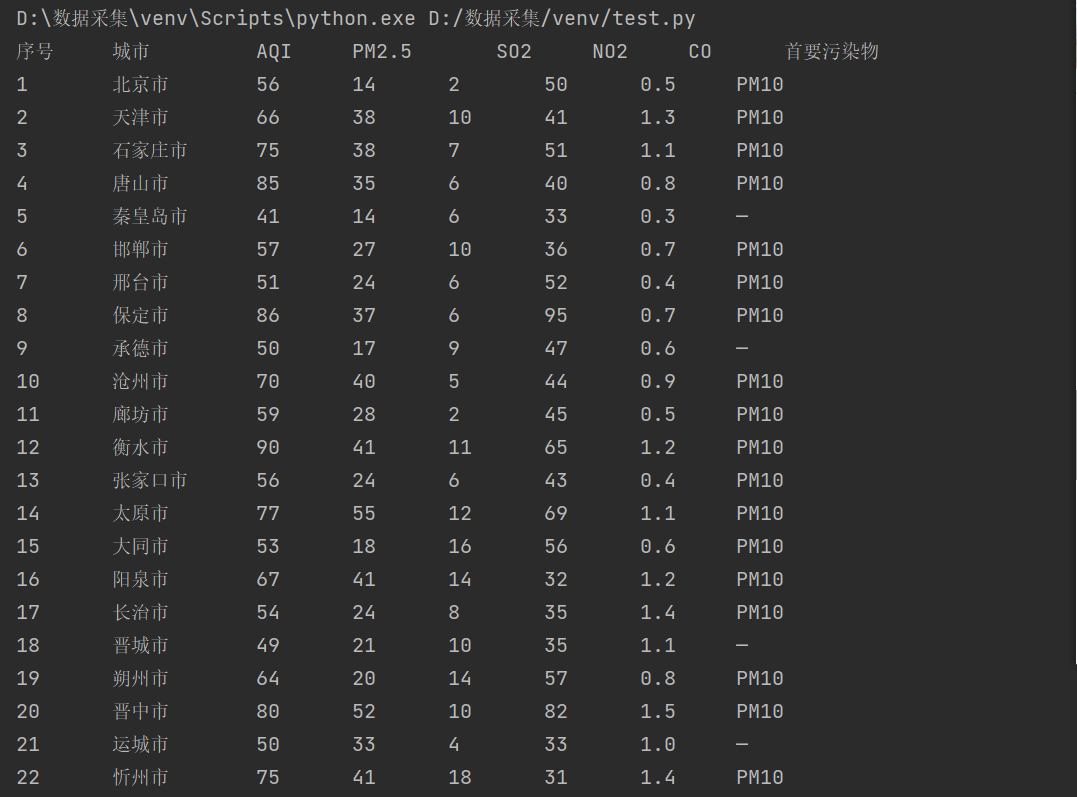
最后调整一下格式输出就好了
def printUList(ulist, num): tplt = "{}\t\t{:4}\t\t{}\t\t{}\t\t{}\t\t{}\t\t{}\t\t{}" print(tplt.format("序号", "城市", "AQI", "PM2.5","SO2","NO2","CO","首要污染物", chr(12288))) for i in range(num): u = ulist[i] print(tplt.format(u[0], u[1], u[2], u[3], u[4],u[5],u[6],u[7], chr(12288)))
得到结果
3)心得体会
这次实验和之前的作业比较类似,完成的也比较快,但是在寻找节点信息方面还要多加练习
作业③
1)实验要求
-
使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
- 将自选网页内的所有jpg文件保存在一个文件夹中
2)思路和分析
获取网页信息
requests:
ef RequestsGetText(page): try: url="http://news.fzu.edu.cn/" header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'} r = requests.get(url,headers=header,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text GetImg(r.text,page)#之后会用到获取图片的代码 except: print(" ") return ""
urllib:
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'}
count=0#总的图片数量,方便后续命名
url="http://news.fzu.edu.cn/"
r=urllib.request.Request(url,headers=header)
reqs=urllib.request.urlopen(r)
data = reqs.read()
unicodedata= data.decode()
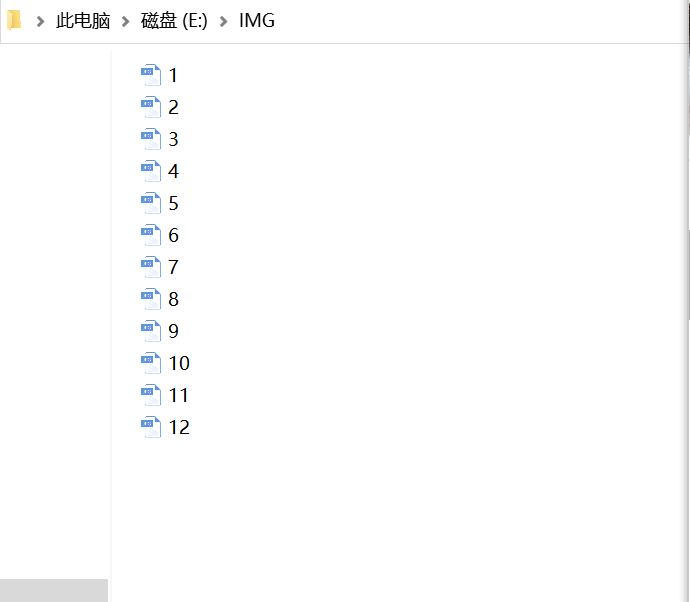
获取图片并保存
pat= r'<img src="/(.*?).jpg"' imagelist=re.compile(pat).findall(unicodedata) for img in imagelist: count+=1 thisurl ='http://news.fzu.edu.cn/attach/'+img+".jpg" #这个地方http不加s file='E:/IMG/'+str(count)+'.jpg' urllib.request.urlretrieve(thisurl,filename=file)
得到结果
3)心得体会
这类题型之前也有练习过,做起来会比较容易一些。但是在获取pat已经url的时候还是要费些心思。
完整代码:实验一 · 车车别吃了/moocy - 码云 - 开源中国 (gitee.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号