


SQL进阶教程1-6 :使用关联子查询比较行与行,当主键id有间断时如何比较行与行
使用SQL对同一行数据进行行列间的比较很简单,只需要在WHERE子句里协商比较条件就可以了,例如col_1 = col_2。使用SQL进行行间比较时,发挥主要作用的技术是关联子查询,特别是与自连接相结合的“自关联子查询”
eg. 需要用到行间数据比较的具有代表性的业务场景是,使用基于时间序列的包进行时间序列分析。假设有下面这样一张记录了某个公司每年的营业额的表Sales。
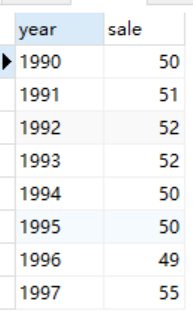
年营业额的趋势:
SQL:
SELECT S1.year, CASE WHEN sale = (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '→' -- 持平 WHEN sale > (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '↑' -- 增长 WHEN sale < (SELECT sale FROM Sales S2 WHERE S2.year = S1.year - 1) THEN '↓' -- 减少 ELSE '—' END AS var FROM Sales S1 ORDER BY year;
查询结果:
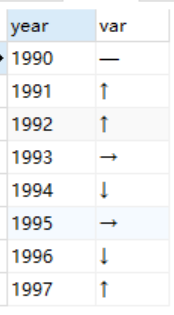
当前的执行结果是竖着展示的,怎么将执行结果改成横着展示呢????
二、当时间轴有间断时,如何与过去最邻近的时间进行比较
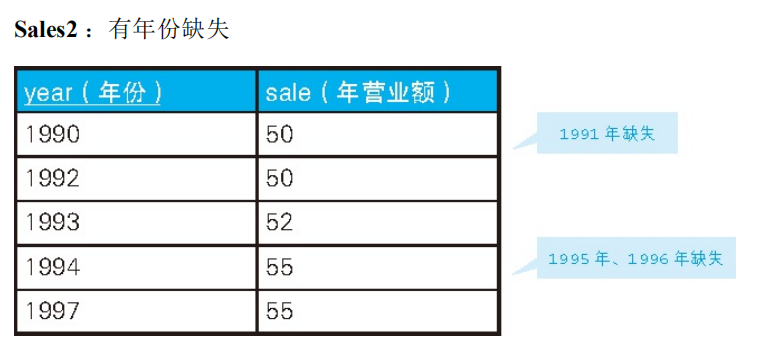
对某一年来说,“过去最邻近的年份”需要满足下面两个条件:
1. 与该年份相比是过去的年份;
2,在满足条件1的年份中,年份最早的一个。
SELECT year, sale FROM Sales2 S1 WHERE sale = (SELECT sale FROM Sales2 S2 WHERE S2.year = (SELECT MAX(year) -- 条件2 :在满足条件1 的年份中,年份最早的一个 FROM Sales2 S3 WHERE S1.year > S3.year)) -- 条件1 :与该年份相比是过去的年份 ORDER BY year;
使用自连接可以减少一层子查询的嵌套:
SELECT S1.year, S1.sale FROM sales2 S1, sales2 S2 WHERE S1.sale = S2.sale AND S2.year = (SELECT MAX(year) FROM sales2 S3 WHERE S1.year > S3.year)
查询每一年与过去最邻近的年份之间的营业额之差:
SELECT S1.year as now_year, S2.year as pre_year, S1.sale as now_sale, S2.sale as pre_sale, S1.sale - S2.sale as diff FROM sales2 S1, sales2 S2 WHERE S2.year = (SELECT MAX(year) FROM sales2 S3 WHERE S1.year > S3.year)

由执行结果可以发现,这条SQL无法获取到最早年份1990年的数据,如果想让结果出现1990年的数据,可以使用“自外连接”来实现:
SELECT S1.year as now_year,
S2.year as pre_year,
S1.sale as now_sale,
S2.sale as pre_sale,
S1.sale - S2.sale as diff
FROM sales2 S1 LEFT JOIN sales2 S2
ON S2.year = (SELECT MAX(year)
FROM sales2 S3
WHERE S1.year > S3.year)
ORDER BY S1.year
将表Sales2作为主表进行外连接后,所有年份就都出现在表侧栏里了。
这条SQL语句能与过去与其最近的年份进行比较,因此即使年份有缺失也没有关系,而且不只是数值,这条SQL语句还可以应用于字符类型、日期类型等具有顺序的列,通用性较高。但是因为使用极值函数时会发生排序,会影响性能,所以如果极值函数的参数是主键,能够使用索引的话尽量使用索引。
三、移动累计值和移动平均值
将截止到某个时间点且案按照时间记录的数值累加而得出来的数值称为累计值。
Accounts
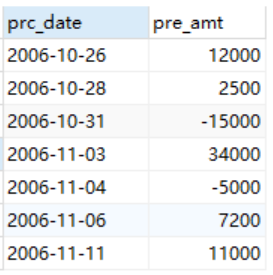
处理金额为正数代表存钱,为负数代表取钱。然后求,截止到某个处理日期的处理金额的累计值,实际上就是求截止到那个时间点的账户金额。
SELECT prc_date, prc_amt, (SELECT SUM(prc_amt) FROM Accounts A2 WHERE A2.prc_date <= A1.prc_date) FROM Accounts A1
上面的例题并没有指定要求的累计值的时间区间,因此计算的是从最早的数据开始的累计值。考虑一下,如何以3次处理未单位求累计值,即移动累计值。作为移动,指的是将累计的数据进行行数固定,一行一行地偏移。

也就是A1和A2之间的对应行id间差值应该<=3,
SELECT prc_date, A1.prc_amt, (SELECT SUM(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date AND (SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <= 3 ) AS mvg_sum FROM Accounts A1 ORDER BY prc_date;
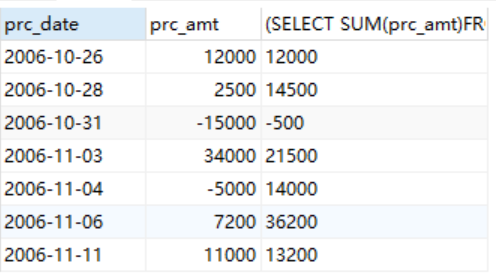
在处理前两行时,即使数据不满3行,这条SQL语句还是计算出了相应的累计值,其实,可以将这样的情况当做无效来处理。
#使用自连接关联子查询来求指定行的累加值 SELECT prc_date, A1.prc_amt,(SELECT SUM(prc_amt) FROM Accounts A2 WHERE A1.prc_date >= A2.prc_date AND (SELECT COUNT(*) FROM Accounts A3 WHERE A3.prc_date BETWEEN A2.prc_date AND A1.prc_date ) <= 3 HAVING COUNT(*) =3) AS mvg_sum -- 不满3 行数据的不显示 FROM Accounts A1 ORDER BY prc_date; #最内层<=3,指的是 A1和A2之间相差<=3; #下一个=3 指的是符合上述条件的A2的数目为3
四、查询重叠的时间区间
假设有下面这样一张表Reservations,记录了酒店或者旅馆的预约情况。
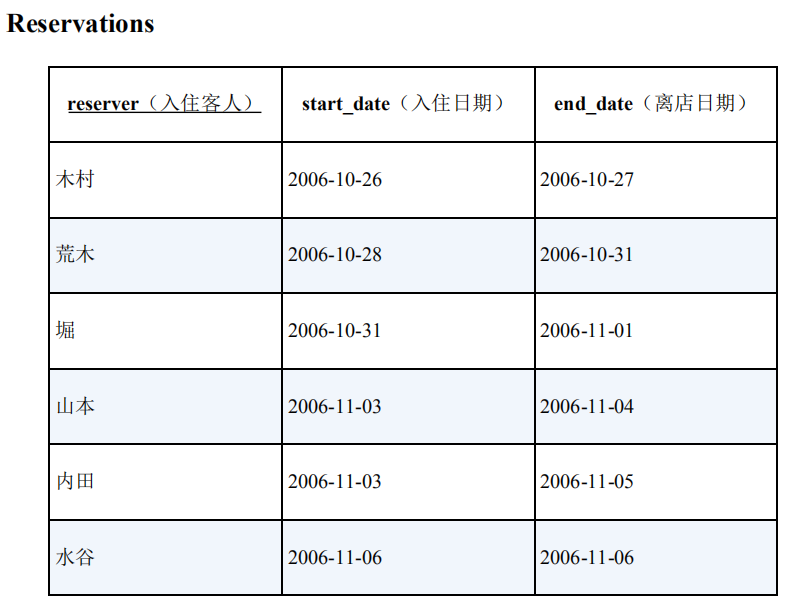
这张表里面没有房间编号,请把表中数据当成是某一房间在某段时间内的预约情况。在正常情况下,每天只能有一组客人在该房间住宿。但是从表中的数据可以看出,这里存在重叠的预定日期。显然,这样会有问题,必须马上重新分配房间,我们面对的问题是如何查出住宿日期重叠的客人并列表显示。
日期重叠类型:
(1)自己的入住日期在他人的住宿期间内;
(2)自己的离店日期在他人的住宿期间内;
(3)自己的入住日期和离店日期都在他人的住宿期间内;
第三种情况其实是被前两种情况包含的,是(1)(2)的交集。因此,充要条件是满足类型(1)和(2)中至少一个条件。
错误SQL:
-- 求重叠的住宿期间 SELECT reserver, start_date, end_date FROM Reservations R1 WHERE EXISTS (SELECT * FROM Reservations R2 WHERE R1.reserver <> R2.reserver -- 与自己以外的客人进行比较 AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date -- 条件(1):自己的入住日期在他人的住宿期间内 OR R1.end_date BETWEEN R2.start_date AND R2.end_date)); -- 条件(2):自己的离店日期在他人的住宿期间内
分析上面的SQL语句,如果山本的入住日期不是11月3号,而是11月4号:
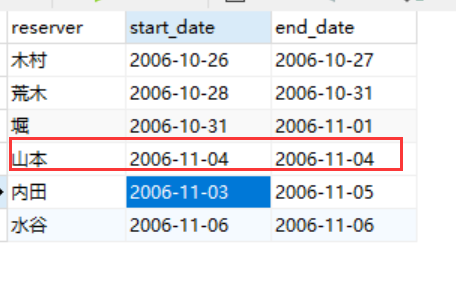
此时,因为内田的入住日期和离店日期均不在另外一个人的入住和离店日期之间而是其住宿区间完全包含了他人的住宿期间,会被这条SQL语句排除掉。
-- 升级版:把完全包含别人的住宿期间的情况也输出 SELECT reserver, start_date, end_date FROM Reservations R1 WHERE EXISTS (SELECT * FROM Reservations R2 WHERE R1.reserver <> R2.reserver AND ( ( R1.start_date BETWEEN R2.start_date AND R2.end_date OR R1.end_date BETWEEN R2.start_date AND R2.end_date) OR ( R2.start_date BETWEEN R1.start_date AND R1.end_date AND R2.end_date BETWEEN R1.start_date AND R1.end_date) ) );
需要注意的是使用标量子查询时,性能可能会变差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号