
YOLO系列:YOLO v1
1 YOLO v1
YOLO v1中将图像分为S*S格子,每个格子预测B个boundingbox(对于一个bbox有坐标(x,y), w,h和该bbox的置信度),C个分类得分。
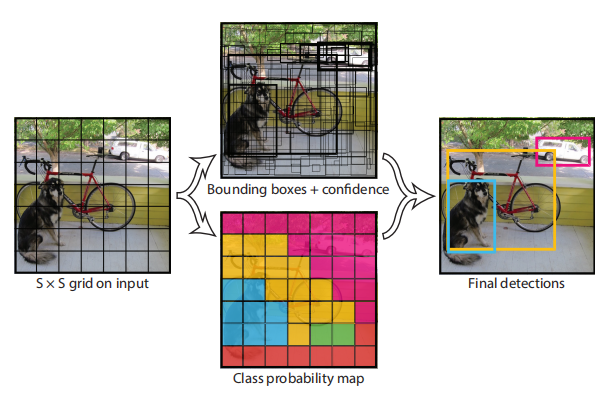
在论文中S=7,C=20,B=2,所以输出的tennsor大小为7*7*30,其中30 = (2*(4+1)+20)。
YOLOV1中网络结构比较简单,主要思想是直接通过CNN得到输出结果。论文中网络结构图如下:
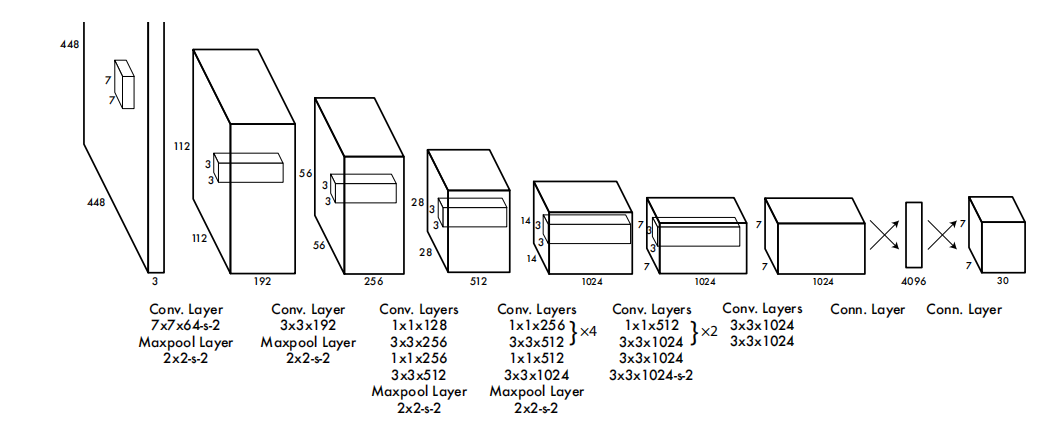
网络结构比较简单,整体结构上可以认为是卷积后就通过全连接层分类。注意全连接层输出大小为4096,这个大小就是7*7*30。预测时,需要将全连接层的结果进行reshape成7*7*30
2 YOLO v1中的损失函数
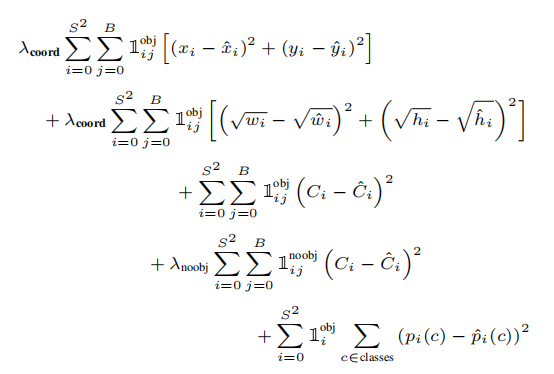
λcoord代表相关性大的损失,λnoobj分别代表相关性小的损失,论文中λcoord取值为5,λnoobj取值为0.5。
损失函数中的第一项是计算每个各种预测的(xi, yi)与真实值之间的损失。
损失函数中的第二项是对于宽和高的损失,作者对宽高进行开根号操作,主要是为了消除不同尺度的目标对损失函数的影响。
需要注意的是第一、二项中,并不是将每个格子中所有bbox都参与误差计算,这里只选取与真实框的IOU值高的bbox。
损失函数中第三项是检测到目标的目标框的误差。
损失函数中第四项是没有检测到目标的目标框的误差。
注意第四项中前面的系数,这个系数比较小,主要是因为一张图像中没有目标的框比较多,这里相当于做了平衡。
损失函数中第五项就是每个格子的分类损失。
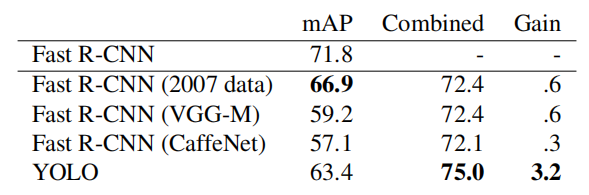
3 YOLO v1与同期网络对比
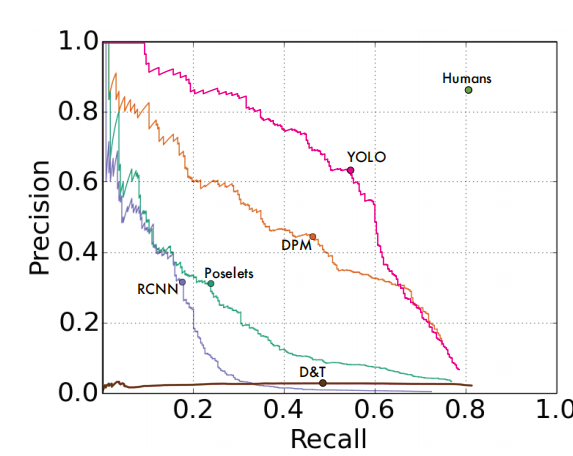
4 YOLO v1检测结果示意图

YOLO v1的优缺点
当时提出来时,最明显的噱头就快。毕竟YOLOV1只经过卷积和全连接层,如果更换轻量的主干网络速度更快。
当然这个版本的缺点也非常明显。
1)每个格子只预测B个格子,不好处理目标重叠的情况。
2)使用S*S划分格子的方式不好检测细粒度的物体。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号