

MPLS 知识要点1
MPLS 是一种转发机制
1>Protocol
2>转发机制(CPU,进程交换)
1>控制流量
2>管理流量
3>服务流量
1,过境流量---CEF
2,接收流量---Process switch
3,异常流量
控制引擎,协议重启的时候可以不影响数据面的转发---CEF(只查20字节)(重复路由,一直交换)
路由表会新增一条32位Link Local路由,需要进行CPU处理。
MPLS
{
Control-Plane(Route,Label[LDP|TDP|RSVP|BGP])
Data-Plane---LFIB
}
传统IP转发的四个参数,目的,下一跳,出口,MAC。会产生延迟
MPLS TE是最大的优点,流量规则
例
PBR,可实现,但扩展性差,没有重路由的能力。
路由查找的顺序:
1,PBR
2,RIB
3,PBR-Default
4,默认路由
为什么布署MPLS需要开启CEF?
1,压制Label
2,分类规则FEC
FEC->转发等价类
>IGP,目的前缀
>BGP,下一跳
BGP路由黑洞的解决方案:
1,Full mesh
2,RR
3,联邦
4,MPLS
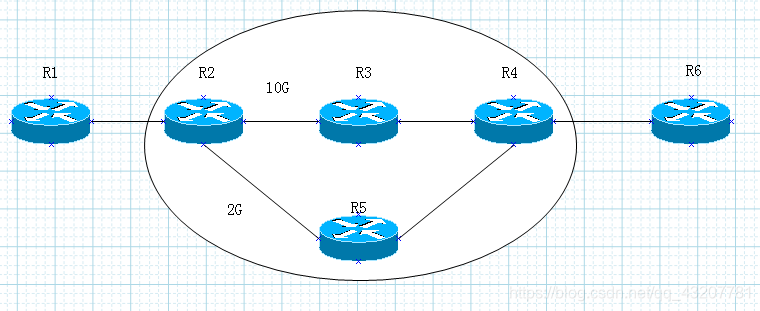
为什么MPLS VPN会快,假设十万条路由对应单条FEC,快。
SDH SONET 属于一层技术,时分复用。
1,覆盖VPN,运营商,不管三层
2,对等VPN,运营商,参与三层
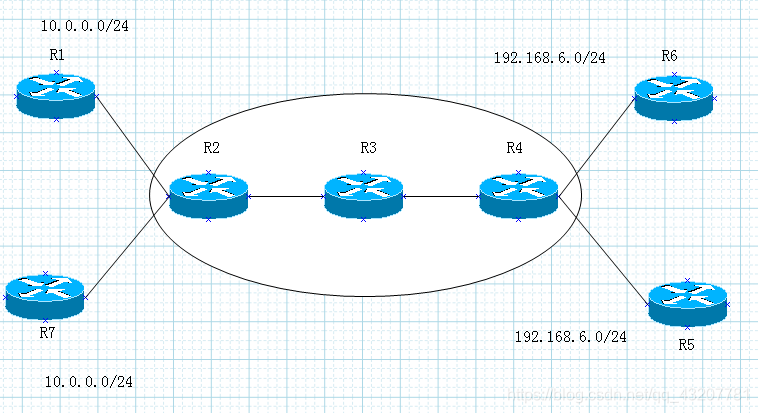
相同的网络前缀,如果运行目前路由协议怎么去解决冲突问题。
{
路由隔离(VRF,RD,RT)
路由传递(MPBGP)
}
----------------------------------------------------------------------------------------
MPLS第一天===================================================
控制层面,数据层面。相反的。
现在运营商将近40万条路由.
cpu 查路由表,早期的路由器进程交换.慢,
fast switch 一次路由多次交换.
cef->FIB(是一个路由表的拷贝,目的,下一跳,出接口),邻居表(下一跳,和下一跳的MAC地址,如ARP表.)
MPLS
控制面:交换路由信息,标签交换.igp
数据面:ldp ,tdp bgp,rsvp
Rib 路由表
边缘LSR,
if packet是路由就查FIB.
if packet是标签包就查LFIB.
CEF在MPLS中的作用:
1.进入标签域的标签压置.
2.基于MPLS的单播应用中,LDP是为每一个FIB的目的前缀分配标签.
基于MPLS的应用:
1.unicast ip routing
2.multicast ip routing
3.mpls te
4.qos
5.mpls vpns
6.atom
标签分发协议是为FEC分发标签,不同的应用会有不同的FEC分发方式.
FEC 具有某种转发共性的转发数据.放在FIB表.
在单播应用中,目标相同,同一个FEC.
l2vpn 每条伪线就是一个FEC.
MPLS 第二天========================================================================
标签为FEC分的。
0-15保留。
标签分配 标签分发 标签保留 标签空间
frame 独立控制 下游自主 自由保留 基于平台
cell 按需 按序 保守保留 基于接口
收敛
frame 快 --因为保留了 容易丢包
cell 慢 稳定
环路避免:frame 控制面,依靠路由协议。数据面,TTL。
cell 控制面, 路径矢量 数据面,hop-count
在cell,只有当下游设备有去往目标网络,才会往上游返回本地标签。按需,是指有数据流来的时候,才分配。
只有当目的地在MPLS域内时,才会有PHP
ldp id 2.2.2.2:0----4bytes:2bytes 0表示frame mode.非0 cell mode
接收不到标签的情况:CEF,关闭了通告,mpls 没开,标签分错了。
以太帧:Dmac|Smac|type|payload|FCS
6 6 2 1500 4
type字段:0x0800----ip
0x8847----label
大于2000 巨型帧
大于1500 小巨型帧
小于1500 帧
no mpls ip pro forwarding 保护了TTL。
直接置为255跳。
MPLS 第三天=====================================================
LDP.646端口,
自动发现机制。用UDP发现.
对等体发现-ldp link hello message,targeted hello message
LDP session (TCP连接才会稳session)
label advertisement
ldp notification
最大的lo 口做ID。
LDP在传送地址来建邻居的,默认是用router-id来填充的,如果要修改可用,mpls ldp discovery transport-address interface.
地址小的一方,打开646.
工作流程,发现,前提是可达,使用更新源,打开646.
eigrp 4 种包文,ospf 5 种报文-hello dbd,lau ,laack..
ldp 十一种报文。
label allocation in unicast ip
1.labels are assigned to forwarding equivalence classes(FEC)
2.FEC in unicast ip routing is equal to a destination prefix found in FIB.
3.this is true only for internal gateway protocol (IGP),derived prefixes.
4.BGP-derived prefixes are assigned the label that is used for the BGP next-hop address.
5.The result is that all prefixes learned from an external BGP neighbor use a single label.
只有当路由通过IGP学才有标签。
不会给BGP路由分标签。
CE到PE,PE做的动作,
1.FEC分类。
2.给FEC关联标签。
MPLS VPN。PE要用环回口建邻居。物理口建邻居,会不通,因为PHP的行为。
MPLS 第四天=======================================================
早期peer-to-peer vpn模型的两大缺陷:
1.路由隔离----本地隔离:VRF
全局隔离:RD AS:Rx and ip:Rx
2.路由传递----vpnv4=rd+ipv4=96bits
用mp-bgp来传递
isis 2-3万
ospf 1-2万
MPLS 第五天=======================================================
traceroute
怎么回包,当包到mpls vpn域,他会假设前面有设备可回去源,所以改成255跳往前发,当到目的有回去的路由,就往回。
然后,会超时回,
源再以TTL=2再发,以此类推。
vpnv4 路由的四个组成部分:
RT | next-hop | vpnv4 route | label.
先FEC分类,再压标签。
在控制面,PE会为VRF每个vpn前缀分标签。服务标签。
上面的标签,叫转发标签。
注:将BGP重分布进RIP的metric参数transparent只有在两个站点都运行RIP时才使用,它是将sp core作为连线处理。
MPLS 第六天=======================================================
如果不打,red ospf 100 mat i e 1 e 2
默认打o oia 重发布。
做实验弄清楚lsa type 5 and 外部路由标识。
真正的lsa5 才会标识在里面。
在PE上ospf进程下打。
capability vrf-lite-------do not preform PE specific checks
lsa 5 环路机制:在PE检测的是Tag field.
>Tag 位由PE设备将BGP路由重发布进OSPF的时候带的。它的值就等于BGP的AS号。
>当其它PE收到OSPF路由,只要检测该路由所带的TAG位,与自己的AS号一样,则不会参与SPF算法。
也就是不会放入路由表。
#sh ip osp databse 看tag位。
倒数16个bits
lsa 3 domain-id down-bit
no ip vrf VPN 要两分钟才能再敲。
internet access========================================
负载均衡,有基于包,基于目的。
MPLS要求基于包。
ip cef load-sharing
int f0/0
ip load-sharing per-packet | per-destination
默认是基于目的,所以做BGP负载时,接口要改一下。
策略路由,最长匹配,策略默认,默认。
1.vrf specific default route
2.separate pe-ce sub-interface(non vrf)
3.extranet with internet vrf
4.extranet with internet vrf along with vrf-aware nat
CE 得到默认路由的方式。
PE CE之间需不需要公网IP。
需不需要NAT转换。
TE ===================================================
什么是TE,
1。相对于网络工程而言流量工程是网络投入生产之前的最后一环。
2。是对网络中流量规划的一种工具。
1.mpls te 在网络中部署的必要性。
1。数据网络的超额定购,网络中最优路径未必是最好路径。
传统IP解决流量工程方面的不足。
-调整cost
-eigrp
-pbr(扩展性 2 不具备重路由功能)
2.与qos不同,TE通过对流量或者是部分流量的控制来避免链路过载,充分利用链路。
因为网络中某些情况下最优路径并不是唯一路径。
因为网络中某些情况下最优路径并不是最好路径。
QOS是丢弃不重要的流量来保证重要流量的就应用。
tunnel 没队列,lo 0 subinterface
2.mpls te 的三大组件及三大组件如何协同工作。
1.mpls
cbr
rsvp(cr-ldp)
cbr的讲解(是ospf/isis 对TE的扩展,确定tunnel的建立路径)
1。普通的链路状态协议选路依据的参数(SPF)
三元组:router-id,neighbor-id,cost
2.CBR为支持mpls-te对普通链路状态协议 的改进(CSPF)
相对于三元组添加的其它参数(六元组,九元组)
ospf 的新增的lsa 10
aboute ospf 的扩展说明(也叫opaque lsas)
lsa9----link-local scope(只在链路间泛洪,用于ospf nsf多)
lsa10---area -local scope(只在本区域内泛洪)
lsa11---as-wide scope(在整个ospf 域内泛洪)
The link-state id field in the lsa header of an opaque lsa id defined as having two distinct portions.the fires 8 bit of the 32 bit field designate the opaque type ,while the remaining 24 bits represent a unique opaque id .the iana is reponsible for assigning opaque type codes 0 through 127,with the remaining values(128-255) set aside for private and experimental usage.
isis 的3个新增的TLV(TLV22/TLV124/TLV135)
关于isis 的扩展说明:
TLV22---扩展的中间系统可达性TLV(clns 扩展)
TLV134--流量工程router id TLV
TLV135--扩展的ip可达性TLV (ip的扩展)
CBR什么情况会泛洪TE信息:
1.对预留带宽的变化。
2.配置变化
3。在隧道设置失效之后
4。RSVP预留带宽的改变。
5.CBR周期性泛洪,比IGP更快(默认ospf 30min/isis 15min)
TE信息的泛洪周期默认是3min
mpls traffic-eng link-management timers periodic-flooding xxx
isis在以太网包的号:FEFE-------需查查,抓包。
所以协议都有触发更新。
mpls te 工作过程
tunnel interface
Constraint
>destination
>priority
>bandwidth
>affinity
1>>>tunnel interface -- CBR
2>>>rsvp
3>>>cspf在符合条件的拓扑中计算出源去往目的地的最优路径,并将该路径的每一个接口IP交与rsvp的ero.
4.rsvp----5.----mpls这个时候就真正预留带宽出来的。RSVP沿着ERO请求带宽和标签。
软协议rsvp,不具备选路。
ip rsvp sender-host x.x.x.x x.x.x.x tcp 80 80 1000 100 假设触发RSVP应用。
ip rsvp reservation-host x.x.x.x x.x.x.x tcp 80 80 1000 100
RSVP-------------------------------预留带宽,标签分配
rsvp是interserv信令协议.
为某个应用预留它所需要的资源。
RSVP本身不工作,需要网络应用去触发
.netmeeting/voip
.mpls te
>>>WFQ对RSVP支持的必要性
>>>传统RSVP及扩展RSVP对mpls te的支持
label request
label:
ERO:记录的是CBR给tunnel计算机出来的最短路径的每一个接口地址。
RRO:记录的是tunnel经过的每个网络节点tunnel的router-id和这个网络节点给tunnel分配的标签(也可以用于控制面的环路避免)
session attribute:attribute-flag,setup priority hold priority
三。autoroute 下在te隧道中的IGP路由度量值计算。
1.默认情况下,tunnel的metric值等于到达tunnel终点的所有物理链路中最小链路的metric值(要知道tunnel旨向的是一个节点
而不是具体某个地址)。所以从tunnel源到终点的所有直连链路都是从tunnel经过并且metric值都等于tunnel的metric.
2.在autoroute时调整度量值的计算可以通过tunnel下命令修改。
tunnel mpls traffic-eng autoroute metric{absolute | relative}value
absolute 仅仅指tunnel本身而以,不包括其直连接口,所以到达终点的直连链路的
metric=tunnel metric+直连链路metric
relative:以相对于最小度量值的igp路径来修改隧道用以在IGP中通告的度量。
forwarding adjacency mpls te的一个feature,可以让igp 将te lsp看作一条链路.te tunnel首端路由器上的igp将te lsp关联上一个特定的igp cost(自已指定)后以链路的形式将其通告出去。这样一来,同一个区域中的任何路由器在执行SPF算法的时候都将会包含这条链路,同样IGP将只会以一条链路的形式看待te tunnel的整个路径。
配置说明。必须在一对lsr之间配置两条te tunnel(每个方向上一条),并且必须在每一条上都启用邻接转发。这样做的原因是虽然只要在隧道的一个方向上配置邻接转发链路就会被通告,但是只有当两个方向上都能够看到这条链路的时候才会在spf算法中包含该邻接关系的链路。
pe-p
R1--R2--R3--R4--R5
R1---R4 tunnel 14
R5---R2 tunnel 25
解决方法,R5-tunnel 14 ldp
R1--tunnel 25 ldp
要建立单播邻居。定向的.
int tu 15
mpl i
R2:
mpls ldp discovery targeted-hello accept.接收定向的hello packet
R4:
mpls ldp neighbor 1.1.1.1 targeted ldp
三层标签。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号