

DDIA 第3章
数据库:append only
何为数据库?写个shell脚本,set的时候追加纪录,get的时候grep and tail 最新纪录,即为一个数据库
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
这个“数据库”写入是挺快的,但是一旦数据量增大,查询会有很大的性能问题
那么我们就需要想办法使用索引来加速查询。但是增加索引也会使得写入数据变慢。因为每次增删改数据的时候,索引也需要对应更新。
因此索引的选择非常的重要。
散列索引
这种appendonly 的情况下写入非常的快,但是查询的时候会很慢,怎么办?
我们可以增加hash索引:key 为编号,value为该记录所在的内存地址,这样可以很快的通过key找到对应的记录
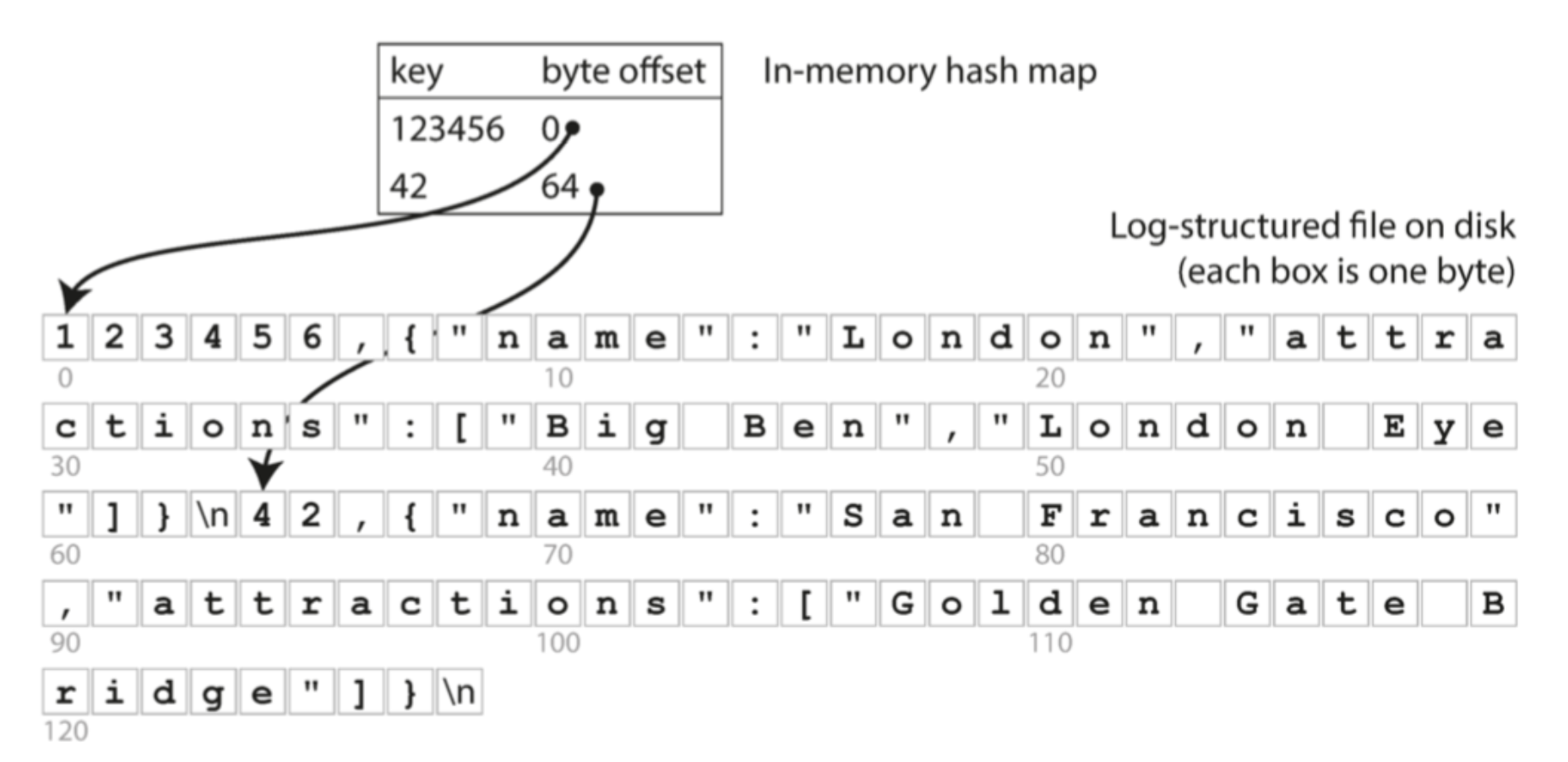
日志合并压缩
那么问题又来了, 我们一直追加写,磁盘迟早得被用完,怎么办?
这时候我们可以,将日志追加写到一定大小的段(segment),当segment到达一定大小的时候,关闭这个segment,打开一个新文件,然后对已经关闭的segment进行压缩.
压缩是怎么做的?想象一下,我们有好多重复的键因为我们每次update(set)记录的时候总是追加,因此,我们可以进行segment合并,舍弃旧的记录,只保留最新纪录


每个段现在都有自己的内存散列表,将键映射到文件偏移量。为了找到一个键的值,我们首先检查最近的段的散列映射;如果键不存在,我们就检查第二个最近的段,依此类推。合并过程将保持段的数量足够小,所以查找过程不需要检查太多的散列映射。
文件格式:使用二进制编码更快,空间更省
删除记录:并不是真的删除,而是追加了一个删除记录(tombstone),日志合并的时候通过这个tombstone可以将该条记录丢弃掉
崩溃恢复:内存hash索引定期snapshot + WAL (Write Ahead Log)
部分写入记录: 如果crash的时候有一半记录写进去了,怎么办?使用checksum做校验,舍弃坏记录
并发控制:由于写操作是以严格的顺序追加到日志中的,所以常见的实现是只有一个写入线程。也因为数据文件段是仅追加的或者说是不可变的,所以它们可以被多个线程同时读取。
数据更新的时候,为什么不直接在原位置更新,而是在最后追加新值进去? 原因是顺序写比随机写要快太多太多。
SSTables和LSM树
但是上面问题是,内存真的能放下所有的key吗?如果有很多很多key,怎么办?可以把这些key保存到硬盘吗?硬盘读性能绝对是块不到哪去的。

2.我们甚至不需要保存所有的排序过的key,以 图 3-5 为例:假设你正在内存中寻找键 handiwork,但是你不知道这个键在段文件中的确切偏移量。但你知道 handbag 和 handsome 的偏移,而且由于排序特性,你知道 handiwork 必须出现在这两者之间。这意味着你可以跳到 handbag 的偏移位置并从那里扫描,直到你找到 handiwork(或没找到,如果该文件中没有该键)。

构建和维护SSTables
B树:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}