C# 词法分析器(六)构造词法分析器 update 2022.09.12
系列导航
最核心的 DFA 已经成功构造出来了,最后一步就是根据 DFA 得到完整的词法分析器。
一、运行时词法规则的定义
T 表示词法分析器的标识符的类型(一般是一个枚举类型),TController 表示词法分析器的控制器,可以使用默认实现 LexerController<T>。定义规则方法包括:定义上下文的 DefineContext 方法、定义正则表达式的 DefineRegex 方法和定义终结符的 DefineSymbol 方法。调用 DefineContext 方法定义的词法分析器上下文,会使用 LexerContext 类的实例表示,它的基本定义如下所示:
// 当前上下文的索引。 int Index; // 当前上下文的标签。 string Label; // 当前上下文的类型。 LexerContextType ContextType;
在词法分析器中,仅可以通过标签来切换上下文,因此 LexerContext 类本身是 internal 的。
上下文的类型就是包含型或者排除型,等价于 Flex 中的 %s 和 %x 定义(可参见 Flex 的 Start Conditions)。这里简单的解释下,在进行词法分析时,如果当前上下文是排除型的,那么仅在当前上下文中定义的规则会被激活,其它的(非当前上下文中定义的)规则都会失效。如果当前上下文是包含型的,那么没有指定任何上下文的规则也会被激活。
默认上下文标签为 "Initial"。
DefineRegex 方法,就等价于 Flex 中的定义段(Definitions Section),可以定义一些常见的正则表达式以简化规则的定义,例如可以定义lexer.DefineRegex("digit", "[0-9]");
在正则表达式的定义中,就可以直接使用 "{digit}" 来引用预先定义的正则表达式。
最后是定义终结符的 DefineSymbol 方法,就对应于 Flex 中的规则段(Rules Section),可以定义终结符的正则表达式和相应的动作。
终结符的动作使用 Action<TController> 来表示,由 LexerController<T> 类来提供 Accept,Reject,More 等方法。
其中,Accept 方法会接受当前词法单元,并返回 Token 对象。Reject 方法会拒绝当前匹配,转而寻找次优的规则,这个操作会使词法分析器的所有匹配变慢,需要谨慎使用。More 方法通知词法分析器,下次匹配成功时,不替换当前的文本,而是把新的匹配追加在后面。
Accept 方法和 Reject 方法是相互冲突的,每次匹配成功只能调用其中的一个。如果两个都未调用,那么词法分析器会认为当前匹配是成功的,但不会返回 Token,而是继续匹配下一个词法单元。
二、设计时词法规则的定义
为了简化设计时词法规则的定义和实现,选择使用 C# Attribute 来指定相关规则,而非词法规则文件。为了使用 T4 模板,需引入一些必备依赖:
1. 通过 nuget 依赖运行时 Cyjb.Compilers.Runtime。
2. 通过 nuget 依赖生成器 Cyjb.Compilers.Design,注意请如下指定引用配置,可以正常编译项目并避免产生运行时引用。
<ItemGroup> <PackageReference Include="Cyjb.Compilers.Design" Version="1.0.4"> <GeneratePathProperty>True</GeneratePathProperty> <PrivateAssets>all</PrivateAssets> <IncludeAssets>compile; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets> </PackageReference> </ItemGroup>
之后就是定义词法规则了。首先要求提供一个继承自 LexerController<T> 的部分类,通过在这个类上定义 Attribute 完成词法规则的定义。
public partial class CalcController : LexerController<Calc> {
}
使用 LexerContextAttribute 和 LexerInclusiveContextAttribute 声明词法分析器的上下文。例如:
// 声明上下文
[LexerContext("TestContext")]
// 声明排除型上下文
[LexerInclusiveContext("TestContext2")]
public partial class CalcController : LexerController<Calc> {
}
使用 LexerRegexAttribute 声明正则表达式。例如:
// 声明正则表达式
[LexerRegex("digit", "[0-9]+")]
public partial class CalcController : LexerController<Calc> {
}
使用 LexerSymbolAttribute 声明终结符。可以声明在类上,表示没有相关动作,也可以声明在方法上,并将此方法作为相关动作。例如:
// 声明终结符
[LexerSymbol("\\+", Kind = Calc.Add)]
public partial class CalcController : LexerController<Calc> {
/// <summary>
/// 数字的终结符定义。
/// </summary>
[LexerSymbol("[0-9]+", Kind = Calc.Id)]
public void DigitAction()
{
Value = int.Parse(Text);
Accept();
}
}
最后是添加与词法分析器同名的 tt 文件,内容如下:
<#@ include file="$(PkgCyjb_Compilers_Design)\content\CompilerTemplate.t4" #>
运行 T4 模板后即可生成同名的 .lexer.cs 文件,包含了词法分析器的实现。下图是一个简单的示例:
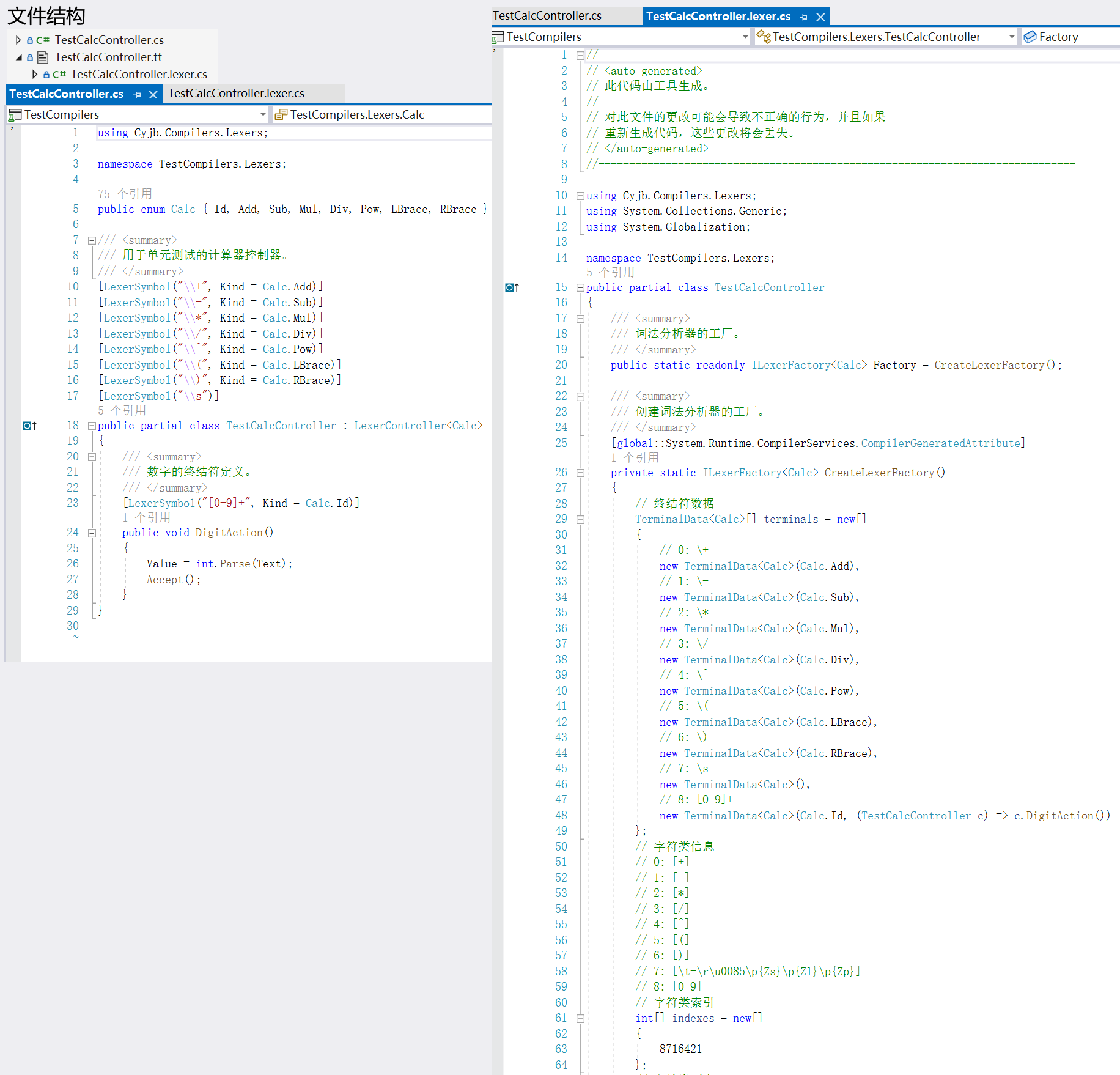
图 1 设计时词法分析器示例
三、词法分析器的实现
3.1 基本的词法分析器
由于多个规则间是可能产生冲突的,例如字符串可以与多个正则表达式匹配,因此在说明词法分析器之前,首先需要定义一个解决冲突的规则。这里采用与 Flex 相同的规则:
- 总是选择最长的匹配。
- 如果最长的匹配与多个正则表达式匹配,总是选择先被定义的正则表达式。
基本的词法分析器非常简单,它只能实现最基础的词法分析器功能,不能支持向前看符号和 Reject 动作,但是大部分情况下,这就足够了。
这样的词法分析器几乎相当于一个 DFA 执行器,只要不断从输入流中读取字符送入 DFA 引擎,并记录下来最后一次出现的接受状态就可以了。当 DFA 引擎到达了死状态,找到的词素就是最后一次出现的接受状态对应的符号(这样就能保证找到的词素是最长的),对应多个符号的时候只取第一个(之前已经将符号索引从小到大进行了排序,因此第一个符号就是最先定义的符号)。
简单的算法如下:
输入:DFA $D$
$s = s_0$
while (c != eof) {
$s = D[c]$
if ($s \in FinalStates$) {
$s_{last} = s$
}
c = nextChar();
}
$s_{last}$ 即为匹配的词素
实现该算法的代码可见 TokenizerSimple<T> 类,核心代码如下:
// 最后一次匹配的符号和文本索引。
int lastAccept = -1, lastIndex = Source.Index;
while (true) {
state = NextState(state);
if (state == -1) {
// 没有合适的转移,退出。
break;
}
int[] symbols = Data.States[state].Symbols;
if (symbols.Length > 0) {
lastAccept = symbols[0];
lastIndex = Source.Index;
}
}
if (lastAccept >= 0) {
// 将流调整到与接受状态匹配的状态。
Source.Index = lastIndex;
TerminalData<T> terminal = Data.Terminals[lastAccept];
Controller.DoAction(Start, terminal.Kind, terminal.Action);
}
3.2 支持定长的向前看符号的词法分析器
接下来,将上面的基本的词法分析器进行扩展,让它支持定长的向前看符号。
向前看符号的规则形式为 $r = s/t$,如果 $s$ 或 $t$ 可以匹配的字符串长度是固定的,就称作定长的向前看符号;如果都不是固定的,则称为变长的向前看符号。
例如正则表达式 abcd 或者 [a-z]{2},它们可以匹配的字符串长度是固定的,分别为 4 和 2;而正则表达式 [0-9]+ 可以匹配的字符串长度就是不固定的,只要是大于等于一都是可能的。
区分定长和变长的向前看符号,是因为定长的向前看符号匹配起来更容易。例如正则表达式 a\*/bcd,识别出该模式后,直接回退三个字符,就找到了 a* 的结束位置。
对于规则 abc/d*,识别出该模式后,直接回退到只剩下三个字符,就找到了 abc 的结束位置。
我将向前看符号可以匹配的字符串长度预先计算出来,存储在 int? Trailing 数组中,其中 null 表示不是向前看符号,正数表示前面($s$)的长度固定,负数表示后面($t$)的长度固定,0 表示长度都不固定。
所以,只需要在正常的匹配之后,判断 Trailing 的值。如果为 null,不是向前看符号,不用做任何操作;如果是正数 n,则把当前匹配的字符串的前 n 位取出来作为实际匹配的字符串;如果是负数 $-n$,则把后 $n$ 位取出来作为实际匹配的字符串。实现的代码可见 TokenizerFixedTrailing<T> 类。
3.3 支持变长的向前看符号的词法分析器
对于变长的向前看符号,处理起来则要更复杂些。因为不能确定向前看的头是在哪里(并没有一个确定的长度),所以必须使用堆栈保存所有遇到的接受状态,并沿着堆栈向下找,直到找到包含 -symbolIndex 的状态(我就是这么区分向前看的头状态的,可参见上一篇《C# 词法分析器(五)转换 DFA》的 2.4 节 DFA 状态的符号索引)。
需要注意的是,变长的向前看符号是有限制的,例如正则表达式 ab\*/bcd\*,这时无法准确的找到 ab\* 的结束位置,而是会找到最后一个 b 的位置,导致最终匹配的词素不是想要的那个。出现这种情况的原因是使用 DFA 进行字符串匹配的限制,只要是前一部分的结尾与后一部分的开头匹配,就会出现这种问题,所以要尽量避免定义这样的正则表达式。
实现的代码可见 TokenizerRejectableTrailing<T> 类,沿着状态堆栈寻找目标向前看的头状态的代码如下:
// stateStack 是状态堆栈
int target = -acceptState;
while (true) {
astate = stateStack.Pop();
if (ContainsTrailingHead(astate.Symbols, target)) {
// 找到了目标状态。
break;
}
}
// ContainsTrailingHead 方法利用符号索引的有序,避免了很多不必要的比较。
bool ContainsTrailingHead(int[] symbolInsymbolsdex, int target) {
// 在当前状态中查找,从后向前找。
for (int i = symbols.Length - 1; i >= 0; i--) {
int idx = symbols[i];
if (idx >= 0)
{
// 前面的状态已经不可能是向前看头状态了,所以直接退出。
break;
}
if (idx == target) {
return true;
}
}
return false;
}
在沿着堆栈寻找向前看头状态的时候,不必担心找不到这样的状态,DFA 执行时,向前看的头状态一定会在向前看状态之前出现。
3.4 支持 Reject 动过的词法分析器
Reject 动作会指示词法分析器跳过当前匹配规则,而去寻找同样匹配输入(或者是输入的前缀)的次优规则。
比如下面的例子:
lexer.DefineSymbol("a").Action(c => { Console.WriteLine(c.Text); c.Reject(); });
lexer.DefineSymbol("ab").Action(c => { Console.WriteLine(c.Text); c.Reject(); });
lexer.DefineSymbol("abc").Action(c => { Console.WriteLine(c.Text); c.Reject(); });
lexer.DefineSymbol("abcd").Action(c => { Console.WriteLine(c.Text); c.Reject(); });
lexer.DefineSymbol("bcd").Action(c => { Console.WriteLine(c.Text); });
lexer.DefineSymbol(".").Action(c => { });
对字符串 "abcd" 进行匹配,最后输出的结果是:
abcd abc ab a bcd
具体的匹配过程如下所示:
第一次匹配了第 4 个规则 "abcd",然后输出字符串 "abcd",并 Reject。
所以词法分析器会尝试次优规则,即第 3 个规则 "abc",然后输出字符串 "abc",并 Reject。
接下来继续尝试次优规则,即第 2 个规则 "ab",然后输出字符串 "ab",并 Reject。
继续尝试次优规则,即第 1 个规则 "a",然后输出字符串 "a",并 Reject。
然后,继续尝试次优规则,即第 6 个规则 ".",此时字符串 "a" 被成功匹配。
最后,剩下的字符串 "bcd" 恰好与规则 5 匹配,所以直接输出 "bcd"。
在实现上,为了做到这一点,同样需要使用堆栈来保存所有遇到的接受状态,如果当前匹配被 Reject,就沿着堆栈找到次优的匹配。实现的代码可见 TokenizerRejectable<T> 类。
上面这四个小节,说明了词法分析器的基本结构,和一些功能的实现。实现了所有功能的词法分析器实现可见 TokenizerRejectableTrailing<T> 类。
四、一些词法分析的例子
接下来,我会给出一些词法分析器的实际用法,可以作为参考。
4.1 计算器
下面的例子是一个简单的计算器词法分析器:
enum Calc { Id, Add, Sub, Mul, Div, Pow, LBrace, RBrace }
Lexer<Calc> lexer = new();
lexer.DefineSymbol("[0-9]+").Kind(Calc.Id).Action(c =>
{
c.Value = int.Parse(c.Text);
c.Accept();
});
lexer.DefineSymbol("\\+").Kind(Calc.Add);
lexer.DefineSymbol("\\-").Kind(Calc.Sub);
lexer.DefineSymbol("\\*").Kind(Calc.Mul);
lexer.DefineSymbol("\\/").Kind(Calc.Div);
lexer.DefineSymbol("\\^").Kind(Calc.Pow);
lexer.DefineSymbol("\\(").Kind(Calc.LBrace);
lexer.DefineSymbol("\\)").Kind(Calc.RBrace);
// 吃掉所有空白。
lexer.DefineSymbol("\\s");
ILexerFactory<Calc> factory = lexer.GetFactory();
string text = "456 + (98 - 56) * 89 / -845 + 2^3";
Tokenizer<Calc> tokenizer = factory.CreateTokenizer(text);
foreach(Token<Calc> token in tokenizer) {
Console.WriteLine(token);
}
// 输出为:
// Id "456" at [0..3)
// Add "+" at [4..5)
// LBrace "(" at [6..7)
// Id "98" at [7..9)
// Sub "-" at [10..11)
// Id "56" at [12..14)
// RBrace ")" at [14..15)
// Mul "*" at [16..17)
// Id "89" at [18..20)
// Div "/" at [21..22)
// Sub "-" at [23..24)
// Id "845" at [24..27)
// Add "+" at [28..29)
// Id "2" at [30..31)
// Pow "^" at [31..32)
// Id "3" at [32..33)
// <<EOF>> at 33
相应的设计时词法分析器定义为:
[LexerSymbol("\\+", Kind = Calc.Add)]
[LexerSymbol("\\-", Kind = Calc.Sub)]
[LexerSymbol("\\*", Kind = Calc.Mul)]
[LexerSymbol("\\/", Kind = Calc.Div)]
[LexerSymbol("\\^", Kind = Calc.Pow)]
[LexerSymbol("\\(", Kind = Calc.LBrace)]
[LexerSymbol("\\)", Kind = Calc.RBrace)]
[LexerSymbol("\\s")]
partial class CalcController : LexerController<Calc>
{
/// <summary>
/// 数字的终结符定义。
/// </summary>
[LexerSymbol("[0-9]+", Kind = Calc.Id)]
public void DigitAction()
{
Value = int.Parse(Text);
Accept();
}
}
4.2 字符串
下面的例子可以匹配任意的字符串,包括普通字符串和逐字字符串(@"" 这样的字符串)。由于代码中的字符串用的都是逐字字符串,所以双引号比较多,一定要数清楚个数。
enum Str { Str }
Lexer<Str> lexer = new();
lexer.DefineRegex("regular_char", @"[^""\\\n\r\u0085\u2028\u2029]|(\\.)");
lexer.DefineRegex("regular_literal", @"\""{regular_char}*\""");
lexer.DefineRegex("verbatim_char", @"[^""]|\""\""");
lexer.DefineRegex("verbatim_literal", @"@\""{verbatim_char}*\""");
lexer.DefineSymbol("{regular_literal}|{verbatim_literal}").Kind(Str.Str);
ILexerFactory<Str> factory = lexer.GetFactory();
string text = @"""abcd\n\r""""aabb\""ccd\u0045\x47""@""abcd\n\r""@""aabb\""""ccd\u0045\x47""";
Tokenizer<Str> tokenizer = factory.CreateTokenizer(text);
foreach (Token<Str> token in tokenizer)
{
Console.WriteLine(token);
}
// 输出为:
// Str ""abcd\n\r"" at [0..10)
// Str ""aabb\"ccd\u0045\x47"" at [10..31)
// Str "@"abcd\n\r"" at [31..42)
// Str "@"aabb\""ccd\u0045\x47"" at [42..65)
// <<EOF>> at 65
相应的设计时词法分析器定义为:
[LexerRegex("regular_char", @"[^""\\\n\r\u0085\u2028\u2029]|(\\.)")]
[LexerRegex("regular_literal", @"\""{regular_char}*\""")]
[LexerRegex("verbatim_char", @"[^""]|\""\""")]
[LexerRegex("verbatim_literal", @"@\""{verbatim_char}*\""")]
[LexerSymbol("{regular_literal}|{verbatim_literal}", Kind = Str.Str)]
partial class TestStrController : LexerController<Str>
{ }
4.3 转义的字符串
下面的例子利用了上下文,不但可以匹配任意的字符串,同时还可以对字符串进行转义。
class EscapeStrController : LexerController<Str>
{
public int CurStart;
public StringBuilder DecodedText = new();
}
Lexer<Str, EscapeStrController> lexer = new();
const string ctxStr = "str";
const string ctxVstr = "vstr";
lexer.DefineContext(ctxStr);
lexer.DefineContext(ctxVstr);
// 终结符的定义。
lexer.DefineSymbol(@"\""").Action(c =>
{
c.PushContext(ctxStr);
c.CurStart = c.Start;
c.DecodedText.Clear();
});
lexer.DefineSymbol(@"@\""").Action(c =>
{
c.PushContext(ctxVstr);
c.CurStart = c.Start;
c.DecodedText.Clear();
});
lexer.DefineSymbol(@"\""").Context(ctxStr).Action(c =>
{
c.PopContext();
c.Start = c.CurStart;
c.Text = c.DecodedText.ToString();
c.Accept(Str.Str);
});
lexer.DefineSymbol(@"\\u[0-9]{4}").Context(ctxStr).Action(c =>
{
c.DecodedText.Append((char)int.Parse(c.Text.AsSpan()[2..], NumberStyles.HexNumber));
});
lexer.DefineSymbol(@"\\x[0-9]{2}").Context(ctxStr).Action(c =>
{
c.DecodedText.Append((char)int.Parse(c.Text.AsSpan()[2..], NumberStyles.HexNumber));
});
lexer.DefineSymbol(@"\\n").Context(ctxStr).Action(c =>
{
c.DecodedText.Append('\n');
});
lexer.DefineSymbol(@"\\\""").Context(ctxStr).Action(c =>
{
c.DecodedText.Append('\"');
});
lexer.DefineSymbol(@"\\r").Context(ctxStr).Action(c =>
{
c.DecodedText.Append('\r');
});
lexer.DefineSymbol(@".").Context(ctxStr).Action(c =>
{
c.DecodedText.Append(c.Text);
});
lexer.DefineSymbol(@"\""").Context(ctxVstr).Action(c =>
{
c.PopContext();
c.Start = c.CurStart;
c.Text = c.DecodedText.ToString();
c.Accept(Str.Str);
});
lexer.DefineSymbol(@"\""\""").Context(ctxVstr).Action(c =>
{
c.DecodedText.Append('"');
});
lexer.DefineSymbol(@".").Context(ctxVstr).Action(c =>
{
c.DecodedText.Append(c.Text);
});
ILexerFactory<Str> factory = lexer.GetFactory();
string text = @"""abcd\n\r""""aabb\""ccd\u0045\x47""@""abcd\n\r""@""aabb\""""ccd\u0045\x47""";
Tokenizer<Str> tokenizer = factory.CreateTokenizer(text);
foreach (Token<Str> token in tokenizer)
{
Console.WriteLine(token);
}
// 输出为:
// Str "abcd
// " at [0..10)
// Str "aabb"ccdEG" at [10..31)
// Str "abcd\n\r" at [31..42)
// Str "aabb\"ccd\u0045\x47" at [42..65)
// <<EOF>> at 65
这里利用自定义词法分析控制器类型支持词法分析器的复用,避免在多次调用中并发访问同一闭包中的变量。这里的输出结果,恰好是 4.2 节的输出结果转义之后的结果。需要注意的是,这里利用 c.Accept() 方法修改了要返回的词法单元,而且由于涉及到多重转义,在设计规则的时候一定要注意双引号和反斜杠的个数。
相应的设计时词法分析器定义为:
[LexerContext("str")]
[LexerContext("vstr")]
partial class TestEscapeStrController : LexerController<Str>
{
private const string CtxStr = "str";
private const string CtxVstr = "vstr";
private int curStart;
private readonly StringBuilder decodedText = new();
[LexerSymbol(@"\""")]
public void BeginStrAction()
{
PushContext(CtxStr);
curStart = Start;
decodedText.Clear();
}
[LexerSymbol(@"@\""")]
public void BeginVstrAction()
{
PushContext(CtxVstr);
curStart = Start;
decodedText.Clear();
}
[LexerSymbol(@"<str, vstr>\""", Kind = Str.Str)]
public void EndAction()
{
PopContext();
Start = curStart;
Text = decodedText.ToString();
}
[LexerSymbol(@"<str>\\u[0-9]{4}")]
[LexerSymbol(@"<str>\\x[0-9]{2}")]
public void HexEscapeAction()
{
decodedText.Append((char)int.Parse(Text.AsSpan()[2..], NumberStyles.HexNumber));
}
[LexerSymbol(@"<str>\\n")]
public void EscapeLFAction()
{
decodedText.Append('\n');
}
[LexerSymbol(@"<str>\\\""")]
public void EscapeQuoteAction()
{
decodedText.Append('\"');
}
[LexerSymbol(@"<str>\\r")]
public void EscapeCRAction()
{
decodedText.Append('\r');
}
[LexerSymbol(@"<*>.")]
public void CopyAction()
{
decodedText.Append(Text);
}
[LexerSymbol(@"<vstr>\""\""")]
public void VstrQuoteAction()
{
decodedText.Append('"');
}
}
现在,完整的词法分析器已经成功构造出来,相关代码都可以在这里找到。
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号