
hibernate笔记
什么是POJO
在使用hibernate时,要求和数据库的某张表相互映射的那个java类,
是一个POJO类,一般放在com.xxx.domain包下,POJO类翻译过来就是:
简单的Java对象(Plain Ordinary Java Objects)实际就是普通
JavaBeans,使用POJO名称是为了避免和EJB混淆起来。一个POJO类应当
具有:
①有一个主键属性,用于唯一标识该对象。
(这就是为什么hibernate设计者建议要映射的表需要一个主键)
②有其它的属性
③有对各个属性操作的get/set方法
④属性一般是private修饰.
⑤一定有一个无参的构造函数(用于hibernate框架反射用.)
■ Configuraion类
①负责管理hibernate的配置信息
②读取hibernate.cfg.xml
③加载hibernate.cfg.xml配置文件中
配置的驱动,url,用户名,密码,连接池.
④管理 *.hbm.xml对象关系文件.
hibernate.cfg.xml文件
①该文件主要用于指定各个参数,是hibernate核心文件
②默认放在src目录下,也可以放在别的目录下。
③指定连接数据库的驱动、用户名、密码、url、连接池..
④指定对象关系映射文件的位置.
⑤也可使用hibernate.properties文件来替代该文件.(推荐使用
hibernate.cfg.xml)。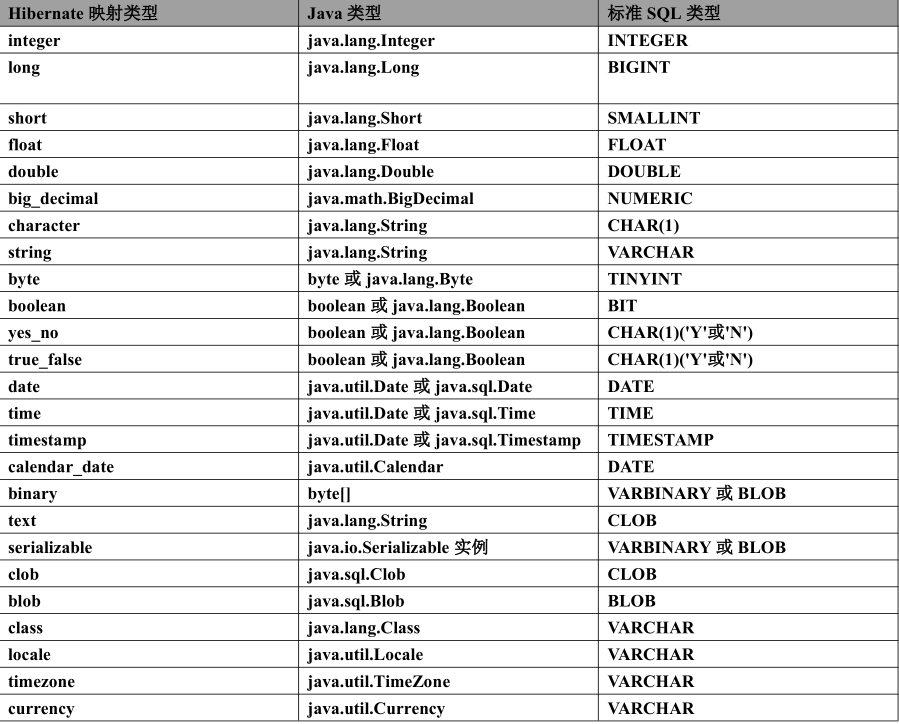
■ get()和load()区别
1、get()方法直接返回实体类,如果查不到数据则返回null。load()会
返回一个实体代理对象(当前这个对象可以自动转化为实体对象),
但当代理对象被调用时,如果没有数据不存在,就会抛出个
org.hibernate.ObjectNotFoundException异常
2.load先到缓存(session缓存/二级缓存)中去查,如果没有则返回一个
代理对象(不马上到DB中去找),等后面使用这个代理对象操作的时
候,才到DB中查询,这就是我们常说的 load在默认情况下支持延迟加
载(lazy)
3. get先到缓存(session缓存/二级缓存)中去查,如果没有就到DB中去
查(即马上发出sql)。总之,如果你确定DB中有这个对象就用
load(),不确定就用get()(这样效率高)
■ openSession()和 getCurrentSession()区别
①采用getCurrentSession()创建的session会绑定到当前线程中,而采用openSession()创建的session则不会
②采用getCurrentSession()创建的session在commit或rollback时会自动关闭,而采用openSession()创建的session必须手动关闭.
③使用getCurrentSession()需要在hibernate.cfg.xml文件中加入
如下配置:
* 如果使用的是本地事务(jdbc事务)
<property name="hibernate.current_session_context_class">thread</property>
* 如果使用的是全局事务(jta事务)
<property name="hibernate.current_session_context_class">jta</property>
■ openSession()和 getCurrentSession()联系
深入探讨:
在 SessionFactory启动的时候,Hibernate 会根据配置创建相应的 CurrentSessionContext,在getCurrentSession()被调用的时候,实际被执行的方法是 CurrentSessionContext.currentSession()。在
currentSession()执行时,如果当前Session为空,currentSession会调用SessionFactory的openSession。
Session 常用方法讲解
1,save()方法 将一个临时对象转变成持久化对象;
2,load()方法 VS get()方法
都是根据 OID 从数据库中加载一个持久化对象。
区别 1:假如数据库中不存在与 OID 对应的记录,Load()方法会抛出异常,而 get()方法返回 null;
区别 2:load 方法默认采用延迟加载策略,get 方法采用立即检索策略;
2,update()方法 将一个游离对象转变为持久化对象;
3,saveOrUpdate()方法 包含了 save()和 update()方法;
4,merge()方法,合并对象;
5,delete()方法,删除对象;
对象状态:
瞬时(transient):数据库中没有数据与之对应,超过作用域会被JVM垃圾回收器回收,一般是new出来且与session没有关联的对象。
持久(persistent):数据库中有数据与之对应,当前与session有关联,并且相关联的session没有关闭,事务没有提交;持久对象状态发生改变,在事务提交时会影响到数据库(hibernate能检测到)。
脱管/游离(detached):数据库中有数据与之对应,但当前没有session与之关联;脱管对象状态发生改变,hibernate不能检测到。
Hibernate 中四种对象状态
临时状态(transient):刚用 new 语句创建,还没有被持久化,并且不处于 Sesssion 的缓存中。处于临时状态
的 Java 对象被称为临时对象。
持久化状态(persistent):已经被持久化,并且加入到 Session 的缓存中。处于持久化状态的 Java 对象被称为
持久化对象。
删除状态(removed):不再处于 Session 的缓存中,并且 Session 已经计划将其从数据库中删除。处于删除状
态的 Java 对象被称为删除对象。
游离状态(detached):已经被持久化,但不再处于 Session 的缓存中。处于游离状态的 Java 对象被称为游离对
象。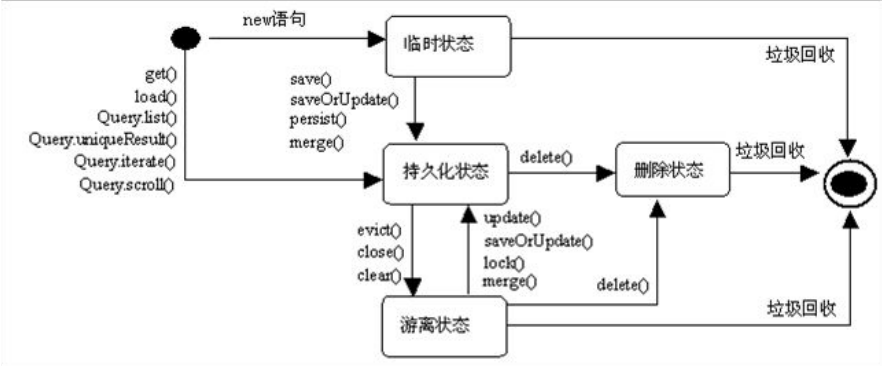
一对多(Department-Employee)
Department映射文件添加
<set name=”集合对象属性名”>
<key column=”外键名”/>
<one-to-many class=”集合放入的类名”/>
</set>
一对一(Person - IdCard)
1)基于主键的one-to-one(IdCard的映射文件)
<id name=”id”>
<generator class=”foreign”><param name=”property”>person</param></generator>
<id>
<one-to-one name=” person” constrained=”true”/>
[没有constraned true将不会生成外键约束]
Person映射文件: <one-to-one name=“idCard” />
一对一(Person - IdCard)
2)基于外健的one-to-one,可以描述为多对一,加unique=“true”约束,
IdCard的映射文件 中:
<many-to-one name=”person” column=”person_id” unique=”true” not-null=”true”/>
<!-唯一的多对一,其实就便成了一对一了就会在Idcard表生成外键-->
☞ Person映射文件不变化:
多对多(student - course)
在操作和性能方面都不太理想,所以多对多的映射使用较少,实际使
用中最好转换成一对多的对象模型;Hibernate会为我们创建中间
关联表,转换成两个一对多。
<set name=“xxx" table=“xxx">
<key column=“xxx"/>
<many-to-many class=“xxx" column=“xxx"/>
</set>
多对多(student - course)
在操作和性能方面都不太理想,所以多对多的映射使用较少,实际使
用中最好转换成一对多的对象模型;Hibernate会为我们创建中间
关联表,转换成两个一对多。
cascade (Employee – Department) bbs()
Casade用来说明当对主对象进行某种操作时是否对其关联的从对象也作类似的操作,常用的cascade:
none,all,save-update ,delete, lock,refresh,evict,replicate,persist,
merge,delete-orphan(one-to-many) 。一般对many-to-one,many-to-many不设置级联,在<one-to-one>和<one-to-many>中设置级联。
① 在集合属性和普通属性中都能使用cascade
② 一般讲cascade配置在one-to-many(one的一方,比如Employee-Department),和one-to-one(主对象一方)
■ 懒加载的概念
懒加载(Load On Demand)是一种独特而又强大的数据获取方法 ,
是指程序推迟访问数据库,这样做可以保证有时候不必要的访问数
据库,因为访问一次数据库是比较耗时的。
Domain Object 是非final的,才能实现懒加
载。
懒加载问题 ,解决:
Hibernate.initialize(代理对象);
在映射文件中加入 lazy=“false”
openinsessionview解决(过滤器)
1,缓存的概念:
缓存是介于物理数据源与应用程序之间,是对数据库中的数据复制一份临时放在内存或者硬盘中的容
器,其作用是为了减少应用程序对物理数据源访问的次数,从而提高了应用程序的运行性能。Hibernate 在进
行读取数据的时候,根据缓存机制在相应的缓存中查询,如果在缓存中找到了需要的数据(我们把这称做“缓
存命 中"),则就直接把命中的数据作为结果加以利用,避免了大量发送 SQL 语句到数据库查询的性能损耗。
2,Hibernate 缓存的分类:
一、Session 缓存(又称作事务缓存):Hibernate 内置的,不能卸除。
缓存范围:缓存只能被当前 Session 对象访问。缓存的生命周期依赖于 Session 的生命周期,当 Session 被关闭
后,缓存也就结束生命周期。
二、SessionFactory 缓存(又称作应用缓存):使用第三方插件,可插拔。
缓存范围:缓存被应用范围内的所有 session 共享,不同的 Session 可以共享。这些 session 有可能是并发访问缓
存,因此必须对缓存进行更新。缓存的生命周期依赖于应用的生命周期,应用结束时,缓存也就结束了生命
周期,二级缓存存在于应用程序范围。
3,二级缓存策略提供商:
提供了 HashTable 缓存,EHCache,OSCache,SwarmCache,jBoss Cathe2,这些缓存机制,其中 EHCache,
OSCache 是不能用于集群环境(Cluster Safe)的,而 SwarmCache,jBoss Cathe2 是可以的。HashTable 缓存主
要是用来测试的,只能把对象放在内存中,EHCache,OSCache 可以把对象放在内存(memory)中,也可以
把对象放在硬盘(disk)上(为什么放到硬盘上?上面解释了)。
4,什么数据适合放二级缓存中:
(1)经常被访问
(2)改动不大
(3)数量有限
(4)不是很重要的数据,允许出现偶尔并发的数据。
比如组织机构代码,列表信息等;
缓存的作用主要用来提高性能,可以简单的理解成一个Map;使
用缓存涉及到三个操作:把数据放入缓存、从缓存中获取数据、
删除缓存中的无效数据。
一级缓存,Session级共享。
save,update,saveOrUpdate,load,get,list,iterate,lock这些方法都会将对象放在一级缓存中,一级缓存不能控制缓存的数量,所以要注意大批量操作数据时可能造成内存溢出;可以用evict,clear方法清除缓存中的内容。
二级缓存, SessionFacotry级共享
hibernate二级缓存插件(组件)一览图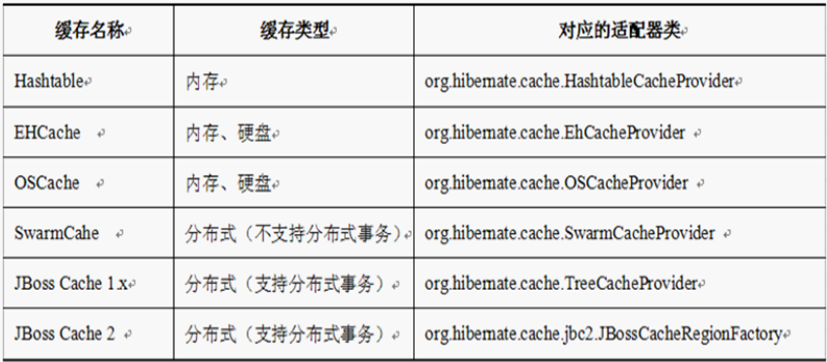
应用OsCache作为二级缓存
①步骤 -配置
②步骤-拷贝一个oscache.propertis配置文件
③步骤-在*.hbm.xml文件中加入使用二级缓存的策略
<cache usage="read-write"/>
也可以直接在hibernate.cfg.xml配置:
<class-cache class="cn.hsp.domain.Users" usage="read-only" />
hibernate二级缓存策略
■ 只读缓存(read-only)
■ 读写缓存(read-write) [ 银行,财务软件]
■ 不严格读写缓存(nonstrict-read-write) [bbs 被浏览多少次]
■ 事务缓存(transactional)
统计信息打开generate_statistics,用sessionFactory.getSatistics()获取统计信息。
什么是对象标识符(OID object id)
Hibernate 中的持久化对象对应数据库中的一张数据表,因此区分不同的持久化对象,在Hibernate中是通过OID(对象标识符)来完成的,从表的角度看,OID对应表的主键。从类的角度看OID对应类的主键属性.
对象标识符生成方法
Hibernate中的主要对象标识生成策略很多,这里主要介绍8种标识
符生成方法,其中包括7种标识符生成器和一种复合主键生成方式。
①increment ②indentity
③sequence ④hilo
⑤native ⑥assigned
⑦uuid ⑧foreign
①increment标识符生成器
由Hibernate自动以递增方式生成标识符,每次增量为1。
优点:不依赖于底层数据库系统,适用于所有的数据库系统。
缺点:适用于单进程环境下,在多线程环境下很可能生成相同主键值
,而且OID必须为数值类型,比如long,int,short类型
配置方式:
<id name=“id” type=”long” column=”ID”>
<generator class=”increment”/>
</id>
②identity标识符生成器
由底层数据库生成标识符。
前提条件:数据库支持自动增长字段类型,比如(sql server,mysql)
,而且OID必须为数值类型,比如long,int,short类型。
配置文件:
<id name=”id” type=”long” column=”ID”>
<generator class=”identity”/>
</id>
③sequence标识符生成器
依赖于底层数据库系统的序列
前提条件:需要数据库支持序列机制(如:oracle等),而且OID必须
为数值类型,比如long,int,short类型。
配置文件:
<id name=”id” type=”java.lang.Long” column=”ID”>
<generator class=”sequence”>
<param name=”sequence”>my_seq</param>
</generator>
</id>
④native标识符生成器
native生成器能根据底层数据库系统的类型,自动选择合适的标识
符生成器,因此非常适用于跨数据库平台开发,他会由Hibernate根据
数据库适配器中的定义,自动采用identity,hilo,sequence的其中一种
作为主键生成方式,但是OID必须为数值类型(比如long,short,int等)
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”>
<generator class=”native”/>
</id>
⑤hilo标识符生成器
hilo标识符生成器由Hibernate按照一种high/low算法生成标识符,
他从数据库中的特定表的字段中获取high值,因此需要额外的数据库表
保存主键生成的历史状态,hilo生成方法不依赖于底层数据库,因此适
用于每一种数据库,但是OID必须为数值类型(long,int,shor类型)。
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”>
<generator class=”hilo”>
<param name=”table”>my_hi_value</param>
<param name=”column”>next_value</param>
</generator>
</id>
⑥uuid标识符生成器
由Hibernate基于128位唯一值产生算法,根据当前设备IP,时间,
JVM启动时间,内部自增量等4个参数生成16进制数值作为主键,一般
而言,利用uuid方式生成的主键提供最好的数据插入性能和数据库平台
适应性. OID一般使用是String类型,大家去试试数值可否?
配置文件:
<id name=”id” type=”java.lang.String” column=”ID”>
<generator class=”uuid”/>
</id>
⑦assigned标识符生成器
采用assign生成策略表示由应用程序逻辑来负责生成主键标识符,
OID类型没有限制。
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”>
<generator class=”assigned”/>
</id>
⑧映射复合主键—略讲
为了讲解复合主键,我们先建一张表:
create table CUSTOMERS
( CUSNAME VARCHAR2(40) not null,
HOMEADDRESS VARCHAR2(50) not null,
BIRTHDAY DATE not null,
SEX VARCHAR2(2),
CUSCOMPANY VARCHAR2(40)
)
设置复合主键
alter table CUSTOMERS
add constraint CUS_PK primary key (CUSNAME, HOMEADDRESS, BIRTHDAY)
⑧映射复合主键—略讲
第一种方式:以独立主键类映射复合主键,这样可以达到将逻辑加以
隔离的目的,配置文件如下:
<composite-id name="id" class="com.test.model.pojo.CustomersId">
<key-property name="cusname" type="java.lang.String">
<column name="CUSNAME" length="40" />
</key-property>
<key-property name="homeaddress" type="java.lang.String">
<column name="HOMEADDRESS" length="50" />
</key-property>
<key-property name="birthday" type="java.util.Date">
<column name="BIRTHDAY" length="7" />
</key-property>
</composite-id>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号