
selenium4元素定位
1、根据元素属性ID定位到元素
from selenium impot webdriver
from selenium.webdriver.comom.by import By
#创建webdriver对象
wd=webdriver.Chrom()
#调用webdriver对象的get方法 可以让浏览器打开指定的网址
wd.get('http://www.baidu.com)
#对页面元素进行操作
wd.find_element(By.ID,'kw').send_keys('selenium')
#分解 1、element=wd.find_element(By.ID,'kw'),根据id选择元素,返回的就是该元素对应的webelement对象
#2、element.send_keys('selenium')) ,通过webelement对象,就可以对页面元素进行操作,例如输入字符串到这个输入框里
2、class属性 class_name,tag名
#根据class_name选择元素,返回的是一个列表
里面都是class属性值为title-content-title 的元素对应的webelement对象
elements=driver.find_elements(By.CLASS_NAME,'title-content-title')
#for element in elements:
# print(element.text)
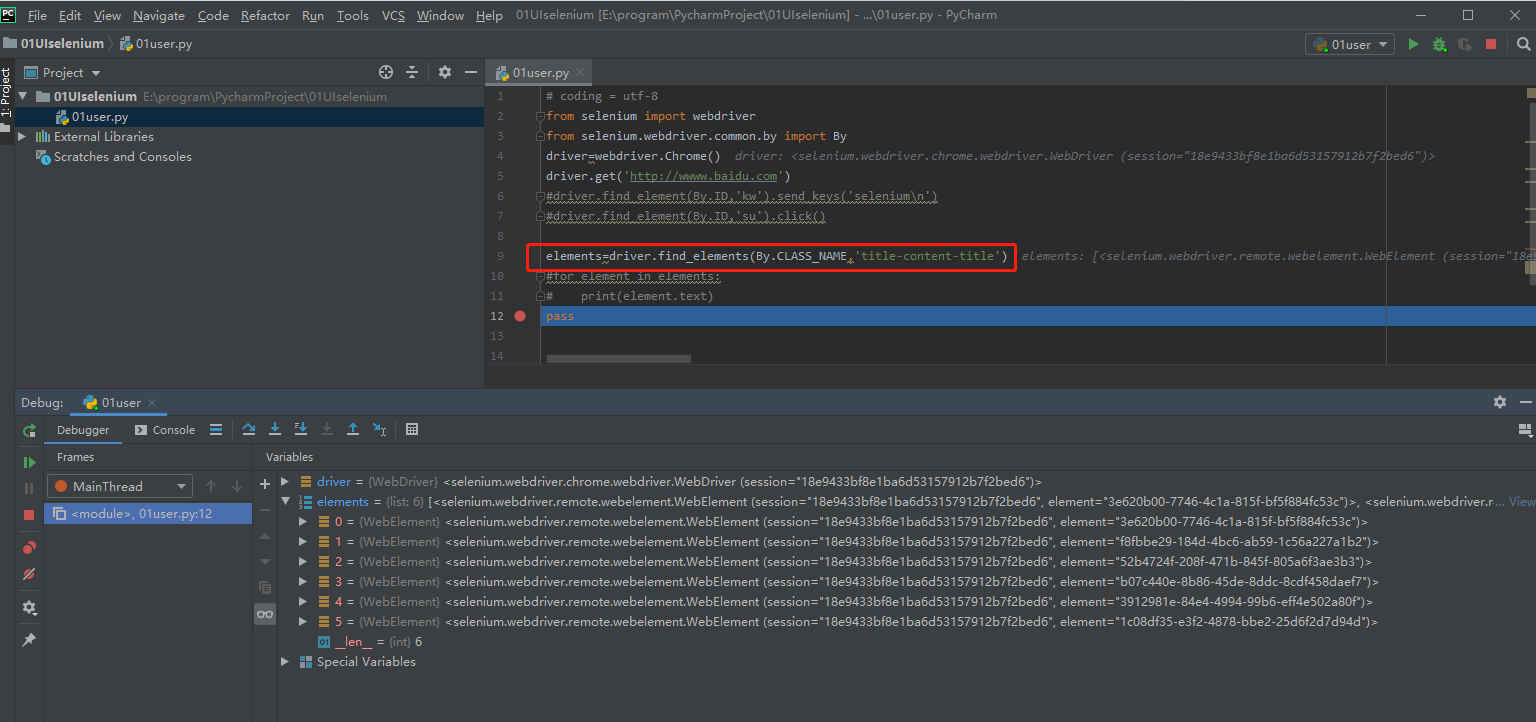
打印出text的内容
#for element in elements:
# print(element.text)

问题:find_elements得到的是一个列表,该怎么点击对应的列表呢?
belements.click()
AttributeError: 'list' object has no attribute 'click'
解决:点击对应的列表第几个,有两种方式
方法一:
belements=driver.find_elements(By.CLASS_NAME,'title-content-title')
belements[5].click()
方法二:
belements=driver.find_elements(By.CLASS_NAME,'title-content-title')[5]
belements.click()
https://wenku.baidu.com/view/8a355b0aa9ea998fcc22bcd126fff705cd175c40.html
思考:怎么实现循环点击一遍?
未解决
belements=driver.find_elements(By.CLASS_NAME,'title-content-title')
#belements[5].click()
for i in range(belements):
belements.click(i)
i+1
报错:得把列表个数用函数再转换一遍:https://www.runoob.com/python3/python3-list.html
for i in range(len(belements)):
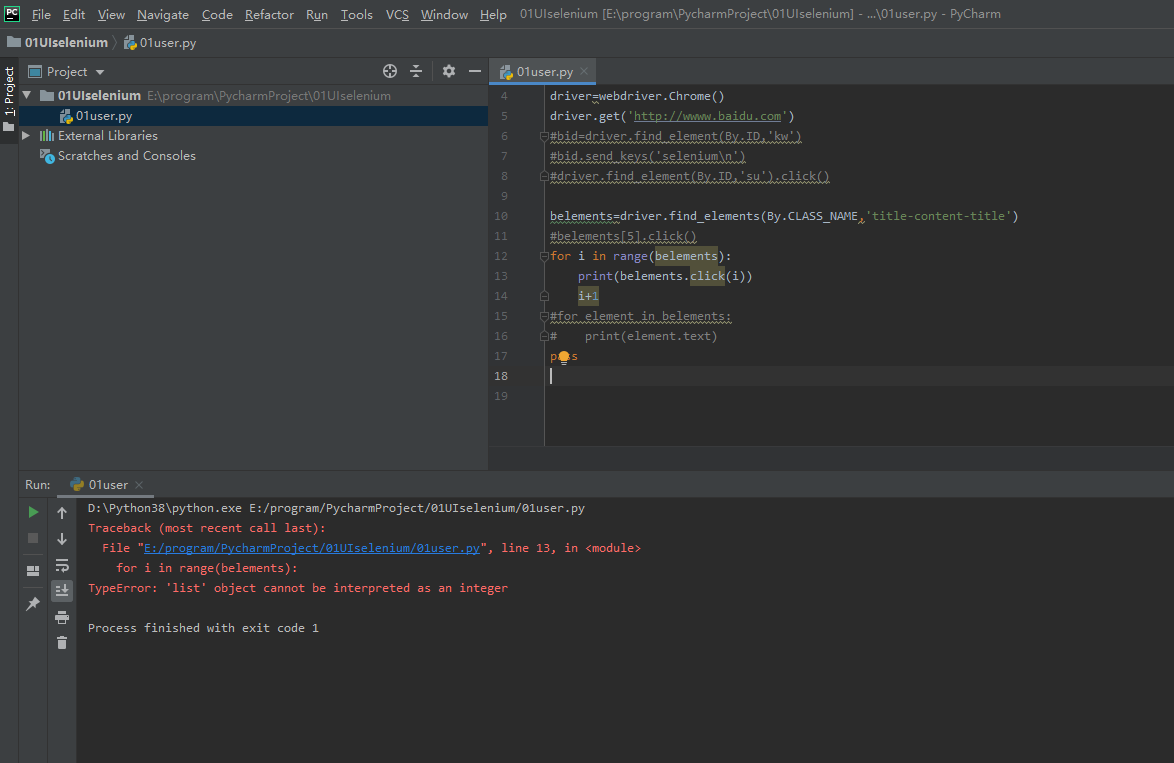
还有一个错误是
belements.click(i) 姐妹你脑袋糊了
最终:
# coding = utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('http://wwww.baidu.com')
#bid=driver.find_element(By.ID,'kw')
#bid.send_keys('selenium\n')
#driver.find_element(By.ID,'su').click()
belements=driver.find_elements(By.CLASS_NAME,'title-content-title')
#belements[5].click()
i=0
for i in range(len(belements)):
belements[i].click()
i+1
#for element in belements:
# print(element.text)
pass
3、xpath定位元素
//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号