kaldi学习资料
转载:https://blog.csdn.net/w_manhong/article/details/79977431
Dan povey 主页,有kaldi的详细入门文档,以及相关的论文
kaldi官网
kaldi—github
系统搭建过程及生成文件解释:
http://blog.sina.com.cn/s/blog_444061c70101hx7l.html
单音素训练:
https://blog.csdn.net/u010731824/article/details/69668765
https://blog.csdn.net/baidu_36137891/article/details/77849041
https://blog.csdn.net/fengzhou_/article/details/77996244
三音素训练:
https://blog.csdn.net/u010731824/article/details/70161677
决策树状态绑定:
https://blog.csdn.net/u010731824/article/details/69668647
一些查看输出文件命令(配置好PATH后,在s5demo下运行):
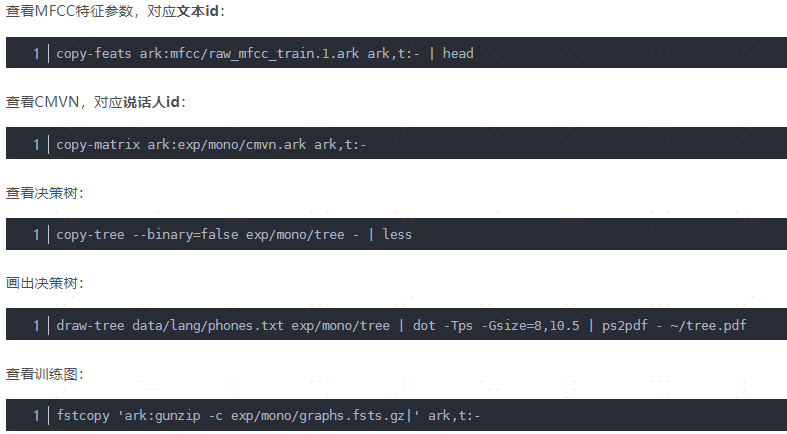
查看MFCC特征参数,对应文本id:
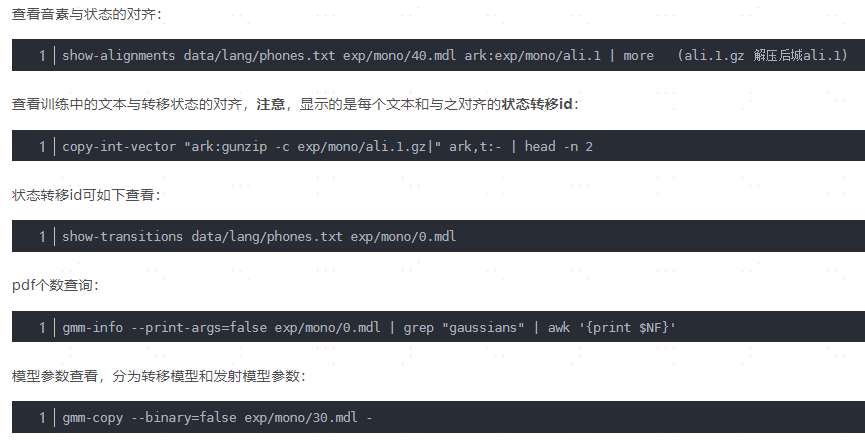
构造训练的fst网络,从源码级别分析,是每个句子构造一个phone level 的fst网络。这里采用预编译的原因是,可以尽量减少占用训练时间。 $data/text 中包含对每个句子的单词级别(words level)或音素级别(phone level)的标注,L.fst是词典的fst表示,作用是将一串的音素转换成单词。 构造monophone解码图就是先将text中的每个句子,生成一个fst(类似于语言模型中的G.fst,只是相对比较简单,只有一个句子), 然后和L.fst进行composition 形成训练用的音素级别(phone level)fst网络(类似于LG.fst)。 fsts.JOB.gz 中使用key-value 的方式保存每个句子和其对应的fst网络,通过 key(句子索引)就能找到这个句子的fst网络, value中保存的是句子中每两个音素之间互联的边(Arc),例如句子转换成音素后,标注为:“a b c d e f”, 那么value中保存的其实是 a->b b->c c->d d->e e->f这些连接(kaldi会为每种连接赋予一个唯一的id), 后面进行 HMM训练的时候是根据这些连接的id进行计数,进一步得到音素内(intra)状态的转移概率和音素间(inter)状态的转移概率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号