摘要:
GLIP-L 和 GLIP-T(C) 在 COCO 数据集上的 Zero-Shot 预测结果 GPU为Tesla P40 24G。 指标 GLIP-L GLIP-T(C) AP@[IoU=0.50:0.95] (所有区域的平均精度) 51.24%/61.7% 46.74%/55.1% AP@[IoU 阅读全文
posted @ 2025-01-03 13:20
陈用饼
阅读(563)
评论(0)
推荐(0)
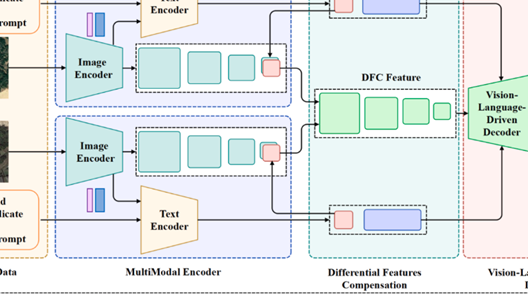 一、学习目标 学习 VLM 的基本原理和架构,理解视觉和语言信息的融合方式,掌握 VLM 的训练方式与评估方法。 学习 VLM 在遥感领域的应用(RemoteCLIP、ChangeCLIP),并尝试本地复现。 二、学习内容 文献 An Introduction to Vision-Language 阅读全文
一、学习目标 学习 VLM 的基本原理和架构,理解视觉和语言信息的融合方式,掌握 VLM 的训练方式与评估方法。 学习 VLM 在遥感领域的应用(RemoteCLIP、ChangeCLIP),并尝试本地复现。 二、学习内容 文献 An Introduction to Vision-Language 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号