寒假作业(2/2)——疫情统计
| 这个作业属于哪个课程 | 2020春丨W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2)——疫情统计 |
| 这个作业的目标 | 开发疫情统计程序,学习使用github,github desktop,IEAD,Jprofiler |
| 作业正文 | CY的寒假作业(2/2) |
| 其他参考文献 | CSDN、菜鸟教程、简书 |
一、Github仓库地址
作业的主仓库:https://github.com/numb-men/InfectStatistic-main
我的Github仓库地址:https://github.com/muxiao167/InfectStatistic-main
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 65 |
| Estimate | 估计这个任务需要多少时间 | 1590 | 1710 |
| Development | 开发 | 1170 | 1250 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 90 | 95 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 120 | 140 |
| Coding | 具体编码 | 600 | 630 |
| Code Review | 代码复审 | 60 | 65 |
| Test | 测试(自我测试,修改代码,提交修改) | 150 | 130 |
| Reporting | 报告 | 420 | 460 |
| Test Report | 测试报告 | 60 | 50 |
| Size Measurement | 计算工作量 | 60 | 50 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 300 | 360 |
| 合计 | 1650 |
三、解题思路描述
1、如何思考
在大致浏览过一遍题目后,首先先理清该程序设计前,我们已有的是哪些东西,所要得到的又是什么。
首先,日志文本:日志文件的命名,遵守对应的日期规范。而这特殊的日期命名规则,便是之后所需要读取信息的限制规则。而日志文件的内容保存着一些记录,那么这些记录,是需要我们从中进行提取信息的。
其次,命令:我们需要先理解该命令,到底是怎么回事。java InfectStatistic就是运行该文件,而后边便是它所使用的参数,这些会传递到main函数的String[] args中。那么接下来来分析参数。list便是命令的开头,必须拥有。-log,-out等等参数在作业中都有详细说明。
最后,输出文件(也就是我们所要得到的东西):输出文件中,需要列出全国和各省份的各类型患者人数,那这便需要对日志文本中各个信息进行提取并保存,最后对应的输出。而输出格式,输出省份,输出类型的顺序,都需要参考命令行参数,可在测试中逐渐修改。
那么,现在已经理清程序所要做的事情:
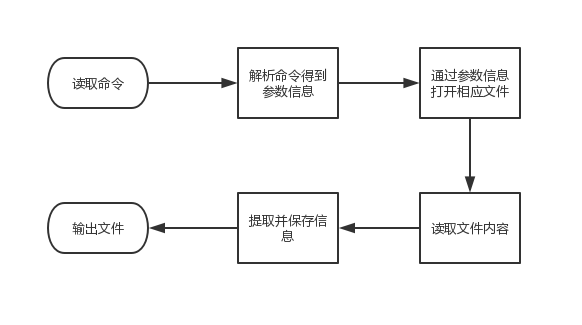
a.读取命令
b.解析命令得到其中的参数信息
c.通过参数信息打开相应文件
d.读取这些文件内容
e.提取并保存所要的信息
f.输出至输出文件。
2、如何找资料
在现如今,找资料最普遍的方法便是上网去搜索自己所需要的资料,我也不例外地采用该方式。当然从一开始便去找资料那是漫无目的的,于是我将作业中提供资料的链接,都大致了解一遍,都是些什么。再之后编写代码,使用github,单元测试等等过程中遇到问题,也就有了能够查找问题的位置。在这些资料中,有需要深究,但未给出解释的再自行去搜索。
四、设计实现过程
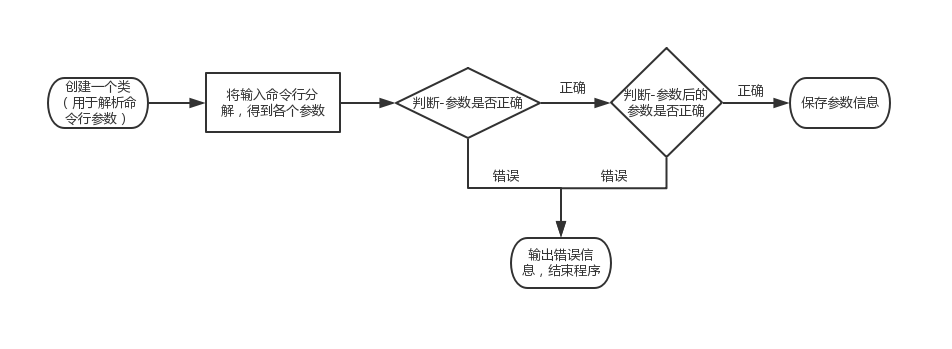
1、创建一个类,用于解析命令行参数
a.将输入的string[] args,分解为多个string,从中得到-参数以及之后的参数。
b.判断-参数是否为-log,-out,-date,-type,-province中的一个。
c.判断-参数后的参数是否符合要求。
d.以上判断出现错误,则输出错误信息,结束程序。若无误则保存参数信息。
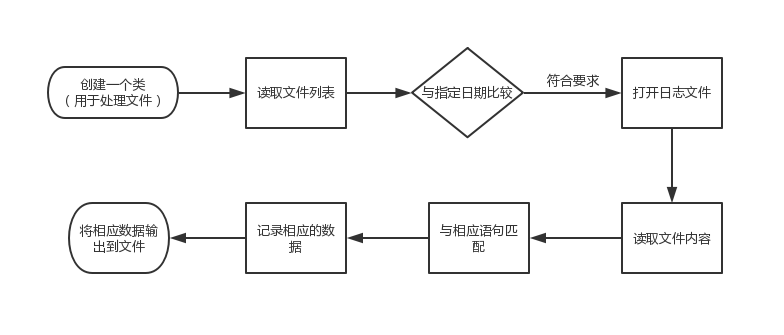
2、创建一个类,用于处理文件
a.读取日志文件目录路径下的文件列表
b.文件列表中的文件名与-date所指定的日期进行比较。
c.打开指定日期前的日志文件。
d.读取文件内容,并与相应语句匹配进行各种处理,从而记录相应的数据。
e.将相应数据输出到文件
五、代码说明
1、InfectStatistic类
a.属性:
String log_path; //日志文件位置
String out_path; //输出文件位置
-date不设置则默认为所提供日志最新的一天,所以先将保存指定日期的date设置为当前日期。
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");
Date d = new Date(System.currentTimeMillis());
public String date = formatter.format(d); //指定日期
-type不设置该项默认会列出所有情况,默认顺序为type_str属性中列举的顺序,所以将type属性中的值设置为如下。这是为了之后设置-type时,能够按照特定顺序输出。第一个输出的type值设置为1,以此类推。不输出则设置为0。
int[] type = {1,2,3,4}; //指定类型
public String[] type_str = {"感染患者", "疑似患者", "治愈", "死亡"}; //类型顺序列表(为给指定类型下标使用)
-province不设置该项会列出读取的日志文件中所提到的省份以及全国的信息。总数为35:全国+34个省份,默认顺序province_str属性中列举的顺序。将province[0]的值设置为-1,其余全设置为0,代表未设置-province参数。当指定省份时,将其数值设置为1时表示需要列出,而其余为0的表示无需列出。
int[] province; //指定省份
public String[] province_str = {"全国", "安徽", "澳门" ,"北京", "重庆", "福建","甘肃","广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江", "湖北", "湖南", "吉林","江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西", "陕西", "上海","四川", "台湾", "天津", "西藏", "香港", "新疆", "云南", "浙江"};
//省份顺序列表(为给指定省份下标使用)
保存各类型人数统计信息(一维代表省份排序,二维表示类型排序)顺序分别参照province_str和type_str。每个默认值都为0
public int[][] people = new int[35][4]; //人数统计
b.方法:
public static void main(String[] args); //程序入口
c.内部类:
class CmdArgs{}; //用于解析命令行参数
class FileHandle{}; //用于处理文件
2、CmdArgs类,用于解析命令行参数
a.属性:
String[] args; //保存传入的命令行
b.方法:
CmdArgs(String[] args_str); //构造函数,将命令行字符串数组传递进CmdArgs类
public boolean extractCmd(); //提取命令行中的参数
public boolean extractCmd() {
if(!args[0].equals("list")) {//判断命令格式开头是否正确
System.out.println("命令行格式有误——开头非list错误");
return false;
}
for(i = 1; i < args.length; i++) {
if(args[i].equals("-log")) { //读取到-log参数
i = getLogPath(++i);
if(i == -1) { //说明上述步骤中发现命令行出错
System.out.println("命令行格式有误——日志路径参数错误");
return false;
}
}
...其他参数同上
如果输出的不符合要求便return false;
}
return true;
}
public int getLogPath(int i); //得到日志文件位置
public int getLogPath(int i) {
if(i < args.length) { //当下标未越界
if(args[i].matches("^[A-z]:\\\\(.+?\\\\)*$")) //判断字符串是不是文件目录路径
log_path = args[i];
else
return -1;
} else
return -1;
return i;
}
public int getOutPath(int i); //得到输出文件位置
public int getOutPath(int i) {
if(i < args.length) { //当下标未越界
if(args[i].matches("^[A-z]:\\\\(\\S+)+(\\.txt)$")) //判断字符串是不是txt文件路径
out_path = args[i];
...
}
}
public int getDate(int i); //得到指定日期
public int getDate(int i) {
if(i < args.length) { //当下标未越界
if(isValidDate(args[i])) //判断是否是合法日期格式:yyyy-MM-dd
if(date.compareTo(args[i]) >= 0) //判断日期是否超过当前日期
date = args[i] + ".log.txt";
...
}
}
public static boolean isValidDate(String strDate); //判断是否是合法日期格式:yyyy-MM-dd
public boolean isValidDate(String strDate) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
try {
//设置lenient为false. 否则SimpleDateFormat会比较宽松地验证日期
//比如2018-02-29会被接受,并转换成2018-03-01
format.setLenient(false);
format.parse(strDate);
//判断传入的yyyy年-MM月-dd日 字符串是否为数字
String[] sArray = strDate.split("-");
for (String s : sArray) {
boolean isNum = s.matches("[0-9]+");
if (!isNum)
return false;
}
} catch (Exception e) {
return false;
}
return true;
}
public int getType(int i); //得到指定类型
public int getType(int i) {
int j, m = i;
if(i < args.length) { //当下标未越界
for(j = 0; j < 4; j++) //将默认指定全置为0
type[j] = 0;
j = 1; //j用来指定类型的顺序输出
while(i<args.length) {
if(args[i].equals("ip")) {
type[0] = j;
i++;
j++;
}
...其他参数同上
如果输出的不符合要求便return false;
}
}
if(m == i) //说明-type后无正确参数
return -1;
return (i - 1); //接下来不为-type的参数,或越界
}
public int getProvince(int i); //得到指定省份
public int getProvince(int i) {
int j, m = i;
if(i < args.length){
province[0] = 0; //取消未指定状态标记
while(i<args.length) {
for(j = 0; j < province_str.length; j++) {
if(args[i].equals(province_str[j])) { //如果参数找到对应省份
province[j] = 1; //指定该省份需要输出
i++;
break;
}
}
}
}
if(m == i) //说明-province后无正确参数
return -1;
return (i - 1); //接下来不为province的参数,或越界
}
3、FileHandle类,用于处理文件
a.属性:无
b.方法:
FileHandle(); //空构造函数
public void getFileList(); //读取指定路径下的文件名
public void getFileList() {
File file = new File(log_path);
File[] fileList = file.listFiles();
String fileName;
for (int i = 0; i < fileList.length; i++) {
fileName = fileList[i].getName();
if (fileName.compareTo(date) <= 0) { //如果该文件的日期小于指定日期
readTxt(log_path + fileName);
}
}
}
public void readTxt(String filePath); //读取文件内容
public void readTxt(String filePath) {
try {
BufferedReader bfr = new BufferedReader(new InputStreamReader(new FileInputStream(new File(filePath)),"UTF-8"));
String lineTxt = null;
while ((lineTxt = bfr.readLine()) != null) { //按行读取文本内容
if(!lineTxt.startsWith("//")) //遇到“//”不读取
textProcessing(lineTxt);
}
bfr.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public void textProcessing(String string); //文本处理
public void textProcessing(String string) {
String pattern1 = "(\\S+) 新增 感染患者 (\\d+)人";
String pattern2 = "(\\S+) 新增 疑似患者 (\\d+)人";
String pattern3 = "(\\S+) 治愈 (\\d+)人";
String pattern4 = "(\\S+) 死亡 (\\d+)人";
String pattern5 = "(\\S+) 感染患者 流入 (\\S+) (\\d+)人";
String pattern6 = "(\\S+) 疑似患者 流入 (\\S+) (\\d+)人";
String pattern7 = "(\\S+) 疑似患者 确诊感染 (\\d+)人";
String pattern8 = "(\\S+) 排除 疑似患者 (\\d+)人";
boolean isMatch1 = Pattern.matches(pattern1, string);
...其他参数类似
boolean isMatch8 = Pattern.matches(pattern8, string);
if(isMatch1) //新增 感染患者处理
addIP(string);
...其他参数同上
}
public void addIP(String string); //新增感染患者处理
public void addIP(String string) {
String[] str_arr = string.split(" "); //将字符串以空格分割为多个字符串
int i;
int n = Integer.valueOf(str_arr[3].replace("人", ""));//将人前的数字从字符串类型转化为int类型
for(i = 0; i < province_str.length; i++) {
if(str_arr[0].equals(province_str[i])) { //第一个字符串为省份
people[0][0] += n; //全国感染患者人数增加
people[i][0] += n; //该省份感染患者人数增加
if(province[0] == -1) //省份处于未指定状态
province[i] = 1; //需要将该省份列出
break;
}
}
}
以下函数的记录相应数据的方法与上述方法类似,便不一一列举。
public void addSP(String string);//新增疑似患者处理
public void addCure(String string);//新增治愈患者处理
public void addDead(String string);//新增死亡患者处理
public void flowIP(String string);//感染患者流入处理
public void flowSP(String string);//疑似患者流入处理
public void diagnosisSP(String string);//疑似患者确诊感染处理
public void removeSP(String string);//排除疑似患者处理
public void writeTxt(); //输出文件内容
public void writeTxt() {
FileWriter fwriter = null;
int i, j, k;
try {
fwriter = new FileWriter(out_path);
if(province[0] == -1) //省份处于未指定状态
province[0] = 1; //将全国以及省份改为指定状态(即列出日志文件中出现的省份)
for(i = 0; i < province_str.length; i++) { //遍历省份查找需要列出的省份
if(province[i] == 1) { //该省份需要列出
fwriter.write(province_str[i] + " ");
for(j = 0; j < type.length; j++) {
for(k = 0; k < type.length; k++) {
if(type[k] == j+1) { //即该省份需要列出且按照参数顺序
fwriter.write(type_str[k] + people[i][k] + "人 ");
break;
}
}
}
fwriter.write("\n");
}
}
fwriter.write("// 该文档并非真实数据,仅供测试使用");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fwriter.flush();
fwriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
六、单元测试截图和描述
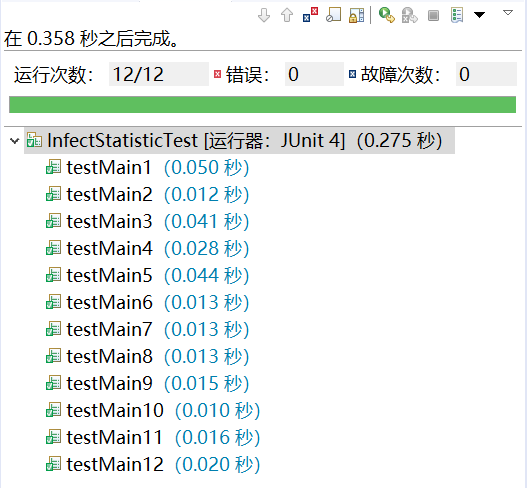
单元测试总时间(12个测试用例)
所用数据为example文件夹中所提供的log日志文件
1、单元测试1
该单元测试的-date参数采用日志文件最早的一天,未指定-type和-province参数。该日志文件中提到的省份只有福建和湖北,所以输出为全国和这两个省份的信息,并且患者类型按照默认排序全部输出。


2、单元测试2
该单元测试的-date参数采用比日志文件最早的一天更早的日期,未指定-type和-province参数。因为该日期前以及当天未有日志文件,所以所有的类型人数全为0人。而未有指定省份,便列出全国以及所有提到的省份,而因为没有日志文件,所以没有省份需要列出,只需要列出全国即可。


3、单元测试3
该单元测试的-date参数采用比日志文件最晚的一天更晚的日期,未指定-type和-province参数。所以读取所有的日志文件,这些日志文件中提到的省份有福建和湖北,所以输出为全国和这两个省份的信息,并且患者类型按照默认排序全部输出。


4、单元测试4
该单元测试的-province参数采用"全国","福建","湖北",未指定-type和-date参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以日志中全国和两个省份的信息都将被列出,并且患者类型按照默认排序全部输出。


5、单元测试5
该单元测试的-province参数采用"福建","河北",未指定-type和-date参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以两个省份的信息都将被列出,并且患者类型按照默认排序全部输出。


6、单元测试6
该单元测试的-province参数采用"河北","福建","全国",未指定-type和-date参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以全国和两个省份的信息都将被列出,而输入-province的参数并未按照顺序,输出还是按照全国和省份名称排序,并且患者类型按照默认排序全部输出。


7、单元测试7
该单元测试的-type参数采用"ip","sp","cure","dead",未指定-date和-province参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以全国和日志中提到的两个省份的信息都将被列出,并且患者类型按照参数顺序输出。


8、单元测试8
该单元测试的-type参数采用"sp","dead","ip","cure",未指定-date和-province参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以全国和日志中提到的两个省份的信息都将被列出,并且患者类型按照-type后所提供的参数顺序输出(即便它是混乱的)。


9、单元测试9
该单元测试的-type参数采用"dead","ip",未指定-date和-province参数。因为未设置-date参数,指定日期默认为当前日期,而当前日期比日志文件中每个文件都晚,所以全国和日志中提到的两个省份的信息都将被列出,并且患者类型按照-type后所提供的参数顺序输出(即便它是不按默认顺序的,不全都有的)。

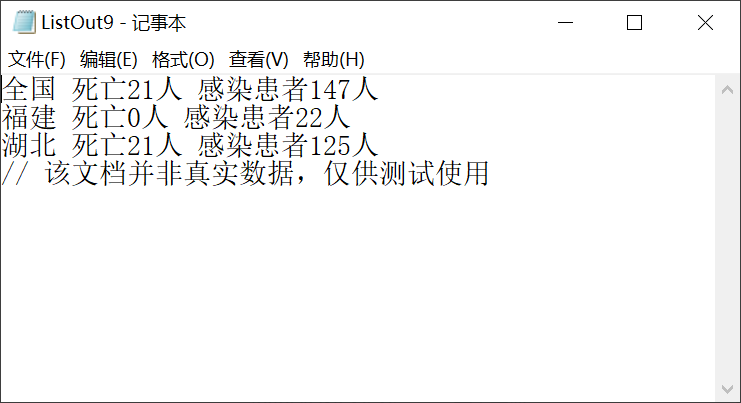
10、单元测试10
该单元测试的-date参数采用比日志文件最早的一天更早的日期,-type参数采用"cure","dead","ip",-province参数采用"全国","浙江","福建"。因为该日期前以及当天未有日志文件,所以所有的类型人数全为0人。因为-province后的参数,所以全国和浙江,福建两个省份的信息都将被列出,并且患者类型按照-type后所提供的参数顺序输出(即便它是不按默认顺序的,不全都有的)。


11、单元测试11
该单元测试的-date参数采用比日志文件最晚的一天,-type参数采用"sp","dead","ip",-province参数采用"浙江","全国","福建"。所以读取所有的日志文件,这些日志文件中提到的省份有福建和湖北,所有浙江的各类型人数为0。而输入-province的参数并未按照顺序,输出还是按照全国和省份名称排序,并且患者类型按照-type后所提供的参数顺序输出(即便它是不按默认顺序的,不全都有的)。


12、单元测试12
该单元测试的-date参数采用比日志文件最早的一天更早的日期,-type参数采用"sp",-province参数采用"湖北","全国"。所以读取所有的日志文件。而输入-province的参数并未按照顺序,输出还是按照全国和省份名称排序,并且患者类型按照-type后所提供的参数输出(即便它是不全都有的)。


七、单元测试覆盖率优化和性能测试
1、单元测试覆盖率
在覆盖率方面,其他没有覆盖到的部分是由于没有使用错误输入参数,也便不会覆盖到那部分的代码。其他正确性的代码基本可以通过单元测试覆盖到位。

2、性能测试

3、性能优化
关于性能优化,我有以下几点看法,但暂时未有较好办法解决:
a.在省份的查找对应关系上,循环使用过多,导致时间复杂度过高。
b.判断成分过多,导致许多不必要的过程
c.在正则表达式匹配中,使用的变量过多,导致匹配上需要花费许多时间。
八、代码规范的链接
代码规范链接:https://github.com/muxiao167/InfectStatistic-main/blob/master/221701116/codestyle.md
九、心路历程与收获
1、做好规划
在以往的学习中,编写一个程序时,也会大概地将需求分析做好,然后进行编写代码,到最后也能编写出一个有模有样的程序出来。但自从学习了《构建之法》,自己在本次作业中实际利用后,才发现过去的分析做的并不完整甚至还有错误。需求分析不仅仅是脑子中过一遍,最好的方法是将这些记录下来,甚至构造出一副流程图。在此之后,再进行设计分析,能够减少在编码中匆忙添加属性和方法的次数,这样也就少去修改已经写好了的方法,减少了许多不必要的工作量。
2、单元测试
在测试程序的过程中,以往使用的方法往往是,运行程序,按照程序流程一步步输入参数,之后查看结果,结果和自己所想结果一致,便说明这个测试完成,再进行下一个测试。而这样的方法明显比较花费时间,而单元测试上,减少了这方面的工作量,甚至提高了程序测试的效率。还能将单元测试自动化,这样每个人都能很容易地运行它,并且可以使单元测试每天都运行。
3、程序完成不代表着结束
当测试都能够成功结束后,我都会下意识认为这项任务我完成,便提交后,将之抛掷脑后。但现在我发现这并不是一个合格的程序员该做的。提交了被要求的程序,之后还有着很多需要再补充的事情。例如计算工作量,在这个程序上编写了多少代码,编写了多少单元测试,这些地方是否还有能够改进的地方。对这次程序编写一个总结,在之后能够用上的时候,再拿出来也能明白这是什么,甚至能够相应的做出改善。
4、自学
在本次的作业,需要学习github desktop,IDEA,Jprofiler的使用,这些软件都是之前未曾使用过的,并且使用过程还都是英文的选项。在学习使用的过程中,遇到了许多的困难。在一次次想要放弃使用,想要有人在旁指导的念头下,坚持下来,查找资料,解决问题,一步步向前,到现在能够基本使用。也许是过惯了在学校有老师教导的学习生活,然而这对于我们来说并不是有利的。在这个技术不断革新的时代,需要不断地学习才能跟上脚步。也正是这样才更需要自学,不断地去学习。过程中的困难,是前进的绊脚石,需要想办法解决它,而不是在它面前停滞不前。
十、技术路线图相关仓库
1、JavaGuide
链接:https://github.com/muxiao167/JavaGuide
简介:
本仓库存放 的文档倾向于提供一个比较详细的学习路径,让读者对于Java整体的知识体系有一个初步认识。另外,本文的一些文章也是学习和复习 Java 知识不错的实践。
2、Heart-First-JavaWeb
链接:https://github.com/muxiao167/Heart-First-JavaWeb
简介:
本仓库存放的是Java Web 入门开发教程。面向新手友好,容易上手。
3、JAVAWeb-Project
链接:https://github.com/muxiao167/JAVAWeb-Project
简介:
本仓库存放的是开始学习JAVA-WEB开发的一些练手项目,这些也适合初学者进行练习
4、javascript
链接:https://github.com/muxiao167/javascript
简介:
本仓库存放的是包含javascript的基础语法,面向对象的实现和设计模式实现
5、awesome-javascript-cn
链接:https://github.com/muxiao167/awesome-javascript-cn
简介:
本仓库存放的是JavaScript 资源大全中文版,内容包括:包管理器、加载器、测试框架、运行器、QA、MVC框架和库、模板引擎等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号