
mysql开窗函数
实验前测试数据
CREATE TABLE `test` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`type` int(0) NULL DEFAULT NULL,
`name` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`sale` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES (1, 1, 'aaa', 100);
INSERT INTO `test` VALUES (2, 1, 'bbb', 200);
INSERT INTO `test` VALUES (3, 1, 'ccc', 200);
INSERT INTO `test` VALUES (4, 1, 'ddd', 300);
INSERT INTO `test` VALUES (5, 2, 'eee', 400);
INSERT INTO `test` VALUES (6, 2, 'fff', 200);
-
mysql 开窗函数需要 mysql 8.0以后才能用
-
分组是组内数据统计合并成一行
-
开窗函数是在分区内,统计当前行和前后数据行的关系,不会合并成一行
-
-
开窗函数格式
开窗取值函数 over(partition by 分区字段 order by 排序字段 函数取值范围 ) -
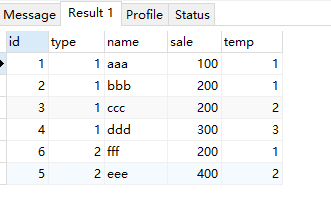
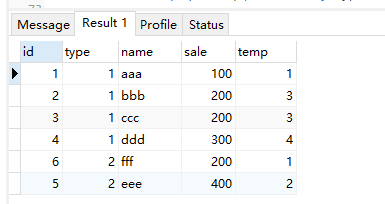
row_number() 区内生成唯一的编号
select *,row_number() over( partition by type order by sale ) as temp from test;
![image-20230324230844255]()
-
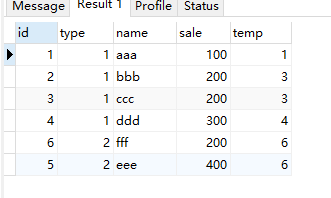
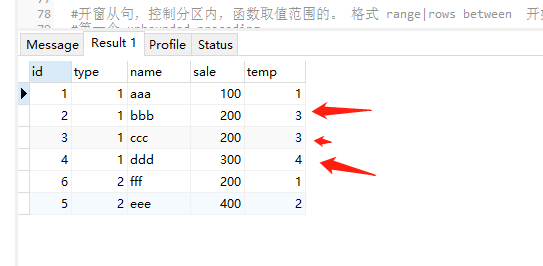
rank() 区内生成编号,分区字段值一样的生成一样的编号,并且编号不是连续的
select *,rank() over( partition by type order by sale ) as temp from test;
![image-20230324230508494]()
-
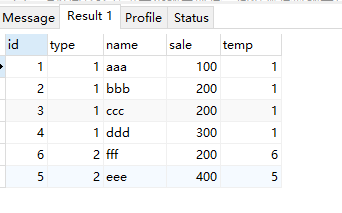
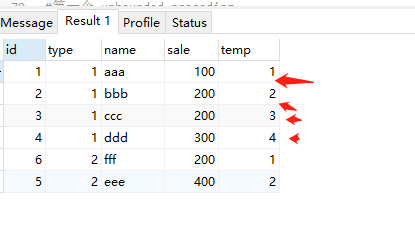
dense_rank() 区内生成不间断的编号,分区字段并且值一样的生成相同的编号
select *, dense_rank() over( partition by type order by sale ) as temp from test;![image-20230324230752429]()
-
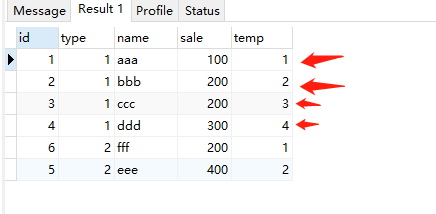
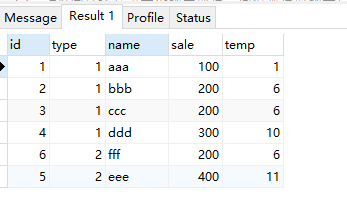
lead(fieldName,n,"默认值") 取后面的第几个字段。不带n默认是下一个,第一个字段可以是一个固定值
select *, lead(id) over( partition by type order by sale ) as temp from test;
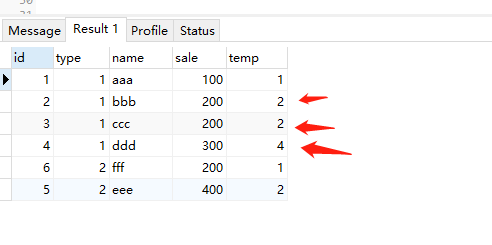
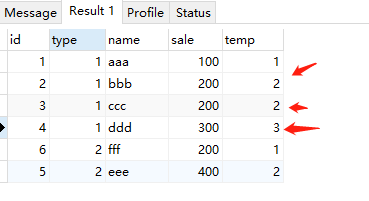
select *, lead(id,2) over( partition by type order by sale ) as temp from test;
select *, lead(id,2,"默认值") over( partition by type order by sale ) as temp from test;
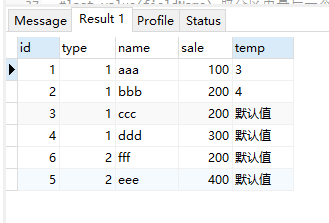
-
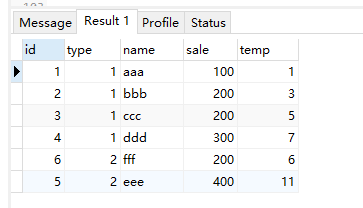
lag(fieldName,n,"默认值") 取前面的第几个字段。不带n默认是上一个,第一个字段可以是一个固定值
select *, lag(id) over( partition by type order by sale ) as temp from test;select *, lag(id,2) over( partition by type order by sale ) as temp from test;
select *, lag(id,2,"默认值") over( partition by type order by sale ) as temp from test;
![image-20230324230935981]()
-
first_value(fieldName),取分区内第一个值,这里需要注意这里的取值范围是 第一个到当前行(并且如果当前当前分区有多个值,会取到这个值的最后一行)
select *, first_value(id) over( partition by type order by sale ) as temp from test;
![image-20230324231003741]()
-
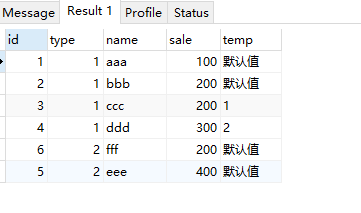
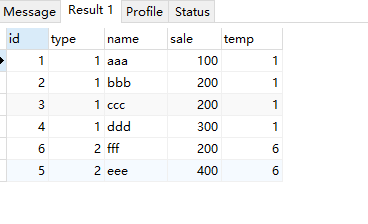
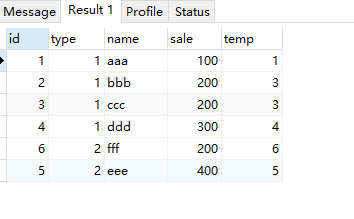
last_value(fieldName),取分区内最后一个值,这里需要注意这里的取值范围是 第一个到当前行(并且如果当前当前分区有多个值,会取到这个值的最后一行)
select *, last_value(id) over( partition by type order by sale ) as temp from test;
-
nth_value(id,2,"默认值"),取当前分区的第几行的值,取值范围默认是第一行到当前行(并且如果当前当前分区有多个值,会取到这个值的最后一行)
select *, nth_value(id,2) over( partition by type order by sale ) as temp from test;
![image-20230324231044901]()
-
ntile(n) 把分区内数据分成多少分,分不均的时候,会依次分给前面的
select *, ntile(3) over( partition by type order by sale ) as temp from test;
![image-20230324231104317]()
-
max(fieldName) 分区内取最大值,范围默认是第一个到当前行,同值那行取到最后一个
select *, max(id) over( partition by type order by sale ) as temp from test;
![image-20230324231137453]()
-
min(fieldName),最大值 ,范围默认是第一个到当前行,同值那行取到最后一个
select *, min(id) over( partition by type order by sale ) as temp from test;
![image-20230324231204517]()
-
avg,分区内取平均值,范围默认是第一个到当前行,同值那行取到最后一个
select *, avg(id) over( partition by type order by sale ) as temp from test;
![image-20230324231218245]()
-
sum,分区内求和,范围默认是第一个到当前行,同值那行取到最后一个
select *, sum(id) over( partition by type order by sale ) as temp from test;
![image-20230324231228845]()
-
count,分区内求数量,范围默认是第一个到当前行,同值那行取到最后一个
select *, count(id) over( partition by type order by sale ) as temp from test;
![image-20230324231243477]()
-
开窗从句默认是第一个到当前行,同值那行取到最后一个, 等价于 range between unbounded preceding and current row
select *, count(id) over( partition by type order by sale range between unbounded preceding and current row ) as temp from test;
![image-20230324231308976]()
-
row 和 range的不同在于处理相同值排序的时候 ,价格相同range取得最后一个id,rows取的当前那个id
select *, count(id) over( partition by type order by sale rows between unbounded preceding and current row ) as temp from test;
![image-20230324231326822]()
-
开窗从句,控制分区内,函数取值范围的。 格式 range|rows between 开始位置 and 结束位置
- 取第一个 unbounded preceding
- 取当前位置 current ROW
- 取最后一个 unbounded following
- 取当前位置前面n preceding
- 取当前位置后面第n following
- range|rows的区别在于排序后分区内重复值时,当前行的取值(current row),range取到分区内重复值最后一个,rows取当前行
-
开窗从句,取前一个到当前
select *, sum(id) over( partition by type order by sale rows between 1 preceding and current row ) as temp from test;
![image-20230324231421909]()
-
开窗从句,取前一个到最后
select *, sum(id) over( partition by type order by sale rows between 1 preceding and unbounded following ) as temp from test;
![image-20230324231431693]()
-
开窗从句,取当前到当前
select *, sum(id) over( partition by type order by sale rows between current ROW and current ROW ) as temp from test;
![image-20230324231443573]()
-
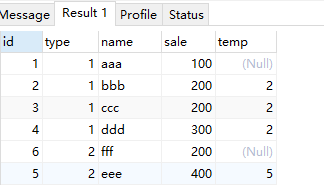
开窗从句,取全部
select *, sum(id) over( partition by type order by sale rows between unbounded preceding and unbounded following ) as temp from test;
![image-20230324231454205]()

能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2023-03-24 23:17 zhangyukun 阅读(314) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号