深度学习入门基于python的理论与实现-第四章神经网络的学习(个人向笔记)
从数据中学习
神经网络的"学习"的学习是指从训练数据自动获取最有权重参数的过程。
神经网络的特征就是可以从数据中学习即由数据自动决定权重参数的值。
机器学习通常是认为确定一些特征量,然后机器从特征量去学习,而神经网络则是将确定特征量这一步也交给机器
训练数据(Training Data)是用于训练机器学习模型的数据集。在监督学习中,训练数据通常包括输入数据(特征)和相应的标签(目标),模型通过观察这些数据并调整参数来学习输入与输出之间的关系。训练数据是模型学习的主要来源,其目标是使模型能够对新的、未见过的数据做出准确的预测或分类。
测试数据(Test Data)则是用于评估模型性能的数据集。与训练数据类似,测试数据也包括输入数据和相应的标签,但这些数据是模型在训练过程中未曾见过的。通过在测试数据上进行评估,可以更客观地评估模型的泛化能力,即模型对未知数据的适应能力。通常,测试数据用于评估模型在真实世界中的表现,并帮助确定模型是否能够泛化到新的数据。
泛化能力(Generalization)是指模型对未曾见过的数据的适应能力。一个具有良好泛化能力的模型能够在未见过的数据上表现良好,而不仅仅是在训练数据上表现好。通过在训练数据上调整参数,并在测试数据上进行评估,可以评估模型的泛化能力。泛化能力是机器学习中一个重要的性能指标,因为它决定了模型在实际应用中的效果。
监督数据(Supervised Data)是一种标记数据,包含了输入数据和相应的标签或输出。在监督学习中,监督数据用于训练模型,模型通过观察输入数据与标签之间的关系来学习。监督学习包括分类和回归等任务,其中分类任务的标签是离散的,而回归任务的标签是连续的。监督数据是训练和评估监督学习模型的基础,因为模型需要通过观察这些数据来学习输入和输出之间的映射关系
过拟合(Overfitting)是指机器学习模型在训练数据上表现得过于优秀,以至于在未见过的测试数据上表现不佳的现象。当模型过于复杂或过度拟合训练数据时,它可能会学习到训练数据中的噪声或不相关的特征,导致在新数据上的泛化能力下降。
损失函数
神经网络的学习是通过某个指标来表现现在的状态,以这个指标维基准,寻找最有权重参数.这个指标就被称为损失函数
损失函数(Loss Function)是用来衡量模型预测结果与实际标签之间的差异的函数。在监督学习中,损失函数通常是一个标量值,它描述了模型在给定输入数据的情况下预测值与真实标签之间的差异程度。
常见的损失函数
均方误差(Mean Squared Error,MSE): 常用于回归问题,计算模型预测值与实际标签之间的平方差的平均值。
交叉熵损失(Cross-Entropy Loss): 用于分类问题,包括二分类和多分类。在二分类问题中,交叉熵损失通常表示为对数损失(Log Loss),衡量模型预测结果与真实标签之间的差异。
对数似然损失(Log-Likelihood Loss): 通常用于分类问题,特别是在逻辑回归模型中。它是对数似然函数的负数,用来最大化模型对训练数据的似然性。
Hinge Loss: 主要用于支持向量机(SVM)和最大间隔分类器(Max-Margin Classifier)等模型,用来最小化分类错误和边界违规的损失。
Huber Loss: 是一种平滑的损失函数,结合了均方误差和绝对误差,对异常值的敏感性较小。
自定义损失函数: 根据特定问题的需求,有时也会设计自定义的损失函数。
一般使用均方误差和交叉熵误差(我还没入门这句话是抄的,一般使用什么我也不太清楚qwq)
均方误差(MSE)
这里的\(y_k\)表示神经网络的输出,\(t_k\)表示监督数据,k表示的是数据的维数
one_hot表示
独热编码(One-Hot Encoding)是一种常用的分类变量编码方法,用于将分类变量转换为机器学习模型可以处理的格式。在独热编码中,每个分类变量都被转换成一个二进制向量,其中只有一个元素是1,其他元素都是0。这个1表示了变量所属的类别。
举例来说,假设有一个包含三个类别的分类变量:红色、蓝色和绿色。对这个分类变量进行独热编码后,可以得到以下编码:
红色:\([1, 0, 0]\)
蓝色 \([0, 1, 0]\)
绿色:\([0, 0, 1]\)
这样,每个类别都被转换成了一个包含三个元素的二进制向量,其中只有一个元素是1,其他元素都是0。
独热编码的优点包括:
适用于分类变量: 独热编码可以将分类变量转换为机器学习模型可以处理的格式,使得模型能够更好地理解和利用这些变量。
避免大小关系的影响: 独热编码将每个类别都表示为一个二进制向量,避免了类别之间的大小关系对模型造成的影响。(当我们使用独热编码时,我们将每个类别都表示为一个二进制向量,其中只有一个元素是1,而其他元素都是0。这意味着在独热编码中,类别之间的距离是相等的,不受类别本身的取值大小影响。)
保留了类别信息: 独热编码在转换过程中保留了类别信息,使得模型能够更好地理解每个类别之间的关系。
数学性质: 独热编码的结果是一组正交向量,具有良好的数学性质,可以方便地用于模型的计算和优化。
总的来说,独热编码是一种常用且有效的分类变量编码方法,适用于许多机器学习任务中。
import numpy as np
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t) ** 2)
# t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
# print(mean_squared_error(np.array(y),np.array(t)))
这里假设2是正确解

当2的概率最高为0.6时,mse如下


当最高概率0.6为7时,mse如下
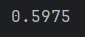
可以看出,MSE越小,表示模型的预测结果与真实值之间的差异越小,模型的拟合效果越好。
优点:它是一个连续可导的凸函数,方便进行梯度下降等优化算法的求解。
它对预测值和真实值之间的差异进行了平方运算,更加关注大误差的样本,因此对离群值更为敏感。
缺点:然而,MSE也有一些缺点,主要是它对离群值敏感,因为它会将大误差的样本的平方差放大,从而影响整体的损失函数。因此,在某些情况下,可能需要考虑其他更适合的损失函数。
交叉熵误差
交叉熵误差也常被用作损失函数
import numpy as np
def cross_entroy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
# delta加入时为了防止log中出现0的不合法情况
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(cross_entroy_error(np.array(y), np.array(t)))
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(cross_entroy_error(np.array(y), np.array(t)))
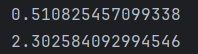
如果模型的预测结果与真实标签一致,交叉熵损失就会越接近0;而如果模型的预测结果与真实标签相差越大,交叉熵损失就会越大。
mini_batch学习
Mini-batch是在训练神经网络时使用的一种技术,它将训练数据分成小批量(mini-batches),每个小批量包含一定数量的样本。相比于将整个训练数据集一次性输入到神经网络中进行训练(称为批量训练).
随机选择一个\(mini_batch\)的数据
# coding: utf-8
import pickle
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
from caicaicai.dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
print(x_train.shape)
print(t_train.shape)
# 从训练数据中随机抽取10笔数据
train_size = x_train.shape[0]
batch_size = 10
# np.random.choice会从指定的数字中随机选择想要个数字,我们这里时从60000个数字中随机选择10个数字
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
mini_batch版交叉熵误差的实现
import numpy as np
def cross_entroy_error(y, t):
# 当只有单个数据时,需要该表数据的形状
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
# 当标签形式为非ont-hot时,的处理情况
# return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
梯度
概念
多元函数的所有偏导数
import numpy as np
# 计算梯度
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# 计算 f(x + h)
x[idx] = tmp_val + h
fxh1 = f(x)
# 计算 f(x - h)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val
return grad
# def f2(x):
# return x[0] ** 2 + x[1] ** 2
#
#
# print(numerical_gradient(f2, np.array([3.0, 4.0])))
# print(numerical_gradient(f2, np.array([0.0, 2.0])))
# print(numerical_gradient(f2, np.array([3.0, 0.0])))
梯度法
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度的方向前进,如此反复,不断延梯度方向前进,进而不断减小函数值的过程就是梯度法.
梯度下降法和梯度上升法是优化算法中常用的两种方法,它们分别用于寻找函数的局部最小值或全局最小值,以及局部最大值或全局最大值。这两种方法的核心思想都是沿着函数的梯度方向进行迭代更新,以逐步接近目标值点。
具体来说,梯度下降法是通过沿着函数梯度的负方向进行迭代更新,以逐步接近最小值点。在每一次迭代中,根据当前位置的梯度方向来更新参数或变量值,使目标函数值减小。梯度下降法广泛应用于求解机器学习中的优化问题,如线性回归、逻辑回归、神经网络等。
相反,梯度上升法则是通过沿着函数梯度的正方向进行迭代更新,以逐步接近最大值点。这种方法适用于求解优化问题中的约束最优化、最大似然估计等。
用数学形式表示梯度法:
其中\(\eta\)表示更新量,再神经网络的学习中,被称为学习率learning rate
学习率
较小的学习率会使参数更新的步长较小,导致收敛速度较慢,但可能会使模型更容易达到局部最优解。较大的学习率会使参数更新的步长较大,导致收敛速度较快,但可能会导致模型在参数空间中振荡或不稳定。
\(当lr=0.01时\)
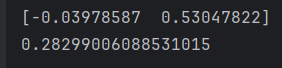
\(当lr=10时\)

\(当lr=1e10时\)
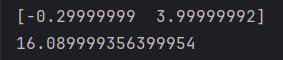
import numpy as np
from caicaicai.ch04.numerical_gradient import numerical_gradient
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
def f_2(x):
return x[0] ** 2 + x[1] ** 2
init_x = np.array([-0.3, 4.0])
y = gradient_descent(f_2, init_x=init_x, lr=0.01, step_num=100)
print(y)
print(f_2(y))
超参数
超参数是在机器学习算法中,开始学习过程之前需要设定的参数,而不是通过训练过程得到的参数数据。它们通常用于控制模型的行为和性能,并且需要根据经验或领域知识进行调整。超参数的选择对模型的训练速度、收敛性、容量以及泛化能力等方面都有显著影响。
常见的超参数包括学习率、迭代次数(epoch)、正则化参数、隐藏层的神经元数量、批量大小(batch-size)等。例如,在k近邻法(kNN)中,k(最相近的点的个数)是一个超参数;在决策树模型中,树的深度是一个超参数。这些超参数的值不能从数据中估计,需要手动设置。
超参数的调整通常是一个试错的过程,可以通过网格搜索、随机搜索、贝叶斯优化等方法进行。为了找到最优的超参数组合,往往需要进行多次实验和验证。
在深度学习中,超参数的选择尤为重要,因为它们直接影响到神经网络的架构和训练过程。合理地设置超参数可以帮助模型更好地学习和泛化,从而提高预测精度和性能。
总之,超参数是机器学习模型中的重要组成部分,需要仔细选择和调整,以优化模型的性能和效果。
神经网络的梯度
神经网络的学习就是不断对权重进行优化,使损失函数值最小化
所以神经网络的梯度就是损失函数关于权重的导数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号