神经网络分类知识蒸馏
参考链接:
知识蒸馏是什么?一份入门随笔
https://zhuanlan.zhihu.com/p/90049906
[论文阅读]知识蒸馏(Distilling the Knowledge in a Neural Network)
https://blog.csdn.net/ZY_miao/article/details/110182948
Distilling the Knowledge in a Neural Network[论文阅读笔记]
https://blog.csdn.net/qq_22749699/article/details/79460817
github参考代码(mxnet)
https://github.com/TuSimple/neuron-selectivity-transfer
基础知识:
蒸馏是将大型模型训练得到的已知公式能力,教给小模型,使小模型学习到近似的公式能力,同时拥有较低的预测时延。这种操作,往往比从头开始训练小模型,得到的准确度要更高。
大模型:教师模型
小模型:学生模型
正常小模型训练label:例如4分类种族Asian=0,lable使用onehot编码,[0, 0, 1, 0]
大模型预测输出:4分类种族大模型预测输出,[-0.5620071291923523, -0.5602135062217712, 1.7244330644607544, -0.5817564129829407]
蒸馏:大模型的预测输出,带着比原始label更多的预测信息,将小模型的label换成大模型的预测输出,能使小模型快速学习到大模型的能力
蒸馏示意图:
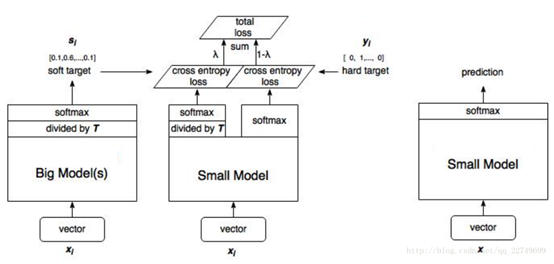
1) 大模型预测输出fc1_output,除以蒸馏温度T,在softmax转换输出,得到大模型软一点的teacher_soft_labels
2) 小模型预测输出fc1_output,除以蒸馏温度T,在softmax转换输出,得到大模型软一点的student_soft_labels
3) 将student_soft_logits和teacher_soft_labels交叉熵输出,同时乘以蒸馏权重
4) 小模型预测输出fc1_output,softmax转换输出,与真实label进行交叉熵输出,同时乘以1-蒸馏权重
5) 3和4结果相加组成总的损失
6)训练完成,输出结果预测模型,则取消掉蒸馏的过程,直接softmax层输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号