数据采集第四次大作业
作业四
作业1
1.1内容
- 要求
熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据。 - 候选网站
http://www.dangdang.com/ - 关键词:python
- 输出信息
MySQL数据库存储和输出格式如下:

1.2代码&结果
- 图书信息解析
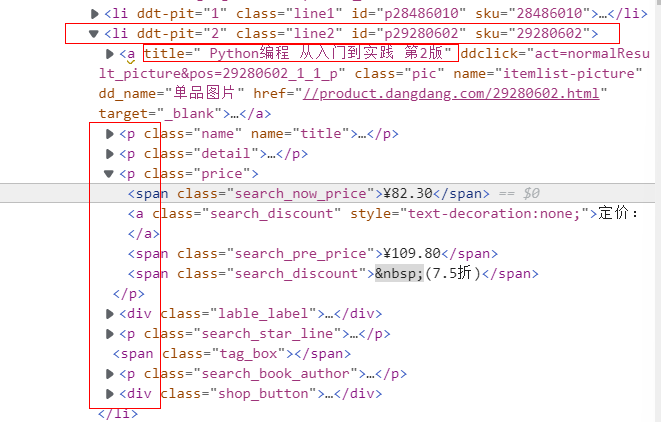
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") # 每一页的图书列表
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first() # 书名
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() # 价格
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() # 作者
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first() # 日期
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first() # 出版社
detail = li.xpath("./p[@class='detail']/text()").extract_first() # 详情
- 翻页处理
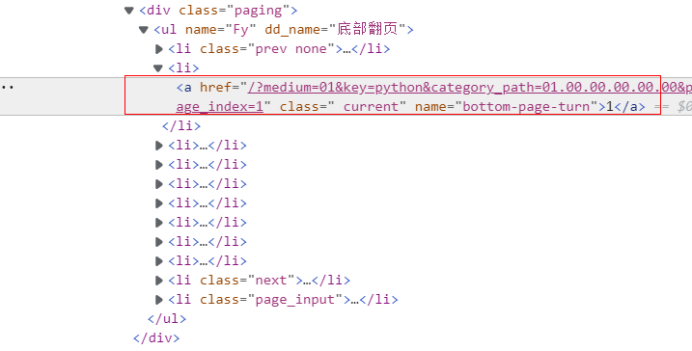
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link: # 最后一页时link为None
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse) # 继续爬取下一页
- items.py
class BookItem(scrapy.Item):
title = scrapy.Field() # 序号
author = scrapy.Field() # 书名
date = scrapy.Field() # 日期
publisher = scrapy.Field() # 出版社
detail = scrapy.Field() # 具体情况
price = scrapy.Field() # 价格
- settings.py
# 解除限制
ROBOTSTXT_OBEY = False
# 数据库信息
HOST = '127.0.0.1'
PORT = 3306
DATABASE = 'mydb'
USER = 'root'
PASSWORD = '123456'
DEFAULT_REQUEST_HEADERS = { # 设置请求头
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
ITEM_PIPELINES = { # 打开pipelines
'exe4_1.pipelines.BookPipeline': 300,
}
- pipelines.py
-
- open_spider函数链接数据库
# 从settings读取数据库信息
settings = get_project_settings()
host = settings["HOST"]
port = settings["PORT"]
user = settings["USER"]
database = settings["DATABASE"]
password = settings["PASSWORD"]
# 连接数据库
self.con = pymysql.connect(host=host, port=port, user=user,passwd=password, db=database, charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
-
- process_item函数插入数据库
self.cursor.execute("insert into books (id, bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) "
"values(%s,%s,%s,%s,%s,%s,%s)", (self.count+1, item["title"], item["author"],
item["publisher"],item["date"], item["price"], item["detail"]))
-
- close_spider函数关闭与数据库连接
if self.opened: # 关闭数据库连接
self.con.commit()
self.con.close()
self.opened = False
print("closed")
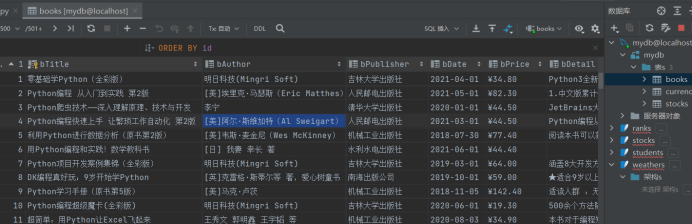
- 结果

1.3心得
- 本题为复现题,没有遇到太多困难。巩固了scrapy框架下的数据爬取,学习使用了mysql数据库的存取,与sqlite3只有些许连接上的不同。
1.4代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验4/作业1
作业2
2.1内容
- 要求
熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。 - 候选网站
招商银行网:http://fx.cmbchina.com/hq/ - 输出信息
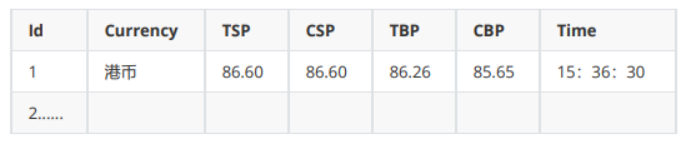
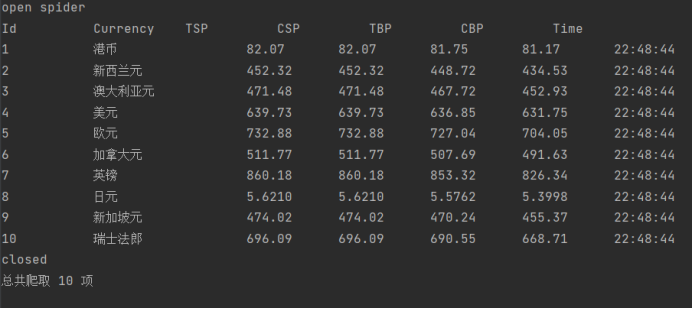
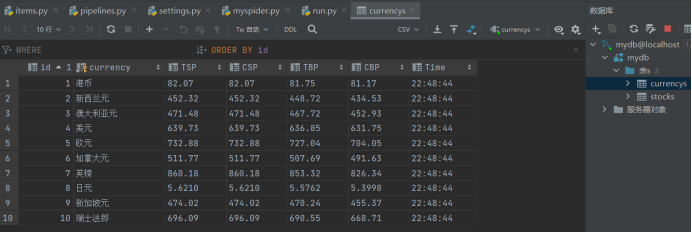
MySQL数据库存储和输出格式如下:
2.2代码&结果
- 货币信息解析
trs = selector.xpath("//div[@id='realRateInfo']//tr") # 货币列表
for i in range(1, len(trs)):
currency = trs[i].xpath("./td[@class='fontbold']/text()").extract_first() # 货币名
td1 = trs[i].xpath("./td[@align='center']/text()").extract() # 各货币下的第一类td节点列表
td2 = trs[i].xpath("./td[@class='numberright']/text()").extract() # 各货币下的第二类td节点列表
currency = currency.strip() # 处理货币名,去除不必要字符
c_time = td1[2].strip().strip("\n") # Time
tsp = td2[0].strip().strip("\n") # TSP
csp = td2[1].strip().strip("\n") # CSP
tbp = td2[2].strip().strip("\n") # TBP
cbp = td2[3].strip().strip("\n") # CBP
- items.py
class CurrencyItem(scrapy.Item):
currency = scrapy.Field() # 货币名
tsp = scrapy.Field() # TSP
csp = scrapy.Field() # CSP
tbp = scrapy.Field() # TBP
cbp = scrapy.Field() # CBP
c_time = scrapy.Field() # Time
- settings.py和pipelines.py
与作业1相似,不再重复
- 结果
2.3心得
- 本题不涉及翻页,只有货币信息的提取,较易完成,只是需要注意提取信息时有的需要做多余字符的去除,再次巩固练习了scrapy框架下的爬取和mysql数据库的存储。
2.4代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验4/作业2
作业3
3.1内容
- 要求
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。 - 候选网站
东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board - 输出信息
MySQL数据库存储和输出格式如下:
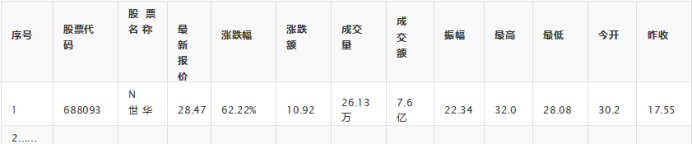
3.2代码&结果
- 股票信息提取
trs = self.driver.find_elements(By.XPATH, "//div[@class='listview full']//tbody/tr") # 股票信息列表
for i in range(len(trs)):
tds = trs[i].find_elements(By.XPATH, "./td")
no = tds[1].text # 股票代码
name = tds[2].find_elements(By.XPATH, "./a")[0].text # 股票名称
newPrice = tds[4].find_elements(By.XPATH, "./span")[0].text # 最新报价
change = tds[5].find_elements(By.XPATH, "./span")[0].text # 涨跌幅
changePrice = tds[6].find_elements(By.XPATH, "./span")[0].text # 涨跌额
turnover = tds[7].text # 成交量
turnoverPrice = tds[8].text # 成交额
amp = tds[9].text # 振幅
max = tds[10].find_elements(By.XPATH, "./span")[0].text # 最高
min = tds[11].find_elements(By.XPATH, "./span")[0].text # 最低
today = tds[12].find_elements(By.XPATH, "./span")[0].text # 今开
yesterday = tds[13].text # 昨收
- 翻页处理
if self.page == 1: # 如果为某个板块的第一页,则继续爬取此板块的下一页
# 寻找页面的翻页按钮
pages = self.driver.find_elements(By.XPATH, "//div[@class='dataTables_wrapper']//span[@class='paginate_page']/a")
pages[1].click()
self.page += 1 # 记录翻页
self.processSpider() # 开始下一页的爬取
- 股票板块切换

self.page = 1 # 新板块的第一页
self.board_no += 1 # 记录爬取的新板块号
if self.board_no <= 3: # 不超过预计爬取的板块
lis = self.driver.find_elements(By.XPATH, "//div[@id='tab'][@class='tab-nav tab-head row']//li")
a = lis[self.board_no - 1].find_elements(By.XPATH, "a")
self.driver.execute_script("arguments[0].scrollIntoView(false);", a[0]) # 使切换板块按钮在视口,能被点击
time.sleep(1) # 等待出现在视口
a[0].click()
self.processSpider() # 开始下一个板块的爬取
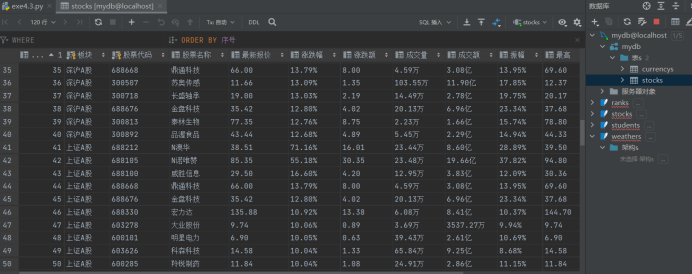
- 结果

3.3心得
- selenium爬取时要注意使用time.sleep,等待页面响应后再进行信息爬取。
- 对于页面切换,常会发现一些按钮不在视口,所以要进行“driver.execute_script("arguments[0].scrollIntoView(false);", button)”的处理,才能顺利点击。
3.4代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验4/作业3
- 031904132 陈晓淇
