
回归问题及正则化
1.线性回归模型及求解方法
什么是回归?

X的行表示每个样本,列表示每个特征。
研究X和Y之间关系的统计分析方法称之为回归。其中X是自变量,Y是因变量。
利用训练数据,使用回归模型(如线性模型)去拟合变量之间的关系。因此训练任务就是利用数据,来学习模型中的参数 parameter(如线性模型中的斜率和截距)。
回归和分类的区别和联系
-
区别:
分类:使用训练集推断输入x所对应的离散类别(如:+1,-1)。
回归:使用训练集推断输入x所对应的输出值,为连续实数。
-
联系:
利用回归模型进行分类:可将回归模型的输出离散化以进行分类,即y= sign(f(x))。
利用分类模型进行回归:也可利用分类模型的特点,输出其连续化的数值。
线性模型

非线性模型

线性回归
线性回归模型中,假设自变量和因变量满足如下形式:
问题:已知一些数据,如何求里面的未知参数,给出一个最优解。因此通常将参数求解问题转化为求最小误差问题。
一般采用模型预测结果与真实结果的差的平方和作为损失函数:

概率解释(为什么采用差的平方和作为误差函数):

求解参数(就是求解使得上式最小的参数θ)
-
矩阵解法:scikit-learn中的 Linear Regression类使用的是矩阵解法(有时也称为最小二乘法)。可以解出线性回归系数θ

-
梯度下降法:梯度下降( Gradient descent)是利用一阶的梯度信息找到函数局部最优解的一种方法。
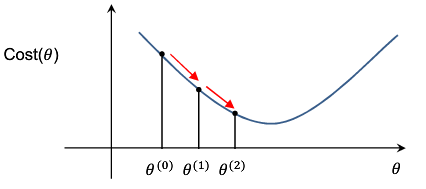
其基本思想是,要找代价函数最小值,只需要每一步都往下走,也就是每一步都可以让误差损失函数小一点。
对于线性回归,参数的更新方法一般为(其中L为超参数,学习速率,即每一步走多远)![]()

如何求梯度?
 (倒数第二步,只有k=j时才存在偏导)
(倒数第二步,只有k=j时才存在偏导)先初始化一组θ,在这个θ值之上,用梯度下降法去求出下一组θ的值。当迭代到一定程度,J(θ)的值趋于稳定,此时的θ即为要求得的值。
2.多元回归与多项式回归
sklearn的一元线性回归
在sklearn中,所有的估计器都带有fit0和 predict0方法。
fit()用来拟合模型(将输入数据输入给模型,训练得到参数), predict()利用拟合出来的模型对样本进行预测。
实例:用sklearn来构建一元线性回归预测披萨价格
1 from sklearn.linear_model import LinearRegression 2 X=[[6],[8],[10],[14],[18]] 3 y=[[7],[9],[13],[17.5],[18]] 4 model=LinearRegression() 5 model.fit(X, y) 6 print('预测12英寸披萨价格:$%.2f'%model.predict([12])[0])
输出结果:预测12英寸披萨价格:$13.68
线性回归的参数
对于刚才的例子,Linear Regression类的fit()方法学习线性回归模型y=w0+w1x
线性回归模型学习到的参数是截距和权重系数。下图中的直线就是匹萨直与价格的线性关系。

残差(residual)
估计值(拟合值)与实际观察值之间的差

多元线性回归
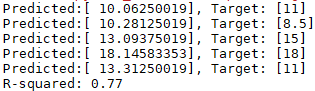
from sklearn.linear_model import LinearRegression X=[[6,2],[8,1],[10,0],[14,2],[18,0]] y=[[7],[9],[13],[17.5],[18]] model=LinearRegression() model.fit(X, y)
X_test=[[8,2],[9,0],[11,2],[16,2],[12,0]] y_test=[[11],[8.5],[15],[18],[11]] predictions=model.predict(X_test) for i, prediction in enumerate(predictions): print('Predicted:%s, Target: %s'%(prediction,y_test[i])) print('R-squared: %.2f'%model.score(X_test,y_test))
R方
可以用于评估回归模型对现实数据拟合的程度。
计算步骤:

多项式回归
用适当幂次的多项式来近似反应因变量与自变量之间的关系。
多项式模型:![]()

多项式回归的步骤:

二次回归指多项式的最高次为2次。


3.损失函数的正则化(可以有效解决过拟合问题)
向量范数

矩阵范数

线性回归的正则化
应对过拟合 (Overfitting)。因为在某些情况下,学习得到的模型在训练集上也许误差较小,但是对于测试集中之前未见样本的预测却未必有效。为此可以在损失函数中加入正则化项。
以线性回归为例:

其中α是正则化参数( regularization parameter),用于控制两个不同的目标的平衡。
- 第一个目标是使假设更好地拟合训练数据。
- 第二个目标是要正则化处理,使得模型不要太复杂。
线性回归正则化后的梯度更新方法:

为什么回归要正则化?
实例:使用一个2次函数加上随机的扰动来生成500个点,然后尝试用1,2,100次方的多项式对该数据进行拟合。

拟合的性能:一次方:R2=0.82
二次方:R2=0.88
100次方:R2=0.89
下面从500个样本中去掉2个,而在测试时使用所有的500个样本。
多项式拟合结果:一次方:R2=0.85
二次方:R2=0.90
100次方:R2=0.57
结果表明,高次多项式过度拟合了训练数据。
通过查看,会发现100次多项式拟合出的系数数值通常很大。因此在拟合过程中可以限制这些系数数值的大小来避免生成畸形的拟合函数。
具体做法就是在损失函数中加入正则化项,以抑制这些系数的数值。
- 如: Lasso回归(使用L1正则化)
- 岭( Ridge)回归(使用L2正则化)
- 弹性网( Elastic net,使用L1+12正则化)等回归
通过岭回归,拟合结果为:一次方:R2=0.78
二次方:R2=0.87
100次方:R2=0.90
岭回归中正则权重的作用

alpha值越大(即越偏左),weights(即回归权重参数)变得较小,即对权重的约束越大。
alpha值越小(即越偏右),权重系数 weights的取值表现出较大的震荡。特别是当接近最右侧时,相当于没有对权重参数进行约束。
通过交叉验证找到最佳超参数alpha
sklearn提供了 RidgeCV,可以允许输入一系列的 alphas,然后 sklearn通过交叉验证得到适合的alpha。

4.逻辑回归
线性回归的输出值的范围通常是无法限定的。
逻辑回归通过使用 logistic函数(或称为 sigmoid函数)将其转化为(0,1)区间的数值。

逻辑回归可以被理解为是一个被 logistic函数归一化后的线性回归,也可以被视为一种广义线性模型。
逻辑回归应用举例:垃圾短信分类
可以用TF-IDF来抽取短信的特征向量,然后用逻辑回归分类:
(逻辑回归的输出值是连续的,而垃圾短信分类则是经典的两类分类问题,如何解决?)
办法:如果逻辑回归响应变量等于或超过指定的临界值(如0.5),预测结果就是正例,否则为反例。
逻辑回归中的损失函数优化方法
即如何找到能使损失函数取值尽可能小的模型参数。
class sklearn、linear_model.LogisticRegression(solver='liblinear')。其中的 solver参数决定了逻辑回归损失函数的优化方法。
Solver的常见取值包括:
-
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的情况。
-
liblinear:使用了开源的 liblinear库实现,内部使用了坐标轴下降法CD来迭代优化损失函数。
-
其他取值,如 bfgs、 newton-cg等
坐标下降法
Sklearn中逻辑回归的优化解决方案“ liblinear”使用基于 Liblinear的 coordinate descent CD(坐标下降)算法。
CD是一种非梯度优化算法。在每次迭代中,在当前点处沿一个坐标方向进行一维搜索以求得一个函数的局部极小值。在整个过程中循环使用不同的坐标方向。
如果在某次迭代中,函数得不到优化,说明一个驻点已经达到。

Tip:对于非平滑函数,CD法可能会遇到问题。即函数等高线非平滑时,算法可能在非驻点中断执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号