java架构之路-(mysql底层原理)Mysql之让我们再深撸一次mysql
让我再深撸一次mysql吧,这次主要以应对面试来说说mysql,大概几个方向,索引结构,查询引擎,索引优化,explain的详解和trace工具的使用。
索引:
我们先来看一下mysql的B+tree,本文几乎都在围绕这个图来说的。
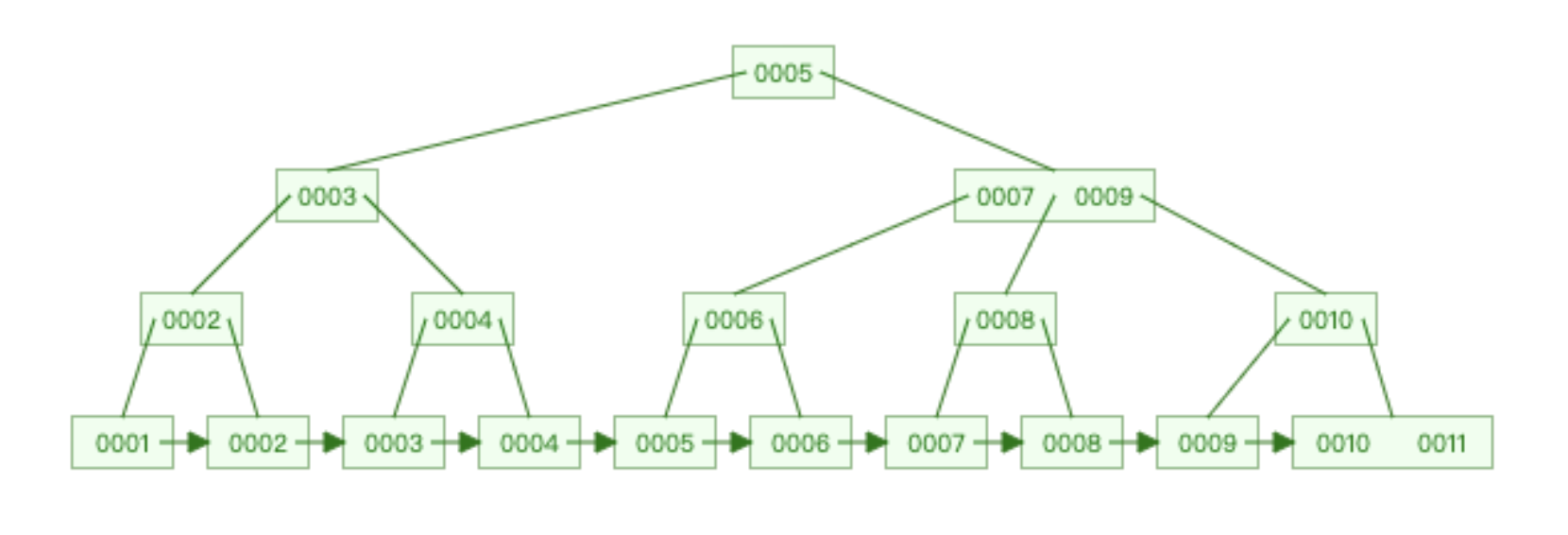
mysql的底层是使用B+tree来存储数据的,和B+tree有一点点不同的是叶子节点是双向链表的结构,并不是图内的单向指针的。且null值放置在叶子节点的最前面。这个是主键索引。
下面我来看一下联合索引,比如我们现在有Student表,将name,age,address三个字段设置成联合索引,这时存储的节点变为先按照name排序,name一致按照age排序的B+tree,携带数据为主键ID,并不携带整体数据的。
查询引擎:
我们常见的查询引擎主要是InnoDB还有MyISAM,区别主要是,MyISAM存储B+tree的索引携带数据都是内存地址,我们在查询的时候需要拿到hash计算后的内存地址,然后回行得到数据,而InnoDB直接携带数据,不需要回行,MyISAM不支持事物,不支持外键,也不支持行级锁,对于数据的非范围查询效率可能要高于InnoDB,且在底层有维护count总条数的内存,但是MyISAM的范围查询是不能用到索引的。我们大部分使用的都是InnoDB查询引擎,顺便提一下,MyISAM在磁盘上的文件为三个,一个是表的结构,一个是索引文件,一个是真正的数据文件,InnoDB在磁盘上存的是两个文件,一个是表结构文件,两一个是索引和数据文件。
explain的详解:
我们执行
explain select * from student;
这时会有十列数据,分别的是id,select_type,table,type,possible_keys,key,key_len,ref,rows,Extra。我们来逐个说一下他们都是干啥的。深入理解explain和B+tree的使用,mysql面试也就有救了。
id:就是一个编号,同时也代表了select的执行顺序,一般来说,我们有几个select就有几行数据,他们可能拥有相同或者不同的ID,执行顺序为ID大的优先执行,id相同,从上到下执行。id为null的最后执行。
select_type:代表我们的执行是一个什么样子的SQL,是简单查询啊,还是连表查询,大致可以分为
primary:复杂查询的最外层查询,(嵌套查询的最外层)比如explain select 1 from (select * from table) t;
subquery:子查询的select,但不表示在from后面的查询,比如explain select (select 1 from table) from table;或者explain select * from table where id = (select 1 from table where id = 2)
derived:和上面的subquery是相对的,表示在外层from后面的子查询。比如explain select * from (select * from table) t;
union:联合查询,explain select * from table union select * from table;
union result:表示联合查询后的组合,并不代表实际的select。
table:代表你查询的是哪一张表,如果表你给予了别名,这里会显示别名,会显示<derivedn>,标红色的n为执行计划里的id列。还有某些时候会显示<union1,2>,也就是说,我们合并id为1和2的结果虚拟表。有时候还会显示null,例如EXPLAIN SELECT 1
system一般是表为空,或者表里只有一行数据。 性能也是最好的,用左脚脚指头想想,数据都为空,或者只要一行,查询一定不会慢到哪里去。
const:用到了主键索引的查询,效率依然给力。主键索引叶子节点直接带着数据呢,不需要再去扫描第二颗树,效果一定给力了。
eq_ref:eq比较啊。所以简单的sql不会出现这个玩意。例如explain select * from table t innter join table2 t2 on t.pid = t2.id;也就是说该select下关联的一定是主键id,效率也是很OK的,后面会说一下innter join的查询机制。在trace的使用会说的,别慌,干货面试还没到来。
ref:相比eq_ref来说比较好记忆的,还是比较,也就是非主键索引的比较。例如explain select * from table t innter join table2 t2 on t.pid = t2.name;还是走索引的性能还是可以的。说明一下,这个type为ref,简单查询也可以出现,不一定是两张表关联才会出现的。
range:范围查询,也可以理解为索引范围查询。
index:扫描全表索引,比All强一点,说完All会举例。
All:垃圾了,全表扫描。
例如:explain SELECT classNum from student; 就是一个index查询,因为classNum是一个非主键索引,所以在我们的节点上存储的,不需要携带id再次去第二个上扫描。
explain SELECT classNum,create_time from student;就是一个all查询,因为classNum虽然是一个非主键索引,可以拿到classNum的数据,但是我们却得不到create_time的数据,其实也可以通过classNum的索引树得到id,然后再拿着id去主键索引树上找create_time,需要查找两颗树,代价太大了,mysql底层帮我们优化了,在这里说一下啊。sql具体走不走索引和表内数据量一点关系都没有,不是说表里的数据大,就一定走索引或者不走索引,后面我们在trace会具体分析。
possible_keys:可能用到的索引。比如主键索引,非主键联合索引。
set session optimizer_trace="enabled=on",end_markers_in_json=on
直接在mysql控制台运行就OK的,平时没事别开这个玩意,会对性能有影响的。
然后我们运行sql;在后面加上SELECT * FROM information_schema.OPTIMIZER_TRACE;例如:
select * from student WHERE name > '张三'; SELECT * FROM information_schema.OPTIMIZER_TRACE;
这时我们看结果2中会有有这样一个数据

我们来主要看第二列,TRACE,复制出来弄到json解析器内。
然后我们查找一下cost这个参数,cost就是我们使用各个索引的一个指标,越大表示越差,只在一个sql内比较,不要在两个不同的sql比较啊。我们来看一下我的cost
 这个是全表扫描大概是4.1。然后我继续向下看。
这个是全表扫描大概是4.1。然后我继续向下看。
这有还有一个使用name_num_address这个联合索引的cost为3.41要比前面的4.1好,那么mysql选择走name_num_address联合索引。我这还有一个事例。EXPLAIN select * from student WHERE name > 'a';
正常来说,name是一个联合索引,我们拿按照name去范围查找,type列应该为range,其实不然,mysql并没有选择走任何索引。可以自己尝试用trace去看看执行过程。
由于我爱动mysql的默认配置,这里简单说一下using filesort排序,底层分为两中排序方式,一种是单路排序,也可以理解为一次排序或者叫非回溯排序,就是你的查询结果足够小(小于1024字节),mysql有一个
max_length_for_sort_data 的参数默认为1024字节,我们就将我们要排序的结果集拿到sort buffer中进行排序,如果大于1024字节,放不下啦,也就是双路排序,也可以叫回溯排序,就是我们只拿着需要排序的字段和唯一标识的id到sort buffer中进行排序,排序以后再回去找他们对应的数据,
这个就是双路排序,使用trace工具可以看到不同的using filesort,可以自己尝试。输入set max_length_for_sort_data = 字节数,可以自己更改这个参数,最好没事别动这个玩意。让DBA调,我们只是知道这么回事,太底层的还没深入研究。
貌似说了这么多可以出几个面试题来聊聊了。
1、我们InnoDB的主键用数字自增好,还是UUID好?
答:当然是数字的好,还是回到我们的B+tree,这颗树是按照由小到大,由左向右来排列的。我们的数字便于我们去比较,UUID比较起来是很耗力耗时的。而且UUID比较占地方,mysql的B+tree的每个节点16KB大小,我们用数字类型,可在有限的空间内,有限的层级,存储更多的数据(其实没啥用了,三层的B+tree就可以存2000万的数据了)
而且最好是自动增长的,因为中间有间隙时,当我们插入的数据正好需要排列在间隙位置,可能会造成树的重新排列,影响效率。
2、为什么要设置is not null字段。
答:mysql对于null是不友好的,官方文档也是这样来说的,不建议使用null,null都放在B+tree最左侧,对于比较大小是很不利的。在sql语句中where ** is null 会直接不使用索引,与其null还不如给予其一个默认值。
3、什么是最左前缀原则。
答:我们在使用复合索引时必须要按照其顺序充分的使用,比如我们的联合索引为ABC三列,那我们想用C就一定先使用B,想使用B一定要使用A。范围查询以后的索引不再继续使用,并且不要做任何函数计算处理,也会不再走索引查询了。
再就是比如有一个字段varchar类型,我们在比较数字的时候一定要加“”,不然mysql底层会执行一个强转函数,从而造成不在走索引。
4、说说对于mysql的优化措施。个人总结。
答: 使用int类型作为主键,且自动增长。(一定要设置一个主键),设置索引字段is not null,索引字段要选择区分度高使用频率高的字段。
货币字段使用DECIMAL来存储。 很多事还要对应实际的业务需要来确定的。
mysql的索引个人觉得差不多就这么多吧。关于索引的使用优化并没有说太多,这个还是需要靠个人经验的,心中有索引的存储模型,熟练使用explain我相信优化sql不成问题的。
下一期我们再来说说mysql的锁,事务,分布式还有日志。 还有MVCC
有一个点忘记说了,select count(name) from table 非主键索引是最快的。别不信,自己琢磨琢磨。自己去试(InnoDB)。MyISAM引擎有维持count的内存。
最进弄了一个公众号,小菜技术,欢迎大家的加入


 浙公网安备 33010602011771号
浙公网安备 33010602011771号