[Python] 爬虫系统与数据处理实战 Part.5 排序与反爬
PageRank
- 计算每个网页的PageRank值,根据此值大小对网页重要性排序
动态排序
- 主从服务器维持心跳
- 根据重排条件,启动重排流程
- 通知爬虫暂停爬取
- 爬虫在心跳回复中收到暂停通知,暂停爬取并通知主机
- 主机等待所有爬虫暂停
- 主机开始重排网页
- 重排结束,设置标志位
- 心跳回复收到回复指令,继续爬取
通信协议
- 注册
- 暂停、回复爬取
- 终止爬取
- 错误通知
- 状态同步
Master 工作
- 管理爬虫
- 动态重排
- 间隔检查状态
Slave 工作
- 注册
- 获取并执行命令
- 同步状态
- 爬取网页,保存到各分布式数据库
deque
- 单线程
- SELECT * FROM URLS WHERE STATUS='NEW' ORDER BY PR DESC LIMIT 1
- 多线程防止拿到同一条 url ,实现加读锁的效果:
- chk_code = random.nextInt()
- UPDATE URLS SET CHE_CODE=chk_code, STATUS=‘Downloading’ WHERE STATUS='New' ORDER BY PR DESC LIMIT 1
- SELECT * FROM urls WHERE CHK_CODE=chk_code
反爬虫
服务器处理 Web 请求流程
- 到达防火墙,检查访问频次
- 根据端口映射,到达对应服务器,如 Apache
- 到达 Apache,通过 virtual host 查找根目录
- 查找 .htaccess 伪静态设置,映射实际目录及文件
- 执行脚本或提取文件
- 确认 cookie 信息,查找用户
- 用户权限检查
- 执行命令,返回数据
Virtual Host
- 一台服务器主机可以处理多个域名或 IP
- 将不同域名及 IP 映射到不同的网站根目录
- 不同域名指向同一服务器,更容易被服务器网关识别为爬虫而禁止
- 对于一个域名映射多台服务器的网站(CDN),可并发抓取不同服务器,避开访问频率限制
- 输入域名,默认路由到最近 CDN
- 访问 CDN,ip+host
- 输入CDN ip 地址无法访问,每个 CDN 服务器服务多个域名,需要指定 host
- 小网站——多 ip 代理;大网站——Virtual Host
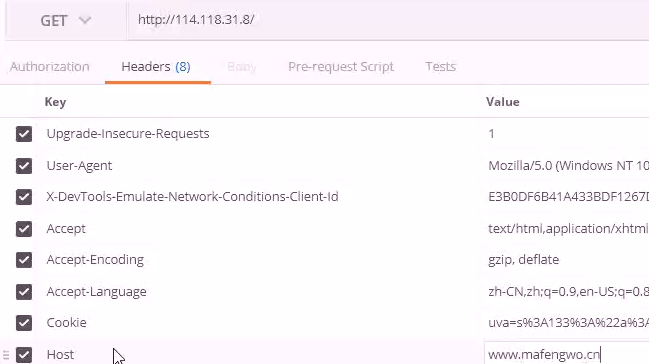
爬虫识别规则
- 单一 IP 非常规访问频次
- 单一 IP 非常规数据流量
- 大量重复简单的网站行为
- 只下载网页,没有后续 js css 请求
- 陷阱,如通过CSS对用户隐藏的链接,只有爬虫才会访问
反爬措施
- 大量使用动态网页,爬虫无法拿到重要数据,或爬取效率大幅降低
- 基于流量的拒绝,设置访问最大带宽,如每个 IP 最多 3 个连接,最大 1 MB/s
- 基于 IP 连接的拒绝,如每个 IP 最多同时 1个连接
- iptables 的控制
应对措施
- 降低访问频次,如 20s 一次
- 多主机策略(分布式+CDN+proxy)
- 修改 User-Agent
- 动态 IP 切换,变换 IP
- 把爬虫放到访问频繁的主站 IP 子网下,如教育网
- 探测陷阱,如 nofollow 的 tag,display:none 的 css
- 使用了规则(pattern)的批量爬取,对规则进行组合
- 按照 Robots.txt 的定义行为明文抓取
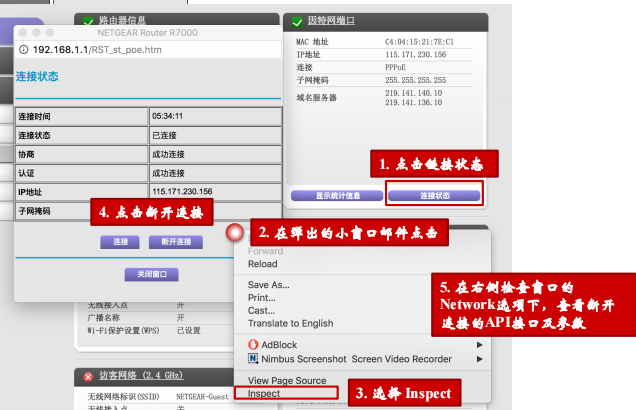
- 重启路由器,路由器登录方式
- json
- ajax 表单
- Authorization Required

 浙公网安备 33010602011771号
浙公网安备 33010602011771号