[项目] 智慧出行
业务架构
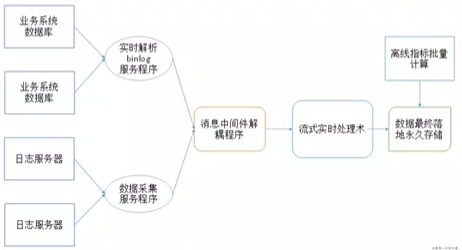
- 流程
- 成都、海口两台日志服务器的数据不断产生,flume采集
- 网络传输到第三台flume(兼做网关),再到kafka不同的topic里
- sparkstreaming解析kafka数据,存入hbase,redis
技术选型
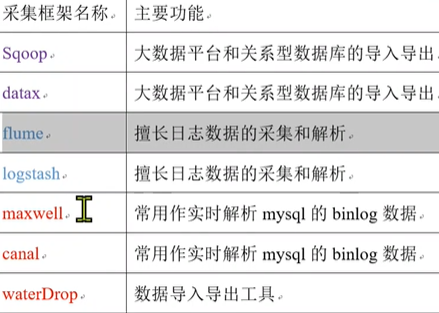
- 数据采集
- 大数据平台和关系型数据库的导入导出:Sqoop、datax
- 日志数据的采集和解析:flume(固态硬盘,每秒20-30M)、logstash
- 实时解析mysql的binlog数据:maxwell、canal、waterDrop
- 消息中间件
- RabiitMQ
- Kafka
- Redis
- 实时流处理技术
- Storm:现在基本不用
- SparkStreaming:非结构化数据
- StructStreaming:结构化数据
- Flink:使用较多
- 永久存储
- HFDS:分布式文件存储系统
- Hbase:K-V对的nosql数据库
- Kudu:类似Hbase
- 离线计算框架(OLAP)
- MapReduce:分布式文件计算系统
- Hive:基于MR数仓
- Impala:sql on hadoop,速度快,内存消耗大
- SparkSQL:基于spark,批流处理
- FinkSQL:基于flink,批流处理
- druid:针对时间序列数据,提供低延迟数据写入及快速交互式查询的分布式OLAP数据库
- kylin:基于hbase的预计算
- presto:分布式sql查询引擎,查询分布在一个或多个不同数据源中的大数据集
- clickHouse:开源OLAP框架
- 架构
- kappa:实时和离线分开
- lambda:消息中间件接收数据后实时处理
- 前端
- AngularJS前后端分离
数据采集模块
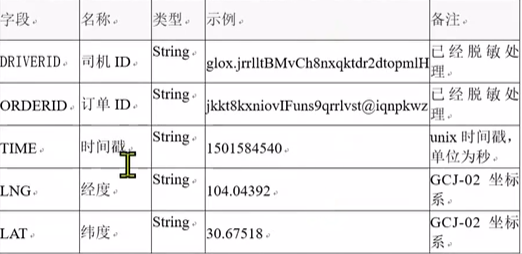
- 数据格式
- 数据回放
- java -jar bin/FileOperate-1.0-SNAPSHOT-jar-with-dependencies.jar /root/kkb/datas/sourcefile/chengdu /root/kkb/datas/destfile/chengdu 3000
- ps -ef | grep FileOperate-1.0-SNAPSHOT-jar | grep -v grep
- flume
- node01 node02
- source:TailDirSource
- channel:FIleChannel
- sink:avro sink
- node03
- source:avro source
- channael:FIleChannel
- sink:kafka
- bin/flume-ng agent -n a1 -f conf/flume-client.conf -c conf -Dflume.root.logger=INFO,console
- node01 node02
- kafka
- bin/kafka-server-start.sh config/server.properties &
- bin/kafka-topics.sh --create --zookeeper bigdata111:2181 --replication-factor 1 --partitions 3 --topic cheng_du_gps_topic
- bin/kafka-console-consumer.sh --bootstrap-server bigdata111:9092 --topic cheng_du_gps_topic
- 启动顺序:数据生成--flume--kafka消费

- 数据接收异常补录:at least once,允许重复,flume接收异常可重试
轨迹监控模块
- 日志数据通过flume采集后,收集到kafka中
- SparkStreaming消费kafka数据,维护offset到hbase(kafka offset 默认50个分区,1个副本,存在数据丢失问题)
- 将GPS数据保存到redis
- 前台websocket获取GPS数据,在地图上显示小车运行轨迹
- 类设计
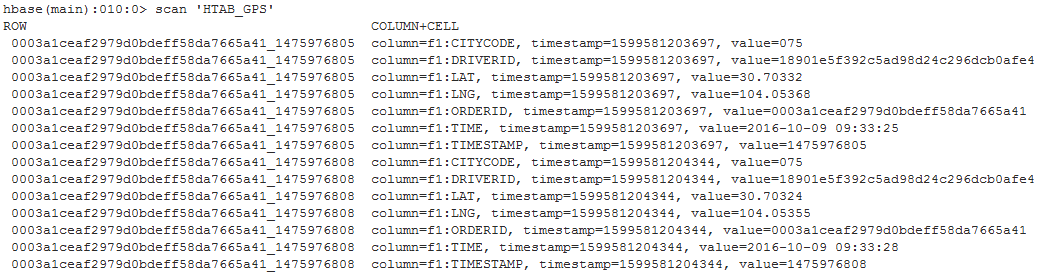
- StreamingKafka.scala:读kafka数据到hbase和redis
- HBaseUtil.java:连接初始化(局部变量,谁用谁取谁关,保证线程安全)
- HBse建表,导入数据
- create 'hbase_offset_store','f1','f2'
- create 'HTAB_GPS','f1','f2'
- 运行SparkStreaming程序


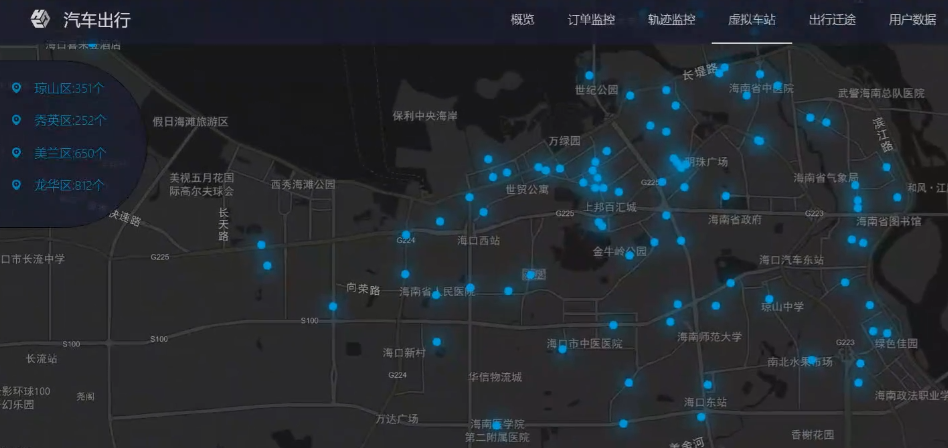
虚拟车站
- 规划上车点,解决司机找乘客问题
- hbase中的每个订单都有上车经纬度,在区域划分为小单元
- 将地球划分成为六边形(栅格化)
- 取圈内打车点经纬度最小的为虚拟车站,所有圈内的人都在虚拟车站上车
- 判断哪些经纬度属于同一个六边形:相同六边形里面的经纬度通过uber h3算法,会得到相同的long类型的结果值
- 判断虚拟车站属于哪个区:边界经纬度广播,使用 java geometry 库对点以及面之间的关系做判断(共享单车电子围栏)
- 统计虚拟车站数据,保存在HBase中
- 通过phoenix创建表/视图映射hbase表(二级索引),以sql语句方式查询HBase,通过javaWeb展示
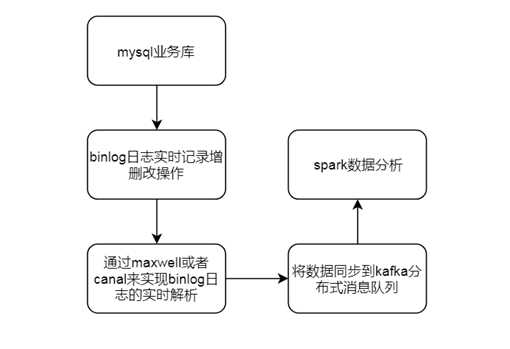
业务库功能开发
- 通过 maxwell,解析业务库 mysql 的binlog,将业务数据实时同步到 kafka
- 业务数据库表
- driver_info:司机表
- renter_info:乘客表
- order_info:订单表
- opt_alliance_business:司管方表
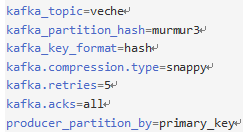
- kafka配置
- 分区,解决数据倾斜:maxwell 中 hash+murmur3,key.hashCode%分区数;自定义分区
- 全局数据无序,分区内部有序:一个 topic 一个分区;自定义 rowkey,保证每个用户数据有序
- 业务数据库表
- SparkStreaming 解析 kafka 数据,存入 Hbase
- hbase设计
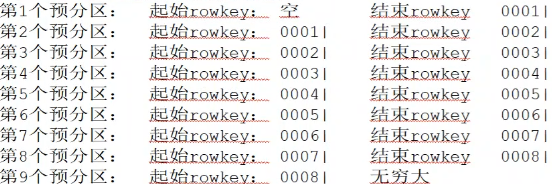
- 预分区避免数据倾斜,如 driver-info 设计8个预分区
- hbase 中数据按字典序排序,最大 | , 最小 ""(空)
- (id+时间戳).md5 截取12位,拼接前4位,得到16位长度rowkey
- 类设计
- CreateHBaseTableInit.java:创建hbase表
- StreamingMaxwellKafka.scala:消费kafka数据到hbase
- HbaseTools.scala:增删改查逻辑
- RowkeyUtil.scala:rowkey设计逻辑
- 冷热数据分离
- 轨迹数据量大,通过订单号通过 get rowkey 查询
- 订单表、用户表等数据少,通过 phoenix 二级索引查询
- kafka 数据 exactly once 保证
- at least once + 幂等性(rowkey特性)
- 第一步插入hbase,第二步更新offset
- 第一步异常:下次继续重新消费
- 第一步正常,第二步异常:下次继续重复消费(多次插入,幂等性),相同数据rowkey覆盖
- hbase设计
- sparkSQL 离线批量处理,自定义数据源获取 Hbase 中数据,将查询结果保存到 Hbase 中
- 获取hbase数据方式
- OLTP:scan、get
- OLAP:hive整合hbase、mr读hbase、sparkSQL自定义数据源、sparkCore读hbase
- sparkSQL自定义数据源
- redis、hbase、mongoDB、文件,实现大数据查询平台
- DataSource V2
- 类设计
- SparkSQLVirtualStation.scala:sparkContext.newAPIHadoopRDD 获取hbase数据,转换为RDD,再转为DF
- HbaseSourceAndSink.scala:自定义数据源,读取hbase数据,java和scala类型转换,写sql,结果存到hbase
- WriteSupport->createWrite->DatasourceWrite->createWriteFactory->DataWriteFactory->createDataWrite->DataWrite
- 获取hbase数据方式
- 监控页面大屏开发,写 sql
- 统计每个城市,每日及每月车辆的总数量
- 通过phoenix创建表/视图映射hbase表(二级索引),以sql语句方式查询HBase,通过javaWeb展示
Spark调优与监控
- 调优
- sparkconf 参数设置
- sparkSession 参数设置
- 感知+背压+动态资源划分->资源弹性的管理操作
- 监控
- 代码监控、restAPI监控、浏览器管理界面监控
问题
- 面试怎么说项目
- 细节:业务逻辑、功能模块、负责的功能职责、遇到了哪些问题、日常工作、服务器配置、数据量大小
- 数据倾斜
- 发现倾斜:查看任务管理界面,某些task运行时间比其他长的多
- 如何解决:将数据打散,保证每个task计算数据量大致差不多
- 为什么要把kafka的offset保存到hbase
- kafka保存offset会过期
- kafka 中 topic consum_offset 默认50个分区,一个副本,存在数据丢失问题
- 方便控制hbase的offset值,实现数据重复消费功能
- HBase如何设计Rowkey避免数据倾斜
- 主键.hashCode % numPartitions
- 左补齐三个0
- (id + 数据创建时间戳).md5截取12位拼接上前面4位,得到16位长度的rowkey
- maven dependency 飘红
- 用课程的maven仓库覆盖本地的
- 删除maven仓库中lastupdate
- 打开idea
- Hbase实时查询的方式
- get scan 或 scan startRow stopRow
- phoenix:作为Hbase二级索引,通过sql语句查询
- phoenix全局索引及局部索引适用情况
- 大数据两种架构模型
- lambda:离线和实时分开,数据不一致,结果可能不一样
- kappa:通过消息中间件收集数据,实时和离线用同一套代码
- 分区发现感知+背压+动态资源划分机制=资源弹性管理操作
- spark.dynamicAllocation.enabled
- spark.streaming.backpressure.initialRate
- Spark任务监控方式
- 代码监控
- restAPI
- 浏览器管理界面
- SparkStreaming本质是微批次处理
- 每批次成功数据,失败数据
- 执行多少批次
- 每批次执行时间
- 实际生产环境
- 每天数据增量>50GB,至少保存1年以上,历史累计数据超过4TB
- 一台高配服务器成本,每个月费用2-5w
- 0-10小型机集群;10-30台中型机集群;>30台大型机集群
- 128G内存+16/32核CPU+4/8TB机械硬盘+万兆网卡
- 每条数据1KB,一天数据量
- 出行项目配置
- GPS数据,每天500-1TB
- 保存最近3个月数据
- 42台高配服务器,128GB+8TB硬盘+32核CPU(研发费用每年2亿)
- 起步租云服务器,也可以机房托管
- 面试
- 刷题,写简历,改简历,模拟面试,面试,录音,总结回顾
- 数仓统计了哪些功能?回答五个模块以上(用户、物品),每个模块五个以上指标(留存率)
- IDEA快捷键
- ctrl+alt+v:提取变量
参考
SparkStreaming整合Kafka(Offset保存在Hbase上,Spark2.X + kafka0.10.X)
https://www.cnblogs.com/mlxx9527/p/9391944.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号