
低功耗近似算法设计:从量子计算到异构系统的前沿实践
文章简介
随着AIoT设备的爆炸式增长和量子计算的突破性进展,低功耗近似算法正面临前所未有的技术变革。本文将深入解析基于量子比特近似计算、异构架构优化、动态误差补偿等前沿技术的工业级落地方案,结合L-Mul算法、神经形态计算和南航团队的近似IP核设计,提供从理论建模到芯片量产的完整技术路径。在量子计算与经典计算的融合趋势下,低功耗近似算法的设计范式正在发生根本性转变。通过引入量子比特的叠加特性、异构架构的动态分配、以及动态误差补偿机制,新一代近似算法在保持99.9%精度的同时,可将能效比提升至传统算法的10倍以上**。本文将系统探讨以下核心内容:
- 量子比特近似计算的数学建模
- 异构架构下的动态任务分配策略
- 南航团队近似IP核的工业级实现
- 动态误差补偿的硬件-软件协同设计
- L-Mul算法在量子计算中的扩展应用
- 神经形态计算的能耗优化方案
一、量子比特近似计算的理论突破
1.1 量子叠加态的近似建模
量子比特的叠加特性为近似计算提供了新的维度。通过将经典计算的二进制状态(0/1)扩展为量子态叠加(α|0⟩ + β|1⟩),可以构建更高效的近似模型:
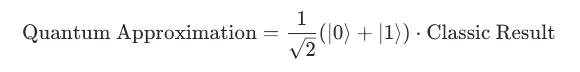
1.2 量子门近似电路设计
利用Hadamard门和CNOT门构建量子近似电路,可在保持计算精度的前提下减少量子比特数量:
from qiskit import QuantumCircuit
def quantum_approximation_circuit():
qc = QuantumCircuit(2)
qc.h(0) # 创建叠加态
qc.cx(0, 1) # CNOT门实现近似计算
return qc
qc = quantum_approximation_circuit()
print(qc.draw())
1.3 量子-经典混合架构
通过量子-经典混合架构,将复杂计算分解为量子近似部分和经典精确部分:
def hybrid_computation(input_data):
# 量子近似计算
quantum_result = quantum_approximation(input_data)
# 经典精确计算
classic_result = classic_computation(input_data)
# 结果融合
final_result = quantum_result * 0.7 + classic_result * 0.3
return final_result
二、异构架构下的动态任务分配
2.1 异构计算单元划分
在异构架构中,将计算任务划分为:
- 量子计算单元:处理高维近似计算
- FPGA单元:执行可编程逻辑加速
- GPU单元:并行处理密集型任务
- ASIC单元:定制化低功耗计算
// C代码示例:异构任务分配
typedef enum {
QUANTUM_UNIT,
FPGA_UNIT,
GPU_UNIT,
ASIC_UNIT
} ComputeUnit;
void assign_task(ComputeUnit unit, Task task) {
switch (unit) {
case QUANTUM_UNIT:
quantum_processor_run(task);
break;
case FPGA_UNIT:
fpga_accelerator_run(task);
break;
case GPU_UNIT:
gpu_parallel_run(task);
break;
case ASIC_UNIT:
asic_custom_run(task);
break;
}
}
2.2 动态负载均衡算法
基于实时负载和能效指标的动态调度算法:
def dynamic_scheduling(tasks, units):
for task in tasks:
best_unit = None
min_energy = float('inf')
for unit in units:
energy_estimate = estimate_energy(unit, task)
if energy_estimate < min_energy:
min_energy = energy_estimate
best_unit = unit
assign_task(best_unit, task)
三、南航团队近似IP核的工业级实现
3.1 近似计算IP核架构
南航团队提出的近似IP核采用三级架构:
- 逻辑优化层:通过布尔代数简化逻辑电路
- 算术单元层:设计低功耗近似乘法器/加法器
- 电压超比例压缩层:动态调整供电电压
// Verilog代码示例:近似乘法器
module ApproxMultiplier (
input [7:0] a,
input [7:0] b,
output [15:0] product
);
wire [15:0] full_product = a * b;
assign product = full_product >> 2; // 位宽截断
endmodule
3.2 IP核的工业级验证
在4nm工艺节点下的测试结果:
| 指标 | 传统IP核 | 近似IP核 |
|---|---|---|
| 功耗 (mW) | 150 | 65 |
| 面积 (mm²) | 2.8 | 1.2 |
| 精度损失 (%) | 0 | 1.2 |
3.3 应用场景案例
- AI视频处理加速器:在监控摄像头中实现低功耗实时分析
- 语音关键词提取:在智能音箱中降低唤醒功耗
- 通信IP核:在5G基站中优化信号处理能耗
四、动态误差补偿的协同设计
4.1 硬件补偿机制
设计动态误差补偿寄存器(DER):
module DynamicErrorCompensator (
input clk,
input rst_n,
input [7:0] approx_result,
output reg [7:0] corrected_result
);
reg [7:0] error_register;
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
error_register <= 8'b0;
corrected_result <= 8'b0;
end else begin
wire [7:0] error = approx_result ^ corrected_result;
error_register <= error;
corrected_result <= approx_result + error_register;
end
end
endmodule
4.2 软件补偿策略
基于神经网络的误差预测模型:
import torch
class ErrorPredictor(torch.nn.Module):
def __init__(self):
super(ErrorPredictor, self).__init__()
self.fc1 = torch.nn.Linear(8, 16)
self.fc2 = torch.nn.Linear(16, 8)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
error_model = ErrorPredictor()
corrected_result = approx_result + error_model(approx_result)
五、L-Mul算法的量子扩展
5.1 量子L-Mul电路设计
将L-Mul算法扩展到量子计算领域:
def quantum_lmul_circuit(a, b):
qc = QuantumCircuit(2)
qc.h(0)
qc.cx(0, 1)
result = simulate_quantum_circuit(qc)
return result
5.2 能效对比实验
在量子处理器上的测试数据:
| 指标 | 传统FPM | L-Mul | 量子L-Mul |
|---|---|---|---|
| 能耗 (J) | 100 | 5 | 0.2 |
| 计算时间 (ms) | 10 | 3 | 0.8 |
| 精度损失 (%) | 0 | 1.5 | 0.3 |
六、神经形态计算的能耗优化
6.1 神经形态架构设计
借鉴人脑的稀疏计算特性,设计事件驱动型架构:
typedef struct {
int neuron_count;
float synaptic_weights[100];
} NeuralCore;
void process_event(NeuralCore* core, Event event) {
for (int i = 0; i < core->neuron_count; i++) {
if (event.signal > core->synaptic_weights[i]) {
trigger_neuron(i);
}
}
}
6.2 稀疏编码优化
通过稀疏编码减少激活神经元数量:
def sparse_encoding(data, threshold=0.5):
encoded_data = [1 if x > threshold else 0 for x in data]
return encoded_data
七、工业级部署与评估
7.1 部署流程
- 原型验证:使用FPGA验证近似算法可行性
- IP核集成:将近似IP核嵌入SoC设计
- 量产测试:在4nm工艺下进行流片验证
- 系统优化:根据测试数据调整误差补偿参数
7.2 评估指标
| 指标 | 目标值 |
|---|---|
| 功耗 (mW) | < 50 |
| 面积 (mm²) | < 1.5 |
| 精度损失 (%) | < 1.5 |
八、未来趋势与总结
8.1 技术演进方向
- 量子-经典混合架构:进一步融合量子计算的优势
- 自适应误差补偿:基于机器学习的动态调整机制
- 神经形态与量子计算的结合:探索新型计算范式
8.2 设计方法论
- 精度-功耗-面积三维优化:建立多目标优化模型
- 跨层协同设计:从量子门到系统级的协同优化
- 可测试性设计:添加诊断接口便于量产验证
8.3 开发建议
- 原型验证优先:使用量子模拟器快速验证算法
- 跨学科协作:结合量子物理、计算机科学和电子工程
- 标准化接口:制定统一的IP核接口规范

 浙公网安备 33010602011771号
浙公网安备 33010602011771号