

Scrapy初
爬取'http://www.521609.com'图片并保存到本地


1 import scrapy 2 from scrapy.selector import HtmlXPathSelector 3 import os 4 from scrapy.http import Request 5 from tutorial import items 6 7 8 class MyspiderSpider(scrapy.Spider): 9 name = 'myspider' 10 allowed_domains = ['521609.com'] 11 start_urls = ['http://www.521609.com/daxuexiaohua'] 12 url_set = set() 13 def parse(self, response): 14 self.url_set.add(response.url) 15 #1、获取当前页面的图片信息 16 hxs = HtmlXPathSelector(response) 17 div_item = hxs.select('//div[@class="index_img list_center"]') 18 src_list = div_item.select('.//img/@src') 19 alt_list = div_item.select('.//img/@alt') 20 #获取图片和名字 21 for (src,alt) in zip(src_list,alt_list): 22 addr = 'http://www.521609.com'+src.extract() 23 name = alt.extract() 24 item = items.TutorialItem(addr = addr,name = name) 25 yield item 26 #2、获取所有的页面 27 page = hxs.select('//div[@class="listpage"]') 28 page_list = page.select('.//a/@href').extract() 29 for per_page in page_list: 30 page_abs_url = os.path.join(self.start_urls[0],per_page) 31 if page_abs_url in self.url_set: 32 pass 33 else: 34 obj = Request(url=page_abs_url, method='GET', callback=self.parse) 35 yield obj
1 import scrapy 2 3 4 class TutorialItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 addr = scrapy.Field() 8 name = scrapy.Field()
ITEM_PIPELINES = {'tutorial.pipelines.TutorialPipeline':100}
1 import os 2 import requests 3 4 class TutorialPipeline(object): 5 def __init__(self): 6 if not os.path.exists('E:\my\down_pic'): 7 os.makedirs('E:\my\down_pic') 8 9 def process_item(self, item, spider): 10 response = requests.get(item['addr'], stream=True) 11 file_name = '%s.jpg' % (item['name']) 12 print(file_name) 13 with open(os.path.join('E:\my\down_pic', file_name), mode='wb') as f: 14 f.write(response.content) 15 return item
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
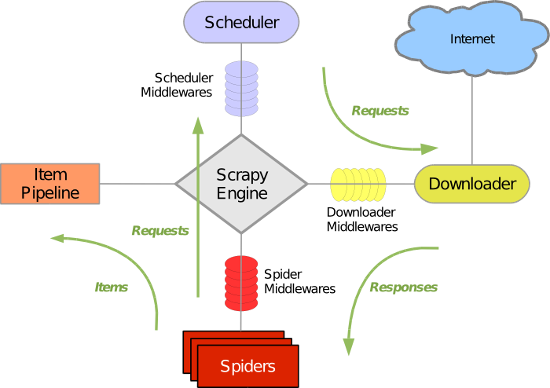
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号