hdfs丢数据块问题探讨
背景 :在后装kafka的选择hdfs两个盘的路径作为kafka公用盘,安装失败之后hdfs的这个两个盘路径在namenode原生界面显示报错,经过一系列操作,修改了这两个路径下的version文件,就是在/srv/Bigdata/hadoop/data09/dn/current/version修改,修改完重启相应的datanode节点,发现显示报错的路径恢复了,丢失的数据块报错也少了,具体修改就是从其他正常的盘的version文件复制过来,后面根据这个思路,同时修改了其他路径,然后重启之后发现数据块并没有得到修复,但是路径已经不报错了,是什么原因导致的namenode报blockMissing呢?为什么单个datanode重启之后数据块丢失的变少了,同时几个datanode修改重启之后数据块没有变少。先把跟这个问题相关的原理一个个解释,再结合看一下这个丢块的原因到底是哪种情况造成的。
Namenode是怎么更新元数据的(HA)
- 内存优先: 所有元数据更新首先发生在 NameNode 的内存中,以保证高性能访问。
- EditLog 是关键: 所有更改操作都必须先写入 EditLog 并确保持久化(本地或通过 QJM)后,才被认为成功提交。这是防止数据丢失的核心机制。
- 异步持久化到 FsImage: FsImage是内存状态在某个时间点的完整快照,通过定期的 Checkpointing 过程(由SecondaryNameNode或StandbyNameNode执行生成,目的是加速重启。
- DataNode 报告驱动块位置更新:DataNode的心跳和块报告是NameNode了解块副本实际物理位置和健康状况的唯一方式NameNode据此维护BlocksMap中的位置信息并触发必要的块管理操作(复制、删除)。
- HA 优化:在高可用模式下Standby NameNode持续应用EditLog保持状态同步并执行Checkpointing消除了单点故障和独立的SecondaryNameNode。
这个事情导致namenode元数据出现问题的情况应该是datanode上报出了问题,看一下version文件修改有哪些影响,先来看一下version文件参数配置情况:
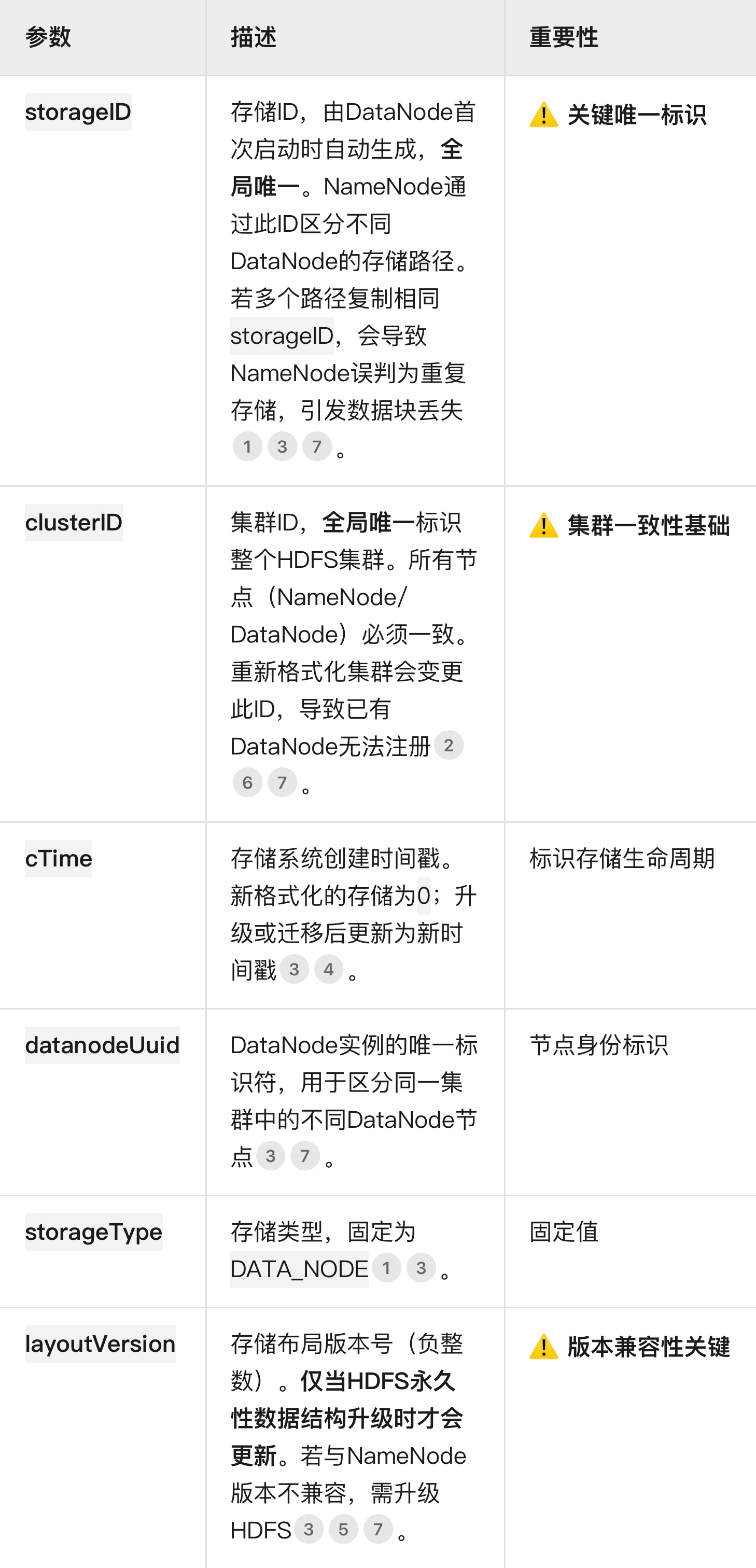
为什么我们修改一个storageId数据能恢复,批量修改之后滚动重启不恢复呢?
操作虽然暂时恢复了DataNode存储路径的可见性,但未能解决数据块丢失的核心问题,原因涉及HDFS存储机制、数据块恢复逻辑以及混合磁盘使用的冲突。以下是详细分析和解决方案:
问题根本原因分析
• HDFS每个数据目录的version文件包含唯一存储ID(StorageID)和集群ID(ClusterID)。从其他路径复制version文件会导致多个磁盘共享相同的存储ID。
• 后果:NameNode会认为这些路径是同一存储的重复上报,仅保留其中一个路径的块信息,其他路径的数据块被视为“丢失”。你首次修改单个DataNode后部分恢复,是因为冲突路径较少;但批量操作后,冲突规模扩大,导致NameNode无法正确关联所有数据块。
• 单节点修改:冲突路径少,部分未冲突的块被正确上报(减少几百个)。
• 批量操作:所有共享路径的存储ID均冲突,NameNode丢弃大量重复上报的块,且未更新的元数据掩盖了真实丢失量。
• 数据未恢复:物理损坏的块需主动修复,仅重启无法解决。
关键点:VERSION文件是DataNode的“身份证”,复制操作等同于让多个磁盘共用同一身份证,必然导致NameNode数据混乱。解决方案的核心是重建唯一ID、物理隔离磁盘、主动修复元数据。
未完待续。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号