NameNode高可用
通过hadoop官网提供的namenodeHA有两种,分别是QJM(Quorum Journal Manager)和NFS(Network File System)

官方参考网址: https://hadoop.apache.org/docs/r3.4.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html
activeNamenode和standbynamenode实现高可用切换的流程是(QJM方式):
图解:
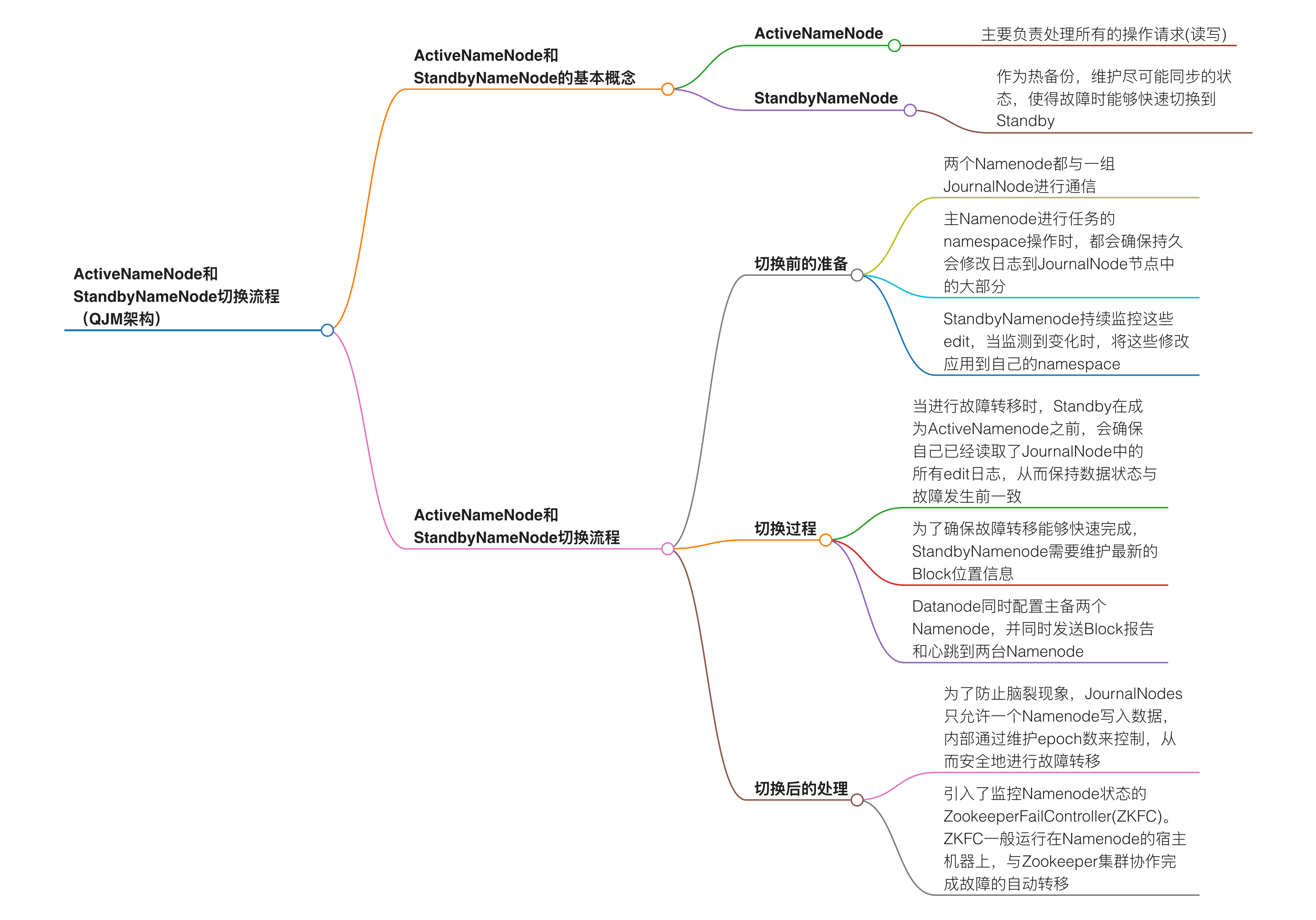
高可用切换核心流程(以 Active 故障切换为例)
-
故障检测(Detection)
HealthMonitor(ZKFC 组件) 周期性(默认每 5 秒)向 Active NameNode 发送 RPC 心跳检测。
若连续失败(默认超时 15 秒):
判定 Active NameNode 异常(如进程崩溃、网络隔离、机器宕机)。
ZKFC 触发 故障切换流程。 -
ZooKeeper 选举(Election)
ZKFC 尝试在 ZooKeeper 集群创建临时节点 /hadoop-ha/${clusterName}/ActiveStandbyElectorLock(抢锁机制)。
若创建成功:
该 ZKFC 对应的 Standby NameNode 被选为新的 Active 候选者。
若创建失败(其他节点已抢锁):
等待并监听该节点,直到锁释放后重试。 -
隔离旧 Active(Fencing)
关键:防止脑裂(双 Active 同时写入)
共享存储隔离(JournalNode 层):
新 Active 生成 更高 epoch number(单调递增的全局序列号)。
向所有 JournalNode 写入新 epoch,使旧 Active 的写权限失效(写入时因 epoch 过低被拒绝)。
进程级隔离:
通过配置的 Fencing 方法强制终止旧 Active 进程:
sshfence:SSH 登录目标机器执行 kill -9。
shellfence:自定义脚本(如调用管理接口隔离机器)。 -
元数据同步(Metadata Sync)
新 Active 从 JournalNode 集群拉取最新的 EditLog。
重放所有未应用的 EditLog 到内存元数据,确保状态与故障前一致。 -
服务接管(Takeover)
HDFS 服务层:
新 Active 解除安全模式,开始处理客户端请求。
更新所有 DataNode 的元数据(通过心跳下发新 Active 地址)。
客户端重定向:
客户端通过 ZKFC 或配置的 VIP(Virtual IP)自动重连到新 Active。
关键组件协作流程图
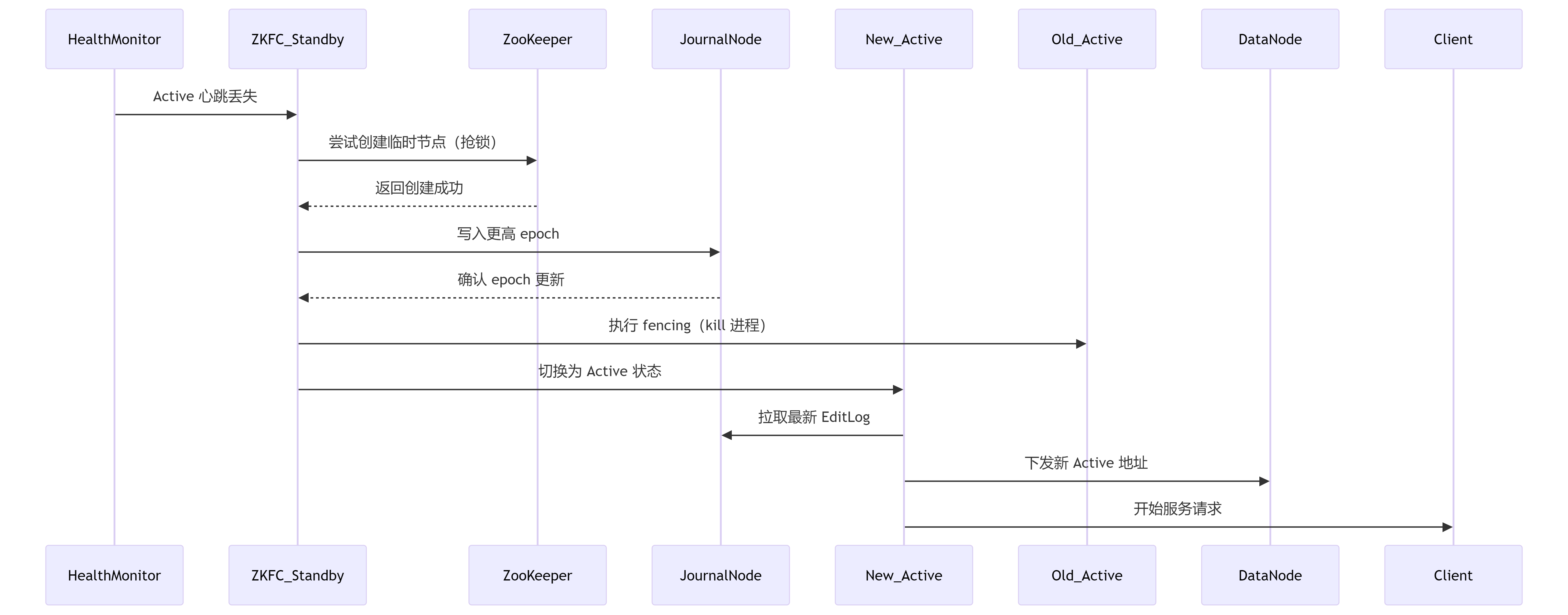
很多不熟悉这个流程的人看着或多或少会有些混乱的,现在挨个讲解一下:
*ZKFailoverController(ZKFC)是基于Zookeeper的故障转移控制器,负责控制NameNode的主备切换。HealthMonitor是ZKFC的一个组件,周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth和getServiceStatus)来监控NameNode的健康状态。当发现Active NameNode异常时,ZKFC会通过Zookeeper进行选举,完成主备切换。ActiveStandbyElector负责具体的主备选举工作,利用Zookeeper的临时节点机制实现选举。
ZKFC是主备切换的“决策者”,HealthMonitor是其“感知器官”。
不存在独立的“ZKFC_Standby”进程,它是ZKFC在Standby NN节点上的运行实例。
- 关于JournalNode同步的数据
JournalNode集群唯一同步的是EditLog,记录所有HDFS元数据变更操作(如创建文件、删除块)
Active NN将EditLog拆分为Segment(如每2MB或60秒滚动),并行写入所有JournalNode。
FsImage(元数据快照):
不通过JournalNode同步!
由Standby NN本地生成:定期合并EditLog生成新FsImage,上传至Active NN替换旧文件--->(这里可以看其他随笔:HDFS概述edits与fsimage的合并机制有讲到)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号