3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
Spark大数据计算平台包含许多子模块,构成了整个Spark的生态系统,其中Spark为核心。
伯克利将整个Spark的生态系统称为伯克利数据分析栈(BDAS),其结构如图1-1所示。
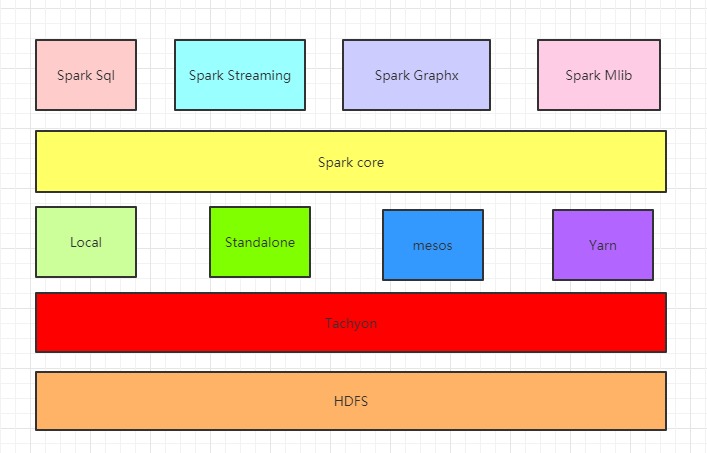
图1-1
组件介绍
1 . Spark Core:Spark的核心组件,其操作的数据对象是RDD(弹性分布式数据集)
图中在Spark Core上面的四个组件都依赖于Spark Core,可以简单认为Spark Core就是Spark生态系统中的离线计算框架,eg:Spark Core中提供的map,reduce算子可以完成mapreduce计算引擎所做的计算任务
2 . Spark Streaming:Spark生态系统中的流式计算框架,其操作的数据对象是DStream,其实Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(批次间隔时长)(如1秒)分成一段一段的数据系列(DStream),每一段数据都转换成Spark Core中的RDD,然后将Spark Streaming中对DStream的转换计算操作变为针对Spark中对RDD的转换计算操作,如下图1-2所示
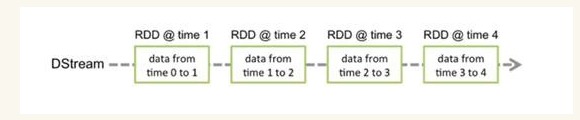
图1-2
在内部实现上,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含了自己特定时间间隔内的数据流(如上图中0到1秒接收到的数据成为一个RDD,1到2秒接收到的数据成为一个RDD),使用Spark Streaming对图中DStream的操作就会转化成使用Spark Core中的对应算子(函数)对Rdd的操作
3 . Spark Sql:可以简单认为可以让用户使用写SQL的方式进行数据计算,SQL会被SQL解释器转化成Spark core任务,让懂SQL不懂spark的人都能通过写SQL的方式进行数据计算,类似于hive在Hadoop生态圈中的作用,提供SparkSql CLI(命令行界面),可以再命令行界面编写SQL
4 . Spark Graphx:Spark生态系统中的图计算和并行图计算,目前较新版本已支持PageRank、数三角形、最大连通图和最短路径等6种经典的图算法
5 . Spark Mlib:一个可扩展的Spark机器学习库,里面封装了很多通用的算法,包括二元分类、线性回归、聚类、协同过滤等。用于机器学习和统计等场景
6 . Tachyon:Tachyon是一个分布式内存文件系统,可以理解为内存中的HDFS
7 . Local,Standalone,Yarn,Mesos:Spark的四种部署模式,其中Local是本地模式,一般用来开发测试,Standalone是Spark 自带的资源管理框架,Yarn和Mesos是另外两种资源管理框架,Spark用哪种模式部署,也就是使用了哪种资源管理框架
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
--------------------------------------------------
DAGScheduler, TaskScheduler.
Master:负责为运行在资源管理跨框架上的应用程序分配资源。
Worker:根据Cluster Manager的指令分配资源,执行应用程序,释放资源。
RDD:RDD是一个懒执行的不可变的可以支持Lambda表达式的并行数据集合。RDD的最大好处就是简单,API的人性化程度很高。RDD的劣势是性能限制,它是一个JVM驻内存对象,这也就决定了存在GC的限制和数据增加时Java序列化成本的升高。
DAG:DAG是一个有向无环图,在Spark中, 使用 DAG 来描述我们的计算逻辑。主要分为DAG Scheduler 和Task Scheduler。
Application:application是Spark API 编程的应用程序,它包括实现Driver功能的代码和在程序中各个executor上要执行的代码,一个application由多个job组成。其中应用程序的入口为用户所定义的main方法。
job:Job是Spark应用执行层次结构中的最高层元素。在Spark应用程序中,每个RDD的Action操作都对应一个Job。每个Job会被划分成一系列的Stage, Stage的数量依赖于发生过多少次shuffle操作。
stage:每个Job都被划分为一些较小的任务集(Task Set),这些任务集称为Stage。这些Stage相互依赖,从而形成一个Stage的DAG图(有向无环图)。
task:发送给Executor端执行的工作单元。每个RDD的分区对应一个Task,也就是说,触发任务执行的RDD有多少个分区就会创建多少个Task。Task的创建是在Driver端完成,而Task的执行在Executor端。Executor会创建一个线程池来执行Task,每个Task对应一个执行线程。
driver:Driver负责启动Spark应用,驱动应用的执行。它对Spark应用的整个执行过程进行管控,它是Spark应用程序的"master"(在Spark应用执行时,Driver端会启动很多服务的master端,这些服务的slave端运行在Executor上,这些服务的slave会向Driver端对应的master注册或汇报运行状态信息)。总的来说Driver需要完成以下几个方面的工作:
- 通过运行Spark应用的main函数来启动Spark应用;
- 向资源管理平台申请资源,并在Worker节点上启动Executor;
- 创建SparkSession(包括SparkContext和SparkEnv, SparkContext会和Cluster Manager进行交互,包括向它申请资源等),并对Spark应用进行规划,编排,最后提交到Executor端执行;
- 收集Spark应用的执行状态,并返回执行结果;
Cluster Manager:负责集群的资源管理和调度,为运行在资源管理框架上的应用程序分配资源。
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
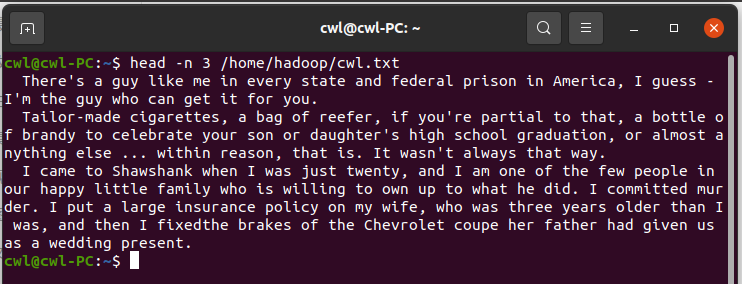
在/home/hadoop创建cwl.txt
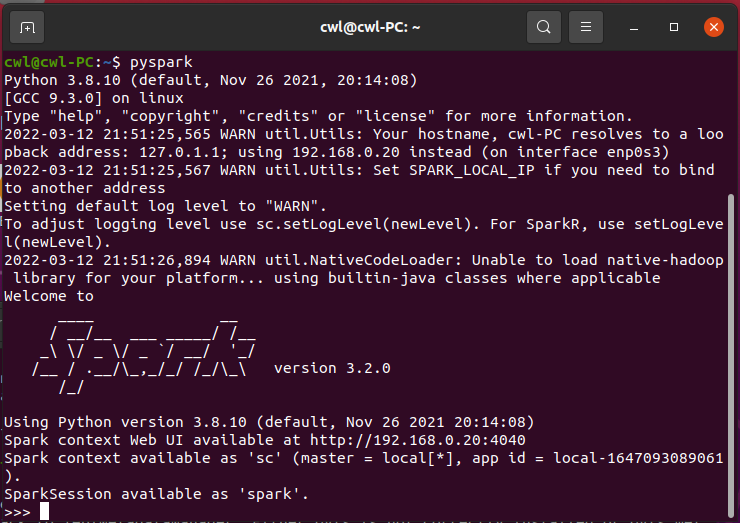
进入spark
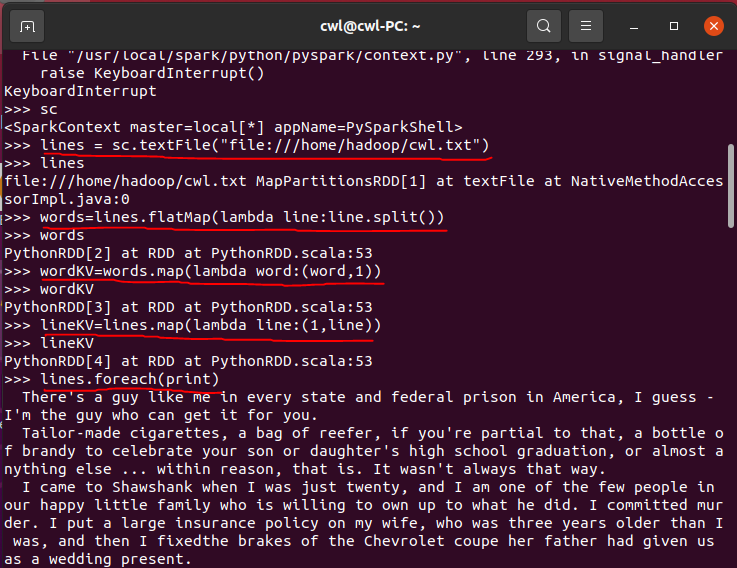
读取和输出文件
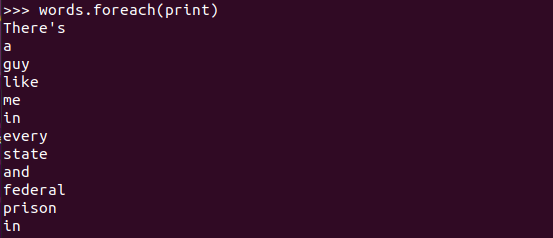
输出分词
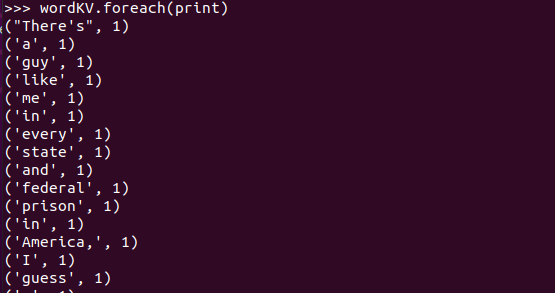
输出词频
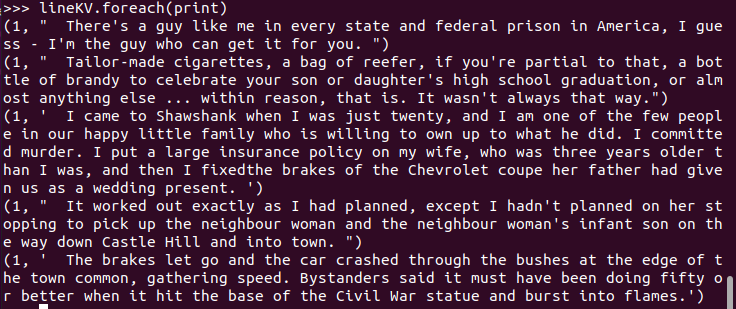
输出句频

 浙公网安备 33010602011771号
浙公网安备 33010602011771号