

20_精确率和召回率
1.分类模型的评估:
estimator.score():一般最常见使用的是准确率,即预测结果正确的百分比。
2.混淆矩阵:
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)。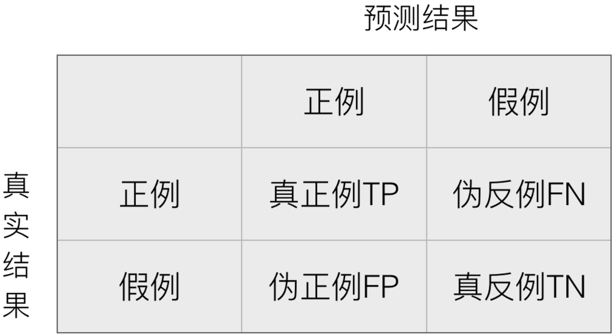
3.精确率和召回率:
精确率(precision):预测结果为正例,真实样例中为正例的比例。
预测结果为真,真实结果就是为真。
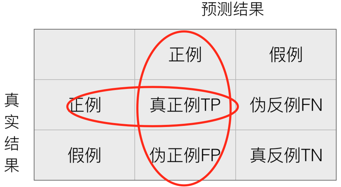
召回率(recall):真实为正例的样本中,预测结果为正例的的比例。
真实结果中出现了假的,就需要召回。

4.sklearn.metrics.classification_report:分类评估模型API
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值;
y_pred:估计器预测目标值;
target_names:目标类别名称;
return:每个类别精确率与召回率;
5.单词:
metrics:衡量指标。
"""
klearn20类新闻分类
20个新闻组数据集包含20个主题的18000个新闻组帖子
"""
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
def naviebayes():
news = fetch_20newsgroups()
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# 进行朴素贝叶斯的预测
mlt = MultinomialNB(alpha=1.0)
# print(x_train.toarray()) # toarray()作用,转为矩阵形式
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测文章的类别为:", y_predict)
print("准确率:", mlt.score(x_test, y_test))
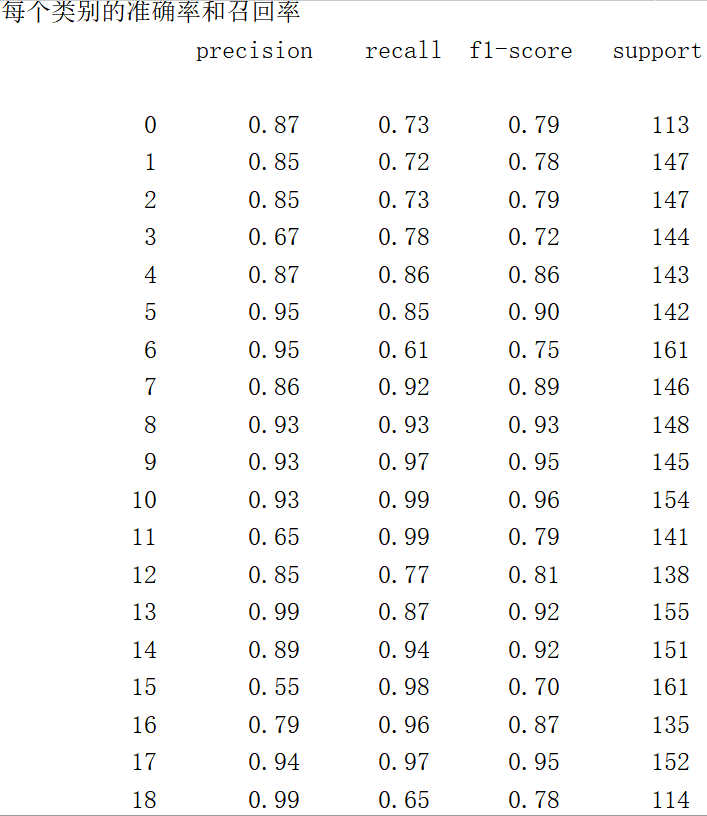
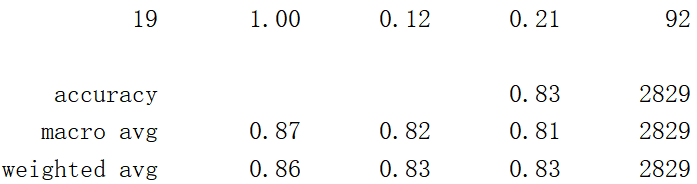
print("每个类别的准确率和召回率\n",classification_report(y_test,y_predict))
if __name__ == '__main__':
naviebayes()
print("每个类别的准确率和召回率\n",classification_report(y_test,y_predict))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号