

13_数据的划分和介绍之sklearn数据集
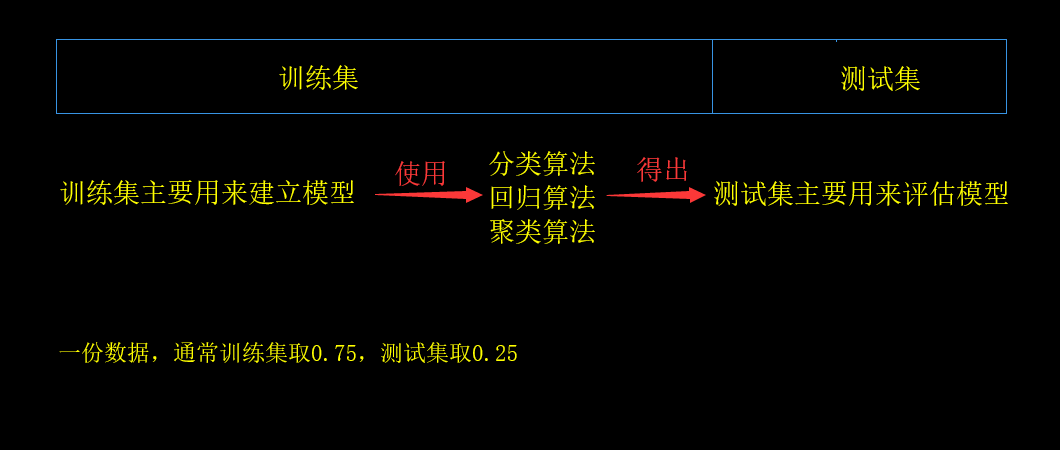
1.数据集是如何划分?训练数据和评估数据不能使用相同数据,不然自己测自己,会使得准确率虚高,在遇到陌生数据时,不够准确。
2.数据集的获取: 通过load或者fetch方法。
3.数据集进行分割:

训练集的数据分为特征值和目标值,测试集的数据也分为特征值和目标值,训练集中的x_test、测试集中的y_test、训练集中的x_train、测试集中的y_train。
训练集:x_train,y_train,分别表示训练集里面的特征值、目标值
测试集:x_test,y_test,分别表示测试集里面的特征值、目标值
注意返回格式:x_train , x_test, y_train , y_test = train_test_split(li.data,li.target,test_size=0.25)
print("训练集的特征值和目标值",x_train,y_train)
print("测试集的特征值和目标值",y_test,y_test)
案例1:鸢尾花(分类数据集,数据离散)
# 鸢尾花 from sklearn.datasets import load_iris li = load_iris() # 获取特征值 print(li.data) # 获取目标值 print(li.target) # 获取描述 print(li.DESCR)
获取描述信息:鸢尾花的属性,类别(属于那种鸢尾花)

鸢尾花的训练值和测试集
# 鸢尾花 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split li = load_iris() # # 获取特征值 # print(li.data) # # 获取目标值 # print(li.target) # # 获取描述 # print(li.DESCR) # # 数据集进行分割 # 注意返回值,训练集train x_train,y_train 测试集 test x_test,y_test x_train , x_test, y_train , y_test = train_test_split(li.data,li.target,test_size=0.25) print("训练集的特征值和目标值",x_train,y_train) print("测试集的特征值和目标值",y_test,y_test)
案例2:新闻组类别(分类数据集,数据离散)
subset='all':表示既获取训练数据,又获取测试数据。
from sklearn.datasets import fetch_20newsgroups news = fetch_20newsgroups(subset='all') print(news.data) print(news.target)
注:fetch_20newsgroups,会从网上下载大约14MB的数据集
案例3:波士顿房价(回归数据集,数据连续)
from sklearn.datasets import load_boston
lb = load_boston()
print("获取特征值")
print(lb.data)
print("获取目标值")
print(lb.target)
print("获取描述信息")
print(lb.DESCR)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号