
20194306 实验四 Python综合实践
学号 2019-2020-2 《Python程序设计》实验x报告
课程:《Python程序设计》
班级: 1943
姓名: 陈伟
学号:20194306
实验教师:王志强
实验日期:2020年6月14日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等
本次实践我选择做一个爬虫,爬取豆瓣网TOP250电影榜。
2. 实验过程及结果
import requests
from bs4 import BeautifulSoup
import pprint
page_indexs = range(0, 250, 25) # 构造分页数字列表
list(page_indexs)
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析(豆瓣网TOP250网址)
"""
htmls = []
for idx in page_indexs:
url = f"https://movie.douban.com/top250?start={idx}&filter="
print("craw html:", url)
r = requests.get(url,
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"})
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
return htmls
# 执行爬取
htmls = download_all_htmls()
htmls[0]
def parse_single_html(html):
"""
解析单个HTML,得到数据(四项数据:排名,电影名,评分,评价人数)
@return list({"link", "title", [label]})
"""
soup = BeautifulSoup(html, 'html.parser')
article_items = (
soup.find("div", class_="article")
.find("ol", class_="grid_view")
.find_all("div", class_="item")
)
datas = []
for article_item in article_items:
rank = article_item.find("div", class_="pic").find("em").get_text()
info = article_item.find("div", class_="info")
title = info.find("div", class_="hd").find("span", class_="title").get_text()
stars = (
info.find("div", class_="bd")
.find("div", class_="star")
.find_all("span")
)
rating_num = stars[1].get_text()
comments = stars[3].get_text()
datas.append({"排名":rank,"电影名":title,"评分":rating_num,"评价人数":comments.replace("人评价", "")})
return datas
#pprint.pprint(parse_single_html(htmls[0]))
all_datas = []
for html in htmls: #打印所得到的数据
list = parse_single_html(html)
all_datas.extend(list)
pprint.pprint(list)
all_datas
len(all_datas)
结果: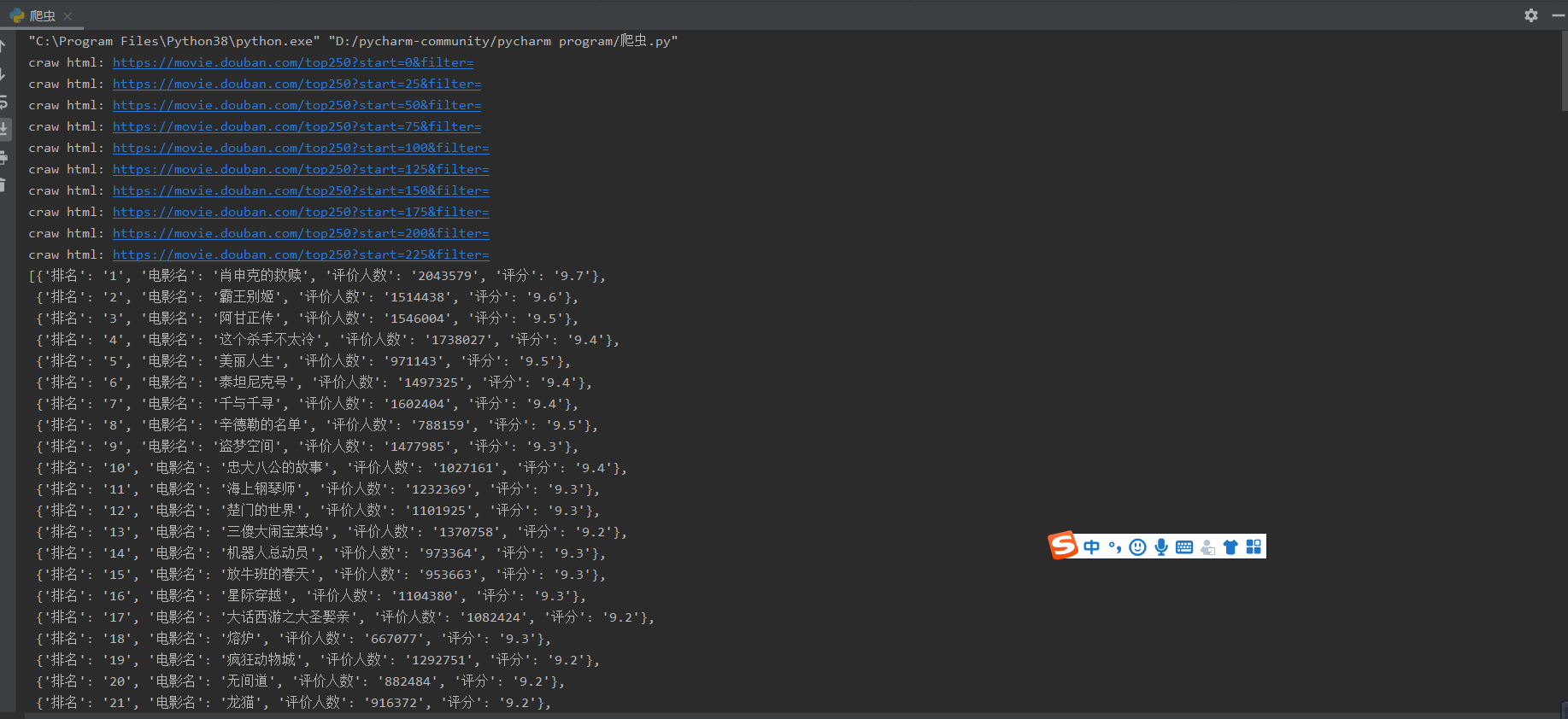
3. 实验过程中遇到的问题和解决过程
- 问题1:下载了requests库和bs4,却无法运用
- 问题1解决方案:从网上找到方法:在Pycharm的File - Settings - Project Interpreter页面,点击Add,,再点击System Interpreter,再重新选择一遍自己的环境变量即可;但方法失效,因为不清楚原因,我将python卸载重新安装,重新下载了requests库和bs4
其他(感悟、思考等)
这一个学期的学习,我对python有了更深的理解,python能实现很多事情,如果应用到生活上那将带来很多便利,但学习python也不是一件很容易的事,必须要每天学,并且多练多动手,才能更好地掌握python。这一学期我对python的学习只能说还可以,会设计最基础的爬虫,但同样,也有很多比如将数据(列表)写入文件,存入Excel表格是我还未掌握的。我相信在以后的不断学习中,我一定能学好python。
这学期老师讲的课很好,知识点讲解加上现场展示让人很容易就能听懂,在课后布置作业并且限时完成也可以让我们更快的掌握课上所学的内容,当然,如果老师在课上能多一点互动提问,在课下可以分享更多有趣的python代码就更好了

