Spark技术文档
Spark 源码解读
1. Spark调度模式-FIFO和FAIR
https://blog.csdn.net/dabokele/article/details/51526048
如果不加设置,jobs会提交到default调度池中。由于调度池的使用是Thread级别的,只能通过具体的SparkContext来设置local属性(即无法在配置文件中通过参数spark.scheduler.pool来设置,因为配置文件中的参数会被加载到SparkConf对象中)。所以需要使用指定调度池的话,需要在具体代码中通过SparkContext对象sc来按照如下方法进行设置:
sc.setLocalProperty("spark.scheduler.pool", "test")
设置该参数后,在该thread中提交的所有job都会提交到test Pool中。
如果接下来不再需要使用到该test调度池,
sc.setLocalProperty("spark.scheduler.pool", null)
http://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application
Scheduling Within an Application
http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
combineByKey函数需要传递三个函数做为参数,分别为createCombiner、mergeValue、mergeCombiner,需要理解这三个函数的意义
结合数据来讲的话,combineByKey默认按照key来进行元素的combine,这里三个参数都是对value的一些操作
1>第一个参数createCombiner,如代码中定义的是 : (v) => (v, 1)
这里是创建了一个combiner,作用是当遍历rdd的分区时,遇到第一次出现的key值,那么生成一个(v,1)的combiner,比如这里key为address,当遇到第一个
chaoyang,20 的时候,(v,1)中的v就是age的值20,1是address出现的次数
2>第2个参数是mergeValue,顾名思义就是合并value,如代码中定义的是:(accu: (Int, Int), v) => (accu._1 + v, accu._2 + 1)
这里的作用是当处理当前分区时,遇到已经出现过的key,那么合并combiner中的value,注意这里accu: (Int, Int)对应第一个参数中出现的combiner,即(v,1),注意类型要一致
那么(accu._1 + v, accu._2 + 1)就很好理解了,accu._1即使需要合并的age的值,而acc._2是需要合并的key值出现的次数,出现一次即加1
3>第三个参数是mergeCombiners,用来合并各个分区上的累加器,因为各个分区分别运行了前2个函数后需要最后合并分区结果.
ok,运行代码,结果如下,分别按照address来计算出age的平均值
tail -100 logs/spark-logs
https://stackoom.com/
2. Stream-Static Join
多数据源Join思路
多数据源Join大致有以下三种思路:
数据源端Join,如Android/IOS客户端在上报用户行为数据时就获取并带上用户基础信息。
计算引擎上Join,如用Spark Streaming、Flink做Join。
结果端Join,如用HBase/ES做Join,Join键做Rowkey/_id,各字段分别写入列簇、列或field。
三种思路各有优劣,使用时注意一下。这里总结在计算引擎Spark Streaming上做Join。
流与完全静态数据Join
流与完全静态数据Join。有两种方式,一种是RDD Join方式,另一种是Broadcast Join(也叫Map-Side Join)方式。
RDD Join 方式
思路:RDD Join RDD 。
Broadcast Join 方式
思路:RDD遍历每一条数据,去匹配广播变量中的值。
流与半静态数据Join
半静态数据指的是放在Redis等的数据,会被更新。
思路:RDD 每个Partition连接一次Redis,遍历Partition中每条数据,根据k,去Redis中查找v。
Stream-Stream Join
流与流Join。
思路:DStream Join DStream。
getOrElse()主要就是防范措施,如果有值,那就可以得到这个值,如果没有就会得到一个默认值,个人认为早开发过程中用getOrElse()方法要比用get()方法安全得多。
1、广播变量在Driver端定义
2、广播变量在Execoutor只能读取不能修改
3、广播变量的值只能在Driver端修改
4、不能将RDD广播出去,RDD不存数据,可以将RDD的结果广播出去,rdd.collect()
https://blog.csdn.net/wangpei1949/article/details/83892162
https://blog.csdn.net/u013013024/article/details/77877570
foreachPartition应该属于action运算操作,而mapPartitions是在Transformation中,所以是转化操作,此外在应用场景上区别是mapPartitions可以获取返回值,继续在返回RDD上做其他的操作,而foreachPartition因为没有返回值并且是action操作,所以使用它一般都是在程序末尾比如说要落地数据到存储系统中如mysql,es,或者hbase中,可以用它。
https://blog.csdn.net/u010454030/article/details/78897150
最后,需要注意一点,如果操作是iterator类型,我们是不能在循环外打印这个iterator的size,一旦执行size方法,相当于iterato就会被执行,所以后续的foreach你会发现是空值的,切记iterator迭代器只能被执行一次。
rdd.toDebugString
可以根据查看RDD的依赖:
但是执行的时候相当于走了两次流程,sum的时候前面计算了一遍,然后checkpoint又会计算一次,所以一般我们先进行cache然后做checkpoint就会只走一次流程,checkpoint的时候就会从刚cache到内存中取数据写入hdfs中,如下:
其中作者也说明了,在checkpoint的时候强烈建议先进行cache,并且当你checkpoint执行成功了,那么前面所有的RDD依赖都会被销毁,如下:
rdd.cache()
rdd.checkpoint()
rdd.collect
SparkContext的初始化(仲篇)——SparkUI、环境变量及调度
https://blog.csdn.net/beliefer/article/details/50720582
https://www.cnblogs.com/small-k/p/8909942.html
SparkStreaming在处理kafka中的数据时,存在一个kafka offset的管理问题:
官方的解决方案是checkpoint:
checkpoint是对sparkstreaming运行过程中的元数据和
每次rdds的数据状态保存到一个持久化系统中,当然这里面也包含了offset,一般是HDFS,S3,如果程序挂了,或者集群挂了,下次启动仍然能够从checkpoint中恢复,从而做到生产环境的7*24高可用。如果checkpoint存储做hdfs中,会带来小文件的问题。
但是checkpoint的最大的弊端在于,一旦你的流式程序代码或配置改变了,或者更新迭代新功能了,这个时候,你先停旧的sparkstreaming程序,然后新的程序打包编译后执行运行,会出现两种情况:
(1)启动报错,反序列化异常
(2)启动正常,但是运行的代码仍然是上一次的程序的代码。
https://spark.apache.org/docs/2.1.0/streaming-programming-guide.html#upgrading-application-code
Kafka带有提交偏移量的API,可将偏移量存储在一个特殊的Kafka主题中。
但这个容错语义是at least one,且Kafka不是事务性的,故障出现后会数据可能会重复。
如要实现at least one,要求SparkStreaming输出形式是幂等的。
幂等(idempotent、idempotence):
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
幂等函数:可以使用相同参数重复执行,并能获得相同结果的函数。
例如setTrue()就是一个幂等函数。
SparkStreaming有哪些输出是幂等的?
println不是幂等性的,因为我们看到了重复打印
数据按Key写Redis是幂等性的,重复写结果相同
数据按RowKey写HBase是幂等性的,重复写结果相同
————————————————
版权声明:本文为CSDN博主「小基基o_O」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Yellow_python/article/details/119864718
ds.foreachRDD { rdd =>
// 1、获取偏移量(如果有)
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 2、处理数据并输出结果
// 3、输出结果成功后,异步提交偏移量
ds.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
3. flink
<properties>
<flink.version>1.10.0</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<kafka.version>2.2.0</kafka.version>
</properties>
4.分析
方差是衡量源数据和期望值相差的度量值。
标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同
标准差、方差越大,离散程度越大
Pearson相关系数(Pearson Correlation Coefficient)是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。
偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。偏度(Skewness)亦称偏态、偏态系数。
峰度(Kurtosis)与偏度类似,是描述总体中所有取值分布形态陡缓程度的统计量。这个统计量需要与正态分布相比较,峰度为0表示该总体数据分布与正态分布的陡缓程度相同;峰度大于0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;峰度小于0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大。
例如上图中,左图是标准正太分布,峰度=3,右图的峰度=4,可以看到右图比左图更高尖。
通常我们将峰度值减去3,也被称为超值峰度(Excess Kurtosis),这样正态分布的峰度值等于0,当峰度值>0,则表示该数据分布与正态分布相比较为高尖,当峰度值<0,则表示该数据分布与正态分布相比较为矮胖。
Phoenix的二级索引主要有两种,即全局索引和本地索引。全局索引适合那些读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。本地索引适合那些写多读少,或者存储空间有限的场景。
索引定义完之后,一般来说,Phoenix会判定使用哪个索引更加有效。但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。
5. 快捷键
ctrl+shift+A: 使用IDEA, 你需要记住的是action,而不是快捷键. 例如我想要打开设置界面,那么 ctrl+shift+A,然后输入setting,第一个候选action就是settings(同时你可以看到打开settings的快捷键是ctrl+alt+S); 如果你想要复制当前行,那么ctrl+shift+A,输入dupl就可以看到duplicate line. 下次你就知道复制行是ctrl+D, 当然,这对英语和编程短语要求有些高,实际上,你也可以搜索 edit code actions, 回车, 这时会弹出你可以对当前行操作的action,第三个就是duplicate line. 这时你懂了吧, 只要搜索你的意图,大概清楚你想要的操作是属于哪个类型,然后搜索这个类型单词即可. 或者你可以直接搜索actions, 熟悉这些actions的分类,这样你就可以慢慢熟悉自己最常用的快捷键了.
alt+Home/ ctrl+E: 初学者会习惯用鼠标在project窗口选择文件,这样效率很低. IDEA提供了很好的文件导航,就在工具栏下方,alt+Home即可激活导航,然后你可以用方向键移动浏览每个文件夹的文件,回车进入某个文件夹,然后alt+Ins,即可新建文件(包括class,package). 当然你也可以用ctrl+E 打开最近操作的文件,包括terminal.
上一个位置: 这个是我在eclipse中常用的快捷键. 在IDEA中是: ctrl+alt+ 方向键. 注意,这个是上一次光标的位置,不是编辑的位置,所以可能需要你习惯. 此外, alt+左右方向是编辑窗口tab切换.
search everywhere vs find in path: 如果你想要搜索一个类或者接口, 双击shift,激活 search everywhere, 但是不会搜索普通文本的, 如果你使用mybatis, 想要搜索xml的sql,那么你需要使用ctrl+shift+F,叫find in path, 当然搜索的范围越大,结果就越多, 所以只有在search everywhere不行的时候才使用find in path.
zen mode: ctrl+shift+F12, 就是editor窗口最大化的意思啦,全心开始码吧...
refactor this: ctrl+shift+alt+T, 重构,可以这么说,新手使用这个快捷键频率体现了你代码的水平, 只用重构越多,代码水平才可能提高,如果你从来没用过,你不是在写代码,只是. 记不住这个快捷键没关系, ctrl+shift+A ,然后输入refactor就出来了.
有一个很好的gif教程:
你需要学会使用以下功能
方法执行: Alt + F8;
条件断点: 断点上右键即可;
日志断点: 不要再傻傻的用sysout或者http://log.info去记录一些调试日志啦.调试完你还要删除代码. 请用日志断点.当然, idea 专业版提供而来很好的热更新功能,修改代码后可以直接更新web容器的代码.
方法断点: 如果你只对某个方法的入参和返回值感兴趣, 那么不要浪费时间在单步调试一步步走完这个方法, 只要在方法名那一行断点. 方法断点是一个红色里面四个黑点的标识.
异常断点: 如果你想在异常抛出时停下来,那么使用 Run -> View BreakPoints -> add breakPoint
变量断点: 在并发程序中你不知道那个线程或者方法修改了某个变量,这时你可以对变量声明处断点,并右键设置.例如,变量修改时停下来.
还有更多debug技能需要你去发现,都在Run -> View Breakpoint里.
F9:恢复程序
Alt+F10:显示执行断点
F8: 跳到下一步
F7:进入到代码
Alt+shift+F7:强制进入代码
Shift+F8:跳到下一个断点
Atl+F9:运行到光标处
ctrl+shift+F9:debug运行java类
ctrl+shift+F10:正常运行java类
Alt+F8:debug时选中查看值
Alt + Ctrl + S 打开Settings
Alt + Ctrl + Shift + S 打开Project Structrue
Alt + Enter 快速修复
Alt + / 单词自动补全
Alt + Insert 代码自动生成,比如setter、getter、toString等等
Alt + Shift + V 把类中成员移动到另一个类
Ctrl + Shift + F 格式化代码
Ctrl + Shift + U 大小写切换
Ctrl + Shift + I 根据当前上下文显示代码定义,比如:光标停在方法上就会以popupview方式显示该方法的定义
Ctrl + click 跳到源码
Shift + Shift 搜索所有文件
Ctrl + E 打开最近访问文件列表
实际开发中我会结合IDEA的postfix completion和aiXcoder配置使用,IDEA本身就已经提供了许多快速补全的快捷方式,不过我发现组内很多人并没有真正用起来。
Restfultoolkit一套RESTful服务开发辅助工具集,维护项目通常会涉及到查找一个请求所对应的类,一般用ctrl + shift + f进行全局搜索,但是如果项目文件太多,这种查找方式的效率就很低。
Restfultoolkit管理项目中全部的请求链接,可以快速查找。
快捷键:ctrl+ alt + n
可以复制当前请求的全路径和JSON格式的参数,开发测试中非常的实用。
6. 缓存
如何释放cache缓存:unpersist,它是立即执行的。persist是lazy级别的(没有计算),unpersist是eager级别的。RDD cache的生命周期是application级别的,也就是如果不显示unpersist释放缓存,RDD会一直存在(虽然当内存不够时按LRU算法进行清除),如果不正确地进行unpersist,让无用的RDD占用executor内存,会导致资源的浪费,影响任务的效率。
https://blog.csdn.net/qq_27639777/article/details/82319560
7.模块列表
源码阅读
Spark至今只经历过1.x、2.x和3.x三个大版本的变化,在核心实现上,我们在Github能看到的最早的实现是0.5版本,这个版本只有1万多行代码,就把Spark的核心功能实现了。
当然我们不可能从这么古老的版本看,假如你接触过Spark,现在准备看源码,那么我建议从2.x版本中选取一个,最好是2.3或者2.4。但是经过如此多的迭代,Spark的代码量已经暴增了几倍。关于Spark3.x中的新增功能和优化例如动态资源分配,可以针对性的进行补充即可。
我把最重要的模块列表如下:
Spark的初始化
SparkContext SparkEnv SparkConf RpcEnv SparkStatusTracker SecurityManager SparkUI MetricsSystem TaskScheduler
Spark的存储体系
SerializerManager BroadcastManager ShuffleManager MemoryManager NettyBlockTransferService BlockManagerMaster BlockManager CacheManager
Spark的内存管理
MemoryManager MemoryPool ExecutionMemoryPool StorageMemoryPool MemoryStore UnifiedMemoryManager
Spark的运算体系
LiveListenerBus MapOutputTracker DAGScheduler TaskScheduler ExecutorAllocationManager OutputCommitCoordinator ContextClearner
Spark的部署模式
LocalSparkCluster Standalone Mater/Executor/Worker的容错
Spark Streaming
StreamingContext Receiver Dstream 窗口操作
Spark SQL
Catalog TreeNode 词法解析器Parser RuleExecutor Analyzer与Optimizer HiveSQL相关
其他
假如你对图计算Spark GraphX和机器学习Spark MLlib感兴趣,可以单独看看。
一些可以直接入门的项目
我曾经发过一些可以直接入门的项目,大家可以参考:
这里就不得不说B站了,你可以在B站找到非常丰富的学习资源,甚至我自己也曾经上传过关于Spark的项目。
我这里找了一个不错的入门视频:https://www.bilibili.com/video/BV1tp4y1B7qd
另外下面这篇文章也是一个完整的入门案例:
《Spark Streaming + Canal + Kafka打造Mysql增量数据实时进行监测分析》
8.Kafka
创建了AdminClient的实例对象后,我们就可以通过它提供的方法操作Kafka,常用的方法如下:
方法名称
作用
createTopics 创建一个或多个Topic
listTopics 查询Topic列表
deleteTopics 删除一个或多个Topic
describeTopics 查询Topic的描述信息
describeConfigs 查询Topic、Broker等的所有配置项信息
alterConfigs 用于修改Topic、Broker等的配置项信息(该方法在新版本中被标记为已过期)
incrementalAlterConfigs 同样也是用于修改Topic、Broker等的配置项信息,但功能更多、更灵活,用于代替alterConfigs
createPartitions 用于调整Topic的Partition数量,只能增加不能减少或删除,也就是说新设置的Partition数量必须大于等于之前的Partition数量
Tips:
describeTopics和describeConfigs的意义主要是在监控上,很多用于监控Kafka的组件都会使用到这两个API,因为通过这两个API可以获取到Topic自身和周边的详细信息
https://blog.51cto.com/zero01/2495884
InterfaceAudience 类包含有三个注解类型,用来说明被他们注解的类型的潜在使用范围,即audience
1.如果标注的是Public,说明被注解的类型对多有工程和应用可用。
2.如果标注的是LimitedPrivate,说明被注解的类型只能用于某些特定的工程或应用,如Common,HDFS,MapReduce,ZooKeeper,HBase等。
3.如果标注的是Private,说明被注解的类型只能用于Hadoop。
InterfaceStability 类包含三个注解,用于说明被他们注解的类型的稳定性。
@InterfaceStability.Evolving
1.如果标注的是Stable,说明主版本是稳定的,不同主版本之间可能不兼容。
2.如果标注的是Evolving,说明是不停在变化的,不同小版本之间也可能不兼容。
3.如果标注的是Unstable,说明稳定性没有任何保证。
Partition的索引从0开始,所以第一个partition=0,第二个partition=1
在创建Topic时我们需要设定Partition的数量,但如果觉得初始设置的Partition数量太少了,那么就可以使用createPartitions方法来调整Topic的Partition数量,但是需要注意在Kafka中Partition只能增加不能减少。
https://www.jianshu.com/p/5bdd9a0d7d02
Kafka-Eagle 安装到使用全教程
https://www.jianshu.com/p/2ebfad402fa0
https://www.cnblogs.com/zeling/p/8494851.html
https://ke.smartloli.org/
https://blog.csdn.net/Locky_LLL/article/details/104840827
http://node1:8048/ke 初始用户名:admin 密码:123456
https://blog.csdn.net/hell_oword/article/details/120111230
http://192.168.3.66:8048/ke/account/signin?/ke/
初始用户名:admin 密码:123456
select * from "ke_topic" where "partition" in (0,1,2) limit 10;
select * from "hs_spin" where "partition" in (0,1,2) limit 10;
前几天为了省事,在申请group的时候,就使用了原来的group,本来以为group从属于某一个topic,topic不同,group之间相互不会影响,但实际情况不是这样的。
kafka不同topic的consumer如果用的groupid名字一样的情况下,其中任意一个topic的consumer重新上下线都会造成剩余所有的consumer产生reblance行为,
即使大家不是同一个topic,这主要是由于kafka官方支持一个consumer同时消费多个topic的情况,所以在zk上一个consumer出问题后zk是直接把group下面所有的consumer都通知一遍
earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
最近也是有人问我kafka的auto.offset.reset设置为earliest后怎么结果和自己想象的不一样呢,相信很多人都对这个参数心存疑惑,今天来详细讲解一下:
kafka-0.10.1.X版本之前: auto.offset.reset 的值为smallest,和,largest.(offest保存在zk中)
kafka-0.10.1.X版本之后: auto.offset.reset 的值更改为:earliest,latest,和none (offest保存在kafka的一个特殊的topic名为:__consumer_offsets里面)
顾名思义,earliest就是从最开始消费数据,latest即为从最新的数据开始消费,但我们在使用的时候发现并不是这样的.下面就来详细测试一下.
先看一下官网对auto.offset.reset的解释吧(测试版本为0.10.2.1)
如果存在已经提交的offest时,不管设置为earliest 或者latest 都会从已经提交的offest处开始消费
如果不存在已经提交的offest时,earliest 表示从头开始消费,latest 表示从最新的数据消费,也就是新产生的数据.
none topic各分区都存在已提交的offset时,从提交的offest处开始消费;只要有一个分区不存在已提交的offset,则抛出异常
show processlist 命令非常实用,有时候mysql经常跑到50%以上或更多,就需要用这个命令看哪个sql语句占用资源比较多,就知道哪个网站的程序问题了。
show processlist 命令的输出结果显示了有哪些线程在运行,可以帮助识别出有问题的查询语句;如果有SUPER权限,则可以看到全部的线程,否则,只能看到自己发起的线程(这是指当前对应的MySQL帐户运行的线程)。
先简单说一下各列的含义和用途
第一列,id,不用说了吧,一个标识,你要kill一个语句的时候很有用
user列,显示单前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。
host列,显示这个语句是从哪个ip的哪个端口上发出的。呵呵,可以用来追踪出问题语句的用户。
db列,显示这个进程目前连接的是哪个数据库。
command列,显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。
time列,此这个状态持续的时间,单位是秒。
state列,显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成
info列,显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是这是一个判断问题语句的重要依据。
————————————————
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table
正在检查数据表(这是自动的)。
Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out
复制从服务器正在连接主服务器。
Copying to tmp table on disk
由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
Creating tmp table
正在创建临时表以存放部分查询结果。
deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。
deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
Flushing tables
正在执行FLUSH TABLES,等待其他线程关闭数据表。
Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。
Locked
被其他查询锁住了。
Sending data
正在处理Select查询的记录,同时正在把结果发送给客户端。
Sorting for group
正在为GROUP BY做排序。
Sorting for order
正在为ORDER BY做排序。
Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执Alter TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。
Removing duplicates
正在执行一个Select DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。
Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
Repair by sorting
修复指令正在排序以创建索引。
Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。
Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在Update要修改相关的记录之前就完成了。
Sleeping
正在等待客户端发送新请求.
System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加--skip-external-locking参数来禁止外部系统锁。
Upgrading lock
Insert DELAYED正在尝试取得一个锁表以插入新记录。
Updating
正在搜索匹配的记录,并且修改它们。
User Lock
正在等待GET_LOCK()。
Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, Alter TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。
waiting for handler insert
Insert DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。
大部分状态对应很快的操作,只要有一个线程保持同一个状态好几秒钟,那么可能是有问题发生了,需要检查一下。还有其他的状态没在上面中列出来,不过它们大部分只是在查看服务器是否有存在错误是才用得着。
常用计数器
————————————————
版权声明:本文为CSDN博主「盛艺小豆丁」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_33814090/article/details/113207648
show 后面的参数可以更改用来查看不同的数据,通过show profiles来觉得自己需要查看那个语句。
参数 功能
all 显示所有的开销信息
block io 显示块IO相关开销
cpu 显示CPU相关开销信息
ipc 显示发送和接收相关开销信息
memory 显示内存相关开销信息
page faults 显示页面错误相关开销信息
————————————————
版权声明:本文为CSDN博主「夕麻」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45735361/article/details/104115116
参数注意
converting HEAP to MyISAM查询结果太大,内存都不够用了往磁盘上搬
Creating tmp table 创建临时表
Copying to tmp table on disk 把内存中临时表复制到磁盘,危险
locked
show profile cpu,block_io for query 3
测试环境可以开启:
全局查询日志
开启命令
set global general_log = 1;
1
将SQL语句写到表中
set global log_output = 'TABLE';
1
我们所编写的SQL语句,会记录到MySQL库里的genral_log表,我们可通过下述语句来查看
select * from mysql.general_log;
9. log4j 日志输出级别
log4j定义了8个级别的log(除去OFF和ALL 可以说分为6个级别),
* 优先级从高到低依次为:OFF FATAL ERROR WARN INFO DEBUG TRACE ALL
*
* ALL 最低等级的 用于打开所有日志记录
* TRACE 很低的日志级别 一般不会使用
* DEBUG 指出细粒度信息事件对调试应用程序是非常有帮助的 主要用于开发过程中打印一些运行信息
* INFO 消息在粗粒度级别上突出强调应用程序的运行过程
* 打印一些你感兴趣的或者重要的信息 这个可以用于生产环境中输出程序运行的一些重要信息
* 但是不能滥用 避免打印过多的日志
* WARN 表明会出现潜在错误的情形 有些信息不是错误信息 但是也要给程序员的一些提示
* ERROR 指出虽然发生错误事件 但仍然不影响系统的继续运行
* 打印错误和异常信息 如果不想输出太多的日志 可以使用这个级别
* FATAL 指出每个严重的错误事件将会导致应用程序的退出
* 这个级别比较高了 重大错误 这种级别你可以直接停止程序了
* OFF 最高等级的,用于关闭所有日志记录
*
* 如果将log level设置在某一个级别上 那么比此级别优先级高的log都能打印出来
* 例如 如果设置优先级为WARN 那么OFF FATAL ERROR WARN 4个级别的log能正常输出
* 而INFO DEBUG TRACE ALL级别的log则会被忽略
10.dbeaver常用快捷键
hot key
ctrl + enter 执行sql
ctrl + \ 执行sql,保留之前窗口结果
ctrl + shift + ↑ 向上复制一行
ctrl + shift + ↓ 向下复制一行
ctrl + alt + F 对sql语句进行格式化,对于很长的sql语句很有用
ctrl + d 删除当前行
alt + ↑ 向上选定一条sql语句
alt + ↓ 向下选定一条sql语句
ctrl + / 行注释
ctrl + shift+ / 块注释
ctrl + f 查找、替换
ctrl + space sql提示(如果写了from table后也会自动提示field)
ctrl + shift + E 执行计划
ctrl + shift + U 将选定的sql转换成大写字母
ctrl + shift + L 将选定的sql转换成小写字母
————————————————
版权声明:本文为CSDN博主「ronaldo2018」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sinat_17697111/article/details/88800616
【hive】求日期是星期几
在Hive原生版本中,目前并没有返回星期几的函数。
除了利用java自己编写udf外,也可以利用现有hive函数实现。
方法格式:
pmod(datediff('#date#', '任意年任意一个星期日的日期'), 7)
1、datediff 是两个日期相减的函数,hive日期函数可以见附录:
日期相减函数:datediff
语法:datediff(string enddate, string startdate)
返回值: int
说明: 返回两个时间参数的相差天数。
2、 pmod 是正取余函数:
正取余函数 : pmod
语法: pmod(int a, int b),pmod(double a, double b)
返回值: int double
说明: 返回正的a除以b的余数
如:2012-01-01刚好是星期日。
pmod(datediff('#date#', '2012-01-01'), 7)
返回值:int,“0-6”(“0-6”分别表示“星期日-星期六”)
注意:这里的日期必须是'string'类型的格式为'yyyy-MM-dd',因为datediff()函数对参数的要求
补充:当后边的日期不是周日的时候,我们可以对datediff结果进行加减到周日即可
例如:2018-01-01是周一,我们可以在datediff基础上+1/-6.
为什么是周一要+1呢,因为对于一整周的时间是少了一天.
变通一下,一样可以达到相同的目的:
select pmod(datediff('2018-06-04', '2018-01-01') - 6, 7);
select pmod(datediff('2018-06-04', '2018-01-01') + 1, 7);
附赠:bigint类型的日期转换成string(yyyy-MM-DD)类型的日期
from_unixtime(unix_timestamp(cast(20180707 as string),'yyyymmdd'),'yyyy-mm-dd')
20180707 -> '2018-07-07'
-- hive 求某一天是星期几
select htime,
(case when pmod(datediff(htime,'2018-01-01') + 1,7) = 1 then 'Monday'
when pmod(datediff(htime,'2018-01-01') + 1,7) = 2 then 'Tuesday'
when pmod(datediff(htime,'2018-01-01') + 1,7) = 3 then 'Wednesday'
when pmod(datediff(htime,'2018-01-01') + 1,7) = 4 then 'Thursday'
when pmod(datediff(htime,'2018-01-01') + 1,7) = 5 then 'Friday'
when pmod(datediff(htime,'2018-01-01') + 1,7) = 6 then 'Saturday'
else 'Weekend'
end) time_interval
from
hs_spin.ods_wide_host_external limit 6;
count(...) over(partition by ... order by ...)--求分组后的总数。
sum(...) over(partition by ... order by ...)--求分组后的和。
max(...) over(partition by ... order by ...)--求分组后的最大值。
min(...) over(partition by ... order by ...)--求分组后的最小值。
avg(...) over(partition by ... order by ...)--求分组后的平均值。
rank() over(partition by ... order by ...)--rank值可能是不连续的。
dense_rank() over(partition by ... order by ...)--rank值是连续的。
first_value(...) over(partition by ... order by ...)--求分组内的第一个值。
last_value(...) over(partition by ... order by ...)--求分组内的最后一个值。
lag() over(partition by ... order by ...)--取出前n行数据。
lead() over(partition by ... order by ...)--取出后n行数据。
ratio_to_report() over(partition by ... order by ...)--Ratio_to_report() 括号中就是分子,over() 括号中就是分母。
percent_rank() over(partition by ... order by ...)-- 计算当前行所在前百分位
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-versions) on project apache-atlas: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :apache-atlas
可能会角色里面的message信息有点奇怪,这是我改之后的结果,原本的情况是:
requireJavaVersion 要求jdk8-151 以上才行
requireMavenVersion 要求在3.5.0 以上
因此,我们编译的maven版本和jdk版本要在其要求范围内,这样就不会报这个插件错误了(事实上,我这里修改是有点画蛇添足,但是直接指定也行)。
下载安装JDK。(不要用Linux自带的jdk,且atlas2.0要求,jdk版本最好1.8.0_151以上)。
下载安装Maven(atlas2.0版本最低要求3.6.0)。
安装Python环境(Linux下自带Python环境,可忽略)
下载Apache Atlas
官网链接:http://atlas.apache.org/#/Downloads
我这里下载的是2.0.0
————————————————
版权声明:本文为CSDN博主「Y_尘」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Y_anger/article/details/105514126
浏览器访问localhost:21000。等几分钟可出现登录界面。
用户名:admin
密码:admin
11.spark 任务添加外部依赖包
依赖包放这个目录下 spark on yarn:
/opt/spark/spark-2.1.1-bin-hadoop2.6/jars
mkdir -p /opt/external_jars
ln -s /opt/external_jars /opt/spark/spark-2.1.1-bin-hadoop2.6/jars/external_jars
具体操作如下:
(1)新建目录
mkdir -p /opt/external_jars
(2)上传依赖包
XXX
(3)建立软链接
ln -s /opt/external_jars /opt/spark/spark-2.1.1-bin-hadoop2.6/jars/external_jars
ln -s /opt/external_jars $SPARK_HOME/jars/external_jars
(4)执行任务即可
xxx
注意:$SPARK_HOME 为spark安装目录
--jars
ln -s /home/gamestat /gamestat
rm -rf b 注意不是rm -rf b/
mkdir -p /opt/external_jars
ln -s /opt/external_jars /usr/lib/hadoop-hdfs/lib/external_jars
ln -s /opt/external_jars /usr/lib/hadoop-yarn/lib/external_jars
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/external_jars/*
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/external_jars/*
spark-submit --class ezviz.bigdata.spark.OfflineJob --master yarn --deploy-mode cluster --queue azkaban --name antarmy_XP_one_day_data --driver-memory 2G --executor-memory 10G --executor-cores 3 --num-executors 10 --conf spark.driver.extraJavaOptions=" -Dfile.encoding=utf-8 " --conf spark.executor.extraJavaOptions=" -Dfile.encoding=utf-8 " --conf spark.yarn.jars=local:/opt/cloudera/parcels/CDH/lib/spark/jars/*,local:/opt/cloudera/parcels/CDH/lib/spark/hive/*:/opt/cloudera/parcels/CDH/lib/hive/lib/* --conf spark.sql.parquet.compression.codec=gzip --conf spark.shuffle.consolidateFiles=true EzBigdataFramework-1.0-SNAPSHOT-shaded.jar "/user/antarmy/antarmy_xp_one_day_data.conf"
--conf spark.yarn.jars=local:/opt/external_jars/* --conf spark.sql.parquet.compression.codec=gzip --conf spark.shuffle.consolidateFiles=true EzBigdataFramework-1.0-SNAPSHOT-shaded.jar
spark.driver.extraClassPath /opt/external_jars/*
git add 添加了多余文件
git add . 表示当前目录所有文件,不小心就会提交其他文件
git add 如果添加了错误的文件的话
撤销操作
git status 先看一下add 中的文件
git reset HEAD 如果后面什么都不跟的话 就是上一次add 里面的全部撤销了
git reset HEAD XXX.py 就是对某个py文件进行撤销了
git reset HEAD file 即使对file文件夹进行撤销
12.Hbase
truncate_preserve 'hs_spin:ods_ext_item_origin'
describe 'hs_spin:ods_ext_item_origin'
count 'hs_spin:ods_ext_item_origin'
--disable 'tablename'
--drop 'tablename'
--
--
--DROP TABLE "hs_spin"."wh_wide_t1";
A>B and A>C
B>A and B>C
C
1,2,3
-- ELECT b.column_name column_name --字段名
--,b.data_type data_type --字段类型
--,b.data_length --字段长度
--,a.comments comments --字段注释
--FROM user_col_comments a
--,all_tab_columns b
--WHERE a.table_name = b.table_name and
--a.table_name = 'table_name';
select * from "hs_spin"."hive_hbase_test";
select * from "test"."hive_hbase_test";
--use "test"
create table "test"."hive_hbase_test" (
"ROW" VARCHAR PRIMARY KEY,
"f"."id" VARCHAR,
"f"."name" VARCHAR,
"f"."age" VARCHAR);
CREATE SCHEMA IF NOT EXISTS "ns_hs_flink";
/*
CREATE VIEW IF NOT EXISTS "ns_hs_flink"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
);
CREATE TABLE IF NOT EXISTS "ns_hs_flink"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
) column_encoded_bytes=0;--禁用列映射
*/
0000074d93654e3e836c4be4a9b34712
SELECT min(a."crt"),max(a."crt") from "hs_spin"."ods_min_yield_val" a;
CREATE TABLE "hs_spin"."pictures"(
"ROW" VARCHAR PRIMARY KEY,
"f1"."content" VARCHAR,
"f1"."filename" VARCHAR,
"f1"."filesize" VARCHAR,
"f1"."filesplits" VARCHAR);
/*
desc "hs_spin:ods_min_yield_val"
scan "hs_spin:ods_min_yield_val" ,{LIMIT=>6}
scan "hs_spin:ods_min_yield_val" ,{LIMIT=>2}
scan "hs_spin:ods_min_yield_val", {COLUMNS => 'f',LIMIT=>3}
scan "hs_spin:ods_yeid_data" ,{LIMIT=>2}
import org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
import org.apache.hadoop.hbase.filter.RowFilter
scan 'hs_spin:dwd_min_yield_val','1435183125@2404213781392523265@20210716170001', {LIMIT=>1}
scan 'hs_spin:dwd_min_yield_val', {LIMIT=>1}
get 'hs_spin:dwd_min_yield_val','1435183125@2404213781392523265@20210716170001'
get 'hs_spin:ods_wide_host','6440379923955687632@2021-07-27 08:00:00'
get 'hs_spin:ods_wide_host','4478282144964194612@2021-07-27 04:00:00'
get 'hs_spin:ods_wide_host','8290000109709697632@20210727080000'
count 'hs_spin:ods_wide_host'
import org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
import org.apache.hadoop.hbase.filter.RowFilter
import org.apache.hadoop.hbase.filter.RegexStringComparator
scan 'hs_spin:dwd_min_yield_val',{FILTER => RowFilter.new(CompareFilter::CompareOp.valueOf('EQUAL'), SubstringComparator.new('20210716170001')),LIMIT=>1}
scan 'hs_spin:data_item_val',{FILTER => RowFilter.new(CompareFilter::CompareOp.valueOf('EQUAL'), SubstringComparator.new('1441341441')),LIMIT=>1}
scan 'hs_spin:data_item_val',{FILTER => RowFilter.new(CompareFilter::CompareOp.valueOf('EQUAL'), RegexStringComparator.new(".*1441341441.*")),LIMIT=>1}
scan 'hs_spin:data_item_val',{STARTROW=>'1441341441',STOPROW=>'1441341441z',LIMIT=>10}
scan 'hs_spin:data_item_val_cp',{STARTROW=>'1441341441',STOPROW=>'1441341441z',LIMIT=>10}
scan 'hs_spin:data_item_val',{STARTROW=>'1444390914',STOPROW=>'1444390914z',LIMIT=>10}
scan 'hs_spin:data_item_val',{STARTROW=>'1441598501',STOPROW=>'1441598501z',LIMIT=>10}
scan 'hs_spin:data_item_val',{STARTROW=>'1444390914@YLXS030',STOPROW=>'1444390914z',LIMIT=>10}
scan 'hs_spin:data_item_val',{STARTROW=>'1444390914@YLXS030',STOPROW=>'1444390914z',LIMIT=>10}
scan 'hs_spin:data_item_val',{STARTROW=>'1444390914@YLXS030@202108090759',STOPROW=>'1444390914z',LIMIT=>10}
YLXS030
1444390914
202108090759
scan 'test1', {FILTER => RowFilter.new(CompareFilter::CompareOp.valueOf('EQUAL'), SubstringComparator.new('ts3'))}
ROW COLUMN+CELL
user1|ts3 column=sf:s1, timestamp=1409122354954, value=sku123
scan "hs_spin:ods_spin_host" ,{LIMIT=>1}
scan "hs_spin:ods_wide_host" ,{LIMIT=>1}
put 'hs_spin:ods_wide_host', '0005670556180797632@2020-09-25', 'f_data:htime', '时间'
get 'hs_spin:ods_wide_host', '0005670556180797632@2020-09-25'
get 'hs_spin:ods_wide_host', '0005670556180797632@2020-09-25'
deleteall 'tableName','rowkey' —— 根据rowkey删除表
deleteall 'hs_spin:ods_wide_host', '0005670556180797632@2020-09-25'
deleteall 'hs_spin:ods_wide_host', '2021-07-17'
put 'hs_spin:ods_wide_host', 'r1', 'c1', 'value'
> alter 'Rumenz','depart'
alter 'hs_spin:ods_wide_host','f_data'
> alter 'Rumenz','delete'=>'depart'
// 表名 rowkey 列族:字段名 值
> put 'Rumenz','001','user:name','入门小站'
> put 'Rumenz','001','user:type','1'
//Hbase中表没有rename操作
//1.禁止表插入
> disable 'Rumenz'
//2.制作快照
> snapshot 'Rumenz','RumenzShot'
//3.克隆快照为新名字
> clone_snapshot 'RumenzShot','RumenzNew'
//4.删除快照
> delete_snapshot 'RumenzShot'
//5.删除原表
> drop 'Rumenz'
> desc 'RumenzNew'
scan 'test_table', FILTER=>"ValueFilter(=,'binary:侠梦的开发笔记')"
scan 'hs_spin:data_item_val_cp',{COLUMNS => ['f:devid','f:val'],FILTER=>"ValueFilter(=,'binary:YLXS030')",LIMIT=>3}
scan 'hs_spin:data_item_val_cp',{COLUMNS => ['f:devid','f:val'],FILTER=>"ValueFilter(=,'binary:YLXS030')",LIMIT=>3}
scan 'emp', {FILTER => "RowFilter(=,'binary:5555')"}
import org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
import org.apache.hadoop.hbase.util.Bytes
scan 'ld_login_2',{STARTROW=>'1395590400',LIMIT=>1,FILTER=>SingleColumnValueFilter.new(Bytes.toBytes('cf'),Bytes.toBytes('uid'),CompareFilter::CompareOp.valueOf('EQUAL'),Bytes.toBytes('48159865'))}
scan "hs_spin:ods_yeid_data" ,{LIMIT=>1}
scan "hs_spin:dwd_min_yield_val", {COLUMNS => 'f',LIMIT=>3}
scan "hs_spin:dwd_min_yield_val", {COLUMNS => 'f',LIMIT=>1}
scan "hs_spin:dwd_min_yield_val", {COLUMNS => 'f:producer_id',LIMIT=>3}
scan "hs_spin:dwd_min_yield_val",{FILTER=>"PrifixFilter('100')",LIMIT=>3}
scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['key' , 'id' , 'name' , 'host_id' , 'model_id' , 'dev_group' , 'path_id' , 'staff_id' , 'staff_name' , 'class_type' , 'variety' , 'yarn_count' , 'class_order' , 'class_order_alias' , 'producer_id' , 'efficiency' , 'factor' , 'output_m' , 'output_kg' , 'output_add_m' , 'output_add_kg' , 'htime' , 'crt' , 'online'], LIMIT => 3, STARTROW => '100'};
scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['f:producer_id' , 'f:class_order' , 'f:crt' , 'f:host_id' ], LIMIT => 3, STARTROW => '100'}
scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['f:class_order', 'f:class_order_alias', 'f:crt', 'f:dev_group', 'f:efficiency', 'f:factor', 'f:host_id', 'f:htime', 'f:model_id', 'f:name', 'f:online', 'f:output_add_kg', 'f:output_add_m', 'f:output_kg', 'f:output_m', 'f:path_id', 'f:producer_id', 'f:staff_name'], LIMIT => 3, STARTROW => '100'}
scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['f:class_order', 'f:class_order_alias', 'f:crt', 'f:dev_group', 'f:efficiency', 'f:factor', 'f:host_id', 'f:htime', 'f:model_id', 'f:name', 'f:online', 'f:output_add_kg', 'f:output_add_m', 'f:output_kg', 'f:output_m', 'f:path_id', 'f:producer_id', 'f:staff_name'], LIMIT => 1, STARTROW => '100'}
scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['f:producer_id' , 'f:class_order' , 'f:crt' , 'f:host_id' ],TIMERANGE => [1621750981904, 1621750981924], LIMIT => 3, STARTROW => '100'}
-- 查询最后一条数据
scan 'hs_spin:dwd_min_yield_val', {REVERSED => true,LIMIT => 1}
scan 'hs_spin:dwd_min_yield_val', {ALL_METRICS => true}
scan 'hs_spin:dwd_min_yield_val', {ALL_METRICS => true,LIMIT => 1}
scan 'hs_spin:dwd_min_yield_val', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED'],LIMIT => 1}
scan 'hs_spin:dwd_min_yield_val', {ROWPREFIXFILTER => '100', FILTER => "(QualifierFilter (>=, 'binary:100')) AND (TimestampsFilter ( 123, 456))"}
get 'hs_spin:ods_fault_tolerant_coefficient','6925670556180797632'
get "hs_spin:ods_fault_tolerant_coefficient", '7478282144964194612'
put 'hs_spin:ods_fault_tolerant_coefficient','7478282144964194612','f:ratio','0.03'
get 'hs_spin:ods_fault_tolerant_coefficient','6925670556180797632',{COLUMN=>'f:ratio'}
get 'hs_spin:ods_fault_tolerant_coefficient','6925670556180797632',{COLUMN=>['f:ratio','f:host_id']}
put 'hs_spin:ods_fault_tolerant_coefficient','6925670556180797632','f:ratio','10.35098650746265'
put 'hs_spin:ods_fault_tolerant_coefficient','6925670556180797632','f:ratio','10.35098650746264'
--truncate table "hs_spin"."ods_wide_host";
--truncate "hs_spin"."ods_wide_host";
--
--truncate 'hs_spin:ods_wide_host'
--truncate 'hs_spin:ods_wide_host'
10.35098650746264
hbase> scan 'ns1:hs_spin:dwd_min_yield_val', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 'hs_spin:dwd_min_yield_val', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 'hs_spin:dwd_min_yield_val', {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]}
hbase> scan 'hs_spin:dwd_min_yield_val', {REVERSED => true,LIMIT => 1}
hbase> scan 'hs_spin:dwd_min_yield_val', {ALL_METRICS => true,LIMIT => 1}
hbase> scan 'hs_spin:dwd_min_yield_val', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 'hs_spin:dwd_min_yield_val', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"}
scan "hs_spin:ods_min_yield_val", {COLUMNS => 'f',RAW => true,LIMIT=>3}
get "hs_spin:ods_min_yield_val", '1434475522@null@20210609220301'
1700000100@2633282539095064594@20210606200101
scan '表名', {LIMIT => 2}
scan 'user', {COLUMNS => 'info'}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
describe 't1' / desc 't1'
scan "hs_spin:ods_min_yield_val" ,{COLUMNS=>['name','id’],LIMIT=>10}
describe "hs_spin:ods_min_yield_val" / desc 't1'
scan "test:hive_hbase_test"
get "test:hive_hbase_test",'0001'
select * from "hs_spin"."hive_hbase_test";
enable "hs_spin"."hive_hbase_test";
hbase shell
use test;
list_namespace
drop_namespace TEST
drop_namespace "TEST"
create_namespace "test", {"author"=>"CC11001100", "create_time"=>"2022-11-4 17:51:53"}
create_namespace "test", {"author"=>"CC11001100", "create_time"=>"2022-11-4 17:51:53"}
use "test"
describe_namespace 'test'
disable "test:hive_hbase_test"
drop "test:hive_hbase_test"
drop_namespace "test"
list_namespace_tables 'test'
-- hbase
create_namespace 'ns_weibo'
create 'ns_weibo:content','info'
put 'ns_weibo:content','1002_1597824006872','info:content','哦,我的上帝,f1'
put 'ns_weibo:content','1002_1597824007229','info:content',',我的上帝,f2'
put 'ns_weibo:content','1002_1597824007311','info:content','哦,我的上帝,f3'
put 'ns_weibo:content','1003_1597824007386','info:content','哦,我的上帝,f5'
create_namespace 'ns_hs_flink'
create 'ns_hs_flink:content','info'
put 'ns_hs_flink:content','1002_1597824006872','info:content','哦,我的上帝,f1'
put 'ns_hs_flink:content','1002_1597824007229','info:content',',我的上帝,f2'
put 'ns_hs_flink:content','1002_1597824007311','info:content','哦,我的上帝,f3'
put 'ns_hs_flink:content','1003_1597824007386','info:content','哦,我的上帝,f5'
scan 'ns_hs_flink:content'
-- phoenix
CREATE SCHEMA IF NOT EXISTS "ns_hs_flink";
CREATE VIEW IF NOT EXISTS "ns_hs_flink"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
);
CREATE TABLE IF NOT EXISTS "ns_hs_flink"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
) column_encoded_bytes=0;--禁用列映射
scan 'ns_weibo:content'
-- phoenix
CREATE SCHEMA IF NOT EXISTS "ns_weibo";
CREATE VIEW IF NOT EXISTS "ns_weibo"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
);
CREATE TABLE IF NOT EXISTS "ns_weibo"."content" (
"ROW" VARCHAR NOT NULL PRIMARY KEY,
"info"."content" VARCHAR
) column_encoded_bytes=0;--禁用列映射
column_encoded_bytes=0;如果hbase表存在加上这个,否则hbase的数据不会映射过来
SPLIT ON ('133','158','159') phoenix的预分区,比hbase更直观明了
SPLIT ON和column_encoded_bytes不能同时存在
COMPRESSION='snappy''?选择压缩方式
SALT_BUCKETS=16 加盐预分区,会?峙渲贫ㄊ康脑し智?,会根据rowkey的hash将数据分配到指定分区,但是不可控会造成数据热点问题
*/
SELECT r."htime" htime,r."dev_group" dev_group,r."batch" batch,r."variety_num" varietyNum,
r."class_order" class_order,r."class_type" class_type,
round(to_number(r."prods"),2) prods,ROUND(to_number(r."rate"), 2) rate,r."host_name" host_name
FROM "hs_spin"."mk_machine_platforms" r
ORDER BY r."htime" DESC ,r."class_order",reverse(substr(r."ROW",1,19));
SELECT *
FROM "hs_spin"."mk_machine_platforms" r
ORDER BY r."htime" DESC ,r."class_order",reverse(substr(r."ROW",1,19)) limit 10;
CREATE TABLE "hs_spin"."wh_wide_all"(
"ROW" VARCHAR PRIMARY KEY ,
"f"."id" VARCHAR ,
"f"."serial_no" VARCHAR ,
"f"."name" VARCHAR ,
"f"."dev_group" VARCHAR ,
"f"."model_id" VARCHAR ,
"f"."variety_id" VARCHAR ,
"f"."batch_id" VARCHAR ,
"f"."emp_name" VARCHAR ,
"f"."class_order" VARCHAR ,
"f"."class_type" VARCHAR ,
"f"."ratea" VARCHAR ,
"f"."rateb" VARCHAR ,
"f"."ratec" VARCHAR ,
"f"."proda1" VARCHAR ,
"f"."add_proda1" VARCHAR ,
"f"."proda" VARCHAR ,
"f"."add_proda" VARCHAR ,
"f"."prodb1" VARCHAR ,
"f"."add_prodb1" VARCHAR ,
"f"."prodb" VARCHAR ,
"f"."add_prodb" VARCHAR ,
"f"."prodc1" VARCHAR ,
"f"."add_prodc1" VARCHAR ,
"f"."prodc" VARCHAR ,
"f"."add_prodc" VARCHAR ,
"f"."prodnow1" VARCHAR ,
"f"."add_prodnow1" VARCHAR ,
"f"."prodnow" VARCHAR ,
"f"."add_prodnow" VARCHAR ,
"f"."ratenow" VARCHAR ,
"f"."open_status" VARCHAR ,
"f"."active_power" VARCHAR ,
"f"."add_active_power" VARCHAR ,
"f"."reverse_active_power" VARCHAR ,
"f"."perceptual_active_power" VARCHAR ,
"f"."capacitive_reactive_power" VARCHAR ,
"f"."a_phase_voltage" VARCHAR ,
"f"."b_phase_voltage" VARCHAR ,
"f"."c_phase_voltage" VARCHAR ,
"f"."ab_line_voltage" VARCHAR ,
"f"."bc_line_voltage" VARCHAR ,
"f"."ca_line_voltage" VARCHAR ,
"f"."a_phase_current" VARCHAR ,
"f"."b_phase_current" VARCHAR ,
"f"."c_phase_current" VARCHAR ,
"f"."a_phase_active_power" VARCHAR ,
"f"."b_phase_active_power" VARCHAR ,
"f"."c_phase_active_power" VARCHAR ,
"f"."a_phase_reactive_power" VARCHAR ,
"f"."total_work" VARCHAR ,
"f"."b_phase_reactive_power" VARCHAR ,
"f"."c_phase_reactive_power" VARCHAR ,
"f"."total_reactive_power" VARCHAR ,
"f"."a_phase_apparent_power" VARCHAR ,
"f"."b_phase_apparent_power" VARCHAR ,
"f"."c_phase_apparent_power" VARCHAR ,
"f"."total_apparent_power" VARCHAR ,
"f"."a_phase_power_factor" VARCHAR ,
"f"."b_phase_power_factor" VARCHAR ,
"f"."c_phase_power_factor" VARCHAR ,
"f"."power_factor" VARCHAR ,
"f"."frequency" VARCHAR ,
"f"."htime" VARCHAR ,
"f"."owner_id" VARCHAR ,
"f"."mf_id" VARCHAR ,
"f"."online" VARCHAR ,
"f"."crt" VARCHAR );
SELECT * FROM "hs_spin"."data_item_val" limit 10;
SELECT * FROM "hs_spin"."ods_wide_host" limit 10;
SELECT count(1) FROM "hs_spin"."ods_wide_host"; --799432 800943
delete from "hs_spin"."ods_wide_host" where 1=1;
SELECT COUNT(1) from "hs_spin"."ods_wide_host";
[root@cdh1 ~]# hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'sda_crm_calls20180102'
[root@cdh1 ~]# hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'hs_spin:ods_spin_host'
select * from hs_spin:ods_max_yeid_data limit 10;
SELECT COUNT(1) from "hs_spin"."pictures";
SELECT * from "hs_spin"."pictures";
select * from "hs_spin"."data_item_val" a where a."key" like '%2367874700551389189' LIMIT 10;
select * from "hs_spin"."data_item_val" a where a."key" like '%9189' LIMIT 10;
SELECT COUNT(1) from "hs_spin"."ods_wide_host"; --408875
SELECT * from "hs_spin"."ods_wide_host" order by "start_time" desc;
SELECT COUNT(1) from "hs_spin"."spindle_speed_avg_his";
SELECT * from "hs_spin"."spindle_speed_avg_his";
SELECT max("crt"),"t_start_date","t_end_date" FROM "hs_spin"."spindle_speed_avg_his";
SELECT max("crt"),min("crt") FROM "hs_spin"."spindle_speed_avg_his";
--CREATE TABLE "hs_spin"."spindle_speed_avg_his" (
-- "ROW" VARCHAR PRIMARY KEY,
-- "f"."host_id" VARCHAR,
-- "f"."producer_id" VARCHAR,
-- "f"."hostname" VARCHAR,
-- "f"."variety" VARCHAR,
-- "f"."spindle_speed_avg" VARCHAR,
-- "f"."crt" VARCHAR,
-- "f"."t_start_date" VARCHAR,
-- "f"."t_end_date" VARCHAR
--);
SELECT
ROW,
host_id,
producer_id,
hostname,
variety,
spindle_speed_avg,
crt,
t_start_date,
t_end_date
FROM "hs_spin"."spindle_speed_avg_his"
;
SELECT count(1) FROM "hs_spin"."spindle_speed_avg_his"; --99840
SELECT * FROM "hs_spin"."spindle_speed_avg_his" limit 10;
SELECT * FROM "hs_spin"."spindle_speed_avg_his" limit 10;
SELECT MYKEY,MYCOLUMN FROM "ns_hs_flink"."test_phoenix_api";
SELECT MYKEY,MYCOLUMN FROM "ns_hs_flink"."test_phoenix_api";
SELECT * FROM "hs_spin"."spindle_speed_avg_his" where "ROW"='2367900818650169344@202106300001';
SELECT * FROM "hs_spin"."spindle_speed_avg_his" where "t_start_date"='2021-07-12';
SELECT * FROM "hs_spin"."spindle_speed_avg" where "ROW"='2367900818650169344@202106251748';
"ns_hs_flink:airTest"
--create table test_phoenix_api(mykey integer not null primary key ,mycolumn varchar )
--create table "ns_hs_flink"."test_phoenix_api"(mykey integer not null primary key ,mycolumn varchar )
create table IF NOT EXISTS "ns_hs_flink"."test_phoenix_api3"(mykey integer not null primary key ,mycolumn varchar )
/*
squirrel sql客户端里面 有没有快捷键可以让自己写的代码格式化
快捷键盘 : ctrl+alt+f 组合键盘 不过不是很好看
sf SELECT * FROM
智能提示 ctrl+t
scan "ns_hs_flink:airTest"
*/
--CREATE TABLE "hs_spin"."spindle_speed_avg" (
-- "ROW" VARCHAR PRIMARY KEY,
-- "f"."host_id" VARCHAR,
-- "f"."producer_id" VARCHAR,
-- "f"."hostname" VARCHAR,
-- "f"."variety" VARCHAR,
-- "f"."spindle_speed_avg" VARCHAR,
-- "f"."crt" VARCHAR
--);
--DROP TABLE "ns_hs_flink"."content";
--drop table if exists "ns_hs_flink"."content";
--drop table if exists "ns_hs_flink"."hive_hbase_test";
--upsert into "ns_hs_flink".test01_20200413 (COL1, COL6) values(1, 321334);
SELECT COL1,COL2,COL3,COL4,COL5 FROM "ns_hs_flink"."TEST01_20200413";
SELECT ROW,serial_no,producer_id,dev_group,htime,host_name,add_proda,batch_id,batch,add_prodb,add_prodc,prods,variety_num,class_order,class_type,variety_id,rate,model_id,code,open_num,emp_name FROM "hs_spin"."mk_machine_platforms";
SELECT * FROM "hs_spin"."mk_machine_platforms" a limit 3;
SELECT * FROM "hs_spin"."mk_machine_platforms" a where a."producer_id"='2162304858206502921' and a."class_order_alias"='ну░Я' and a."htime"='2021-06-06';
SELECT * FROM "hs_spin"."mk_machine_platforms" a where a."producer_id"='2162304858206502921' and a."class_type"='A' and a."htime"='2021-06-06';
SELECT * FROM "hs_spin"."mk_machine_platforms" a where a."producer_id"='2162304858206502921' and a."class_order"='1' and a."htime"='2021-06-06';
SELECT * FROM "hs_spin"."mk_machine_platforms" a where a."producer_id"='2162304858206502921' and a."class_order"='2' and a."htime"='2021-06-06' and a."add_proda" is not null;
/*
CREATE TABLE "ns_hs_flink"."hive_hbase_test"(
"ROW" VARCHAR PRIMARY KEY,
"cf"."id" VARCHAR,
"cf"."name" VARCHAR,
"cf"."age" VARCHAR
);
*/
select * from "ns_hs_flink"."hive_hbase_test";
13.hive中标准偏差函数stddev()详细讲解
1.标准偏差概念
标准偏差(Std Dev,Standard Deviation) -统计学名词。一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。标准偏差的大小可通过标准偏差与平均值的倍率关系来衡量。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差应该是17.078分,B组的标准差应该是2.160分,说明A组学生之间的差距要比B组学生之间的差距大得多。
标准偏差又分为总体标准偏差与样本标准偏差
总体标准偏差:针对总体数据的偏差,所以要平均,
样本标准偏差,也称实验标准偏差:针对从总体抽样,利用样本来计算总体偏差,为了使算出的值与总体水平更接近,就必须将算出的标准偏差的值适度放大,即,
2.标准偏差计算公式:
样本标准偏差
,
代表所采用的样本X1,X2,...,Xn的均值。
总体标准偏差
,
代表总体X的均值。
例:有一组数字分别是200、50、100、200,求它们的样本标准偏差。
= (200+50+100+200)/4 = 550/4 = 137.5
= [(200-137.5)^2+(50-137.5)^2+(100-137.5)^2+(200-137.5)^2]/(4-1)
样本标准偏差 S = Sqrt(S^2)=75, 注:八年级(下册)上海科学技术出版 21.2数据的离散程度中的标准差是总体标准差
3.hive中的标准偏差函数 stddev_pop(),stddev_samp(),stddev()
stddev_pop() 总体标准方差,stddev_samp() 样本标准方差
(1) hive引擎计算标准偏差
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'A' as col, '2' as num
union all
select 'A' as col, '3' as num
union all
select 'B' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
group by col
;
查询结果:
(2)spark引擎查询标准偏差
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'A' as col, '2' as num
union all
select 'A' as col, '3' as num
union all
select 'B' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
group by col
查询结果
由上可看出,hive中stddev()函数默认计算总体标准偏差,spark 中stddev()函数默认计算样本标准偏差
4.stddev()也可用于窗口函数
select col, stddev(num) over(partition by col) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'A' as col, '2' as num
union all
select 'A' as col, '3' as num
union all
select 'B' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
查询结果:
5. 当计算的输入数据只有一行时 ,hive和spark计算标准方差的结果
(1)hive
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
group by col
;
查询结果:
(2)spark
select col, stddev_pop(num),stddev_samp(num),stddev(num) as stddev_col
from (
select 'A' as col, '1' as num
union all
select 'B' as col, '2' as num
) as a
group by col
;
hive删除数据
按分区删除:
ALTER TABLE test1 DROP PARTITION (dt='2016-04-29');
删除符合条件的数据:
insert overwrite table t_table1 select * from t_table1 where XXXX;
其中xxx是你需要保留的数据的查询条件。
insert overwrite table tlog_bigtable PARTITION (dt='2017-12-20',game_id = 'id')
select * from tlog_bigtable t
where t.dt = '2017-12-20'
and t.event_time < '2017-12-20 20:00:00'
and t.game_id = 'id'
清空表:
insert overwrite table t_table1 select * from t_table1 where 1=0;
DROP TABLE [IF EXISTS] table_name ;
TRUNCATE TABLE table_name
Method
ttl(String)
Found usages (10 usages found)
Delegate to another instance method (1 usage found)
Maven: redis.clients:jedis:2.9.0 (1 usage found)
redis.clients.jedis (1 usage found)
ShardedJedis (1 usage found)
ttl(String) (1 usage found)
100 return j.ttl(key);
Unclassified usage (1 usage found)
Maven: redis.clients:jedis:2.9.0 (1 usage found)
redis.clients.jedis (1 usage found)
JedisCluster (1 usage found)
ttl(String) (1 usage found)
212 return connection.ttl(key);
Value read (8 usages found)
ods_flink (8 usages found)
com.hangshu.sink (8 usages found)
RedisCustomSink.scala (8 usages found)
48 println("sadd之前"+this.redisCon.ttl(value.key))
50 println("sadd之后"+this.redisCon.ttl(value.key))
51 if (this.redisCon.ttl(value.key) == -1) {
54 println("设置过期之后/每次更新后"+this.redisCon.ttl(value.key))
79 println("sadd之前"+this.redisCon.ttl(value.key))
81 println("sadd之后"+this.redisCon.ttl(value.key))
82 if (this.redisCon.ttl(value.key) == -1) {
85 println("设置过期之后/每次更新后"+this.redisCon.ttl(value.key))
当 key 不存在时,返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以秒为单位,返回 key 的剩余生存时间。
注意:在 Redis 2.8 以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回 -1 。
14.mysql
对mysql中日期范围搜索的大致有三种方式:
1、between and语句;
2、datediff函数;
3、timestampdiff函数;
下面就具体说明下这三种方式:
第一种: between and语句
select * from dat_document where commit_date between '2018-07-01' and '2018-07-04'
结果是1号到3号的数据,这是因为时间范围显示的实际上只是‘2018-07-01 00:00:00’到'2018-07-04 00:00:00'之间的数据,而'2018-07-04'的数据就无法显示出来,between and对边界还需要进行额外的处理.
第二种: datediff函数
datediff函数返回两个日期之间的天数
语法:DATEDIFF(date1,date2)
SELECT DATEDIFF('2018-07-01','2018-07-04');
运行结果:-3
所以,datediff函数对时间差值的计算方式为date1-date2的差值。
————————————————
第三种: timestampdiff函数
timestampdiff函数日期或日期时间表达式之间的整数差。
语法:TIMESTAMPDIFF(interval,datetime1,datetime2),比较的单位interval可以为以下数值
FRAC_SECOND。表示间隔是毫秒
SECOND。秒
MINUTE。分钟
HOUR。小时
DAY。天
WEEK。星期
MONTH。月
QUARTER。季度
YEAR。年
select TIMESTAMPDIFF(DAY,'2018-07-01 09:00:00','2018-07-04 12:00:00');
运行结果:3
所以,timestampdiff函数对日期差值的计算方式为datetime2-datetime1的差值。
请注意:DATEDIFF,TIMESTAMPDIFF对日期差值的计算方式刚好是相反的。
————————————————
版权声明:本文为CSDN博主「斌小哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38319645/article/details/81050962
另外,如果是在xml文件中对计算的值进行比较的话,有可能会用到<、>、<=、>=等,xml会报错,这里需要对这些符号进行替换。
| 原符号 | < | <= | > | >= | & | ' | " |
|---|---|---|---|---|---|---|---|
| 替换符号 | < | <= | > | >= | & | ' | " |
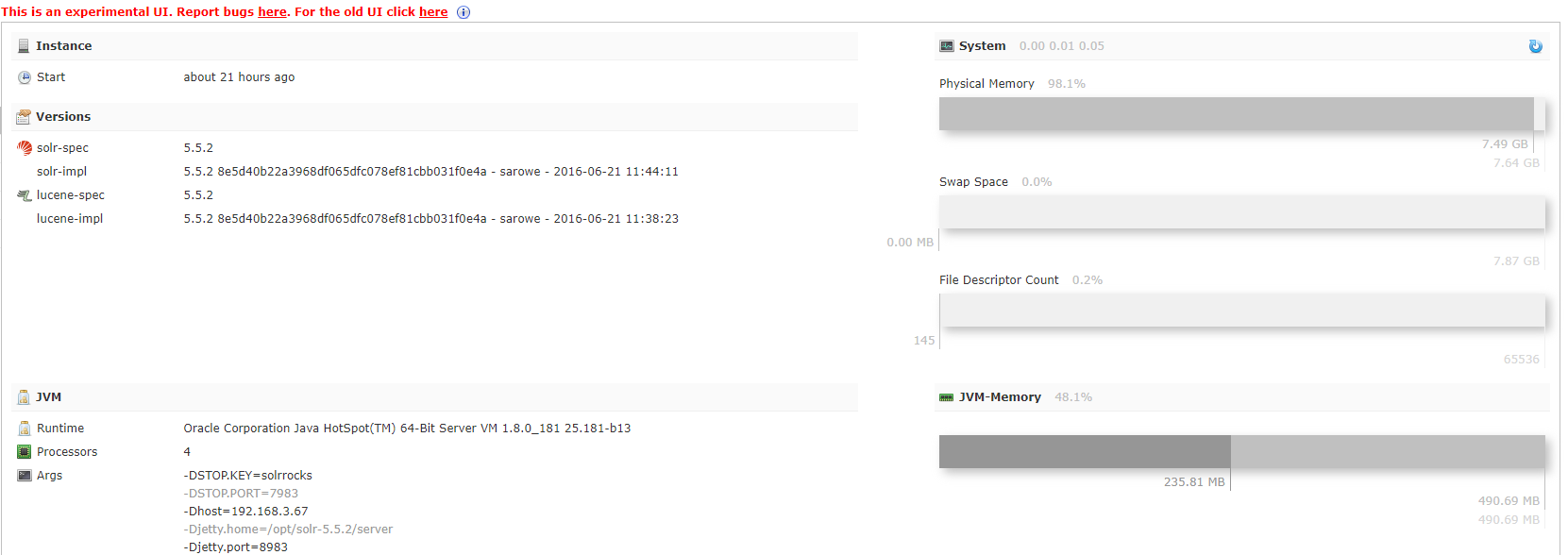
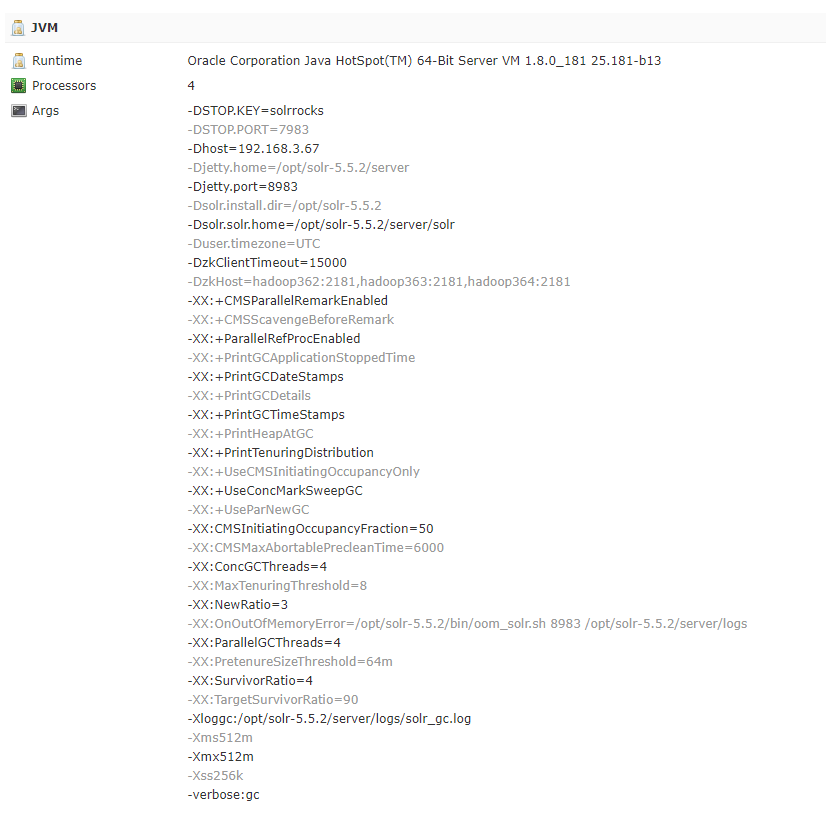
Oracle Corporation Java HotSpot(TM) 64-Bit Server VM (1.8.0_181 25.181-b13)
Processors
4
Args
-DSTOP.KEY=solrrocks-DSTOP.PORT=7983-Dhost=192.168.3.67-Djetty.home=/opt/solr-5.5.2/server-Djetty.port=8983-Dsolr.install.dir=/opt/solr-5.5.2-Dsolr.solr.home=/opt/solr-5.5.2/server/solr-Duser.timezone=UTC-DzkClientTimeout=15000-DzkHost=hadoop362:2181,hadoop363:2181,hadoop364:2181-XX:+CMSParallelRemarkEnabled-XX:+CMSScavengeBeforeRemark-XX:+ParallelRefProcEnabled-XX:+PrintGCApplicationStoppedTime-XX:+PrintGCDateStamps-XX:+PrintGCDetails-XX:+PrintGCTimeStamps-XX:+PrintHeapAtGC-XX:+PrintTenuringDistribution-XX:+UseCMSInitiatingOccupancyOnly-XX:+UseConcMarkSweepGC-XX:+UseParNewGC-XX:CMSInitiatingOccupancyFraction=50-XX:CMSMaxAbortablePrecleanTime=6000-XX:ConcGCThreads=4-XX:MaxTenuringThreshold=8-XX:NewRatio=3-XX:OnOutOfMemoryError=/opt/solr-5.5.2/bin/oom_solr.sh 8983 /opt/solr-5.5.2/server/logs-XX:ParallelGCThreads=4-XX:PretenureSizeThreshold=64m-XX:SurvivorRatio=4-XX:TargetSurvivorRatio=90-Xloggc:/opt/solr-5.5.2/server/logs/solr_gc.log-Xms512m-Xmx512m-Xss256k-verbose:gc
-DzkHost=hadoop362:2181,hadoop363:2181,hadoop364:2181
https://solr.apache.org/
https://cwiki.apache.org/confluence/display/solr/SolrQuerySyntax
## 计算时间差
FRAC_SECOND 表示间隔是毫秒
SECOND 秒
MINUTE 分钟
HOUR 小时
DAY 天
WEEK 星期
MONTH 月
QUARTER 季度
YEAR 年
SELECT DATEDIFF('2021-10-11 07:45:00','2021-10-12 15:45:00');
select timestampdiff(MINUTE,'2021-10-11 07:45:00','2021-10-12 15:45:00');
select timestampdiff(HOUR,'2021-10-11 07:45:00','2021-10-12 15:45:00');
SELECT UNIX_TIMESTAMP('2021-10-12 15:45:00');
SELECT UNIX_TIMESTAMP('2021-10-11 15:45:00');
SELECT (UNIX_TIMESTAMP('2021-10-12 15:45:00') - UNIX_TIMESTAMP('2021-10-11 07:45:00'));
SELECT 1634024700-1633938300;
SELECT SEC_TO_TIME(UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time));
SELECT SEC_TO_TIME(UNIX_TIMESTAMP('2021-10-12 15:45:00') - UNIX_TIMESTAMP('2021-10-11 07:45:00'));
-- mysql中查询某一个字段名属于哪一个库中的哪一张表
select table_schema,table_name from information_schema.columns where column_name = '字段名'
改变世界的是这样一群人,他们寻找梦想中的乐园,当他们找不到时,他们亲手创造了它
https://zhuanlan.zhihu.com/p/144027891
https://www.cnblogs.com/listenfwind/p/12886205.html
https://cloud.tencent.com/developer/article/1005925
https://www.jianshu.com/p/edf503a2a1e7
http://www.ptbird.cn/optimization-of-relational-algebraic-expression.html
org.apache.spark.internal.Logging
蟹六跪而二螯,非蛇鳝之,无可寄托者,用心躁也
《antlr4权威指南》
sqlBase.g4
这里antlr4和grun都已经存储成bat文件,所以可以直接调用,实际命令在《antlr4权威指南》说得很详细了就不介绍了。调用完后就会生成这样的语法树
Spark 2.4.3
其中Catalyst可以说是Spark内部专门用来解析SQL的一个框架,在Hive中类似的框架是Calcite(将SQL解析成MapReduce任务)。Catalyst将SQL解析任务分成好几个阶段,这个在对应的论文中讲述得比较清楚,本系列很多内容也会参考论文,有兴趣阅读原论文的可以到这里看:Spark SQL: Relational Data Processing in Spark。
Catalyst在论文中被叫做优化器(Optimizer),这部分是论文里面较为核心的内容,不过其实流程还是蛮好理解的
主要流程大概可以分为以下几步:
1.Sql语句经过Antlr4解析,生成Unresolved Logical Plan(有使用过Antlr4的童鞋肯定对这一过程不陌生)
2.analyzer与catalog进行绑定(catlog存储元数据),生成Logical Plan;
3.optimizer对Logical Plan优化,生成Optimized LogicalPlan;
4.SparkPlan将Optimized LogicalPlan转换成 Physical Plan;
5.prepareForExecution()将 Physical Plan 转换成 executed Physical Plan;
6.execute()执行可执行物理计划,得到RDD;
//lazy已经缓存的表达式的内容,所以不会再运行表达式里面的东西,也就是表达式内容只运行一次
懒加载就是让表达式里面的计算延迟,并且只计算一次,然后就会缓存结果。
值得一提的是,懒加载只对表达式和函数生效,如果直接定义变量,那是没什么用的。因为懒加载就是让延迟计算,你直接定义变量那计算啥啊
lazy的一个作用,是将推迟复杂的计算,直到需要计算的时候才计算,而如果不使用,则完全不会进行计算。这无疑会提高效率。
而在大量数据的情况下,如果一个计算过程相互依赖,就算后面的计算依赖前面的结果,那么懒加载也可以和缓存计算结合起来,进一步提高计算效率。嗯,有点类似于spark中缓存计算的思想。
除了延迟计算,懒加载也可以用于构建相互依赖或循环的数据结构。我这边再举个从stackOverFlow看到的例子:
这种情况会出现栈溢出,因为无限递归,最终会导致堆栈溢出。
//每个Stream有两个元素,一个head表示当前元素,tail表示除当前元素后面的其他元素,也可能为空
//就跟链表一样
《scala函数式编程》
Functional programming in Scala
这同样都是filter和take,代码跟代码的差距咋就这么大呢?
答案就是:因为Stream利用了惰性求值(lazy evaluation),或者也可以称之为延迟执行(deferred execution)。
就在于List是先把数据构造出来,然后在一堆数据中挑选我们心仪的数据。
而Stream是先把算法构造出来,挑选心仪的算法,最后只执行一大堆算法中我们需要的那一部分。
这样,自然就不会执行多余的运算了。
总而言之,懒加载主要是为了能够在一定程度上提升函数式编程的效率,无论是空间效率还是时间效率。这一点看Stream的各个例子就明白了,Stream这种数据结构天然就是懒的。
同时懒加载更重要的一点是通过分离表达式和值,提升了模块化。这句话听起来比较抽象,还是得看回1.2 懒加载的好处这一节的例子。所谓值和表达式分离,在这个例子中,就是当调用Fee().foo的时候,不会立刻要求得它的值,而只是获得了一个表达式,表达式的值暂时并不关心。这样就将表达式和值分离开来,并且模块化特性更加明显!从这个角度来看,这一点和Scala函数式编程(五) 函数式的错误处理介绍的Try()错误处理有些类似,都是关注表达式而不关注具体的值,其核心归根结底就是为了提升模块化。
Option呢,其实就是薛定谔的值,里面可能有值,也可能没有值。只有到要看的时候,才会知道Option里面到底有没有值。
Option全程叫Option[A],表示Option里面存的是A类型的值,这个A可以是Int,String,等等。我们可以通过get这个api来获取Option[A]里面的值,当不存在时,get会返回None。
可以通过isEmpty,来确认Option里面到底是不是有值。也可以通过getOrElse来指定没有值的时候要返回什么值。
Try[A]和Option类似,都是表示一个可能有也可能没有的东西。实际对应过来, Try[A]就表示一个可能成功也可以失败的计算,如果成功,则返回A类型,如果失败,则返回Throwable。
这种做法会忽略掉原本应该抛出的错误,你需要明确知道自己确实是要忽略掉这个错误才能这样用。
Try("asd".toInt).getOrElse(-1)
一个好的程序员,不应当满足于学习到了什么新的技术或者学习了什么新的算法模型。真正有价值的东西,往往是那些人们不乐意去学的底层的,枯燥的内容。
我们应该认识到,单单只会上层应用开发或只会调包调模型而不懂底层原理,那这种开发人员的知识体系便如空中阁楼。看起来华丽壮观,但实际上却地基不稳。一旦出现一点问题这座阁楼便会顷刻崩塌,并且无计可施,只能到处“祈祷”。
对未知的事务保持好奇,不断学习,探究事物的本质,原理。在我看来,这才是程序员之道。
https://www.cnblogs.com/listenfwind/p/9963489.html
RpcEndpoint => Actor
RpcEndpointRef => ActorRef
RpcEnv => ActorSystem
https://cuipengfei.me/blog/2014/10/23/scala-stream-application-scenario-and-how-its-implemented/
Spark RPC 服务端逻辑小结:我们说明了 Spark RPC 服务端启动的逻辑流程,分为两个部分,第一个是 Spark RPC env ,即 NettyRpcEnv 的创建过程,第二个则是 RpcEndpoint 注册到 dispatcher 的流程。
1. NettyRpcEnvFactory 创建 NettyRpcEnv
根据地址创建 NettyRpcEnv。
NettyRpcEnv 开始启动服务,包括 TransportContext 根据地址开启监听服务,向 Dispacther 注册一个 RpcEndpointVerifier 等待。
2. Dispatcher 注册 RpcEndpoint
Dispatcher 初始化时便创建一个线程池并阻塞等待 receivers 队列中加入新的 EndpointData
一旦新加入 EndpointData 便会调用该 EndpointData 的 inbox 去处理消息。比如 OnStart 消息,或是 RPCMessage 等等。
客户端逻辑小结:客户端和服务端比较类似,都是需要创建一个 NettyRpcEnv 。不同的是接下来客户端创建的是 RpcEndpointRef ,并用之向服务端对应的 RpcEndpoint 发送消息。
1. NettyRpcEnvFactory 创建 NettyRpcEnv
根据地址创建 NettyRpcEnv。 根据地址开启监听服务,向 Dispacther 注册一个 RpcEndpointVerifier 等待。
2. 创建 RpcEndpointRef
创建一个新的 RpcEndpointRef
创建对应的 verifier ,使用 verifier 向服务端发送请求,判断对应的 RpcEndpoint 是否存在。若存在,返回该 RpcEndpointRef ,否则抛出异常。
3. RpcEndpointRef 使用同步或者异步的方式发送请求。
https://gitee.com/dromara
为往圣继绝学,一个人或许能走的更快,但一群人会走的更远。
https://dromara.org/
https://dromara.org/projects/
https://www.oschina.net/
select total_read_bytes_rate_across_disks, total_write_bytes_rate_across_disks where category = CLUSTER
https://ci.apache.org/projects/flink/flink-docs-release-1.7/
https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/libs/cep/
import org.apache.flink.api.scala._
15.文献下载
http://www.ccgp.gov.cn/cggg/dfgg/cjgg/202108/t20210831_16804338.htm
https://zhuanlan.zhihu.com/p/44149623
https://www.scidown.cn/
www.sciencedirect.com
ieeexplore.ieee.org
pubmed.ncbi.nlm.nih.gov
https://www.sciencedirect.com/science/article/abs/pii/S0951832021002076
FD装备故障诊断专家知识管理系统
https://www.sciencedirect.com/search?qs=Fault%20tree&years=2022%2C2021&lastSelectedFacet=years
Fault tree
Aircraft fault diagnosis
https://www.scidown.cn/scixue.php?doi=10.1016/j.ast.2021.107031
https://www.sciencedirect.com/search?qs=Aircraft%20fault%20diagnosis&years=2020%2C2021%2C2022&lastSelectedFacet=years
http://www.miaotranslation.com/
https://www.hightopo.com/demo/flight-monitor/
https://www.onlinedoctranslator.com/zh-CN/translationform
https://fanyi.sogou.com/user/document/preview?fileId=897afba463b2409e95d33ea6f912ee23
https://www.dogetranslator.com/translation
16.Spark Streaming
流式处理发生中断出错的现象是常有的情况,可能是发生在网络部分、某个节点宕机或程序异常等。,当发生错误导致任务中断后,应该能够恢复到之前成功的状态重新消费。
Storm是利用记录确认机制(Record ACKs)来提供容错功能。
Spark Streaming则采用了基于RDD Checkpoint的方式进行容错。
1.4 性能
延时时间:storm > spark
吞吐量 :spark > storm
1.5. Structed Streaming(结构化)简述
不同点:
Spark Streaming是以RDD构成的DStream为处理结构.
Structed Streaming是一种基于Spark SQL引擎的可扩展且容错的流处理引擎
Structed 提供了更加低延迟的处理模式
相同点:
都是微批的实时处理,内部并不是逐条处理数据记录,而是按照一个个小batch来处理,从而实现低延迟的端到端延迟和一次性容错保证。
原文链接:https://blog.csdn.net/Mrerlou/article/details/113410060
https://www.cnblogs.com/yangxusun9/p/13137592.html
16.1 广播变量、累加器
通常,如下操作rdd.transformation(func),func所需要的外部变量都会以副本的形式从Driver端被发送到每个Executor的每个Task,当Task数目有成百上千个时,这种方式就非常低效;同时每个Task中变量的更新是在本地,也不会被传回Driver端。为此,Spark提供了两种类型的共享变量:广播变量、累加器。
广播变量
广播变量,Execoutor中的只读变量。在Driver端定义,在Exector中只读。
在Execoutor的Task中只读。可用来缓存全局只读变量到Exector中,减少网络通信和存储开销。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/83335273
累加器
累计器,Execoutor中的只增变量。在Exector的Task中只增,在Driver端可读。可用来分布式全局计数和分布式全局聚合。
注意:从Spark 2.x开始,之前的Accumulator被废除,用AccumulatorV2代替。
累加器使用
分布式计数
异常数据收集
UDF、UDAF、UDTF
UDF:用户自定义函数(User Defined Function)。一行输入一行输出。
UDAF: 用户自定义聚合函数(User Defined Aggregate Function)。多行输入一行输出。
UDTF: 用户自定义表函数(User Defined Table Generating Function)。一行输入多行输出。如hive/spark中的explode、json_tuple函数。
UDTF不常用,这里只总结UDF和UDAF。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/83850208
此时注册的方法 只能在sql()中可见,对DataFrame API不可见
用法:sqlContext.udf.register("makeDt", makeDT(_:String,_:String,_:String))
此时注册的方法 只能在sql()中可见,对DataFrame API不可见
用法:sqlContext.udf.register("makeDt", makeDT(_:String,_:String,_:String))
def makeDT(date: String, time: String, tz: String) = s"$date $time $tz"
sqlContext.udf.register("makeDt", makeDT(_:String,_:String,_:String))
// Now we can use our function directly in SparkSQL.
sqlContext.sql("SELECT amount, makeDt(date, time, tz) from df").take(2)
// but not outside
df.select($"customer_id", makeDt($"date", $"time", $"tz"), $"amount").take(2) // fails
2)调用spark.sql.function.udf()方法
此时注册的方法,对外部可见
用法:valmakeDt = udf(makeDT(_:String,_:String,_:String))
示例:
import org.apache.spark.sql.functions.udf
val makeDt = udf(makeDT(_:String,_:String,_:String))
// now this works
df.select($"customer_id", makeDt($"date", $"time", $"tz"), $"amount").take(2)
UDF函数有两种注册方式:
- spark.udf.register() // spark是SparkSession对象
- udf() // 需要import org.apache.spark.sql.functions._
SparkSQL中可以创建自定义函数UDF对dataframe进行操作,UDF是一对一的关系,用于给dataframe增加一列数据的场景。 每次传入一行数据,该行数据可以是一列,也可以是多列,进行一顿操作后,最终只能输出该新增列的一个值。
从Spark 2.0.0开始,Spark Sql包内置和Spark Streaming类似的Time Window,方便我们通过时间来理解数据。
Spark Sql包中的Window API
Tumbling Window
window(timeColumn: Column, windowDuration: String): Column
Slide Window
window(timeColumn: Column, windowDuration: String, slideDuration: String): Column
window(timeColumn: Column,windowDuration: String,slideDuration: String,startTime: String): Column
注意
timeColumn 时间列的schema必须是timestamp类型。
窗口间隔(windowDuration、slideDuration)是字符串类型。如 0 years、0 months 、1 week、0 days、 0 hours、0 minute、 0 seconds、 1 milliseconds、 0 microseconds。
startTime 开始的位置。如从每小时第15分钟开始,startTime为15 minutes。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/83855223
Spark 推测执行是一种优化技术。
在Spark中,可以通过推测执行,即Speculative Execution,来识别并在其他节点的Executor上重启某些运行缓慢的Task,并行处理同样的数据,谁先完成就用谁的结果,并将另一个未完成的Task Kill掉,从而加快Task处理速度。适用于某些Spark任务中部分Task被hang住或运行缓慢,从而拖慢了整个任务运行速度的场景。
注意:
不是所有运行缓慢的Spark任务,都可以用推测执行来解决。
使用推测执行时应谨慎。需要合适的场景、合适的参数,参数不合理可能会导致大量推测执行Task占用资源。
如Spark Streaming写Kafka缓慢,若启用推测执行,可能会导致数据重复。
被推测的Task不会再次被推测。
Spark推测执行参数
spark.speculation :默认false。是否开启推测执行。
spark.speculation.interval :默认100ms。多久检查一次要推测执行的Task。
spark.speculation.multiplier :默认1.5。一个Stage中,运行时间比成功完成的Task的运行时间的中位数还慢1.5倍的Task才可能会被推测执行。
spark.speculation.quantile: 默认0.75。推测的分位数。即一个Stage中,至少要完成75%的Task才开始推测。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/88927332
org.apache.spark.scheduler.TaskSetManager#checkSpeculatableTasks
Spark Streaming是一种面向微批(micro-batch)处理的流计算引擎。Spark Streaming中有3个关于时间间隔的参数,这里做以下总结。
Duration含义
batchDuration: 批次时间。多久一个批次。
windowDuration: 窗口时间。要统计多长时间内的数据。必须是batchDuration整数倍。
slideDuration: 滑动时间。窗口多久滑动一次。必须是batchDuration整数倍。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/89062157
Duration与DStream中RDD数量关系
一个DStream中有且仅有一个RDD。不论是普通DStream还是窗口DStream。
所有DStream都可以看做是WindowedDStream。当只设置了batchDuration,可理解为batchDuration=windowDuration=slideDuration。
DStream.foreachRDD遍历的是间隔slideDuration时间生成的那个RDD。该RDD包含的是windowDuration中的数据。
————————————————
Exactly-Once不是指对输入的数据只处理一次,指的是, 在流计算引擎中, 算子给下游的结果是Exactly-Once的(即:给下游的结果有且仅有一个,且不重复、不少算)。
如在Spark Streaming处理过程中,从一个算子(Operator)到另一个算子(Operator),可能会因为各种不可抗力如机器挂掉等原因,导致某些Task处理失败,Spark内部会基于Lineage或Checkpoint启动重试Task去重新处理同样的数据。因不可抗力的存在,流处理引擎内部不可能做到一条数据仅被处理一次。所以,当流处理引擎声称提供Exactly-Once语义时,指的是从一个Operator到另一个Operator,同样的数据,无论重复处理多少次,最终的结果状态是Exactly-Once。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/89277490
Micro-Batch
典型流处理引擎:Apache Spark(Spark Streaming)。
Spark Streaming将输入的流周期性的划分成一个一个的Batch,然后用Spark批处理的方式,处理每个Batch,一个Batch要么成功,要么失败,失败后重新Replay,Recompute。偶尔可用Checkpoint快照每个RDD状态,恢复时,找到最近的Checkpoint,确定依赖,然后Recompute。
Distributed Snapshot
Distributed Snapshot(分布式快照),简单来说,就是为了保存分布式系统的Global State,当系统Failure Recovery时,从最近一次成功保存的全局快照中恢复每个节点的状态。
典型流处理引擎:Apache Spark(Spark Structured Streaming)、Apache Flink。
Flnk分布式快照是通过Asynchronous Barrier Snapshots算法实现的,该算法借鉴了Chandy-Lamport算法的主要思想,同时也做了一些改进。
Spark Structured Streaming 的Continuous Processing Mode的容错处理使用了基于Chandy-Lamport的分布式快照(Distributed Snapshot)算法。
————————————————
Spark Streaming保证Exactly-Once语义
一个Spark Streaming流处理程序,从广义上讲,包含三个步骤。
接收数据:从Source中接收数据。
转换数据:用DStream和RDD算子转换。
储存数据:将结果保存至外部系统。
如果流处理程序需要实现Exactly-Once语义,那么每一个步骤都要保证Exactly-Once。
接收数据
不同的数据源提供不同的保证。
如HDFS中的数据源,直接支持Exactly-Once语义。如使用基于Kafka Direct API从Kafka获取数据,也能保证Exactly-Once。
转换数据
Spark Streaming内部是天然支持Exactly-once语义。任务失败,不论重试多少次,一个算子给另一个算子的结果有且仅有一个,不重不丢。
储存数据
Spark Streaming中的输出操作foreachRDD默认具有At-Least Once语义,因此当任务失败时会重试多次输出,这样就会重复多次写入外部存储。 如果储存数据想实现Exactly-once,有两种途径。
幂等输出
幂等输出,即同样的数据输出多次,结果一样。一般需要借助外部存储中的唯一键实现。具体步骤:
将kafka参数enable.auto.commit设置为false。
幂等写入后手动提交offset。这里用checkpoint,不需要手动提交,生产中可用Kafka、Zookeeper、HBase等保存offset。
————————————————
Kafka在0.8和0.10之间引入了一种新的消费者API,因此,Spark Streaming与Kafka集成,有两种包可以选择: spark-streaming-kafka-0-8与spark-streaming-kafka-0-10。在使用时应注意以下几点:
spark-streaming-kafka-0-8兼容Kafka 0.8.2.1及以后的版本, 从Spark 2.3.0开始,对Kafka 0.8支持已被标记为过时。
spark-streaming-kafka-0-10兼容Kafka 0.10.0及以后的版本, 从Spark 2.3.0开始, 此API是稳定版。
如果Kafka版本大于等于0.10.0,且Spark版本大于等于Spark 2.3.0,应使用spark-streaming-kafka-0-10。
本文总结spark-streaming-kafka-0-8中两种读取Kafka数据的方式:createStream、createDirectStream。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/89419691
在Spark Streaming中,DStream的转换分为有状态和无状态两种。无状态的操作,即当前批次的处理不依赖于先前批次的数据,如map()、flatMap()、filter()、reduceByKey()、groupByKey()等等;而有状态的操作,即当前批次的处理需要依赖先前批次的数据,这样的话,就需要跨批次维护状态。
总结spark streaming中的状态操作:updateStateByKey、mapWithState、和基于window的状态操作。
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/90199002
反压(Back Pressure)机制主要用来解决流处理系统中,处理速度比摄入速度慢的情况。是控制流处理中批次流量过载的有效手段。
反压机制原理
Spark Streaming中的反压机制是Spark 1.5.0推出的新特性,可以根据处理效率动态调整摄入速率。
当批处理时间(Batch Processing Time)大于批次间隔(Batch Interval,即 BatchDuration)时,说明处理数据的速度小于数据摄入的速度,持续时间过长或源头数据暴增,容易造成数据在内存中堆积,最终导致Executor OOM或任务奔溃。
在这种情况下,若是基于Receiver的数据源,可以通过设置spark.streaming.receiver.maxRate来控制最大输入速率;若是基于Direct的数据源(如Kafka Direct Stream),则可以通过设置spark.streaming.kafka.maxRatePerPartition来控制最大输入速率。当然,在事先经过压测,且流量高峰不会超过预期的情况下,设置这些参数一般没什么问题。但最大值,不代表是最优值,最好还能根据每个批次处理情况来动态预估下个批次最优速率。在Spark 1.5.0以上,就可通过背压机制来实现。开启反压机制,即设置spark.streaming.backpressure.enabled为true,Spark Streaming会自动根据处理能力来调整输入速率,从而在流量高峰时仍能保证最大的吞吐和性能。
Spark Streaming的反压机制主要是通过RateController组件来实现。RateController继承自接口StreamingListener,并实现了onBatchCompleted方法。每一个Batch处理完成后都会调用此方法
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/90727805
反压机制相关参数
spark.streaming.backpressure.enabled
默认值false,是否启用反压机制。
spark.streaming.backpressure.initialRate
默认值无,初始最大接收速率。只适用于Receiver Stream,不适用于Direct Stream。
spark.streaming.backpressure.rateEstimator
默认值pid,速率控制器,Spark 默认只支持此控制器,可自定义。
spark.streaming.backpressure.pid.proportional
默认值1.0,只能为非负值。当前速率与最后一批速率之间的差值对总控制信号贡献的权重。用默认值即可。
spark.streaming.backpressure.pid.integral
默认值0.2,只能为非负值。比例误差累积对总控制信号贡献的权重。用默认值即可。
spark.streaming.backpressure.pid.derived
默认值0.0,只能为非负值。比例误差变化对总控制信号贡献的权重。用默认值即可。
spark.streaming.backpressure.pid.minRate
默认值100,只能为正数,最小速率。
————————————————
注意:
A. 反压机制真正起作用时需要至少处理一个批
由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制真正起作用前,应至少保证处理一个批。
B. 如何保证反压机制真正起作用前应用不会崩溃
要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。若为Direct Stream,如Kafka Direct Stream,则可以通过spark.streaming.kafka.maxRatePerPartition参数来控制。此参数代表了 每秒每个分区最大摄入的数据条数。假设BatchDuration为10秒,spark.streaming.kafka.maxRatePerPartition为12条,kafka topic 分区数为3个,则一个批(Batch)最大读取的数据条数为360条(3*12*10=360)。同时,需要注意,该参数也代表了整个应用生命周期中的最大速率,即使是背压调整的最大值也不会超过该参数。
查看日志
————————————————
同反压机制一样,Spark Streaming动态资源分配(即DRA,Dynamic Resource Allocation)也可以用来应对流处理中批次流量过载的场景。
Spark Streaming动态资源分配,允许为应用动态分配资源。当任务积压时,申请更多资源;当任务空闲时,使用最少资源。
在生产中,可将动态资源分配和背压机制一起使用,通过背压机制来细粒度确保系统稳定;通过动态资源分配机制来粗粒度根据应用负载,动态增减Executors。共同保证Spark Streaming流处理应用的稳定高效。
动态资源分配的原理
入口类是org.apache.spark.streaming.scheduler.ExecutorAllocationManager。ExecutorAllocationManager中的定时器,每隔spark.streaming.dynamicAllocation.scalingInterval时间,调用一次manageAllocation方法来管理Executor。manageAllocation方法计算规则如下:
必须完成至少一个Batch处理,即batchProcTimeCount > 0。
计算Batch平均处理时间(Batch平均处理时间=Batch总处理时间/Batch总处理次数)。
若Batch平均处理时间大于阈值spark.streaming.dynamicAllocation.scalingUpRatio,则请求新的Executor。
若Batch平均处理时间小于阈值spark.streaming.dynamicAllocation.scalingDownRatio,则移除没有任务的Executor。
动态资源分配重要参数
spark.dynamicAllocation.enabled: 默认false,是否启用Spark批处理动态资源分配。
spark.streaming.dynamicAllocation.enabled: 默认false,是否启用Spark Streaming流处理动态资源分配。
spark.streaming.dynamicAllocation.scalingInterval: 默认60秒,多久检查一次。
spark.streaming.dynamicAllocation.scalingUpRatio: 默认0.9,增加Executor的阈值。
spark.streaming.dynamicAllocation.scalingDownRatio: 默认0.3,减少Executor的阈值。
spark.streaming.dynamicAllocation.minExecutors: 默认无,最小Executor个数
spark.streaming.dynamicAllocation.maxExecutors: 默认无,最大Executor个数。
Spark Streaming动态资源分配注意事项
Spark Streaming动态资源分配和Spark Core动态资源分配互斥
Spark Core动态资源分配适合于批处理,如Spark Sql Cli,可以根据Task数量动态分配Executor数量;如Spark ThriftServer On Yarn,空闲时不占用资源,只有在用户提交Sql任务时才会根据Task数动态分配Executor数。
当开启Spark Streaming动态资源分配时,需要关闭Spark Core动态资源分配。
Spark Streaming动态资源分配起作用前,需要至少完成一个Batch处理
由于Spark Streaming动态资源分配需要根据Batch总处理时间和Batch总处理次数来计算Batch平均处理时间,因此需要至少完成一个Batch处理。这就需要我们保证在Spark Streaming动态资源分配起作用前,应用程序不会崩溃。
Spark Streaming动态资源分配应当和Spark Streaming背压机制同时使用
————————————————
版权声明:本文为CSDN博主「wangpei1949」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangpei1949/article/details/90734304
sparkCommLib=/data/apps/sparkCommLib
/usr/hdp/2.6.4.0-91/spark2/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--queue default \
--name spark_streaming_dra \
--driver-cores 1 \
--driver-memory 1G \
--executor-memory 1G \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.streaming.dynamicAllocation.enabled=true \
--conf spark.streaming.dynamicAllocation.minExecutors=1 \
--conf spark.streaming.dynamicAllocation.maxExecutors=15 \
--jars ${sparkCommLib}/kafka_2.11-0.10.1.0.jar,${sparkCommLib}/kafka-clients-0.10.1.0.jar,${sparkCommLib}/spark-streaming-kafka-0-10_2.11-2.1.1.jar,${sparkCommLib}/fastjson-1.2.5.jar \
--class com.bigData.spark.SparkStreamingDRA \
spark-1.0-SNAPSHOT.jar
在Yarn上可以看到,随着Spark Streaming任务队列中Queued的Batch越来越多,Executors数量在逐渐增加。
https://blog.csdn.net/chenjieit619/article/details/53421080
我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
资源参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
内容
1.num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
2.executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
3.executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
4.driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
5.spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
6.spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
7.spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
8.total-executor-cores
参数说明:Total cores for all executors.
9.资源参数参考示例
以下是一份spark-submit命令的示例:
--master spark://192.168.1.1:7077 \
--master yarn-cluster \
--master yarn-client \
./bin/spark-submit \
--master spark://192.168.1.1:7077 \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--total-executor-cores 400 \ ##standalone default all cores
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
————————————————
版权声明:本文为CSDN博主「chenjieit619」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chenjieit619/article/details/53421080
查看正常CPU
SELECT cpu_nice_rate WHERE category= HOST
2. 查看使用物理内存
SELECT physical_memory_used WHERE category= HOST
1.10 Hbase迁移
1.10.1 copytable方式
bin/hbaseorg.apache.hadoop.hbase.mapreduce.CopyTable--peer.adr=zookeeper1,zookeeper2,zookeeper3:/hbase 'testtable'
这个操作需要添加hbase目录里的conf/mapred-site.xml,可以复制hadoop的过来。
1.10.2 Export/Import
bin/hbaseorg.apache.hadoop.hbase.mapreduce.Export testtable /user/testtable[versions] [starttime] [stoptime]
bin/hbaseorg.apache.hadoop.hbase.mapreduce.Import testtable /user/testtable
1.10.3 直接拷贝hdfs对应的文件
首先拷贝hdfs文件,如bin/hadoop distcp hdfs://srcnamenode:9000/hbase/testtable/hdfs://distnamenode:9000/hbase/testtable/
然后在目的hbase上执行bin/hbase org.jruby.Main bin/add_table.rb /hbase/testtable
生成meta信息后,重启hbase
http://www.saoniuhuo.com/question/detail-1914490.html?sort=new
在YARN的原生任务监控界面中,我们经常能看到Aggregate Resource Allocation这个指标(图中高亮选中部分),这个指标表示该任务拥有的所有container每秒所消耗的资源(内存、CPU)总和
GMV (Gross Merchandise Volume) 一般只有平台类的电商网站才喜欢这么说法,比如淘宝,TMALL在电商网站定义里面是网站成交金额这个实际指的是拍下订单金额, 包含付款和未付款的部分而销售额一般对应的是b2c自营网站,那个就是实际流水了以前一些活动销售额的新闻报道,网站喜欢给的是GMV金额, 无他, 数字大,好看!实际付款金额要略低一些,因为有时候是隔天付款,但是订单成交是在当天当然,实际订单可能不支付,所以GMV肯定大于实际销售额
作者:皓子
链接:https://www.zhihu.com/question/20146641/answer/24469879
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如上图,这里面的Aggregate Resource Allocation : 38819 MB-seconds, 104 vcore-seconds是什么意思呢?
例如,我有一个单节点集群,其中,我已将每个容器的内存要求设置为:1228 MB(由config:yarn.scheduler.minimum-allocation-mb确定)和每个容器的vCore为1 vCore(由config确定: yarn.scheduler.minimum-allocation-vcores)。我已将:yarn.nodemanager.resource.memory-mb设置为9830 MB。因此,每个节点总共可以有8个容器(9830/1228 = 8)。因此,对于我的集群:VCores-Total = 1(节点)* 8(容器)* 1(每个容器的vCore)= 8
内存总数= 1(节点)* 8(容器)* 1228 MB(每个容器的内存)= 9824 MB = 9.59375 GB = 9.6 GB
下图显示了我的群集指标:现在让我们看看“MB-seconds”和“vcore-seconds”。根据代码中的描述(ApplicationResourceUsageReport.java):MB-seconds:应用程序分配的聚合内存量(以兆字节为单位)乘以应用程序运行的秒数。vcore-seconds:应用程序分配的聚合数量的vcores乘以应用程序运行的秒数。描述是自我解释的(记住关键词:聚合)。让我用一个例子解释一下。我运行了一个DistCp作业(产生了25个容器),我得到了以下内容:聚合资源分配:10361661 MB-seconds,8424 vcore-seconds
现在,让我们粗略计算每个容器花费的时间:对于内存:
10361661 MB-seconds = 10361661/25(容器)/ 1228 MB(每个容器的内存)= 337.51秒= 5.62分钟
对于CPU
8424 vcore-seconds = 8424/25(容器)/ 1(每容器vCore)= 336.96秒= 5.616分钟
这表明平均每个容器需要5.62分钟才能执行。希望这说清楚。您可以执行某项工作并自行确认。
SELECT 3492333/1024/4/3,3492333/1024/4/3/60;
284.206787109333 4.7367797851555556
SELECT 910/4/1,910/4/1/60;
227.5 3.791666666667
saltstack和ansible、puppet都是自动化运维工具。
cachecloud
利用idea反编译jar包
利用IDEA反编译jar包(idea需要安装插件Java Bytecode Decomplier)
在需要编译的jar包的目录下,打开命令行界面,输入以下命令:
java -cp "D:\soft\IntelliJ IDEA 2020.2.3\plugins\java-decompiler\lib\java-decompiler.jar" org.jetbrains.java.decompiler.main.decompiler.ConsoleDecompiler -dgs=true hive-exec-3.1.0.3.1.0.0-78.jar mysrc
其中的java-decompiler.jar路径跟你自己的安装路径有关
4、命令执行完成之后会在您所指定的目录如mysrc中生成的打包好的源码,一般是jar格式的压缩文件,可以进行解压查看。
说明:
1、mysrc目录需要存在,不存在会报错。
2、一开始使用的非商业版本的IDEA下面的jar包,报版本不一致异常,这个应该是idea生成Bytecode的java版本与目前的jar使用的java版本不一致
java.lang.UnsupportedClassVersionError: HelloWorld has been compiled by a more recent version of the Java Runtime (class file version 53.0), this version of the Java Runtime only recognizes class file versions up to 52.0 at java.lang.ClassLoader.defineClass1(Native Method) ...... ...... at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:495)
后面是使用的商业版本的Bytecode jar包解决了问题
java -version
scala -version
mvn -v
mvn clean install -Dmaven.test.skip=true -Dmaven.javadoc.skip=true -Dcheckstyle.skip=true
-Dmaven.test.skip:跳过测试代码
-Dmaven.javadoc.skip:跳过 javadoc 检查
-Dcheckstyle.skip:跳过代码风格检查
maven 编译的时候跳过这些检查,这样可以减少很多时间,还可能会减少错误的发生。
————————————————
版权声明:本文为CSDN博主「霄嵩」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/accptanggang/article/details/105619131
以便了解项目的进展,可以采取如下步骤更新本地代码:
1)配置原项目地址
git remote add upstream <原仓库github地址> //如:https://github.com/apache/flink.git
2)查看当前仓库的远程仓库地址和原仓库地址
git remote -v
3)获取原仓库的更新
git fetch upstream
4)合并到本地分支
git merge upstream/master
5)查看本地更新
git log
6)更新自己fork 的GitHub仓库
git push origin master
本地代码更新的还可以先更新GitHub上的仓库,然后在使用git pull更新本地仓库,但是这种方法我在使用过程遇到了无法获取最新的版本分支的情况,具体过程可以参考Ref[1]。
个人建议使用本文提及的以git命令方式更新。
此外,在使用git从GitHub上拉代码的过程,可能遇到RPC failed问题,可以参考Ref[2]。
6、异常处理
1) unable to access 'https://github.com/apache/flink.git/': OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 10054
解决办法:git config --global http.sslVerify "false"
Ref:
[1] https://www.cnblogs.com/eyunhua/p/8463200.html
[2]https://www.cnblogs.com/zjfjava/p/10392150.html
16.2 yarn 命令
查看某个任务的具体信息
yarn application -list
dataframe.write.mode('overwrite').format("jdbc").options(
url=mysql_url+"?rewriteBatchedStatements=true", # 开启批处理
driver=mysql_driver,
user='test',
password='xxxxxx',
dbtable=save_table_name,
batchsize=10000, # 每批数据大小
isolationLevel='NONE', # 事务隔离,这里不需要做事务隔离
truncate='true' # 如果不加次参数,overwrite则是删除表重新创建,加上则时trunacte 表而不删除
).save()
url:要连接的JDBC URL。列如:jdbc:mysql://ip:3306
dbtable:应该读取的JDBC表。可以使用括号中的子查询代替完整表(使用select 语句代替表,例如,(select * from table_name) as t1,必须给查询结果加上别名)
driver:用于连接到此URL的JDBC驱动程序的类名,列如:com.mysql.jdbc.Driver
partitionColumn,
lowerBound,
upperBound,
numPartitions:这些options仅适用于read数据。这些options必须同时被指定。他们描述,如何从多个workers并行读取数据时,分割表。partitionColumn必须是表中的数字列。lowerBound和upperBound仅用于决定分区的大小,而不是用于过滤表中的行。表中的所有行将被分割并返回。
fetchsize:仅适用于read数据。JDBC提取大小,用于确定每次获取的行数。这可以帮助JDBC驱动程序调优性能,这些驱动程序默认具有较低的提取大小(例如,Oracle每次提取10行)。
batchsize:仅适用于write数据。JDBC批量大小,用于确定每次insert的行数。这可以帮助JDBC驱动程序调优性能。默认为1000。
isolationLevel:仅适用于write数据。事务隔离级别,适用于当前连接。它可以是一个NONE,READ_COMMITTED,READ_UNCOMMITTED,REPEATABLE_READ,或SERIALIZABLE,对应于由JDBC的连接对象定义,缺省值为标准事务隔离级别READ_UNCOMMITTED。
truncate:仅适用于write数据。当SaveMode.Overwrite启用时,此选项会truncate在MySQL中的表,而不是删除,再重建其现有的表。这可以更有效,并且防止表元数据(例如,索引)被去除。但是,在某些情况下,例如当新数据具有不同的模式时,它将无法工作。它默认为false。
createTableOptions:仅适用于write数据。此选项允许在创建表(例如CREATE TABLE t (name string) ENGINE=InnoDB.)时设置特定的数据库表和分区选项。
http://wuqianling.top/software/notepad/compress.html
https://tool.lu/sql/
16.3 Spark性能优化:资源调优篇
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
Spark任务启动时日志提示:Will allocate AM container, with 896 MB memory including 384 MB overhead
该行日志说明:AM占用了 896 MB 内存,除掉 384 MB 的overhead内存,实际上只有 512 MB ,即 spark.yarn.am.memory 的默认值。
即Yarn AM launch context启动了一个Java进程,设置的JVM内存为 512m ,见 /bin/java -server -Xmx512m 。
设置AM申请的内存值:spark.yarn.am.memory
要想设置AM申请的内存值,要么使用cluster模式,要么在client模式中,是有 --conf 手动设置 spark.yarn.am.memory 属性,例如:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-client \
--num-executors 4 \
--driver-memory 2g \
--executor-memory 3g \
--executor-cores 4 \
--conf spark.yarn.am.memory=1024m \
/usr/lib/spark/lib/spark-examples-1.3.0-cdh5.4.0-hadoop2.6.0-cdh5.4.0.jar \
100000
作者:码农铲屎官
链接:https://www.zhihu.com/question/428004153/answer/1554865003
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对于spark来内存可以分为JVM堆内的和 memoryoverhead、off-heap
其中 memoryOverhead: 对应的参数就是spark.yarn.executor.memoryOverhead , 这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。其实就是额外的内存,spark并不会对这块内存进行管理。
off-heap : 这里特指的spark.memory.offHeap.size这个参数指定的内存(广义上是指所有堆外的)。这部分内存的申请和释放是直接进行的不通过jvm管控所以没有GC。
你的命令spark-sumbit --master yarn --executor-memory 5g --conf spark.yarn.executor=1024
一共会请求内存量 = executor-memory + memoryOverhead
CoarseGrainedExecutorBackend的命令`-Xms 5120m -Xmx5120m` 用于初始分配堆内存(该部分内存由JVM进行管理)
spark.yarn.executor.memoryOverhead配置的内存不受JVM的管控,具体用处上文已介绍
yarn.scheduler.capacity.root.default.capacity:一个百分比的值,表示占用整个集群的百分之多少比例的资源,这个queue-path下所有的capacity之和是100
yarn.scheduler.capacity.root.default.user-limit-factor:每个用户的低保百分比,比如设置为1,则表示无论有多少用户在跑任务,每个用户占用资源最低不会少于1%的资源
yarn.scheduler.capacity.root.default.maximum-capacity:弹性设置,最大时占用多少比例资源
yarn.scheduler.capacity.root.default.state:队列状态,可以是RUNNING或STOPPED
yarn.scheduler.capacity.root.default.acl_submit_applications:哪些用户或用户组可以提交人物
yarn.scheduler.capacity.root.default.acl_administer_queue:哪些用户或用户组可以管理队列
队列不能被删除,只能新增。
更新队列的配置需要是有效的值
同层级的队列容量限制想加需要等于100%。
lcc@lcc ~$ yarn queue -status default
18/12/15 10:55:10 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/12/15 10:55:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Queue Information :
Queue Name : default
State : RUNNING
Capacity : 100.0%
Current Capacity : .0%
Maximum Capacity : 100.0%
Default Node Label expression :
Accessible Node Labels : *
lcc@lcc ~$
可以看到默认是org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler这个调度器,那么这个调度器的名字是什么呢?
我们可以在/Users/lcc/soft/hadoop/hadoop-2.7.4/etc/hadoop/capacity-scheduler.xml文件中看到
FailScheduler
解决办法:
1)调整minshare,maxshare
2)调整maxrunningapp
参数的详细解释,可以参考
http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-configurations-fair-scheduler/
转自:https://blog.csdn.net/wisgood/article/details/48715629
val rdd2 = rdd1.map(…)
val rdd3 = rdd1.filter(…)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cache和unpersisit两个操作比较特殊,他们既不是action也不是transformation。cache会将标记需要缓存的rdd,真正缓存是在第一次被相关action调用后才缓存;unpersisit是抹掉该标记,并且立刻释放内存。只有action执行时,rdd1才会开始创建并进行后续的rdd变换计算。
cache其实也是调用的persist持久化函数,只是选择的持久化级别为MEMORY_ONLY。
persist支持的RDD持久化级别如下:
需要注意的问题:
Cache或shuffle场景序列化时, spark序列化不支持protobuf message,需要java 可以serializable的对象。一旦在序列化用到不支持java serializable的对象就会出现上述错误。
Spark只要写磁盘,就会用到序列化。除了shuffle阶段和persist会序列化,其他时候RDD处理都在内存中,不会用到序列化。
需要构建4个东西:
一个静态的 RDD DAG 的模板,来表示处理逻辑;
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD ;
DAG 的实例,对数据片段进行处理;
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
https://github.com/lw-lin/CoolplaySpark/blob/master/Spark%20Streaming%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E7%B3%BB%E5%88%97/0.1%20Spark%20Streaming%20%E5%AE%9E%E7%8E%B0%E6%80%9D%E8%B7%AF%E4%B8%8E%E6%A8%A1%E5%9D%97%E6%A6%82%E8%BF%B0.md#24
对于spark streaming需要注意以下三点:
尽量保证每个work节点中的数据不要落盘,以提升执行效率。
保证每个batch的数据能够在batch interval时间内处理完毕,以免造成数据堆积。
使用steven提供的框架进行数据接收时的预处理,减少不必要数据的存储和传输。从tdbank中接收后转储前进行过滤,而不是在task具体处理时才进行过滤。
Executor的内存主要分为三块:
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
每个task以及每个executor占用的内存需要分析一下。每个task处理一个partiiton的数据,分片太少,会造成内存不够。
其他资源配置:
具体调优可以参考美团点评出品的调优文章:
http://tech.meituan.com/spark-tuning-basic.html
http://tech.meituan.com/spark-tuning-pro.html
Spark 环境搭建
spark tdw以及tdbank api文档:
http://git.code.oa.com/tdw/tdw-spark-common/wikis/api
其他学习资料:
http://km.oa.com/group/2430/articles/show/257492
转自: http://www.cnblogs.com/liuliliuli2017/p/6809094.html
Spark 目前支持两种序列化机制:java native serialization 和 kryo serialization,默认使用的是Java native serialization。两者的区别:
作者:alexlee666
链接:https://www.jianshu.com/p/68970d1674fa
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
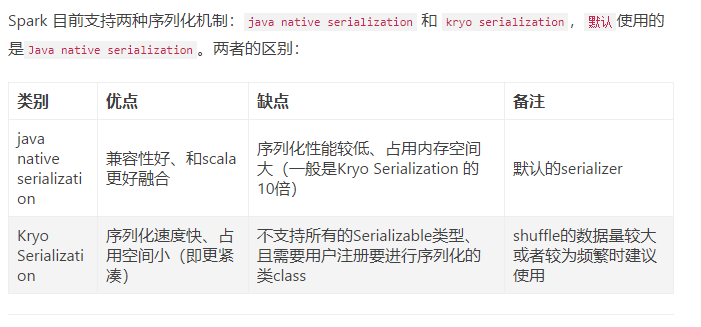
在stat包中实现了皮尔逊卡方检验,它主要包含以下两类
(1)适配度检验(Goodness of Fit test):验证一组观察值的次数分配是否异于理论上的分配。
(2)独立性检验(independence test) :验证从两个变量抽出的配对观察值组是否互相独立(例如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)
由输出的日志可以看出job的提交过程主要经过了SparkContext-》DAGScheduler-》TaskScheduler的处理
与RDD相关的一个重要类就是Dependency类,它负责表示RDD之间的依赖关系。包含了NarrowDependency(窄依赖)与ShuffleDependency(宽依赖)两类
其中NarrowDependency包含一对一的OneToOneDependency与一对多的RangeDependency。在wordcount程序中MappedRDD、FlatMappedRDD都属于
OneToOneDependency,而ShuffledRDD、MapPartitionsRDD属于ShuffleDependency。
job提交的大致调用链是:sc.runJob()->dagScheduler.runJob->dagScheduler.submitJob->dagSchedulerEventProcessActor.JobSubmitted
->dagScheduler.handleJobSubmitted->dagScheduler.submitStage->dagScheduler.submitMissingTasks->taskScheduler.submitTasks
可以看出job先经过DAGScheduler生成stage,转换成TaskSet后提交给TaskScheduler进行调度。TaskScheduler工作原理在上一节已经分析过了,下面
主要来分析下DAGScheduler处理job的过程:
job处理过程中handleJobSubmitted比较关键,finalRDD就是进行action操作前的最后一个RDD,对应wordcount就是MapPartitionsRDD。
submitStage函数中会根据依赖关系划分stage,通过递归调用从finalStage一直往前找它的父stage,直到stage没有父stage时就调用submitMissingTasks方法
提交改stage。这样就完成了将job划分为一个或者多个stage。
最后会在submitMissingTasks函数中将stage封装成TaskSet通过taskScheduler.submitTasks函数提交给TaskScheduler处理。
在SparkContext创建过程中会调用createTaskScheduler函数来启动TaskScheduler任务调度器,本文就详细分析TaskScheduler的工作原理:
TaskScheduler会根据部署方式而选择不同的SchedulerBackend来处理
下图展示了TaskScheduler、TaskSchedulerImpl、SchedulerBackend等任务调度相关类之间的关系
针对不同部署方式会有不同的TaskScheduler与SchedulerBackend进行组合:
Local模式:TaskSchedulerImpl + LocalBackend
Spark集群模式:TaskSchedulerImpl + SparkDepolySchedulerBackend
Yarn-Cluster模式:YarnClusterScheduler + CoarseGrainedSchedulerBackend
Yarn-Client模式:YarnClientClusterScheduler + YarnClientSchedulerBackend
TaskScheduler类负责任务调度资源的分配,SchedulerBackend负责与Master、Worker通信收集Worker上分配给该应用使用的资源情况。
下面以Spark集群模式为例,分析在TaskSchedulerImpl与SparkDepolySchedulerBackend类中的具体操作
一个典型的任务调度模块主要功能就是获取集群资源信息,然后根据调度策略为任务分配资源,TaskSchedulermpl也是这个工作原理,分为资源收集与资源分配:
1、资源信息收集
SparkDepolySchedulerBackend类就是专门负责收集为Application分配的Worker的资源信息的,在它的父类CoarseGrainedSchedulerBackend
中的DriverActor就是与Worker通信的Actor。根据Spark源码分析(一)-Standalone启动过程文中介绍的Worker启动后会向Driver发送RegisterExecutor
消息,此消息中就包含了Executor为Application分配的计算资源信息,而接收该消息的Actor也正是DriverActor。
2、资源分配
TaskSchedulerImpl类就是负责为Task分配资源的。在CoarseGrainedSchedulerBackend获取到可用资源后就会通过makeOffers方法通知
TaskSchedulerImpl对资源进行分配,TaskSchedulerImpl的resourceOffers方法就是负责为Task分配计算资源的,在为Task分配好资源后
又会通过lauchTasks方法发送LaunchTask消息通知Worker上的Executor执行Task
最后,总结一下TaskScheduler相关知识。TaskScheduler是在Application执行过程中,为它进行任务调度的,是属于Driver侧的。对应于一个Application就会
有一个TaskScheduler,TaskScheduler和Application是一一对应的。TaskScheduler对资源的控制也比较鲁棒(所以会取名CoarseGrainedSchedulerBackend),
一个Application申请Worker的计算资源,只要Application不结束就会一直被占有。
SparkContext是应用启动时创建的Spark上下文对象,是一个重要的入口类。本文主要分析下在SparkContext类创建过程中进行的一些重要操作:
1、创建SparkConf对象
创建SparkConf对象来管理spark应用的属性设置。SparkConf类比较简单,是通过一个HashMap(ConcurrentHashMap)容器来管理key、value类型的属性。
2、创建LiveListenerBus监听器
这是典型的观察者模式,向LiveListenerBus类注册不同类型的SparkListenerEvent事件,SparkListenerBus会遍历它的所有监听
者SparkListener,然后找出事件对应的接口进行响应。
3、创建SparkEnv运行环境
在SparkEnv中创建了MapOutputTrackerMasterActor、BlockManager、CacheManager、HttpFileServer一系列对象,关于BlockManager、CacheManager相关 的后续再单独分析。
4、创建SparkUI
在SparkUI对象初始化函数中,注册了StorageStatusListener监听器,负责监听Storage的变化及时的展示到Spark web页面上。
attachTab方法中添加对象正是我们在Spark Web页面中看到的那个标签
5、添加EventLoggingListener监听器
这个默认是关闭的,可以通过spark.eventLog.enabled配置开启。它主要功能是以json格式记录发生的事件
private[spark] def isEventLogEnabled: Boolean = _conf.getBoolean("spark.eventLog.enabled", false)
6、创建Scheduler
创建了TaskScheduler、DAGScheduler
7、加入SparkListenerEvent事件
往LiveListenerBus中加入了SparkListenerEnvironmentUpdate、SparkListenerApplicationStart两类事件,
对这两种事件监听的监听器就会调用onEnvironmentUpdate、onApplicationStart方法进行处理
当一个变量定义为 volatile 之后,将具备两种特性:
1.保证此变量对所有的线程的可见性,这里的“可见性”,如本文开头所述,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存(详见:Java内存模型)来完成。
2.禁止指令重排序优化。有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置),只有一个CPU访问内存时,并不需要内存屏障;(什么是指令重排序:是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理)。
volatile 性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
逻辑回归代码主要包含三个部分
1、classfication:逻辑回归分类器
2、optimization:优化方法,包含了随机梯度、LBFGS两种算法
3、evaluation:算法效果评估计算
DAGScheduler
handleJobSubmitted
getMissingParentStages
submitStage
16.4 Hive常用日期格式转换
固定日期转换成时间戳
select unix_timestamp('2016-08-16','yyyy-MM-dd') --1471276800
select unix_timestamp('20160816','yyyyMMdd') --1471276800
select unix_timestamp('2016-08-16T10:02:41Z', "yyyy-MM-dd'T'HH:mm:ss'Z'") --1471312961
16/Mar/2017:12:25:01 +0800 转成正常格式(yyyy-MM-dd hh:mm:ss)
select from_unixtime(to_unix_timestamp('16/Mar/2017:12:25:01 +0800', 'dd/MMM/yyy:HH:mm:ss Z'))
时间戳转换程固定日期
select from_unixtime(1471276800,'yyyy-MM-dd') --2016-08-16
select from_unixtime(1471276800,'yyyyMMdd') --20160816
select from_unixtime(1471312961) -- 2016-08-16 10:02:41
select from_unixtime( unix_timestamp('20160816','yyyyMMdd'),'yyyy-MM-dd') --2016-08-16
select date_format('2016-08-16','yyyyMMdd') --20160816
返回日期时间字段中的日期部分
select to_date('2016-08-16 10:03:01') --2016-08-16
取当前时间
select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss')
select from_unixtime(unix_timestamp(),'yyyy-MM-dd')
返回日期中的年
select year('2016-08-16 10:03:01') --2016
返回日期中的月
select month('2016-08-16 10:03:01') --8
返回日期中的日
select day('2016-08-16 10:03:01') --16
返回日期中的时
select hour('2016-08-16 10:03:01') --10
返回日期中的分
select minute('2016-08-16 10:03:01') --3
返回日期中的秒
select second('2016-08-16 10:03:01') --1
返回日期在当前的周数
select weekofyear('2016-08-16 10:03:01') --33
返回结束日期减去开始日期的天数
select datediff('2016-08-16','2016-08-11')
返回开始日期startdate增加days天后的日期
select date_add('2016-08-16',10)
返回开始日期startdate减少days天后的日期
select date_sub('2016-08-16',10)
返回当天三种方式
SELECT CURRENT_DATE;
--2017-06-15
SELECT CURRENT_TIMESTAMP;--返回时分秒
--2017-06-15 19:54:44
SELECT from_unixtime(unix_timestamp());
--2017-06-15 19:55:04
返回当前时间戳
Select current_timestamp--2018-06-18 10:37:53.278
返回当月的第一天
select trunc('2016-08-16','MM') --2016-08-01
返回当年的第一天
select trunc('2016-08-16','YEAR') --2016-01-01
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
Avro (Hive 0.9.1 and later)
ORC (Hive 0.11 and later)
RegEx
Thrift
Parquet (Hive 0.13 and later)
CSV (Hive 0.14 and later)
JsonSerDe (Hive 0.12 and later)
1、MetadataTypedColumnsetSerDe
2、LazySimpleSerDe (这是创建表默认的serde,默认的INPUTFORMAT为
3、TextInputFormat,OUTPUTFORMAT为HiveIgnoreKeyTextOutputFormat)
4、ThriftSerDe
5、DynamicSerDe
6、ThriftSerDe
7、DynamicSerDe
8、JsonSerDe
9、Avro SerDe
10、SerDe for the ORC
11、SerDe for Parquet
12、SerDe for CSV
作者:早点起床晒太阳
链接:https://www.jianshu.com/p/afee9acba686
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
ROW FORMAT SERDE
'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
spark-sql --jars $PATH_TO_SPARK_BUNDLE_JAR
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
————————————————
版权声明:本文为CSDN博主「北国风光8765」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_22473611/article/details/121361733
val result: String = sc.textFile("input").flatMap(_.split(" ")).map((_, 1)).reduceByKey( _ + _).collect().mkString(",")
spark-3.0.1-bin-hadoop3.2免费下载
链接:https://pan.baidu.com/s/1ctd9nXT2DpK0A-60sWH1Kg
提取码:khwl
flink kafka创建表样例:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
scan.startup.mode指定了读取kafka的位置,有几个选项:
group-offsets: start from committed offsets in ZK / Kafka brokers of a specific consumer group.
earliest-offset: start from the earliest offset possible.
latest-offset: start from the latest offset.
timestamp: start from user-supplied timestamp for each partition.
specific-offsets: start from user-supplied specific offsets for each partition.
The default option value is group-offsets which indicates to consume from last committed offsets in ZK / Kafka brokers.
If timestamp is specified, another config option scan.startup.timestamp-millis is required to specify a specific startup timestamp in milliseconds since January 1, 1970 00:00:00.000 GMT.
If specific-offsets is specified, another config option scan.startup.specific-offsets is required to specify specific startup offsets for each partition, e.g. an option value partition:0,offset:42;partition:1,offset:300 indicates offset 42 for partition 0 and offset 300 for partition 1.
官方文档 Start Reading Position
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/table/kafka/#start-reading-position
17. 数据质量监控工具-Apache Griffin
https://blog.csdn.net/vipshop_fin_dev/article/details/86362706
https://blog.csdn.net/qq_35995514/article/details/106528192
2.1 依赖准备
JDK (1.8 or later versions)
MySQL(version 5.6及以上)
Hadoop (2.6.0 or later)
Hive (version 2.x)
Spark (version 2.2.1)
Livy(livy-0.5.0-incubating)
ElasticSearch (5.0 or later versions)
Scala(2.x or later versions)
依赖于 Ambari 安装 Griffin ,所以目前来说只需要安装ES,Scala,初始化Griffin元数据库即可。
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:Apache Dubbo™ 是一款高性能 Java RPC 框架。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
更多组件请参考 Roadmap。
————————————————
版权声明:本文为CSDN博主「L_limo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/L_limo/article/details/108832811
https://gitee.com/zhangjq123/phoenix?_from=gitee_search
生产环境
数据质量监控griffin:
地址:http://XXXXXXXXX:4200/#/health
账号:admin
密码:123456
18.Flink
环境:TableEnvironment
功能
在内部的 catalog 中注册 Table
注册外部的 catalog
加载可插拔模块
执行 SQL 查询
注册自定义函数 (scalar、table 或 aggregation)
将 DataStream 或 DataSet 转换成 Table
持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
Flink与Blink流批环境
https://blog.csdn.net/u013411339/article/details/118563814
创建表
临时表(Temporary Table)
临时表通常保存于内存中并且仅在创建它们的 Flink 会话持续期间存在。这些表对于其它会话是不可见的。它们不与任何 catalog 或者数据库绑定但可以在一个命名空间(namespace)中创建。即使它们对应的数据库被删除,临时表也不会被删除。
永久表(Permanent Table)
永久表需要 catalog(例如 Hive Metastore)以维护表的元数据。一旦永久表被创建,它将对任何连接到 catalog 的 Flink 会话可见且持续存在,直至被明确删除。
这么说吧,在关系型数据库中,分三级:database.schema.table。即一个数据库下面可以包含多个schema,一个schema下可以包含多个数据库对象,比如表、存储过程、触发器等。但并非所有数据库都实现了schema这一层,比如mysql直接把schema和database等效了,PostgreSQL、Oracle、SQL server等的schema也含义不太相同。所以说,关系型数据库中没有catalog的概念。但在一些其它地方(特别是大数据领域的一些组件)有catalog的概念,也是用来做层级划分的,一般是这样的层级关系:catalog.database.table。
作者:时间轨迹
链接:https://www.zhihu.com/question/20355738/answer/1241628708
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
schema是对一个数据库的结构描述。在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。
catalog是由一个数据库实例的元数据组成的,包括基本表,同义词,索引,用户等等。
我的理解是schema有点类似于类,catalog有点类似于对象
create table kafka_sink(
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3)
) with (
'connector' = 'kafka',
'topic' = '<yourTopicName>',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'format' = 'csv'
)
CREATE TABLE filesystem_dim (
id STRING,
name STRING
) WITH (
'connector' = 'filesystem',
'path' = 'csv/json/avro/parquet/orc/raw',
'format' = 'CSV'
)
--创建event源表
CREATE TABLE event (
id STRING,
data STRING
) WITH (
'connector' = 'datahub'
...
);
--创建white_list维表。
CREATE TABLE white_list (
id STRING,
name STRING,
) WITH (
'connector' = 'filesystem',
'path' = '${remote_path_uri}',
'format' = '${format}'
);
--关联event源表和white_list维表。
SELECT e.*, w.*
FROM event AS e
JOIN white_list FOR SYSTEM_TIME AS OF proctime() AS w
ON e.id = w.id;
no name type total hp attack defense special attack special defense speed
https://blog.csdn.net/u013411339/article/details/118563814
https://www.cnblogs.com/fxjwind/p/6957844.html
https://www.cnblogs.com/fxjwind/p/6956222.html
flink on yarn-application
yarn-application 和yarn-per-job,有一些差别,yarn-application 的client只负责发起部署任务的请求,其余的比如 获取作业所需的依赖项;通过执行环境分析并取得逻辑计划,即StreamGraph→JobGraph;将依赖项和JobGraph上传到集群中。都交给集群中的jobmanager来做。
另外,如果一个main()方法中有多个env.execute()/executeAsync()调用,在Application模式下,这些作业会被视为属于同一个应用,在同一个集群中执行(如果在Per-Job模式下,就会启动多个集群)。不过两种模式的jobmanager都是分布在集群当中.
————————————————
版权声明:本文为CSDN博主「杜之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_27474277/article/details/116663318
flink run -t yarn-per-job \
-d -ynm FlinkRetention \
-Dyarn.application.name=FlinkRetention \
-c com.bigdata.etl.FlinkRetention /data/bigdata/flink-dw/target/flink-dw.jar \
--consumer.bootstrap.servers ${consumer_bootstrap_servers} \
--producer.bootstrap.servers ${producer_bootstrap_servers} \
--retentionGroupId ${retentionGroupId} \
--flinkSeconds ${flinkSeconds} \
--redis.ip ${redis_ip} \
--redis.port ${redis_port} \
--redis.password ${redis_password}
flink run -t yarn-per-job \ //指定运行模式
-d -ynm FlinkRetention \ //指定在jobmanager里面显示的名字
-Dyarn.application.name=FlinkRetention \ // 指定在yarn上的application的名字
-c com.bigdata.etl.FlinkRetention // 入口类
/data/bigdata/flink-dw/target/flink-dw.jar \ // 自己任务的jar包
--consumer.bootstrap.servers ${consumer_bootstrap_servers} \ 需要传入的参数
--producer.bootstrap.servers ${producer_bootstrap_servers} \
--retentionGroupId ${retentionGroupId} \
--flinkSeconds ${flinkSeconds} \
--redis.ip ${redis_ip} \
--redis.port ${redis_port} \
--redis.password ${redis_password}
flink run-application -t yarn-application \
-ynm FlinkRetention \
-Dyarn.application.name=FlinkRetention \
-Dyarn.provided.lib.dirs="hdfs:///tmp/flink-1.13.0/lib;hdfs:///tmp/flink-1.13.0/plugins" \
-c com.bigdata.etl.FlinkRetention /data/bigdata/flink-dw/target/flink-dw.jar \
--consumer.bootstrap.servers ${consumer_bootstrap_servers} \
--producer.bootstrap.servers ${producer_bootstrap_servers} \
--retentionGroupId ${retentionGroupId} \
--flinkSeconds ${flinkSeconds} \
--redis.ip ${redis_ip} \
--redis.port ${redis_port} \
--redis.password ${redis_password}
https://mvnrepository.com/artifact/org.apache.hadoop
https://www.cnblogs.com/hulichao/p/14800202.html
# flink部署
1. standalone 模式
2. yarn模式
session-cluster模式
job-cluster模式
3. k8s模式
注:yarn模式需要依赖hadoop环境,
搭建请参考:https://blog.csdn.net/AinUser/article/details/120142220
# 1. standalone模式
直接下载flink-1.13.0安装包
https://archive.apache.org/dist/flink/flink-1.13.1/
启动start-cluster.sh脚本即可
# 2. session-cluster模式
2.1. 搭建hadoop集群
参考上面连接,将hadoop集群搭建完成且正确
2.2. 启动yarn-session
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(--container): TaskManager 的数量。
-s(--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个
taskmanager 的 slot 的个数为 1, 有时可以多一些 taskmanager,做冗余。
-jm: JobManager 的内存( 单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm: yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
2.3. 执行任务
./flink run -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
2.4. 查看任务状态
hadoop:http://master:8088/cluster/nodes
flink:http://master:8082
2.5. 取消yarn-session
yarn application --kill application_1577588252906_0001
# 3. job-cluster
3.1. 启动hadoop集群
3.2. 不用启动yarn-session,直接执行如下job启动命令
3.3. 启动job命令
./flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
3.4. 查看启动任务
flink:http://master:8082
# 4. k8s部署
4.1. k8s启动flink-session-cluster
// 启动 jobmanager-service 服务
kubectl create -f jobmanager-service.yaml
// 启动 jobmanager-deployment 服务
kubectl create -f jobmanager-deployment.yaml
// 启动 taskmanager-deployment 服务
kubectl create -f taskmanager-deployment.yaml
4.2. 访问flink UI
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanage r:ui/proxy
https://blog.csdn.net/weixin_40954192/article/details/107513687
//CBO优化
sparkConf.set("spark.sql.cbo.enabled","true")
sparkConf.set("spark.sql.cbo.joinReorder.enabled","true")
sparkConf.set("spark.sql.statistics.histogram.enabled","true")
//自适应查询优化(2.4版本之后)
sparkConf.set("spark.sql.adaptive.enabled","true")
//开启consolidateFiles
sparkConf.set("spark.shuffle.consolidateFiles","true")
//设置并行度
sparkConf.set("spark.default.parallelism","150")
//设置数据本地化等待时间
sparkConf.set("spark.locality.wait","6s")
//设置mapTask写磁盘缓存
sparkConf.set("spark.shuffle.file.buffer","64k")
//设置byPass机制的触发值
sparkConf.set("spark.shuffle.sort.bypassMergeThreshold","1000")
//设置resultTask拉取缓存
sparkConf.set("spark.reducer.maxSizeInFlight","48m")
//设置重试次数
sparkConf.set("spark.shuffle.io.maxRetries","10")
//设置重试时间间隔
sparkConf.set("spark.shuffle.io.retryWait","10s")
//设置reduce端聚合内存比例
sparkConf.set("spark.shuffle.memoryFraction","0.5")
//设置序列化
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//设置自动分区
sparkConf.set("spark.sql.auto.repartition","true")
//设置shuffle过程中分区数
sparkConf.set("spark.sql.shuffle.partitions","500")
//设置自动选择压缩码
sparkConf.set("spark.sql.inMemoryColumnarStorage.compressed","true")
//关闭自动推测分区字段类型
sparkConf.set("spark.sql.source.partitionColumnTypeInference.enabled","false")
//设置spark自动管理内存
sparkConf.set("spark.sql.tungsten.enabled","true")
//执行sort溢写到磁盘
sparkConf.set("spark.sql.planner.externalSort","true")
//增加executor通信超时时间
sparkConf.set("spark.executor.heartbeatInterval","60s")
//cache限制时间
sparkConf.set("spark.dynamicAllocation.cachedExecutorIdleTimeout","120")
//设置广播变量
sparkConf.set("spark.sql.autoBroadcastJoinThreshold","104857600")
//其他设置
sparkConf.set("spark.sql.files.maxPartitionBytes","268435456")
sparkConf.set("spark.sql.files.openCostInBytes","8388608")
sparkConf.set("spark.debug.maxToStringFields","500")
//推测执行机制
sparkConf.set("spark.speculation","true")
sparkConf.set("spark.speculation.interval","500")
sparkConf.set("spark.speculation.quantile","0.8")
sparkConf.set("spark.speculation.multiplier","1.5")
https://blog.csdn.net/u013411339/article/details/113532880
<hive.version>2.3.6</hive.version>
https://blog.csdn.net/apprentices/article/details/100662356
url:在url后加上参数rewriteBatchedStatements=true表示MySQL服务开启批次写入,此参数是批次写入的一个比较重要参数,可明显提升性能
batchsize:DataFrame writer批次写入MySQL 的条数,也为提升性能参数
isolationLevel:事务隔离级别,DataFrame写入不需要开启事务,为NONE
truncate:overwrite模式时可用,表时在覆盖原始数据时不会删除表结构而是复用
————————————————
版权声明:本文为CSDN博主「banana`」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Realoyou/article/details/97632376
https://www.cnblogs.com/wh984763176/p/13675261.html
之前一直报错,akka,AskTimeoutException,尝试添加akka.ask.timeout=120000s, 依然显示该错误。
后来在Flink官网找到了该参数的赋值方式,注意这里有个大坑,数字和时间单位之间,必须有个空格。
shell脚本如下,具体数值大家可以自己根据实际情况调节:
flink run \
-m yarn-cluster \
-ynm applicaiton-name \
-yqu queue \
-p 4000 \
-ys 4 \
-yjm 10g \
-ytm 10g \
-yD akka.client.timeout="120000 s" \
-yD akka.ask.timeout="120000 s" \
-yD web.timeout=120000 \
-yD rest.retry.max-attempts=100 \
-c your-class \
your-jar your-input your-output
1 参数必选 :
-n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量)
2 参数可选 :
-D <arg> 动态属性
-d,--detached 独立运行
-jm,--jobManagerMemory <arg> JobManager的内存 [in MB]
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue <arg> 指定YARN队列.
-s,--slots <arg> 每个TaskManager使用的slots数量
-tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace
-id,--applicationId <yarnAppId> YARN集群上的任务id,附着到一个后台运行的yarn session中
3 run [OPTIONS] <jar-file> <arguments>
run操作参数:
-c,--class <classname> 如果没有在jar包中指定入口类,则需要在这里通过这个参数指定
-m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager
-p,--parallelism <parallelism> 指定程序的并行度。可以覆盖配置文件中的默认值。
4 启动一个新的yarn-session,它们都有一个y或者yarn的前缀
例如:./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
连接指定host和port的jobmanager:
./bin/flink run -m SparkMaster:1234 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
启动一个新的yarn-session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
5 注意:命令行的选项也可以使用./bin/flink 工具获得。
6 Action "run" compiles and runs a program.
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
-c,--class <classname> Class with the program entry point
("main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
-C,--classpath <url> Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify a
protocol (e.g. file://) and be
accessible on all nodes (e.g. by means
of a NFS share). You can use this
option multiple times for specifying
more than one URL. The protocol must
be supported by the {@link
java.net.URLClassLoader}.
-d,--detached If present, runs the job in detached
mode
-n,--allowNonRestoredState Allow to skip savepoint state that
cannot be restored. You need to allow
this if you removed an operator from
your program that was part of the
program when the savepoint was
triggered.
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-q,--sysoutLogging If present, suppress logging output to
standard out.
-s,--fromSavepoint <savepointPath> Path to a savepoint to restore the job
from (for example
hdfs:///flink/savepoint-1537).
7 Options for yarn-cluster mode:
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <arg> Address of the JobManager (master) to
which to connect. Use this flag to
connect to a different JobManager than
the one specified in the
configuration.
-yD <property=value> use value for given property
-yd,--yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,--yarnhelp Help for the Yarn session CLI.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-yj,--yarnjar <arg> Path to Flink jar file
-yjm,--yarnjobManagerMemory <arg> Memory for JobManager Container with
optional unit (default: MB)
-yn,--yarncontainer <arg> Number of YARN container to allocate
(=Number of Task Managers)
-ynl,--yarnnodeLabel <arg> Specify YARN node label for the YARN
application
-ynm,--yarnname <arg> Set a custom name for the application
on YARN
-yq,--yarnquery Display available YARN resources
(memory, cores)
-yqu,--yarnqueue <arg> Specify YARN queue.
-ys,--yarnslots <arg> Number of slots per TaskManager
-yst,--yarnstreaming Start Flink in streaming mode
-yt,--yarnship <arg> Ship files in the specified directory
(t for transfer)
-ytm,--yarntaskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yz,--yarnzookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
Flink提交方式
flink同样支持两种提交方式,默认不指定就是客户端方式
如果需要使用集群方式提交的话。可以在提交作业的命令行中指定-d或者–detached 进行进群模式提交。
-d,–detached If present, runs the job indetached mode(分离模式)
————————————————
版权声明:本文为CSDN博主「雾幻」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lb812913059/article/details/86601150
客户端提交:
FLINK_HOME/bin/flink run -c com.daxin.batch.App flinkwordcount.jar
客户端会多出来一个CliFrontend进程,就是驱动进程。
集群模式提交:
FLINK_HOME/bin/flink run -d -c com.daxin.batch.App flinkwordcount.jar
程序提交完毕退出客户端,不在打印作业进度等信息!
Flink on yarn
请首先确保Hadoop HDFS、YARN集群模式的正确运行,测试flink on yarn是否可以正常运行:
cd $FLINK_HOME
1
提交flink任务到yarn
$ ./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
————————————————
版权声明:本文为CSDN博主「雾幻」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lb812913059/article/details/86601150
参数介绍
yarn-session的参数介绍
-n : 指定TaskManager的数量;
-d: 以分离模式运行;
-id:指定yarn的任务ID;
-j:Flink jar文件的路径;
-jm:JobManager容器的内存(默认值:MB);
-nl:为YARN应用程序指定YARN节点标签;
-nm:在YARN上为应用程序设置自定义名称;
-q:显示可用的YARN资源(内存,内核);
-qu:指定YARN队列;
-s:指定TaskManager中slot的数量;
-st:以流模式启动Flink;
-tm:每个TaskManager容器的内存(默认值:MB);
-z:命名空间,用于为高可用性模式创建Zookeeper子路径;
https://blog.csdn.net/MrZhangBaby/article/details/87797333
https://www.cnblogs.com/liugh/p/7533194.html
解决方案:
状态存储,默认是在内存中,改为存储到HDFS中:
state.backend.fs.checkpointdir: hdfs://t-sha1-flk-01:9000/flink-checkpoints
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mnt/hadoop/dfs/name</value>
</property>
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /flink/flink-checkpoints/5e2ccb2286635ec83f01a40f6f0a70bd/chk-90071/8a62f009-1897-4dab-8f7f-dd3a0e4ddfda (inode 7149764): File does not exist. Holder DFSClient_NONMAPREDUCE_1989935438_58 does not have any open files.
Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs://192.168.3.60:8020/flink/flink-checkpoints/5e2ccb2286635ec83f01a40f6f0a70bd/chk-90071/8a62f009-1897-4dab-8f7f-dd3a0e4ddfda in order to obtain the stream state handle
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Could not flush and close the file system output stream to hdfs://192.168.3.60:8020/flink/flink-checkpoints/5e2ccb2286635ec83f01a40f6f0a70bd/chk-90071/8a62f009-1897-4dab-8f7f-dd3a0e4ddfda in order to obtain the stream state handle
AsynchronousException{java.lang.Exception: Could not materialize checkpoint 90071 for operator groupBy: (devid, itemname), window: (TumblingGroupWindow('w$, 'htime, 20000.millis))
https://blog.csdn.net/lijingjingchn/category_8637886.html
BoundedOutOfOrdernessTimestampExtractor:适用于乱序但最大延迟已知的情况
AscendingTimestampExtractor:适用于时间戳递增的情况
1、允许一定时间延迟的时间戳分配程序
如果我们希望生成的水印有一定的延迟,则可以继承BoundedOutOfOrdernessTimestampExtractor类。
请看下面这个示例代码(使用Java代码):
DataStream<MyEvent> stream = ...
DataStream<MyEvent> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(new MyExtractor());
public static class MyExtractor extends BoundedOutOfOrdernessTimestampExtractor<MyEvent> {
public MyExtractor() {
super(Time.seconds(10));
}
@Override
public long extractTimestamp(MyEvent event) {
return element.getCreationTime();
}
}
注意,上面代码中的BoundedOutOfOrdernessTimestampExtractor的构造函数接受一个参数,该参数指定最大的期望out-of-orderness(在本例中为10秒)。
2、具有升序时间戳的时间戳分配程序
最简单的情况是给定源任务看到的时间戳按升序出现。在这种情况下,当前时间戳始终可以作为水印。
请看下面的示例代码(使用Java代码):
DataStream<MyEvent> stream = ...
DataStream<MyEvent> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(new MyExtractor());
public static class MyExtractor extends AscendingTimestampExtractor<MyEvent> {
@Override
public long extractAscendingTimestamp(MyEvent element) {
return element.getCreationTime();
}
});
可以通过实现一个时间戳提取器和水印生成器来实现来向事件分配时间戳和水印。
默认情况下,Flink将使用处理时间。要改变这个,可以设置时间特征:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果想使用事件时间,则还需要提供一个时间戳提取器和水印生成器,Flink将使用它来跟踪事件时间的进展。
在测试Flink流处理程序的Process Function时,遇到如下的异常:
......
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
......
Caused by: java.lang.NullPointerException
at scala.Predef$.Long2long(Predef.scala:363)
at com.xueai8.StreamingJob$CountWithTimeoutFunction.processElement ......
......
问题排查
当在Flink中使用事件时间时,必须安排事件具有时间戳,并为流设置水印。上面的异常是因为我们在测试ProcessFunction时,使用的数据事件没有时间戳,从而造成代码在执行过程中提取时间戳时出现Null空值异常。
Flink配置JVM参数
flink-conf.yaml新增一行env.java.opts.taskmanager: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
flink on yarn提交脚本加入 -yD env.java.opts.taskmanager="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp"
CDH 搜索jvm关键字
作者:清蒸三文鱼_
链接:https://www.jianshu.com/p/0f8b477f6552
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://www.jianshu.com/p/9c2f5e020ec9
1、Flink 提供了 8 个 Process Function:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
BroadcastProcessFunction
KeyedBroadcastProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
2、KeyedProcessFunction重要方法:
a)processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素 都会调用这个方法,调用结果将会放在 Collector 数据类型中输出。Context 可以访问元素的时间戳,元素的 key,以及 TimerService 时间服务。Context 还可以将结果输出到别的流(side outputs)。
b)onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])是一个回 调函数。当之前注册的定时器触发时调用。参数 timestamp 为定时器所设定 的触发的时间戳。Collector 为输出结果的集合。OnTimerContext 和 processElement 的 Context 参数一样,提供了上下文的一些信息,例如定时器 触发的时间信息(事件时间或者处理时间)。
3、Context 和 OnTimerContext 所持有的 TimerService 对象拥有以下方法:
currentProcessingTime(): Long 返回当前处理时间
currentWatermark(): Long 返回当前 watermark 的时间戳 registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前 key 的 processing time 的定时器。当 processing time 到达定时时间时,触发 timer。
registerEventTimeTimer(timestamp: Long): Unit 会注册当前 key 的 event time 定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。 deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定 时器。如果没有这个时间戳的定时器,则不执行 deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时 器,如果没有此时间戳的定时器,则不执行。 当定时器 timer 触发时,会执行回调函数 onTimer()。注意定时器 timer 只能在 keyed streams 上面使用。
Table API 和 SQL 的程序结构,与流式处理的程序结构类似;也可以近似地认为有这么 几步:首先创建执行环境,然后定义 source、transform 和 sink。
<!-- old planner flink table-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<!--new planner-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
FlinkTable步骤:
// 1、创建表的执行环境
val tableEnv = ...
// 2、创建一张表,用于读取数据
tableEnv.connect(...).createTemporaryTable("inputTable")
// 3、1通过 Table API 查询算子,得到一张结果表
val result = tableEnv.from("inputTable").select(...)
// 3、2通过 SQL 查询语句,得到一张结果表
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM inputTable ...")
// 4、注册一张表,用于把计算结果输出
tableEnv.connect(...).createTemporaryTable("outputTable")
// 5、将结果表写入输出表中
result.insertInto("outputTable")
toAppendStream:
只对增加的新数据有效,较为局限
实现为
extends RichSinkFunction<Row>
toRetractStream:更新的数据为true,未更新为false
implements SinkFunction<Tuple2<Boolean, Row>>
————————————————
版权声明:本文为CSDN博主「_东极」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wwwzydcom/article/details/103658925
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
将一个table转化为一个DataStream的时候,有两种选择
toAppendStream :在没有聚合操作的时候使用
toRetractStream(缩放的含义) :在进行聚合操作之后使用
追加模式(toAppendStream)与缩进模式(toRetractStream)
简介
使用flinkSQL处理实时数据当我们把表转化成流的时候,需要使用toAppendStream与toRetractStream这两个方法。稍不注意可能直接选择了toAppendStream。这个两个方法还是有很大区别的,下面具体介绍。
toAppendStream与toRetractStream的区别:
追加模式:只有在动态Table仅通过INSERT更改修改时才能使用此模式,即它仅附加,并且以前发出的结果永远不会更新。
如果更新或删除操作使用追加模式会失败报错
缩进模式:始终可以使用此模式。返回值是boolean类型。它用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回
按照官网的理解如果数据只是不断添加,可以使用追加模式,其余方式则不可以使用追加模式,而缩进模式侧可以适用于更新,删除等场景。具体的区别 如下图所示:
————————————————
————————————————
版权声明:本文为CSDN博主「GOD_WAR」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/young_0609/article/details/109466857
. Timestamp和Watermark都是基于事件的时间字段生成的
. Timestamp和Watermark是两个不同的东西,并且一旦生成都跟事件数据没有关系了(所有即使事件中不再包含生成Timestamp和Watermark的字段也没关系)
. 事件数据和 Timestamp 一一对应(事件在流中传递以StreamRecord对象表示,value 和 timestamp 是它的两个成员变量)
. Watermark 在生成之后与事件数据没有直接关系,Watermark 作为一个消息,和事件数据一样在流中传递(Watermark 和StreamRecord 具有相同的父类:StreamElement)
. Timestamp 与 Watermark 在生成之后,会在下游window算子中做比较,判断事件数据是否是过期数据
. 只有window算子才会用Watermark判断事件数据是否过期
val input = env.addSource(source)
.map(json => {
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
// flink auto create timestamp & watermark
.assignAscendingTimestamps(element => sdf.parse(element.createTime).getTime)
(1)assignTimestamps(extractor: TimestampExtractor[T]): DataStream[T]
此方法是数据流的快捷方式,其中已知元素时间戳在每个并行流中单调递增。在这种情况下,系统可以通过跟踪上升时间戳自动且完美地生成水印。
注:这种方法创建时间戳与水印最简单,返回一个long类型的数字就可以了
(2)assignTimestampsAndWatermarks
2.assignTimestampsAndWatermarks(assigner: AssignerWithPeriodicWatermarks[T]): DataStream[T]
基于给定的水印生成器生成水印,即使没有新元素到达也会定期检查给定水印生成器的新水印,以指定允许延迟时间
val input = env.addSource(source)
.map(json => {
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
// assign timestamp & watermarks periodically(定期生成水印)
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[LateDataEvent](Time.milliseconds(50)) {
override def extractTimestamp(element: LateDataEvent): Long = {
println("want watermark : " + sdf.parse(element.createTime).getTime)
sdf.parse(element.createTime).getTime
}
})
3.assignTimestampsAndWatermarks(assigner: AssignerWithPeriodicWatermarks[T]): DataStream[T]
此方法仅基于流元素创建水印,对于通过[[AssignerWithPunctuatedWatermarks#extractTimestamp(Object,long)]]处理的每个元素,
调用[[AssignerWithPunctuatedWatermarks#checkAndGetNextWatermark()]]方法,如果返回的水印值大于以前的水印,会发出新的水印,
此方法可以完全控制水印的生成,但是要注意,每秒生成数百个水印会影响性能
val input = env.addSource(source)
.map(json => {
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
// assign timestamp & watermarks every event
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[LateDataEvent]() {
// check extractTimestamp emitted watermark is non-null and large than previously
override def checkAndGetNextWatermark(lastElement: LateDataEvent, extractedTimestamp: Long): Watermark = {
new Watermark(extractedTimestamp)
}
// generate next watermark
override def extractTimestamp(element: LateDataEvent, previousElementTimestamp: Long): Long = {
val eventTime = sdf.parse(element.createTime).getTime
eventTime
}
})
----003
// assign timestamp & watermarks every event
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[SensorReading]() {
// check extractTimestamp emitted watermark is non-null and large than previously
override def checkAndGetNextWatermark(lastElement: SensorReading, extractedTimestamp: Long): Watermark = {
new Watermark(extractedTimestamp)
}
// generate next watermark
override def extractTimestamp(element: SensorReading, previousElementTimestamp: Long): Long = {
val eventTime = element.timestamp
eventTime
}
})
val input: DataStream[Int] = ...
val outputTag = OutputTag[String]("side-output")
val mainDataStream = input
.process(new ProcessFunction[Int, Int] {
override def processElement(
value: Int,
ctx: ProcessFunction[Int, Int]#Context,
out: Collector[Int]): Unit = {
// 将数据发送到常规输出中
out.collect(value)
// 将数据发送到侧输出中
ctx.output(outputTag, "sideout-" + String.valueOf(value))
}
})
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
为了解决这个问题,你可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。WatermarkStrategy 为此提供了一个工具接口:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1))
TimestampAssigner 是一个可以从事件数据中提取时间戳字段的简单函数,我们无需详细查看其实现。但是 WatermarkGenerator 的编写相对就要复杂一些了,我们将在接下来的两小节中介绍如何实现此接口。WatermarkGenerator 接口代码如下:
watermark 的生成方式本质上是有两种:周期性生成和标记生成。
周期性生成器通常通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark。
标记生成器将查看 onEvent() 中的事件数据,并等待检查在流中携带 watermark 的特殊标记事件或打点数据。当获取到这些事件数据时,它将立即发出 watermark。通常情况下,标记生成器不会通过 onPeriodicEmit() 发出 watermark。
周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间)。
生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定。每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的 watermark 非空且值大于前一个 watermark,则将发出新的 watermark。
如下是两个使用周期性 watermark 生成器的简单示例。注意:Flink 已经附带了 BoundedOutOfOrdernessWatermarks,它实现了 WatermarkGenerator,其工作原理与下面的 BoundedOutOfOrdernessGenerator 相似。可以在这里参阅如何使用它的内容。
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxOutOfOrderness = 3500L // 3.5 秒
var currentMaxTimestamp: Long = _
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)
}
override def onPeriodicEmit(): Unit = {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
/**
* 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。
*/
class TimeLagWatermarkGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxTimeLag = 5000L // 5 秒
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
// 处理时间场景下不需要实现
}
override def onPeriodicEmit(): Unit = {
output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));
}
}
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(10))
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20)) //延迟20秒
.withTimestampAssigner(new SerializableTimestampAssigner[(Long, String)] {
override def extractTimestamp(element: (Long, String), recordTimestamp: Long): Long = element._1
})
val withTimestampsAndWatermarks: DataStream[SensorReading] = dataStream
.filter( _.severity == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>)
withTimestampsAndWatermarks
.keyBy( _.getGroup )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) => a.add(b) )
.addSink(...)
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1))
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxOutOfOrderness = 3500L // 3.5 秒
var currentMaxTimestamp: Long = _
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
currentMaxTimestamp = max(eventTimestamp, currentMaxTimestamp)
}
override def onPeriodicEmit(): Unit = {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
/**
* 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。
*/
class TimeLagWatermarkGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxTimeLag = 5000L // 5 秒
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
// 处理时间场景下不需要实现
}
override def onPeriodicEmit(): Unit = {
output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));
}
}
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[MyEvent] {
override def onEvent(element: MyEvent, eventTimestamp: Long): Unit = {
if (event.hasWatermarkMarker()) {
output.emitWatermark(new Watermark(event.getWatermarkTimestamp()))
}
}
override def onPeriodicEmit(): Unit = {
// onEvent 中已经实现
}
}
map方法不允许缺少数据,也就是原来多少条数据,处理后依然是多少条数据,只是用来做转换。
@Slf4j
public class KafkaUrlSinkJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("zookeeper.connect", "localhost:2181");
properties.put("group.id", "metric-group");
properties.put("auto.offset.reset", "latest");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
SingleOutputStreamOperator<UrlInfo> dataStreamSource = env.addSource(
new FlinkKafkaConsumer010<String>(
"testjin",// topic
new SimpleStringSchema(),
properties
)
).setParallelism(1)
// map操作,转换,从一个数据流转换成另一个数据流,这里是从string-->UrlInfo
.map(string -> JSON.parseObject(string, UrlInfo.class))
}
--0x01
// 构造一个嵌套的数据
SingleOutputStreamOperator<List<UrlInfo>> listDataStreaamSource = dataStreamSource
.map(urlInfo -> {
List<UrlInfo> list = Lists.newArrayList();
list.add(urlInfo);
UrlInfo urlInfo1 = new UrlInfo();
urlInfo1.setUrl(urlInfo.getUrl() + "-copy");
urlInfo1.setHash(DigestUtils.md5Hex(urlInfo1.getUrl()));
list.add(urlInfo1);
return list;
}).returns(new ListTypeInfo(UrlInfo.class));
listDataStreaamSource.addSink(new PrintSinkFunction<>());
开始到window了,先回顾下入门版概念中对window的定义:
Window的定义
window:用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window 又可以分为基于时间(Time-based)的 window 以及基于数量(Count-based)的 window。
KeyedStream→WindowedStream,注意datasource类型有变化
可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组。有关窗口的完整说明,请参见windows。
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data
tumbling time windows(翻滚时间窗口) -- 不会有窗口重叠,也就是一个元素只能出现在一个窗口中
sliding time windows(滑动时间窗口)--会有窗口重叠,也就是一个元素可以出现在多个窗口中
data.keyBy(1)
.timeWindow(Time.minutes(1)) //tumbling time window 每分钟统计一次数量和
.sum(1);
data.keyBy(1)
.timeWindow(Time.minutes(1), Time.seconds(30)) //sliding time window 每隔 30s 统计过去一分钟的数量和
.sum(1);
timeWindow: 如上所说,根据时间来聚合流数据。例如:一分钟的 tumbling time window 收集一分钟的元素,并在一分钟过后对窗口中的所有元素应用于一个函数。
windowAll:
DataStream→AllWindowedStream,可以在非分区的数据上直接做windowAll操作
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。有关窗口的完整说明,请参见windows。
警告:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data
官方文档中关于Window的说明:
Windows是处理无限流的核心。Windows将流拆分为有限大小的“桶”,我们可以在其上应用计算。本文档重点介绍如何在Flink中执行窗口,以及程序员如何从其提供的函数中获益最大化。
窗口Flink程序的一般结构如下所示。第一个片段指的是被Keys化流,而第二个片段指的是非被Keys化流。正如人们所看到的,唯一的区别是window(...)针对keyby之后的keyedStream,而windowAll(...)针对非被Key化的数据流。
被Keys化Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
非被Keys化Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
在上面,方括号([...])中的命令是可选的。这表明Flink允许您以多种不同方式自定义窗口逻辑,以便最适合您的需求。
window VS timeWindow
flink中keyedStream中还有一个timeWindow方法,这个方法是在window的基础上做的封装,看下代码实现:
/**
* Windows this {@code KeyedStream} into tumbling time windows.
*
* <p>This is a shortcut for either {@code .window(TumblingEventTimeWindows.of(size))} or
* {@code .window(TumblingProcessingTimeWindows.of(size))} depending on the time characteristic
* set using
* {@link org.apache.flink.streaming.api.environment.StreamExecutionEnvironment#setStreamTimeCharacteristic(org.apache.flink.streaming.api.TimeCharacteristic)}
*
* @param size The size of the window.
*/
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(TumblingProcessingTimeWindows.of(size));
} else {
return window(TumblingEventTimeWindows.of(size));
}
}
/**
* Windows this {@code KeyedStream} into sliding time windows.
*
* <p>This is a shortcut for either {@code .window(SlidingEventTimeWindows.of(size, slide))} or
* {@code .window(SlidingProcessingTimeWindows.of(size, slide))} depending on the time
* characteristic set using
* {@link org.apache.flink.streaming.api.environment.StreamExecutionEnvironment#setStreamTimeCharacteristic(org.apache.flink.streaming.api.TimeCharacteristic)}
*
* @param size The size of the window.
*/
public WindowedStream<T, KEY, TimeWindow> timeWindow(Time size, Time slide) {
if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) {
return window(SlidingProcessingTimeWindows.of(size, slide));
} else {
return window(SlidingEventTimeWindows.of(size, slide));
}
}
可以看到,不管是tumbling time windows,还是sliding time windows,底层都是window方法,所以在具体实现时,大多数情况下可以直接使用timewindow来替换window。
filnk中的Time类型
从上面代码中可以看到,有Processing Time、Event Time,其实还有一种,叫Ingestion Time,以下解释转自flink官网及《从0到1学习Flink》(http://www.54tianzhisheng.cn/)—— Flink 中几种 Time 详解中的说明,如下:
Processing Time:
Processing Time 是指事件被处理时机器的系统时间。
当流程序在 Processing Time 上运行时,所有基于时间的操作(如时间窗口)将使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
例如,如果应用程序在上午 9:15 开始运行,则第一个每小时 Processing Time 窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
Processing Time 是最简单的 “Time” 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
Processing time refers to the system time of the machine that is executing the respective operation.
When a streaming program runs on processing time, all time-based operations (like time windows) will use the system clock of the machines that run the respective operator. An hourly processing time window will include all records that arrived at a specific operator between the times when the system clock indicated the full hour. For example, if an application begins running at 9:15am, the first hourly processing time window will include events processed between 9:15am and 10:00am, the next window will include events processed between 10:00am and 11:00am, and so on.
Processing time is the simplest notion of time and requires no coordination between streams and machines. It provides the best performance and the lowest latency. However, in distributed and asynchronous environments processing time does not provide determinism, because it is susceptible to the speed at which records arrive in the system (for example from the message queue), to the speed at which the records flow between operators inside the system, and to outages (scheduled, or otherwise).
简单来说,processing time 就是在flink集群上,当前数据被处理的时间;以flink集群当前时间为准。
不过就像上面说的,在分布式和异步的场景下,PT无法保证数据处理的时间跟数据真正发生的时间是一致的,因为MQ可能会乱序到达、重试之后到达;而数据在flink中处理时,并发下,某些线程处理速度的快慢也有可能会导致某些数据后发而先至。
Event Time:
Event Time 是事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
完美的说,无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(按照事件的时间)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
假设所有数据都已到达, Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,无论它们到达的顺序如何。
请注意,有时当 Event Time 程序实时处理实时数据时,它们将使用一些 Processing Time 操作,以确保它们及时进行。
Event time is the time that each individual event occurred on its producing device. This time is typically embedded within the records before they enter Flink, and that event timestamp can be extracted from each record. In event time, the progress of time depends on the data, not on any wall clocks. Event time programs must specify how to generate Event Time Watermarks, which is the mechanism that signals progress in event time. This watermarking mechanism is described in a later section, below.
In a perfect world, event time processing would yield completely consistent and deterministic results, regardless of when events arrive, or their ordering. However, unless the events are known to arrive in-order (by timestamp), event time processing incurs some latency while waiting for out-of-order events. As it is only possible to wait for a finite period of time, this places a limit on how deterministic event time applications can be.
Assuming all of the data has arrived, event time operations will behave as expected, and produce correct and consistent results even when working with out-of-order or late events, or when reprocessing historic data. For example, an hourly event time window will contain all records that carry an event timestamp that falls into that hour, regardless of the order in which they arrive, or when they are processed. (See the section on late events for more information.)
Note that sometimes when event time programs are processing live data in real-time, they will use some processing time operations in order to guarantee that they are progressing in a timely fashion.
简单来说,event time就是数据在各自的业务服务器上产生的时间,跟flink无关。
不过由于ET数据到达的方式可能会出现乱序,flink在处理数据的时候就需要等待一些时间,确保一些无序事件都被处理掉,也就导致了会出现延迟。
另外,由于ET数据处理和flink中时间无关,所以要指定watermark,即水印,用于表示当前数据处理的进度。
Ingestion Time:
Ingestion Time 是事件进入 Flink 的时间。 在源操作处,每个事件将源的当前时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,它稍微重一些,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(在源处分配一次),所以对事件的不同窗口操作将引用相同的时间戳,而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序不必指定如何生成水印。
在 Flink 中,,Ingestion Time 与 Event Time 非常相似,但 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
Ingestion time is the time that events enter Flink. At the source operator each record gets the source’s current time as a timestamp, and time-based operations (like time windows) refer to that timestamp.
Ingestion time sits conceptually in between event time and processing time. Compared to processing time, it is slightly more expensive, but gives more predictable results. Because ingestion time uses stable timestamps (assigned once at the source), different window operations over the records will refer to the same timestamp, whereas in processing time each window operator may assign the record to a different window (based on the local system clock and any transport delay).
Compared to event time, ingestion time programs cannot handle any out-of-order events or late data, but the programs don’t have to specify how to generate watermarks.
Internally, ingestion time is treated much like event time, but with automatic timestamp assignment and automatic watermark generation.
介于PT和ET之间,指数据进入到Flink中的时间。
Time图
下面一张图表示了各个时间的产生(来自官网):
flink-times-clock.png
这个图画的很清晰,可以很清楚的看到每种类型的时间产生的位置。
参考资料:
http://www.54tianzhisheng.cn/2018/12/11/Flink-time/
http://www.54tianzhisheng.cn/2018/12/08/Flink-Stream-Windows/
作者:AlanKim
链接:https://www.jianshu.com/p/68463ff911d9
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:AlanKim
链接:https://www.jianshu.com/p/68463ff911d9
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/event_timestamp_extractors.html
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/dev/datastream/event-time/generating_watermarks/
18..1 追加模式(toAppendStream)与缩进模式(toRetractStream)
通过上图可以清晰的看到两种方式的区别,当我们使用的sql语句包含:count() group by时,必须使用缩进模式。
19.算法
19.1 Mahout算法
聚类算法
聚类分析又称为群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。
聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是一个度量(Measurement)的向量,或者是多维空间中的一个点。
聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。
聚类的用途是很广泛的。
分类算法
分类(Categorization or Classfication)就是按照某种标准给对象贴标签(lable),再根据标签来区分归类。
分类是事先定义好类别,类别数不变。
案例
比如程序是区分大豆和绿豆的。我们输入的数据是比如颜色值、半径大小,属于黄豆还是绿豆等等(当然这是个简单的例子)。首先我们需要拿出一些“豆子”的数据给程序,并告诉它是黄豆还是绿豆,然后通过自己的算法,让程序“计算”出区分两种东西的“边界条件”,或者简单说就是提取特征(一般用的比较多的就是距离)。这就相当于训练/学习等概念。
分类是一种基于训练样本数据(这些数据都已经被贴标签)区分另外的样本数据标签的过程,即另外的样本数据应该如何贴标签的问题。举一个简单的例子,现在有一批人的血型已经被确定,并且每个人都有M个指标来描述这个人,那么这批人的M个指标数据就是训练样本数据(这些数据都是已经被贴好标签了的),根据这些训练样本数据,建立分类器(即运用分类算法得到一些规则),然后使用分类器对测试样本集中的未被贴标签的数据进行血型判断。
分类算法和聚类算法的不同之处在于,分类是有指导的学习,而聚类是一种无指导的学习。有指导和无指导其实是指在训练的时候训练样本数据是否提前被贴上了标签。
Mahout算法库中分类模块包含的算法有:Logistic Regression、Bayesian、Support Vector Machine、Random Forests、Hidden Markov Models。
在Mahout算法库中,频繁项集挖掘算法主要是指FP树关联规则算法。传统关联规则算法是根据数据集建立FP树,然后对FP树进行挖掘,得到数据库的频繁项集。在Mahout中实现并行FP树关联规则算法的主要思路是按照一定的规则把数据集分开,然后在每个分开的部分数据集建立FP树,然后再对FP树进行挖掘,得到频繁项集。这里使用的是把数据集分开的规则,可以保证最后通过所有FP树挖掘出来的频繁项集全部加起来没有遗漏,但是会有少量重叠。
https://www.cnblogs.com/jpfss/articles/9013265.html
https://www.cnblogs.com/jpfss/articles/9013280.html
http://blog.fens.me/hadoop-mahout-recommend-job/
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8
Dromara这个开源组织里的项目只针对Java
Cubic
一站式问题定位平台!线程栈监控、线程池监控、动态arthas命令集、依赖分析等等等,强不强大,香不香?
官方网站:https://cubic.jiagoujishu.com/
Gitee托管仓库:https://gitee.com/dromara/cubic
Github托管仓库:https://github.com/dromara/cubic
首先我要介绍的是Sa-Token,可能是史上功能最全的轻量级 Java 权限认证框架。
简单的使用方式,丰富的特性,强大的功能,你有什么理由拒绝?
官方网站:http://sa-token.dev33.cn/
Gitee托管仓库:https://gitee.com/dromara/sa-token
Github托管仓库:https://github.com/dromara/Sa-Token
Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证、权限认证、Session会话、单点登录、OAuth2.0、微服务网关鉴权等一系列权限相关问题。
https://blog.csdn.net/qi15211/article/details/84070709
http://www.apache.org/licenses/LICENSE-2.0.txt
https://sa-token.dev33.cn/
https://mp.weixin.qq.com/s/rLYiwKgNkv9eFMykWdrA3w
https://www.cnblogs.com/bryan31/p/15406243.html
https://sa-token.dev33.cn/v/v1.26.0/doc/index.html#/
https://www.bejson.com/explore/index_new/
cn.dev33.satoken.config.SaTokenConfig
cn.dev33.satoken.stp.SaLoginModel
org.springframework.boot.CommandLineRunner
Sureness
丢掉Shiro吧,也别再用Spring Security了,简单易用多语言多框架支持,基于RESTAPI的强大国产鉴权框架,效率神器!
官方网站:https://usthe.com/sureness
Gitee托管仓库:https://gitee.com/dromara/sureness
Github托管仓库:https://github.com/dromara/sureness
TLog
十分钟即可接入,一款神器的日志框架,支持众多的框架和主流RPC,让你的日志马上升级,变得可追溯!
官方网站:http://yomahub.com/tlog
Gitee托管仓库:https://gitee.com/dromara/TLog
Github托管仓库:https://github.com/dromara/TLog
ImageCombiner
无需P图,用Java也能合成很好看的图,简单的使用方式,服务端批量合图利器!
官方网站:http://dromara.gitee.io/image-combiner
Gitee托管仓库:https://gitee.com/dromara/image-combiner
ImageCombiner
无需P图,用Java也能合成很好看的图,简单的使用方式,服务端批量合图利器!
官方网站:http://dromara.gitee.io/image-combiner
Gitee托管仓库:https://gitee.com/dromara/image-combiner
其实Dromara开源社区还有最知名的项目(也是star最多的项目)——Hutool,那我为什么不写呢。我想说,这框架普及率太高了,几乎是可以取代apache common包,guava包的存在,程序员应该每个人都用下。一篇文章不足以写出Hutool这个框架的全面性和强大。
4、arthas(Java)
Star:27.3k|语言:Java
简单易用的命令行 Java 诊断工具。支持 JVM 进程和资源监控,还能展示 GC、JDK 版本等信息,无需增加代码就可以加入日志,帮助快速定位问题。当线上出现了奇怪的异常时,无需发版就能截获运行时的数据,包括参数、返回值、异常、耗时等信息。
https://www.cnblogs.com/12lisu/p/15370694.html
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
https://www.jianshu.com/p/cfe4c7aaed1e
https://arthas.aliyun.com/doc/arthas-tutorials.html?language=cn
https://www.cnblogs.com/qiaoyihang/p/10533672.html
thread 1 | grep 'main('
sc -d *MathGame
jad demo.MathGame
watch demo.MathGame primeFactors returnObj
当前最忙的前N个线程并打印堆栈
thread -i 5000
thread -i 5000
getstatic demo.MahtGame random
Ognl @demo.MathGame@random
vmtool --action getInstances --className java.lang.String --limit 10
wget https://github.com/hengyunabc/spring-boot-inside/raw/master/demo-arthas-spring-boot/demo-arthas-spring-boot.jar
java -jar demo-arthas-spring-boot.jar
http://localhost:8500/admin-arthas/login
http://localhost:8500/admin-arthas/arthas/index
http://localhost:8000/admin/applications
root/123456
https://www.cnblogs.com/houbbBlogs/p/15409133.html
https://github.com/houbb/heaven/blob/master/doc/gen/heaven-%E7%B4%A2%E5%BC%95.md
https://www.cnblogs.com/lmandcc/p/15354363.html
https://www.cnblogs.com/lmandcc/p/15345444.html
https://www.cnblogs.com/alterwl/p/density-based-clustering.html
https://www.cnblogs.com/bigdata1024/p/15306365.html
https://www.cnblogs.com/jacklondon/p/big_table_design_and_paing.html
https://www.cnblogs.com/huyangshu-fs/p/15062396.html
https://www.cnblogs.com/huyangshu-fs/p/14489114.html
https://www.cnblogs.com/lishanstudy/p/15176552.html
https://www.cnblogs.com/daxnet/p/15173341.html
https://www.cnblogs.com/yangsj666/p/15119841.html
https://www.cnblogs.com/chfcareboke/p/15118931.html
https://www.yuque.com/boyan-avfmj/aviatorscript/guhmrc
https://github.com/zhangpu-paul/flink/tree/release-1.10.1/flink-libraries
MobaXterm
VMware Workstation Pro 15.5.0
软件序列号:
UG5J2-0ME12-M89WY-NPWXX-WQH88
GA590-86Y05-4806Y-X4PEE-ZV8E0
YA18K-0WY8P-H85DY-L4NZG-X7RAD
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
B806Y-86Y05-GA590-X4PEE-ZV8E0
ZF582-0NW5N-H8D2P-0XZEE-Z22VA
UY758-0RXEQ-M81WP-8ZM7Z-Y3HDA
VF750-4MX5Q-488DQ-9WZE9-ZY2D6
UU54R-FVD91-488PP-7NNGC-ZFAX6
YC74H-FGF92-081VZ-R5QNG-P6RY4
YC34H-6WWDK-085MQ-JYPNX-NZRA2
关闭防火墙:
$ systemctl stop firewalld
$ systemctl disable firewalld
关闭selinux:
$ sed -i 's/enforcing/disabled/' /etc/selinux/config
$ setenforce 0
关闭swap:(方法一)
$ swapoff -a $ 临时
$ vim /etc/fstab $ 永久
关闭swap:(方式二)
swapoff -a
echo "vm.swappiness = 0">> /etc/sysctl.conf
sysctl -p
将桥接的IPv4流量传递到iptables的链:
$ cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sysctl --system
# 加载内核模块
modprobe br_netfilter
lsmod | grep br_netfilter
# base repo
cd /etc/yum.repos.d
mv CentOS-Base.repo CentOS-Base.repo.bak
curl -o CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
sed -i 's/gpgcheck=1/gpgcheck=0/g' /etc/yum.repos.d/CentOS-Base.repo
# docker repo
curl -o docker-ce.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# k8s repo
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# update cache
yum clean all
yum makecache
yum repolist
# 1、查看docker现有版本 并进行排序
yum list docker-ce --showduplicates | sort -r
# 2、根据需要安装所需版本的docker
yum install docker-ce-19.03.9 docker-ce-cli-19.03.9 containerd.io -y
# 3、启动docker 并将其设置成开机自启
systemctl start docker
systemctl enable docker
# 4、配置镜像加速
tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors":["https://reg-mirror.qiniu.com/"]}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
#Docker中国区官方镜像
https://registry.docker-cn.com
#网易
http://hub-mirror.c.163.com
#ustc
https://docker.mirrors.ustc.edu.cn
$ yum install -y kubelet kubeadm kubectl
$ systemctl enable kubelet
#安装kubelet 后会在/etc下生成文件目录/etc/kubernetes/manifests/
kubeadm reset
kubeadm config images list
https://blog.csdn.net/weixin_42806458/article/details/115056284
cd /etc/systemd/system/kubelet.service.d
sudo vim 10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
kubeadm init \
--apiserver-advertise-address=`hostname -i` \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.20.5 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16\
--ignore-preflight-errors=NumCPU
kubeadm init \
--apiserver-advertise-address=192.168.40.128 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.3 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16\
--ignore-preflight-errors=NumCPU
kubeadm init --kubernetes-version=v1.14.2 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=Swap
kubeadm init --kubernetes-version=v1.22.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=Swap
Your Kubernetes control-plane has initialized successfully!
## 如果你当前不是root用户 请执行以下命令 贴加环境变量
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
## 如果你是root 用户,请执行以下命令 贴加环境变量
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
## 如果你有其他的 node节点需要加入到集群中来 请执行以下命令 (token 有效期只有24小时)
kubeadm join 192.168.0.135:6443 --token c0bvoz.hgl73sk67hby5k8y \
--discovery-token-ca-cert-hash sha256:abfc5fce397a488c224bf6e44c5a95dc44e1e3bf06e348f9c0675bfb633df647
## 如果想生成永久生效的 token 请执行以下命令 生成:
kubectl token create --ttl 0 # 用永久的token值 替换成 有限期的token值 你的node 可以在任何时间点来加入集群
## 1、下载配置文件:下载calico的yaml文件
wget https://docs.projectcalico.org/manifests/calico.yaml
## 2、查看一下Calico版本是多少:
cat calico.yaml | grep image
查看与K8s的版本支持情况:https://docs.projectcalico.org/getting-started/kubernetes/requirements
## 3、修改calico.yaml:
vim calico.yaml
## name取消注释就可以,value改成第一节的配置文件(kubeadm-config.yaml)里面的podSubnet。
## 在vi里面搜一下“/192.168”就可以找到这个地方。
## 4、创建Calico:
kubectl apply -f calico.yaml
## 5、再次查看K8s组件,就可以看到全部起来了:(需要一些时间 拉取镜像比较慢)
kubectl get pod -n kube-system
kubectl describe po calico-kube-controllers-69496d8b75-n82rx -n kube-system
kubectl taint node master node-role.kubernetes.io/master-
kubectl create deployment nginx-deployment --image=nginx --port=80
kubectl expose deployment nginx-deployment --port=80 --target-port=80 --name=nginx-service --type=NodePort
kubectl get svc|grep nginx|cut -d":" -f2|cut -d"/" -f1
cd ~
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source .bash_profile
yum -y install bash-completion
source /etc/profile.d/bash_completion.sh
19.2 探索1
Ambari
Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是顶级项目。目前最新的发布版本是 2.0.1,未来不久将发布 2.1 版本。就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,但是这里的 Hadoop 是广义,指的是 Hadoop 整个生态圈(例如 Hive,Hbase,Sqoop,Zookeeper 等),而并不仅是特指 Hadoop。用一句话来说,Ambari 就是为了让 Hadoop 以及相关的大数据软件更容易使用的一个工具。
Ambari 自身也是一个分布式架构的软件,主要由两部分组成:Ambari Server 和 Ambari Agent。简单来说,用户通过 Ambari Server 通知 Ambari Agent 安装对应的软件;Agent 会定时地发送各个机器每个软件模块的状态给 Ambari Server,最终这些状态信息会呈现在 Ambari 的 GUI,方便用户了解到集群的各种状态,并进行相应的维护。
https://blog.csdn.net/lijingjingchn/article/details/85256737
最核心的是 Task Slot,每个slot能运行一个或多个task。为了拓扑更高效地运行,Flink提出了Chaining,尽可能地将operators chain在一起作为一个task来处理。为了资源更充分的利用,Flink又提出了SlotSharingGroup,尽可能地让多个task共享一个slot。
Google DataFlow
https://blog.csdn.net/lijingjingchn/article/details/86616891
我们按照上图从左到右的顺序介绍这几个概念,依次是event time,ingestion time,processing time.
1.1 Event Time
事件时间: 事件时间是每条事件在它产生的时候记录的时间,该时间记录在事件中,在处理的时候可以被提取出来。小时的时间窗处理将会包含事件时间在该小时内的所有事件,而忽略事件到达的时间和到达的顺序事件时间对于乱序、延时、或者数据重放等情况,都能给出正确的结果。事件时间依赖于事件本身,而跟物理时钟没有关系。利用事件时间编程必须指定如何生成事件时间的watermark,这是使用事件时间处理事件的机制。机制是这样描述的:事件时间处理通常存在一定的延时,因此自然的需要为延时和无序的事件等待一段时间。因此,使用事件时间编程通常需要与处理时间相结合。
1.2 Ingestion Time
摄入时间: 摄入时间是事件进入flink的时间,在source operator中,每个事件拿到当前时间作为时间戳,后续的时间窗口基于该时间。摄入时间在概念上处于事件时间和处理时间之间,与处理时间相比稍微昂贵一点,但是能过够给出更多可预测的结果。因为摄入时间使用的是source operator产生的不变的时间,后续不同的operator都将基于这个不变的时间进行处理,但是处理时间使用的是处理消息当时的机器系统时钟的时间。与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的watermark。
1.3 Process Time
处理时间: 当前机器处理该条事件的时间流处理程序使用该时间进行处理的时候,所有的操作(类似于时间窗口)都会使用当前机器的时间,例如按照小时时间窗进行处理,程序将处理该机器一个小时内接收到的数据。处理时间是最简单的概念,不需要协调机器时间和流中事件相关的时间。他提供了最小的延时和最佳的性能。但是在分布式和异步环境中,处理时间不能提供确定性,因为它对事件到达系统的速度和数据流在系统的各个operator之间处理的速度很敏感
senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val text = senv.socketTextStream("localhost", 9999)
.assignTimestampsAndWatermarks(new TimestampExtractor)
要启用EventTime处理,我们需要一个时间戳提取器,从消息中提取事件时间信息。请记住,消息是格式值,时间戳。该extractTimestamp方法获取时间戳部分并将其作为一个长期。现在忽略getCurrentWatermark方法,我们稍后再回来。
class TimestampExtractor extends AssignerWithPeriodicWatermarks[String] with Serializable {
override def extractTimestamp(e: String, prevElementTimestamp: Long) = {
e.split(",")(1).toLong
}
override def getCurrentWatermark(): Watermark = {
new Watermark(System.currentTimeMillis)
}
}
Error:(37, 49) java: 无法访问org.apache.flink.configuration.Configuration
找不到org.apache.flink.configuration.Configuration的类文件
provided 生产
compile 开发
Reason: No factory implements 'org.apache.flink.table.delegation.ExecutorFactory'.
compile
This is the default scope, used if none is specified. Compile dependencies are available in all classpaths of a project. Furthermore, those dependencies are propagated to dependent projects.(Compile means that you need the JAR for compiling and running the app. For a web application, as an example, the JAR will be placed in the WEB-INF/lib directory.)
provided
This is much like compile, but indicates you expect the JDK or a container to provide the dependency at runtime. For example, when building a web application for the Java Enterprise Edition, you would set the dependency on the Servlet API and related Java EE APIs to scope provided because the web container provides those classes. This scope is only available on the compilation and test classpath, and is not transitive.(Provided means that you need the JAR for compiling, but at run time there is already a JAR provided by the environment so you don't need it packaged with your app. For a web app, this means that the JAR file will not be placed into the WEB-INF/lib directory.)
For a web app, if the app server already provides the JAR (or its functionality), then use "provided" otherwise use "compile".
compile:默认的scope。任何定义在compile scope下的依赖将会在所有的class paths下可用。maven工程会将其打包到最终的artifact中。如果你构建一个WAR类型的artifact,那么在compile scope下引用的JAR文件将会被集成到WAR文件内。
provided:这个scope假定对应的依赖会由运行这个应用的JDK或者容器来提供。最好的例子就是servlet API。任何在provided scope下定义的依赖在构建时的类路径里是可用的,但是不会被打包到最终的artifact中。如果是一个WAR的文件,servlet API在构建时的类路径里是可用的,但是并不会被打包到WAR文件中。
runtime:在runtime scope下定义的依赖只会在运行期可用,而在构建期的类路径下不可用。这些依赖将会被打包到最终的artifact中。比如你有一个基于web的应用需要在运行时访问MySQL数据库。你的代码没有任何MySQL数据库驱动的硬依赖。你的代码仅仅是基于JDBC API来编写,在构建期并不需要MySQL数据库驱动。然而,在运行期,就需要相应的驱动来操作MySQL数据库了。因此,这个驱动应该被打包到最终的artifact中。
test:只用于测试变异的依赖(比如JUnit),execution必须定义在test scope下。这些依赖不会被打包到最终的artifact中。
system:于provided scope很像。唯一的区别在于,在system scope中,你需要告诉Maven如何去找到这个依赖。如果你要引用的依赖在Maven仓库中不存在时,就可以用这个scope。不推荐使用system依赖。
import:从其它的pom文件中导入依赖设置
作者:随风而去霸
链接:https://www.jianshu.com/p/46de3f6f5703
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
水印本质上是一个时间戳。当Flink中的运算符接收到水印时,它明白(假设)它不会看到比该时间戳更早的消息。因此,在“EventTime”中,水印也可以被认为是一种告诉Flink它有多远的一种方式。
为了这个例子的目的,把它看作是一种告诉Flink一个消息延迟多少的方式。在最后一次尝试中,我们将水印设置为当前系统时间。因此,不要指望任何延迟的消息。我们现在将水印设置为当前时间-5秒,这告诉Flink希望消息最多有5s的延迟,这是因为每个窗口仅在水印通过时被评估。由于我们的水印是当前时间-5秒,所以第一个窗口[5s-15s]将仅在第20秒被评估。类似地,窗口[10s-20s]将在第25秒进行评估,依此类推。
override def getCurrentWatermark(): Watermark = {
new Watermark(System.currentTimeMillis - 5000)
}
allowedLateness也是Flink处理乱序事件的一个特别重要的特性,默认情况下,当wartermark通过window后,再进来的数据,也就是迟到或者晚到的数据就会别丢弃掉了,但是有的时候我们希望在一个可以接受的范围内,迟到的数据,也可以被处理或者计算,这就是allowedLateness产生的原因了,简而言之呢,allowedLateness就是对于watermark超过end-of-window之后,还允许有一段时间(也是以event time来衡量)来等待之前的数据到达,以便再次处理这些数据。
默认情况下,如果不指定allowedLateness,其值是0,即对于watermark超过end-of-window之后,还有此window的数据到达时,这些数据被删除掉了。
注意:对于trigger是默认的EventTimeTrigger的情况下,allowedLateness会再次触发窗口的计算,而之前触发的数据,会buffer起来,直到watermark超过end-of-window + allowedLateness()的时间,窗口的数据及元数据信息才会被删除。再次计算就是DataFlow模型中的Accumulating的情况。
同时,对于sessionWindow的情况,当late element在allowedLateness范围之内到达时,可能会引起窗口的merge,这样,之前窗口的数据会在新窗口中累加计算,这就是DataFlow模型中的AccumulatingAndRetracting的情况。
Apache Beam 最初叫 Apache Dataflow,由谷歌和其合作伙伴向Apache捐赠了大量的核心代码,并创立孵化了该项目。该项目的大部分大码来自于 Cloud Dataflow SDK,其特点有以下几点:
统一数据批处理(Batch)和流处理(Stream)编程的范式
能运行在任何可执行的引擎之上
在大数据的浪潮之下,技术的更新迭代十分频繁。受技术开源的影响,大数据开发者提供了十分丰富的工具。但也因为如此,增加了开发者选择合适工具的难度。在大数据处理一些问题的时候,往往使用的技术是多样化的。这完全取决于业务需求,比如进行批处理的MapReduce,实时流处理的Flink,以及SQL交互的Spark SQL等等。而把这些开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。这也是大数据开发者比较头疼的问题。而今天要分享的就是整合这些资源的一个解决方案,它就是 Apache Beam。
$ mvn archetype:generate \
-DarchetypeRepository=https://repository.apache.org/content/groups/snapshots \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=LATEST \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
$ cd word-count-beam/
$ ls
pom.xml src
$ ls src/main/java/org/apache/beam/examples/
DebuggingWordCount.java WindowedWordCount.java common
MinimalWordCount.java WordCount.java
一个 Beam 程序可以运行在多个 Beam 的可执行引擎上,包括 ApexRunner,FlinkRunner,SparkRunner 或者 DataflowRunner。 另外还有 DirectRunner。不需要特殊的配置就可以在本地执行,方便测试使用。
下面,你可以按需选择你想执行程序的引擎:
对引擎进行相关配置
使用不同的命令:通过 --runner=参数指明引擎类型,默认是 DirectRunner;添加引擎相关的参数;指定输出文件和输出目录,当然这里需要保证文件目录是执行引擎可以访问到的,比如本地文件目录是不能被外部集群访问的。
运行示例程序
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=pom.xml --output=counts --runner=ApexRunner" -Papex-runner
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --inputFile=pom.xml --output=counts" -Pflink-runner
$ mvn package exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --flinkMaster=<flink master> --filesToStage=target/word-count-beam-bundled-0.1.jar \
--inputFile=/path/to/quickstart/pom.xml --output=/tmp/counts" -Pflink-runner
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs://<your-gcs-bucket>/tmp \
--inputFile=gs://apache-beam-samples/shakespeare/* --output=gs://<your-gcs-bucket>/counts" \
-Pdataflow-runner
Apache Beam 主要针对理想并行的数据处理任务,并通过把数据集拆分多个子数据集,让每个子数据集能够被单独处理,从而实现整体数据集的并行化处理。当然,也可以用 Beam 来处理抽取,转换和加载任务和数据集成任务(一个ETL过程)。进一步将数据从不同的存储介质中或者数据源中读取,转换数据格式,最后加载到新的系统中。
数据栅栏(barrier)
在 HBase-0.96 版本以前,HBase 有两个特殊的表,分别是-ROOT-表和.META.表,其中-ROOT-的位置存储在 ZooKeeper 中,-ROOT-本身存储了.META. 表的 RegionInfo 信息,并且-ROOT-不会分裂,只有一个 Region。而.META.表可以被切分成多个Region。
————————————————
版权声明:本文为CSDN博主「李京京」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lijingjingchn/article/details/87254250
第 1 步:Client 请求 ZooKeeper 获得-ROOT-所在的 RegionServer 地址;
第 2 步:Client 请求-ROOT-所在的 RS 地址,获取.META.表的地址,Client 会将-ROOT-的相关 信息 cache 下来,以便下一次快速访问;
第 3 步:Client 请求.META.表的 RegionServer 地址,获取访问数据所在 RegionServer 的地址, Client 会将.META.的相关信息 cache 下来,以便下一次快速访问;
第 4 步:Client 请求访问数据所在 RegionServer 的地址,获取对应的数据。
从上面的路径我们可以看出,用户需要 3 次请求才能直到用户 Table 真正的位置,这在一定 程序带来了性能的下降。在0.96之前使用 3 层设计的主要原因是考虑到元数据可能需要很 大。但是真正集群运行,元数据的大小其实很容易计算出来。在 BigTable 的论文中,每行 METADATA 数据存储大小为 1KB 左右,如果按照一个 Region 为 128M 的计算,3 层设计可以支持的 Region 个数为 2^34 个,采用 2 层设计可以支持 2^17(131072)。那么 2 层设计的情 况下一个集群可以存储 4P 的数据。这仅仅是一个 Region 只有 128M 的情况下。如果是 10G 呢? 因此,通过计算,其实 2 层设计就可以满足集群的需求。因此在 0.96 版本以后就去掉 了-ROOT-表了。
通过Hbase的寻址机制,可以知道Hbase找到RegionServer是向zookeeper请求-ROOT-表(0.96之前版本Hbase),然后找到-META-表,然后在-META-表里找到RegionServer信息。如果RegionServer挂了,它把这个元数据,转移到其它活着的RegionServer上,然后把WAL日志分到其它RegionServer上去重新加载。记住这里是元数据,数据本身是在hdfs上的,所以数据本身不会挂。元数据可以理解成对文件的索引,是放在内存中的。
作者:用心阁
链接:https://www.zhihu.com/question/20130759/answer/35406376
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
集群的组成HBase的运行时有三个集群:
Zookeeper集群,负责HBase(当然还有HDFS)集群的协调服务和配置服务。其中的节点是ZooKeeper服务器
HDFS集群,是一个分布式文件系统,有单一的名字空间。其中的节点有NameNode和DataNode,前者负责存储文件系统的元数据(包括目录名,文件名,等),后则负责存储实际文件的块。
HBase集群,其中的节点有Master和Region ServerHDFS存储在HBase中,关于数据的元数据也是存储在HBase的表中的,而元数据和数据都通过HDFS文件系统存储。
在HDFS中,HBase的文件如下所示:
/hbase,hbase的根目录
/hbase/weblogs,一个名为weblogs的表的目录
/hbase/weblogs/.tableinfo.0000000001,表的元数据信息
/hbase/weblogs/e048f132e3c5ac596e4fbcc486c0ef6e,表的一个Region目录
/hbase/weblogs/e048f132e3c5ac596e4fbcc486c0ef6e/.regioninfo,Region的元数据信息
/hbase/weblogs/e048f132e3c5ac596e4fbcc486c0ef6e/pageviews,Region的一个Column Family目录
/hbase/weblogs/e048f132e3c5ac596e4fbcc486c0ef6e/pageviews/837a8a7bbf044ed3849b77881a3089a7,Region的HFile
Zookeeper存储
不但在HDFS中存储信息,HBase还在Zookeeper中存储信息,其中的znode如下所示:
/hbase/root-region-server ,Root region的位置
/hbase/table/-ROOT-,根元数据信息
/hbase/table/.META.,元数据信息
/hbase/master,当选的Mater
/hbase/backup-masters,备选的Master
/hbase/rs ,Region Server的信息
/hbase/unassigned,未分配的Region也就是说,由Zookeeper保持了集群的状态信息
Region Server存储了三部分信息:
HFile,数据文件,存储在HDFS上
Write-Ahead Log,重做日志,类似于Oracle的Redo Log和MySQL的Binlog,也存在HDFS上。
Memstore,内存中的数据缓存,类似Oracle的Buffer Cache。
1 代表job页面,在里面可以看到当前应用分析出来的所有任务,以及所有的excutors中action的执行时间。
2 代表stage页面,在里面可以看到应用的所有stage,stage是按照宽依赖来区分的,因此粒度上要比job更细一些
3 代表storage页面,我们所做的cache persist等操作,都会在这里看到,可以看出来应用目前使用了多少缓存
4 代表environment页面,里面展示了当前spark所依赖的环境,比如jdk,lib等等
5 代表executors页面,这里可以看到执行者申请使用的内存以及shuffle中input和output等数据
6 这是应用的名字,代码中如果使用setAppName,就会显示在这里
7 是job的主页面。
第一部分event timeline展开后,可以看到executor创建的时间点,以及某个action触发的算子任务,执行的时间。通过这个时间图,可以快速的发现应用的执行瓶颈,触发了多少个action。
第二部分的图表,显示了触发action的job名字,它通常是某个count,collect等操作。有spark基础的人都应该知道,在spark中rdd的计算分为两类,一类是transform转换操作,一类是action操作,只有action操作才会触发真正的rdd计算。具体的有哪些action可以触发计算,可以参考api。collect at test2.java:27描述了action的名字和所在的行号,这里的行号是精准匹配到代码的,所以通过它可以直接定位到任务所属的代码,这在调试分析的时候是非常有帮助的。Duration显示了该action的耗时,通过它也可以对代码进行专门的优化。最后的进度条,显示了该任务失败和成功的次数,如果有失败的就需要引起注意,因为这种情况在生产环境可能会更普遍更严重。点击能进入该action具体的分析页面,可以看到DAG图等详细信息。
stage页面
在Spark中job是根据action操作来区分的,另外任务还有一个级别是stage,它是根据宽窄依赖来区分的。
这个页面比较常用了,一方面通过它可以看出来每个excutor是否发生了数据倾斜,另一方面可以具体分析目前的应用是否产生了大量的shuffle,是否可以通过数据的本地性或者减小数据的传输来减少shuffle的数据量。
调优的经验总结
1 输出信息
在Spark应用里面可以直接使用System.out.println把信息输出出来,系统会直接拦截out输出到spark的日志。像我们使用的yarn作为资源管理系统,在yarn的日志中就可以直接看到这些输出信息了。这在数据量很大的时候,做一些show()(默认显示20),count() 或者 take(10)的时候会很方便。
2 内存不够
当任务失败,收到sparkContext shutdown的信息时,基本都是执行者的内存不够。这个时候,一方面可以调大--excutor-memory参数,另一方面还是得回去看看程序。如果受限于系统的硬件条件,无法加大内存,可以采用局部调试法,检查是在哪里出现的内存问题。比如,你的程序分成几个步骤,一步一步的打包运行,最后检查出现问题的点就可以了。
3 ThreadPool
线程池不够,这个是因为--excutor-core给的太少了,出现线程池不够用的情况。这个时候就需要调整参数的配置了。
4 physical memory不够
这种问题一般是driver memory不够导致的,driver memory通常存储了以一些调度方面的信息,这种情况很有可能是你的调度过于复杂,或者是内部死循环导致。
5 合理利用缓存
在Spark的计算中,不太建议直接使用cache,万一cache的量很大,可能导致内存溢出。可以采用persist的方式,指定缓存的级别为MEMORY_AND_DISK,这样在内存不够的时候,可以把数据缓存到磁盘上。另外,要合理的设计代码,恰当地使用广播和缓存,广播的数据量太大会对传输带来压力,缓存过多未及时释放,也会导致内存占用。一般来说,你的代码在需要重复使用某一个rdd的时候,才需要考虑进行缓存,并且在不使用的时候,要及时unpersist释放。
6 尽量避免shuffle
这个点,在优化的过程中是很重要的。比如你需要把两个rdd按照某个key进行groupby,然后在进行leftouterjoin,这个时候一定要考虑大小表的问题。如果把大表关联到小表,那么性能很可能会很惨。而只需要简单的调换一下位置,性能就可能提升好几倍。
知识,哪怕是知识的幻影,也会成为你的铠甲,保护你不被愚昧反噬。
https://blog.csdn.net/lijingjingchn/article/details/83012987
平均值(110) = 总Region个数(330) / RegionServers总数(3)
# hbase.regions.slop 权重值,默认为0.2
最小值 = Math.floor(平均值 * (1-0.2))
最大值 = Math.ceil(平均值 * (1+0.2))
HBase集群如果判断各个RegionServer中的最小Region个数大于计算后的最小值,并且最大Region个数小于最大值,这是直接返回不会触发负载均衡操作。根据实例中给出的Region数,计算得出最小值Region为88,最大值Region为132。
由于实例中RegionServer2的Region个数为56,小于最小值Region数88,而RegionServer1的Region个数为175,大于了最大值Region数132,所以需要负载均衡操作。
# 使用hbase shell命令进入到HBase控制台,然后开启自动执行负载均衡
hbase(main):001:0> balance_switch true
这样HBase负载均衡自动操作就开启了,但是,如果我们需要立即均衡集群中的Region个数怎么办?这里HBase也提供了管理命令,通过balancer命令来实现,操作如下:
hbase(main):001:0> balancer
但是,这样每次手动执行,每次均衡的个数不一定能满足要求,那么我们可以通过封装该命令,用脚本来调度执行,具体实现代码如下
#! /bin/bash
num=$1
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : RegionServer Start Balancer..."
if [ ! -n "$num" ]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Default Balancer 20 Times."
num=20
elif [[ $num == *[!0-9]* ]]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Input [$num] Times Must Be Number."
exit 1
else
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : User-Defined Balancer [$num] Times."
fi
for (( i=1; i<=$num; i++ ))
do
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Balancer [$i] Times,Total [$num] Times."
echo "balancer"|hbase shell
sleep 5
done
脚本默认执行20次,可以通过输入一个整型参数来自定义执行次数。
当HBase集群检查完所有的RegionServer上的Region个数已打要求,那么此时集群的负载均衡操作就已经完成了。如果没有达到要求,可以再次执行上述脚本,直到所有的Region个数在最小值和最大值之间为止。当HBase集群中所有的RegionServer完成负载均衡后,实例中的各个RegionServer上的Region个数分布,如下图所示:
此时,各个RegionServer节点上的Region个数均在最小值和最大值范围内,HBase集群各个RegionServer节点上的Region处理均衡状态。
https://blog.csdn.net/lijingjingchn/article/details/87180946
3.性能指标
在HBase系统中,有一个非常重要的性能指标,那就是集群处理请求的延时。HBase系统为了反应集群内部处理请求所耗费的时间,提供了一个工具类,即:org.apache.hadoop.hbase.tool.Canary,这个类主要用户检查HBase系统的耗时状态。如果不知道使用方法,可以通过help命令来查看具体的用法,命令如下:
hbase org.apache.hadoop.hbase.tool.Canary -help
(1)查看集群中每个表中每个Region的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary
(2)查看money表中每个Region的耗时情况,多个表之间使用空格分割
# 查看money表和person表
hbase org.apache.hadoop.hbase.tool.Canary money person
hbase org.apache.hadoop.hbase.tool.Canary 'ns_hs_flink:airTest' 'ns_hs_flink:data_item_yl'
(3)查看每个RegionServer的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary -regionserver dn1
hbase org.apache.hadoop.hbase.tool.Canary -regionserver hadoop362
hbase org.apache.hadoop.hbase.tool.Canary -regionserver hadoop363 | grep tool.Canary
hbase org.apache.hadoop.hbase.tool.Canary -regionserver hadoop364 | grep tool.Canary
通常情况下,我们比较关注每个RegionServer节点的耗时情况,将该命令封装一下,然后打印集群中每个RegionServer的耗时情况,脚本实现如下所示:
#########################################################
# 将捕获的RS耗时,写入到InfluxDB中进行存储,用于绘制历史趋势图
#########################################################
#!/bin/bash
post_influxdb_write='http://influxdb:8086/write?db=telegraf_rs'
source /home/hadoop/.bash_profile
for i in `cat rs.list`
do
timespanStr=`(hbase org.apache.hadoop.hbase.tool.Canary -regionserver $i 2>&1) | grep tool.Canary`
timespanMs=`echo $timespanStr|awk -F ' ' '{print $NF}'`
timespan=`echo $timespanMs|awk -F "ms" '{print $1}'`
echo `date +'%Y-%m-%d %H:%M:%S'` INFO : RegionServer $i delay $timespanMs .
currentTime=`date "+%Y-%m-%d %H:%M:%S"`
currentTimeStamp=`date -d "$currentTime" +%s`
insert_sql="regionsever,host=$i value=$timespan ${currentTimeStamp}000000000"
#echo $insert_sql
curl -i -X POST "$post_influxdb_write" --data-binary "$insert_sql"
done
exit
4.总结
在维护HBase集群时,比如重启某几个RegionServer节点后,可能会发送Region不均衡的情况,这时如果开启自动均衡后,需要立即使当前集群上其他RegionServer上的Region处于均衡状态,那么就可以使用手动均衡操作。另外,HBase集群中各个RegionServer的耗时情况,能够反映当前集群的健康状态。
首先,第一件事是指定你的数据流是分组的还是未分组的,这个必须在定义 window 之前指定好。使用 keyBy(…) 会将你的无限数据流拆分成逻辑分组的数据流,如果 keyBy(…) 函数不被调用的话,你的数据流将不是分组的。
在分组数据流中,任何正在传入的事件的属性都可以被当做key(更多详情请见:https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/api_concepts.html#specifying-keys ),分组数据流将你的window计算通过多任务并发执行,以为每一个逻辑分组流在执行中与其他的逻辑分组流是独立地进行的。
在非分组数据流中,你的原始数据流并不会拆分成多个逻辑流并且所有的window逻辑将在一个任务中执行,并发度为1。
————————————————
版权声明:本文为CSDN博主「李京京」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lijingjingchn/article/details/87605585
动态刷新hdfs配置:
hdfs dfsadmin -fs hdfs://nn1:8020 -refreshSuperUserGroupsConfiguration
hdfs dfsadmin -fs hdfs://nn2:8020 -refreshSuperUserGroupsConfiguration
动态刷新yarn配置:
yarn rmadmin -fs hdfs://nn1:8020 -refreshSuperUserGroupsConfiguration
yarn rmadmin -fs hdfs://nn2:8020 -refreshSuperUserGroupsConfiguration
总结:
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
通过收集统计信息不可能存在结果
执行用户的main方法后,就是flink的标准流程了。创建env、构建StreamDAG、生成Pipeline、提交到集群、阻塞运行。当main程序执行完毕,整个run脚本程序也就退出了。
总结来说,Flink提交Jar任务的流程是:
1 脚本入口程序根据参数决定做什么操作
2 创建PackagedProgram,准备相关jar和类加载器
3 通过反射调用用户Main方法
4 构建Pipeline,提交到集群
有的时候不想通过阻塞的方式卡任务执行状态,需要通过类似JobClient的客户端异步查询程序状态,并提供停止退出的能力。
要了解这个流程,首先要了解Pipeline是什么。用户编写的Flink程序,无论是DataStream API还是SQL,最终编译出的都是Pipeline。只是DataStream API编译出的是StreamGraph,而SQL编译出的Plan。Pipeline会在env.execute()中进行编译并提交到集群。
既然这样,此时可以思考一个问题:Jar包任务是独立的Main方法,如何能抽取其中的用户程序获得Pipeline呢?
通过浏览源码的单元测试,发现了一个很好用的工具类:PackagedProgramUtils。
1 classloader类加载的父类优先和子类优先问题
2 threadlocal线程级本地变量的使用
3 PackagedProgramUtils 利用枚举作为工具类
4 PackagedProgramUtils 利用重写env,拦截异常获取pipeline。
https://www.cnblogs.com/xing901022/p/14300093.html
按照窗口聚合的种类可以大致分为:
滚动窗口:比如统计每分钟的浏览量,TumblingEventTimeWindows.of(Time.minutes(1))
滑动窗口:比如每10秒钟统计一次一分钟内的浏览量,SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))
会话窗口:统计会话内的浏览量,会话的定义是同一个用户两次访问不超过30分钟,EventTimeSessionWindows.withGap(Time.minutes(30))
窗口的时间可以通过下面的几种时间单位来定义:
毫秒,Time.milliseconds(n)
秒,Time.seconds(n)
分钟,Time.minutes(n)
小时,Time.hours(n)
天,Time.days(n)
基于时间的窗口分配器支持事件时间和处理时间,这两种类型的时间处理的吞吐量会有差别。使用处理时间优点是延迟很低,但是也存在几个缺点:无法正确的处理历史数据;无法处理乱序数据;结果非幂等。当使用基于数量的窗口,如果数量不够,可能永远不会触发窗口操作。没有选项支持超时处理或部分窗口的处理,当然你可以通过自定义窗口的方式来实现。全局窗口分配器会在一个窗口内,统一分配每个事件。如果需要自定义窗口,一般会基于它来做。不过推荐直接使用ProcessFunction。
以Yarn部署为例,想要启动application模式,可以使用下面的命令:
# 基于application模式启动本地jar
./bin/flink run-application -t yarn-application \
./examples/batch/WordCount.jar
# 附加集群参数配置
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./examples/batch/WordCount.jar
# 基于application模式启动远程jar
./bin/flink run-application -t yarn-application \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
hdfs://myhdfs/jars/my-application.jar
在Session模式中,集群的生命周期与任务无关,可以在集群中同时提交多个任务,他们共享集群资源。Per job模式中,每个任务单独维护集群,可以做到更好的资源隔离,集群的生命周期与任务相同。在Application模式中,为每个应用创建一个集群,main方法会运行在集群中,避免客户端过大的压力。
另外可以通过UI查看指标。这样可以让开发者很容易的创建一些可视化的工具。这些命令同时也只支持正在运行的应用。对于history server,访问的地址是http://<server-url>:18080/api/v1,对于正在运行的任务,可以访问http://localhost:4040/api/v1
在这些api中,应用的标识为ID[app-id]。当通过YARN启动时,每个应用可能会有多次尝试,只有在cluster模式下才有 应用尝试的id,client模式是没有的。如果是集群模式,那么app-id其实是[base-app-id]/[attempt-id],其中base-app-id是yarn的appid。
?status=[active|complete|pending|failed] 可以列出对应的状态
http://localhost:18080/api/v1
问题1:reduce task数目不合适
解决方案:
需要根据实际情况调整默认配置,调整方式是修改参数Spark.default.parallelism。通常的,reduce数目设置为core数目的2-3倍。数量太大,造成很多小任务,增加启动任务的开销;数目太小,任务运行缓慢。所以要合理修改reduce的task数目即spark.default.parallelism
问题2:shuffle磁盘IO时间长
解决方案:
设置spark.local.dir为多个磁盘,并设置磁盘的IO速度快的磁盘,通过增加IO来优化shuffle性能;
问题3:map|reduce数量大,造成shuffle小文件数目多
解决方案:
通过设置spark.shuffle.consolidateFiles为true,来合并shuffle中间文件,此时文件数为reduce tasks数目;
问题4:序列化时间长、结果大
解决方案:
spark默认使用JDK 自带的ObjectOutputStream,这种方式产生的结果大、CPU处理时间长,可以通过设置spark.serializer为org.apache.spark.serializer.KeyoSerializer。
另外如果结果已经很大,那就最好使用广播变量方式了,结果你懂得。
问题5:单条记录消耗大
解决方案:
使用mapPartition替换map,mapPartition是对每个Partition进行计算,而map是对partition中的每条记录进行计算;
问题6 : collect输出大量结果时速度慢
解决方案:
collect源码中是把所有的结果以一个Array的方式放在内存中,可以直接输出到分布式的文件系统,然后查看文件系统中的内容;
问题7: 任务执行速度倾斜
解决方案:
如果数据倾斜,一般是partition key取得不好,可以考虑其他的并行处理方式,并在中间加上aggregation操作;如果是Worker倾斜,例如在某些Worker上的executor执行缓慢,可以通过设置spark.speculation=true 把那些持续慢的节点去掉;
问题8: 通过多步骤的RDD操作后有很多空任务或者小任务产生
解决方案:
使用coalesce或者repartition去减少RDD中partition数量;
问题9:Spark Streaming吞吐量不高
解决方案:
可以设置spark.streaming.concurrentJobs
问题10:Spark Streaming 运行速度突然下降了,经常会有任务延迟和阻塞
解决方案:
这是因为我们设置job启动interval时间间隔太短了,导致每次job在指定时间无法正常执行完成,换句话说就是创建的windows窗口时间间隔太密集了;
为了让以上的这些更加具体一点,这里有一个实际使用过的配置的例子,可以完全用满整个集群的资源。假设一个集群有6个节点有NodeManager在上面运行,每个节点有16个core以及64GB的内存。那么 NodeManager的容量:yarn.nodemanager.resource.memory-mb 和 yarn.nodemanager.resource.cpu-vcores 可以设为 63 * 1024 = 64512 (MB) 和 15。我们避免使用 100% 的 YARN container 资源因为还要为 OS 和 hadoop 的 Daemon 留一部分资源。在上面的场景中,我们预留了1个core和1G的内存给这些进程。Cloudera Manager 会自动计算并且配置。
所以看起来我们最先想到的配置会是这样的:--num-executors 6 --executor-cores 15 --executor-memory 63G。但是这个配置可能无法达到我们的需求,因为:
- 63GB+ 的 executor memory 塞不进只有 63GB 容量的 NodeManager;
- 应用的 master 也需要占用一个core,意味着在某个节点上,没有15个core给 executor 使用;
- 15个core会影响 HDFS IO的吞吐量。
配置成 --num-executors 17 --executor-cores 5 --executor-memory 19G 可能会效果更好,因为:
- 这个配置会在每个节点上生成3个 executor,除了应用的master运行的机器,这台机器上只会运行2个 executor
- --executor-memory 被分成3份(63G/每个节点3个executor)=21。 21 * (1 - 0.07) ~ 19。
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值,即写操作之后的读操作,必须返回该值。(分为弱一致性、强一致性和最终一致性)
可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
————————————————
版权声明:本文为CSDN博主「Jeremy_Lee123」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lixinkuan328/article/details/95535691
2.1、CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。传统的关系型数据库RDBMS:Oracle、MySQL就是CA。
2.2、CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
2.3、 AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
这里,不管是在 local[k] 模式,Standalone 模式,还是 Mesos 或是 YARN 模式,整个 Spark Cluster 的结构都可以用改图来阐述,只是各个组件的运行环境略有不同,从而导致他们可能运行在分布式环境,本地环境,亦或是一个 JVM 实利当中。例如,在 local[k] 模式,上图表示在同一节点上的单个进程上的多个组件,而对于 YARN 模式,驱动程序是在 YARN Cluster 之外的节点上提交 Spark 应用,其他组件都是运行在 YARN Cluster 管理的节点上的。
而对于 Spark Cluster 部署应用后,在进行相关计算的时候会将 RDD 数据集上的函数发送到集群中的 Worker 上的 Executor,然而,这些函数做操作的对象必须是可序列化的。上述代码利用 Scala 的语言特性,解决了这一问题。
此作业执行简单的字数统计。首先,它执行textFile操作读取 HDFS 中的输入文件,然后执行flatMap操作将每一行拆分为单词,然后执行map操作以形成 (word, 1) 对,最后执行reduceByKey操作以求和每个行的计数单词。
可视化中的蓝色阴影框表示用户在其代码中调用的 Spark 操作。这些框中的点代表在相应操作中创建的 RDD。操作本身按它们运行的阶段分组。
可以从这个可视化中获得一些观察结果。首先,它揭示了未通过 shuffle 分隔的流水线操作的 Spark 优化。特别是,每个执行器从 HDFS 读取输入分区后,直接将后续的flatMap和map函数应用于同一任务中的分区,无需触发另一个阶段。
其次,其中一个 RDD 被缓存在第一阶段(由绿色突出显示)。由于封闭操作涉及从 HDFS 读取,因此缓存此 RDD 意味着此 RDD 上的未来计算可以从内存而不是从 HDFS 访问原始文件的至少一个子集。
DAG 可视化的价值在复杂的工作中最为明显。例如,MLlib 中的交替最小二乘法 (ALS) 实现迭代地计算两个因子矩阵的近似乘积。这涉及到一系列的map、join、groupByKey操作。
值得注意的是,在 ALS 中,在正确位置缓存对性能至关重要,因为该算法在每次迭代中广泛重用先前计算的结果。通过 DAG 可视化,用户和开发人员现在可以一目了然地确定某些 RDD 是否正确缓存,如果没有,可以快速了解为什么实现缓慢。
与时间线视图一样,DAG 可视化允许用户单击进入舞台并扩展舞台内的细节。下面描述了 ALS 中单个阶段的 DAG 可视化。
https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html
在stage视图中,属于这个stage的所有RDD的详细信息都会自动展开。用户现在可以快速找到有关特定 RDD 的信息,而无需通过将鼠标悬停在作业页面上的各个点上来进行猜测和检查。
最后,我想强调 DAG 可视化和 Spark SQL 之间的初步集成。由于 Spark SQL 用户对高级物理运算符比对低级 Spark 原语更熟悉,因此应该显示前者。结果类似于映射到底层执行 DAG 的 SQL 查询计划。
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Excuter,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的excuter,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
5.3的代码一直运行,结果可以一直累加,但是代码一旦停止运行,再次运行时,结果会不会接着上一次进行计算,上一次的计算结果丢失了,主要原因上每次程序运行都会初始化一个程序入口,而2次运行的程序入口不是同一个入口,所以会导致第一次计算的结果丢失,第一次的运算结果状态保存在Driver里面,所以我们如果想用上一次的计算结果,我们需要将上一次的Driver里面的运行结果状态取出来,而5.3里面的代码有一个checkpoint方法,它会把上一次Driver里面的运算结果状态保存在checkpoint的目录里面,我们在第二次启动程序时,从checkpoint里面取出上一次的运行结果状态,把这次的Driver状态恢复成和上一次Driver一样的状态
SparkSQL 的元数据的状态有两种:
1、in_memory,用完了元数据也就丢了
2、hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿。
换句话说,SparkSQL的数据仓库在建立在Hive之上实现的。我们要用SparkSQL去构建数据仓库的时候,必须依赖于Hive。
如果用户直接运行bin/spark-sql命令。会导致我们的元数据有两种状态:
1、in-memory状态:
如果SPARK-HOME/conf目录下没有放置hive-site.xml文件,元数据的状态就是in-memory
2、hive状态:
如果我们在SPARK-HOME/conf目录下放置了,hive-site.xml文件,那么默认情况下
spark-sql的元数据的状态就是hive.
在Spark中,也支持Hive中的自定义函数。自定义函数大致可以分为三种:
UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等
UDAF(User- Defined Aggregation Funcation),用户自定义聚合函数,类似在group by之后使用的sum,avg等
UDTF(User-Defined Table-Generating Functions),用户自定义生成函数,有点像stream里面的flatMap
自定义一个UDF函数需要继承UserDefinedAggregateFunction类,并实现其中的8个方法
SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
特点:
---- 为用户提供一个统一的切入点使用Spark 各项功能
---- 允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
---- 减少了用户需要了解的一些概念,可以很容易的与 Spark 进行交互
---- 与 Spark 交互之时不需要显示的创建 SparkConf, SparkContext 以及 SQlContext,这些对象已经封闭在 SparkSession 中
df1.write.format("parquet").mode(SaveMode.Ignore).save("E:\\444")
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。
需要在工作节点间进行数据混洗的转换极大地受益于分区。这样的转换是 cogroup,groupWith,join,leftOuterJoin,rightOuterJoin,groupByKey,reduceByKey,combineByKey 和lookup。
分区是可配置的,只要RDD是基于键值对的即可。
RDD分区的一个分区原则:尽可能是得分区的个数等于集群核心数目
无论是本地模式、Standalone模式、YARN模式或Mesos模式,我们都可以通过spark.default.parallelism来配置其默认分区个数,若没有设置该值,则根据不同的集群环境确定该值
n等于几默认就是几个分区
如果n=* 那么分区个数就等于cpu core的个数
本机电脑查看cpu core,我的电脑--》右键管理--》设备管理器--》处理器
totalCoreCount.get()是所有executor使用的core总数,和2比较去较大值
如果正常的情况下,那你设置了多少就是多少
(1)如果是从HDFS里面读取出来的数据,不需要分区器。因为HDFS本来就分好区了。
分区数我们是可以控制的,但是没必要有分区器。
(2)非key-value RDD分区,没必要设置分区器
al testRDD = sc.textFile("C:\\Users\\Administrator\\IdeaProjects\\myspark\\src\\main\\hello.txt")
.flatMap(line => line.split(","))
.map(word => (word, 1)).partitionBy(new HashPartitioner(2))
没必要设置,但是非要设置也行。
(3)Key-value形式的时候,我们就有必要了。
HashPartitioner
val resultRDD = testRDD.reduceByKey(new HashPartitioner(2),(x:Int,y:Int) => x+ y)
//如果不设置默认也是HashPartitoiner,分区数跟spark.default.parallelism一样
println(resultRDD.partitioner)
println("resultRDD"+resultRDD.getNumPartitions)
RangePartitioner
val resultRDD = testRDD.reduceByKey((x:Int,y:Int) => x+ y)
val newresultRDD=resultRDD.partitionBy(new RangePartitioner[String,Int](3,resultRDD))
println(newresultRDD.partitioner)
println("newresultRDD"+newresultRDD.getNumPartitions)
注:按照范围进行分区的,如果是字符串,那么就按字典顺序的范围划分。如果是数字,就按数据自的范围划分。
自定义分区
# -z是检查后面变量是否为空(空则真) shell可以在双引号之内引用变量,单引号不可
#这一步作用是检查SPARK_HOME变量是否为空,为空则执行then后面程序
#source命令: source filename作用在当前bash环境下读取并执行filename中的命令
#$0代表shell脚本文件本身的文件名,这里即使spark-submit
#dirname用于取得脚本文件所在目录 dirname $0取得当前脚本文件所在目录
#$(命令)表示返回该命令的结果
#故整个if语句的含义是:如果SPARK_HOME变量没有设置值,则执行当前目录下的find-spark-home脚本文件,设置SPARK_HOME值
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
#执行spark-class脚本,传递参数org.apache.spark.deploy.SparkSubmit 和"$@"
#这里$@表示之前spark-submit接收到的全部参数
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
所以spark-submit脚本的整体逻辑就是:
首先 检查SPARK_HOME是否设置;if 已经设置 执行spark-class文件 否则加载执行find-spark-home文件
#定义一个变量用于后续判断是否存在定义SPARK_HOME的python脚本文件
FIND_SPARK_HOME_PYTHON_SCRIPT="$(cd "$(dirname "$0")"; pwd)/find_spark_home.py"
# Short cirtuit if the user already has this set.
##如果SPARK_HOME为不为空值,成功退出程序
if [ ! -z "${SPARK_HOME}" ]; then
exit 0
# -f用于判断这个文件是否存在并且是否为常规文件,是的话为真,这里不存在为假,执行下面语句,给SPARK_HOME变量赋值
elif [ ! -f "$FIND_SPARK_HOME_PYTHON_SCRIPT" ]; then
# If we are not in the same directory as find_spark_home.py we are not pip installed so we don't
# need to search the different Python directories for a Spark installation.
# Note only that, if the user has pip installed PySpark but is directly calling pyspark-shell or
# spark-submit in another directory we want to use that version of PySpark rather than the
# pip installed version of PySpark.
export SPARK_HOME="$(cd "$(dirname "$0")"/..; pwd)"
else
# We are pip installed, use the Python script to resolve a reasonable SPARK_HOME
# Default to standard python interpreter unless told otherwise
if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then
PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"python"}"
fi
export SPARK_HOME=$($PYSPARK_DRIVER_PYTHON "$FIND_SPARK_HOME_PYTHON_SCRIPT")
fi
可以看到,如果事先用户没有设定SPARK_HOME的值,这里程序也会自动设置并且将其注册为环境变量,供后面程序使用
当SPARK_HOME的值设定完成之后,就会执行Spark-class文件,这也是我们分析的重要部分,源码如下:
2.3 spark-class
#!/usr/bin/env bash
#依旧是检查设置SPARK_HOME的值
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
#执行load-spark-env.sh脚本文件,主要目的在于加载设定一些变量值
#设定spark-env.sh中的变量值到环境变量中,供后续使用
#设定scala版本变量值
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
#检查设定java环境值
#-n代表检测变量长度是否为0,不为0时候为真
#如果已经安装Java没有设置JAVA_HOME,command -v java返回的值为${JAVA_HOME}/bin/java
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
#-d检测文件是否为目录,若为目录则为真
#设置一些关联Class文件
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
#执行类文件org.apache.spark.launcher.Main,返回解析后的参数
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
#将build_command方法解析后的参数赋给CMD
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
#执行CMD中的某个参数类org.apache.spark.deploy.SparkSubmit
exec "${CMD[@]}"
spark-class文件的执行逻辑稍显复杂,总体上应该是这样的:
检查SPARK_HOME的值----》执行load-spark-env.sh文件,设定一些需要用到的环境变量,如scala环境值,这其中也加载了spark-env.sh文件-------》检查设定java的执行路径变量值-------》寻找spark jars,设定一些引用相关类的位置变量------》执行类文件org.apache.spark.launcher.Main,返回解析后的参数给CMD-------》判断解析参数是否正确(代表了用户设置的参数是否正确)--------》正确的话执行org.apache.spark.deploy.SparkSubmit这个类
2.4 SparkSubmit
2.1最后提交语句,D:\src\spark-2.3.0\core\src\main\scala\org\apache\spark\deploy\SparkSubmit.scala
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
override def main(args: Array[String]): Unit = {
// Initialize logging if it hasn't been done yet. Keep track of whether logging needs to
// be reset before the application starts.
val uninitLog = initializeLogIfNecessary(true, silent = true)
//拿到submit脚本传入的参数
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
//根据传入的参数匹配对应的执行方法
appArgs.action match {
//根据传入的参数提交命令
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
//只有standalone和mesos集群模式才触发
case SparkSubmitAction.KILL => kill(appArgs)
//只有standalone和mesos集群模式才触发
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
2.4.1 submit十分关键,主要分为两步骤
(1)调用prepareSubmitEnvironment
(2)调用doRunMain
org.apache.spark.deploy.SparkSubmit
堆内内存的大小,由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同(下面第 2 小节会进行介绍)。
Spark 对堆内内存的管理是一种逻辑上的"规划式"的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存:
Spark 在代码中 new 一个对象实例
JVM 从堆内内存分配空间,创建对象并返回对象引用
Spark 保存该对象的引用,记录该对象占用的内存
释放内存:
Spark 记录该对象释放的内存,删除该对象的引用
等待 JVM 的垃圾回收机制释放该对象占用的堆内内存
我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期[2]。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现[3]),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
2.3 内存管理接口
Spark 为存储内存和执行内存的管理提供了统一的接口——MemoryManager,同一个 Executor 内的任务都调用这个接口的方法来申请或释放内存:
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
Spark的运行主要分为2部分:
一部分是驱动程序,其核心是SparkContext;
另一部分是Worker节点上Task,它是运行实际任务的。程序运行的时候,Driver和Executor进程相互交互:运行什么任务,即Driver会分配Task到Executor,Driver 跟 Executor 进行网络传输; 任务数据从哪儿获取,即Task要从 Driver 抓取其他上游的 Task 的数据结果,所以有这个过程中就不断的产生网络结果。其中,下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。
原则十:Data Locality本地化级别
PROCESS_LOCAL:进程本地化,代码和数据在同一个进程中,也就是在同一个executor中;计算数据的task由executor执行,数据在executor的BlockManager中;性能最好
NODE_LOCAL:节点本地化,代码和数据在同一个节点中;比如说,数据作为一个HDFS block块,就在节点上,而task在节点上某个executor中运行;或者是,数据和task在一个节点上的不同executor中;数据需要在进程间进行传输
NO_PREF:对于task来说,数据从哪里获取都一样,没有好坏之分
RACK_LOCAL:机架本地化,数据和task在一个机架的两个节点上;数据需要通过网络在节点之间进行传输
ANY:数据和task可能在集群中的任何地方,而且不在一个机架中,性能最差
spark.locality.wait,默认是3s
Spark在Driver上,对Application的每一个stage的task,进行分配之前,都会计算出每个task要计算的是哪个分片数据,RDD的某个partition;Spark的task分配算法,优先,会希望每个task正好分配到它要计算的数据所在的节点,这样的话,就不用在网络间传输数据;
但是可能task没有机会分配到它的数据所在的节点,因为可能那个节点的计算资源和计算能力都满了;所以呢,这种时候,通常来说,Spark会等待一段时间,默认情况下是3s钟(不是绝对的,还有很多种情况,对不同的本地化级别,都会去等待),到最后,实在是等待不了了,就会选择一个比较差的本地化级别,比如说,将task分配到靠它要计算的数据所在节点,比较近的一个节点,然后进行计算。
但是对于第二种情况,通常来说,肯定是要发生数据传输,task会通过其所在节点的BlockManager来获取数据,BlockManager发现自己本地没有数据,会通过一个getRemote()方法,通过TransferService(网络数据传输组件)从数据所在节点的BlockManager中,获取数据,通过网络传输回task所在节点。
对于我们来说,当然不希望是类似于第二种情况的了。最好的,当然是task和数据在一个节点上,直接从本地executor的BlockManager中获取数据,纯内存,或者带一点磁盘IO;如果要通过网络传输数据的话,那么实在是,性能肯定会下降的,大量网络传输,以及磁盘IO,都是性能的杀手。
什么时候要调节这个参数?
观察日志,spark作业的运行日志,推荐大家在测试的时候,先用client模式,在本地就直接可以看到比较全的日志。
日志里面会显示,starting task。。。,PROCESS LOCAL、NODE LOCAL,观察大部分task的数据本地化级别。
如果大多都是PROCESS_LOCAL,那就不用调节了
如果是发现,好多的级别都是NODE_LOCAL、ANY,那么最好就去调节一下数据本地化的等待时长
调节完,应该是要反复调节,每次调节完以后,再来运行,观察日志
看看大部分的task的本地化级别有没有提升;看看,整个spark作业的运行时间有没有缩短
但是注意别本末倒置,本地化级别倒是提升了,但是因为大量的等待时长,spark作业的运行时间反而增加了,那就还是不要调节了。
spark.locality.wait,默认是3s;可以改成6s,10s
默认情况下,下面3个的等待时长,都是跟上面那个是一样的,都是3s
spark.locality.wait.process//建议60s
spark.locality.wait.node//建议30s
spark.locality.wait.rack//建议20s
(1)Application:表示你的应用程序
(2)Driver:表示main()函数,创建SparkContext。由SparkContext负责与ClusterManager通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭SparkContext
(3)Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数。
(4)Worker:集群中可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的worker节点,在Spark on Yarn模式中指的就是NodeManager节点。
(5)Task:在Executor进程中执行任务的工作单元,多个Task组成一个Stage
(6)Job:包含多个Task组成的并行计算,是由Action行为触发的
(7)Stage:每个Job会被拆分很多组Task,作为一个TaskSet,其名称为Stage
(8)DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系
(9)TaskScheduler:将TaskSet提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
(1)构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
(3)SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task
(4)Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
(5)Task在Executor上运行,运行完毕释放所有资源。
(1)每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
(2)Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
(3)提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
(4)Task采用了数据本地性和推测执行的优化机制。
Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
面向stage的切分,切分依据为宽依赖
维护waiting jobs和active jobs,维护waiting stages、active stages和failed stages,以及与jobs的映射关系
主要职能:
1、接收提交Job的主入口,submitJob(rdd, ...)或runJob(rdd, ...)。在SparkContext里会调用这两个方法。
生成一个Stage并提交,接着判断Stage是否有父Stage未完成,若有,提交并等待父Stage,以此类推。结果是:DAGScheduler里增加了一些waiting stage和一个running stage。
running stage提交后,分析stage里Task的类型,生成一个Task描述,即TaskSet。
调用TaskScheduler.submitTask(taskSet, ...)方法,把Task描述提交给TaskScheduler。TaskScheduler依据资源量和触发分配条件,会为这个TaskSet分配资源并触发执行。
DAGScheduler提交job后,异步返回JobWaiter对象,能够返回job运行状态,能够cancel job,执行成功后会处理并返回结果
2、处理TaskCompletionEvent
如果task执行成功,对应的stage里减去这个task,做一些计数工作:
如果task是ResultTask,计数器Accumulator加一,在job里为该task置true,job finish总数加一。加完后如果finish数目与partition数目相等,说明这个stage完成了,标记stage完成,从running stages里减去这个stage,做一些stage移除的清理工作
如果task是ShuffleMapTask,计数器Accumulator加一,在stage里加上一个output location,里面是一个MapStatus类。MapStatus是ShuffleMapTask执行完成的返回,包含location信息和block size(可以选择压缩或未压缩)。同时检查该stage完成,向MapOutputTracker注册本stage里的shuffleId和location信息。然后检查stage的output location里是否存在空,若存在空,说明一些task失败了,整个stage重新提交;否则,继续从waiting stages里提交下一个需要做的stage
如果task是重提交,对应的stage里增加这个task
如果task是fetch失败,马上标记对应的stage完成,从running stages里减去。如果不允许retry,abort整个stage;否则,重新提交整个stage。另外,把这个fetch相关的location和map任务信息,从stage里剔除,从MapOutputTracker注销掉。最后,如果这次fetch的blockManagerId对象不为空,做一次ExecutorLost处理,下次shuffle会换在另一个executor上去执行。
其他task状态会由TaskScheduler处理,如Exception, TaskResultLost, commitDenied等。
3、其他与job相关的操作还包括:cancel job, cancel stage, resubmit failed stage等
其他职能:
cacheLocations 和 preferLocation
5、TaskScheduler
维护task和executor对应关系,executor和物理资源对应关系,在排队的task和正在跑的task。
内部维护一个任务队列,根据FIFO或Fair策略,调度任务。
TaskScheduler本身是个接口,spark里只实现了一个TaskSchedulerImpl,理论上任务调度可以定制。
主要功能:
1、submitTasks(taskSet),接收DAGScheduler提交来的tasks
为tasks创建一个TaskSetManager,添加到任务队列里。TaskSetManager跟踪每个task的执行状况,维护了task的许多具体信息。
触发一次资源的索要。
首先,TaskScheduler对照手头的可用资源和Task队列,进行executor分配(考虑优先级、本地化等策略),符合条件的executor会被分配给TaskSetManager。
然后,得到的Task描述交给SchedulerBackend,调用launchTask(tasks),触发executor上task的执行。task描述被序列化后发给executor,executor提取task信息,调用task的run()方法执行计算。
2、cancelTasks(stageId),取消一个stage的tasks
调用SchedulerBackend的killTask(taskId, executorId, ...)方法。taskId和executorId在TaskScheduler里一直维护着。
3、resourceOffer(offers: Seq[Workers]),这是非常重要的一个方法,调用者是SchedulerBacnend,用途是底层资源SchedulerBackend把空余的workers资源交给TaskScheduler,让其根据调度策略为排队的任务分配合理的cpu和内存资源,然后把任务描述列表传回给SchedulerBackend
从worker offers里,搜集executor和host的对应关系、active executors、机架信息等等
worker offers资源列表进行随机洗牌,任务队列里的任务列表依据调度策略进行一次排序
遍历每个taskSet,按照进程本地化、worker本地化、机器本地化、机架本地化的优先级顺序,为每个taskSet提供可用的cpu核数,看是否满足
默认一个task需要一个cpu,设置参数为"spark.task.cpus=1"
为taskSet分配资源,校验是否满足的逻辑,最终在TaskSetManager的resourceOffer(execId, host, maxLocality)方法里
满足的话,会生成最终的任务描述,并且调用DAGScheduler的taskStarted(task, info)方法,通知DAGScheduler,这时候每次会触发DAGScheduler做一次submitMissingStage的尝试,即stage的tasks都分配到了资源的话,马上会被提交执行
4、statusUpdate(taskId, taskState, data),另一个非常重要的方法,调用者是SchedulerBacnend,用途是SchedulerBacnend会将task执行的状态汇报给TaskScheduler做一些决定
若TaskLost,找到该task对应的executor,从active executor里移除,避免这个executor被分配到其他task继续失败下去。
task finish包括四种状态:finished, killed, failed, lost。只有finished是成功执行完成了。其他三种是失败。
task成功执行完,调用TaskResultGetter.enqueueSuccessfulTask(taskSet, tid, data),否则调用TaskResultGetter.enqueueFailedTask(taskSet, tid, state, data)。TaskResultGetter内部维护了一个线程池,负责异步fetch task执行结果并反序列化。默认开四个线程做这件事,可配参数"spark.resultGetter.threads"=4。
TaskResultGetter取task result的逻辑
1、对于success task,如果taskResult里的数据是直接结果数据,直接把data反序列出来得到结果;如果不是,会调用blockManager.getRemoteBytes(blockId)从远程获取。如果远程取回的数据是空的,那么会调用TaskScheduler.handleFailedTask,告诉它这个任务是完成了的但是数据是丢失的。否则,取到数据之后会通知BlockManagerMaster移除这个block信息,调用TaskScheduler.handleSuccessfulTask,告诉它这个任务是执行成功的,并且把result data传回去。
2、对于failed task,从data里解析出fail的理由,调用TaskScheduler.handleFailedTask,告诉它这个任务失败了,理由是什么。
6、SchedulerBackend
在TaskScheduler下层,用于对接不同的资源管理系统,SchedulerBackend是个接口,需要实现的主要方法如下:
复制代码
def start(): Unit
def stop(): Unit
def reviveOffers(): Unit // 重要方法:SchedulerBackend把自己手头上的可用资源交给TaskScheduler,TaskScheduler根据调度策略分配给排队的任务吗,返回一批可执行的任务描述,SchedulerBackend负责launchTask,即最终把task塞到了executor模型上,executor里的线程池会执行task的run()
def killTask(taskId: Long, executorId: String, interruptThread: Boolean): Unit =
throw new UnsupportedOperationException
复制代码
粗粒度:进程常驻的模式,典型代表是standalone模式,mesos粗粒度模式,yarn
细粒度:mesos细粒度模式
这里讨论粗粒度模式,更好理解:CoarseGrainedSchedulerBackend。
维护executor相关信息(包括executor的地址、通信端口、host、总核数,剩余核数),手头上executor有多少被注册使用了,有多少剩余,总共还有多少核是空的等等。
主要职能
1、Driver端主要通过actor监听和处理下面这些事件:
RegisterExecutor(executorId, hostPort, cores, logUrls)。这是executor添加的来源,通常worker拉起、重启会触发executor的注册。CoarseGrainedSchedulerBackend把这些executor维护起来,更新内部的资源信息,比如总核数增加。最后调用一次makeOffer(),即把手头资源丢给TaskScheduler去分配一次,返回任务描述回来,把任务launch起来。这个makeOffer()的调用会出现在任何与资源变化相关的事件中,下面会看到。
StatusUpdate(executorId, taskId, state, data)。task的状态回调。首先,调用TaskScheduler.statusUpdate上报上去。然后,判断这个task是否执行结束了,结束了的话把executor上的freeCore加回去,调用一次makeOffer()。
ReviveOffers。这个事件就是别人直接向SchedulerBackend请求资源,直接调用makeOffer()。
KillTask(taskId, executorId, interruptThread)。这个killTask的事件,会被发送给executor的actor,executor会处理KillTask这个事件。
StopExecutors。通知每一个executor,处理StopExecutor事件。
RemoveExecutor(executorId, reason)。从维护信息中,那这堆executor涉及的资源数减掉,然后调用TaskScheduler.executorLost()方法,通知上层我这边有一批资源不能用了,你处理下吧。TaskScheduler会继续把executorLost的事件上报给DAGScheduler,原因是DAGScheduler关心shuffle任务的output location。DAGScheduler会告诉BlockManager这个executor不可用了,移走它,然后把所有的stage的shuffleOutput信息都遍历一遍,移走这个executor,并且把更新后的shuffleOutput信息注册到MapOutputTracker上,最后清理下本地的CachedLocationsMap。
2、reviveOffers()方法的实现。直接调用了makeOffers()方法,得到一批可执行的任务描述,调用launchTasks。
3、launchTasks(tasks: Seq[Seq[TaskDescription]])方法。
遍历每个task描述,序列化成二进制,然后发送给每个对应的executor这个任务信息
如果这个二进制信息太大,超过了9.2M(默认的akkaFrameSize 10M 减去 默认 为akka留空的200K),会出错,abort整个taskSet,并打印提醒增大akka frame size
如果二进制数据大小可接受,发送给executor的actor,处理LaunchTask(serializedTask)事件。
7、Executor
Executor是spark里的进程模型,可以套用到不同的资源管理系统上,与SchedulerBackend配合使用。
内部有个线程池,有个running tasks map,有个actor,接收上面提到的由SchedulerBackend发来的事件。
事件处理
launchTask。根据task描述,生成一个TaskRunner线程,丢尽running tasks map里,用线程池执行这个TaskRunner
killTask。从running tasks map里拿出线程对象,调它的kill方法。
回到顶部
三、Spark在不同集群中的运行架构
Spark注重建立良好的生态系统,它不仅支持多种外部文件存储系统,提供了多种多样的集群运行模式。部署在单台机器上时,既可以用本地(Local)模式运行,也可以使用伪分布式模式来运行;当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、YARN-Client模式或者YARN-Cluster模式。Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但它们的目的基本都是一致的,就是在合适的位置安全可靠的根据用户的配置和Job的需要运行和管理Task。
3.1 Spark on Standalone运行过程
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf().setMaster(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
运行过程文字说明
1、我们提交一个任务,任务就叫Application
2、初始化程序的入口SparkContext,
2.1 初始化DAG Scheduler
2.2 初始化Task Scheduler
3、Task Scheduler向master去进行注册并申请资源(CPU Core和Memory)
4、Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;顺便初
始化好了一个线程池
5、StandaloneExecutorBackend向Driver(SparkContext)注册,这样Driver就知道哪些Executor为他进行服务了。
到这个时候其实我们的初始化过程基本完成了,我们开始执行transformation的代码,但是代码并不会真正的运行,直到我们遇到一个action操作。生产一个job任务,进行stage的划分
6、SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作 时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。
7、将Stage(或者称为TaskSet)提交给Task Scheduler。Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
8、对task进行序列化,并根据task的分配算法,分配task
9、对接收过来的task进行反序列化,把task封装成一个线程
10、开始执行Task,并向SparkContext报告,直至Task完成。
11、资源注销
3.2 Spark on YARN运行过程
YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapReduce、Storm等计算框架。Spark基于此种情况开发了Spark on YARN的运行模式,由于借助了YARN良好的弹性资源管理机制,不仅部署Application更加方便,而且用户在YARN集群中运行的服务和Application的资源也完全隔离,更具实践应用价值的是YARN可以通过队列的方式,管理同时运行在集群中的多个服务。
Spark on YARN模式根据Driver在集群中的位置分为两种模式:一种是YARN-Client模式,另一种是YARN-Cluster(或称为YARN-Standalone模式)。
3.2.1 YARN框架流程
任何框架与YARN的结合,都必须遵循YARN的开发模式。在分析Spark on YARN的实现细节之前,有必要先分析一下YARN框架的一些基本原理。
参考:http://www.cnblogs.com/qingyunzong/p/8615096.html
3.2.2 YARN-Client
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问。
YARN-client的工作流程分为以下几个步骤:
文字说明
1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
3.2.3 YARN-Cluster
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
YARN-cluster的工作流程分为以下几个步骤:
文字说明
1. Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2. ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3. ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4. 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5. ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6. 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
3.2.4 YARN-Client 与 YARN-Cluster 区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
1、YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
2、YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
YARN 作业执行流程:
1、用户向 YARN 中提交应用程序,其中包括 MRAppMaster 程序,启动 MRAppMaster 的命令, 用户程序等。
2、ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求 它在这个 Container 中启动应用程序 MRAppMaster。
3、MRAppMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4 到 7 的步骤。
4、MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
5、一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。
6、NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将 任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7、各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以让 MRAppMaster 随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。
8、应用程序运行完成后,MRAppMaster 向 ResourceManager 注销并关闭自己。
2.3 如何定义一个广播变量?
val a = 3
val broadcast = sc.broadcast(a)
2.4 如何还原一个广播变量?
val c = broadcast.value
2.5 定义广播变量需要的注意点?
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
2.6 注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
三、累加器
3.1 为什么要将一个变量定义为一个累加器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
3.3 如何定义一个累加器?
val a = sc.accumulator(0)
3.4 如何还原一个累加器?
val b = a.value
3.5 注意事项
1、 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的
cluster by:对同一字段分桶并排序,不能和 sort by 连用
distribute by + sort by:分桶,保证同一字段值只存在一个结果文件当中,结合 sort by 保证 每个 reduceTask 结果有序
sort by:单机排序,单个 reduce 结果有序
order by:全局排序,缺陷是只能使用一个 reduce
一定要区分这四种排序的使用方式和适用场景
http://localhost:8082/testEcharts
1.echarts图的title不能与属性名重复。
2.echarts图是自适应的,它必须指定作图的高度即 id=main的Height数值,宽度可以自适应,也可以固定。
解析:
1.可以通过require加载需要使用到的模块,默认是require('echarts'),加载的是所有的图表和组件的ECharts包。
2.type:'pie' 饼状型表格
3.radius:'55%' 半径大小
4.data内含有name和value属性
5.itemStyle是一些通用样式,诸如阴影、透明度、颜色、边框颜色、边框宽度等。
其中emphasis(是鼠标hover悬停事件的高亮样式)、normal(正常展示下的样式)
6.backgroundColor: '#2c343c' 背景颜色
7.textStyle 字体样式
8.lineStyle 边线样式
9.roseType: 'angle' 将饼图显示成南丁格尔图
// 基于准备好的dom,初始化echarts实例 1. (function(){}())与(function(){})()
// 这两种写法,都是一种立即执行函数的写法,即IIFE (Immediately Invoked Function Expression)。这种函数在函数定义的地方就直接执行了。
/*
* 第二类是$(function(){});
$(function(){/*...*/});是$(document).ready(function(){/*...*/})的简写形式,是在DOM加载完成后执行的回调函数,并且只会执行一次。
* */
在一个页面中不同的js中写的$(function(){/*...*/});函数,会根据js的排列顺序依次执行。
$.each()函数不同于JQuery对象的each()方法,它是一个全局函数,不操作JQuery对象,而是以一个数组或者对象作为第1个参数,以一个回调函数作为第2个参数。回调函数拥有两个参数:第1个为对象的成员或数组的索引,第2个为对应变量或内容。
ajax() 方法用于执行 AJAX(异步 HTTP)请求。
所有的 jQuery AJAX 方法都使用 ajax() 方法。该方法通常用于其他方法不能完成的请求。
$.ajax({name:value, name:value, ... })
相关js源码下载:
1.世界地图.js,中国地图.js,中国各省份地图.js
地址:https://github.com/ecomfe/echarts/tree/master/map/js
2.echarts基础报表js源文件(echarts.min.js)
地址:https://github.com/ecomfe/echarts/tree/master/dist
3.3D地图所需的js文件(echarts-gl.min.js)
地址:https://github.com/ecomfe/echarts-gl/tree/master/dist
原博客主链接:http://www.cnblogs.com/carsonwuu/p/8267457.html
log4j.rootCategory=info,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p [%t] %l - %m%n
log4j.appender.R=mastercom.spark.util.CustomDailyRollingFileAppender
log4j.appender.R.File=log/appname.log
log4j.appender.R.DatePattern='.'yyyy-MM-dd
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p [%t] %l - %m%n
log4j.appender.R.maxBackupIndex=15
log4j.appender.R.encoding=utf-8
log4j.appender.R.ImmediateFlush=TRUE
log4j.appender.R.Append=TRUE
总结:使用方法2,只需要将log4j配置文件上传到集群即可,少维护一个脚本,推荐使用方法二。
--driver-java-options "-Dlog4j.configuration=file:/apppath/log4j.properties " \
--conf spark.executor.extraJavaOptions="-Dlog4j.configuration=file:/apppath/log4j.properties" \
一、转换算子转换算子
textfile,也会惰性加载
Transformation,懒执行,需要Action触发执行
filter
过滤 RDD[T]==>RDD[T],窄依赖
map
RDD[T] ->RDD[O], 窄依赖
flatMap
RDD[T]–>RDD[[O]],一对多 ,窄依赖,
mapToPair
sample
抽样算子 RDD[T]–>RDD[O],窄依赖
sortBy
RDD[T]–>RDD[T], 根据你指定的内容排序 宽依赖
sortByKey
根据你的K排序,要求RDD中必须是KV的,宽依赖
reduceByKey
根据RDD的K分组之后聚合(累加,字符串连接) , 宽依赖
join
把两个RDD根据K相同合并,结果RDD[K,(V1,V2)] ,宽依赖
leftOuterJoin
左连接 和下面的一致 都是宽依赖
rightOuterJoin
fullOuterJoin
union
把两个RDD直接聚合成一个RDD,数据不合并 ,窄依赖
intersection
取两个RDD的交集,窄依赖
subtract
mapPartitions
把整个分区的数据作为一个迭代器一次计算 数据量不是特别大 会有性能提升,窄依赖
distinct
去重算子 本质是map + reduceByKey+map 宽依赖
cogroup
(K,V) (K,W)=>(K,([V],[W])) RDD1相同的key value 放在[V]中 另一个RDD相同的key 的value 放在[W]中 宽依赖
mapPartitionsWithIndex
把整个分区的数据作为一个迭代器一次计算 多了一个分区的index 数据量不是特别大 会有性能提升,窄依赖
repartition
可以增多分区,可以减少分区,有shuffle 宽依赖
repartition = coalesce(num,shuffle=true)
coalesce
可以增多分区,也可以减少分区,默认没有shuffle 有shuffle就 宽依赖 没shuffle 就是窄依赖
若RDD由少的分区分到多的分区时,不让产生shuffle, 不起作用
少 - > 多 false RDD1 a、b分区 RDD2 0:a 1:b 2: 窄依赖 。 true RDD1 a、b 分区 RDD2 0:a1 b1 / 1: a2 b2 / 3: a3 b3 宽依赖
多 - > 少 false RDD1 a、b、c 分区 RDD2: 0: a 、 1: b c 窄依赖 。 true RDD1 a、b、c 分区 RDD2 0: a1、b1、c1 1:a2、b2、c2 宽依赖
zip
两个RDD压成一个RDD 窄依赖
zipWithIndex
groupByKey
(K,V)–>(K,iter),根据K相同分组,分组之后把一组的V封装成一个迭代器, 宽依赖
二、行动算子Action
saveAsTextFile等存储算子,也会立即执行
触发transformation类算子执行,一个application中有一个action算子就有一个job
Action算子
foreach
循环出值
count
结果会拿到Driver端
collect
将结果拿回Driver端 返回一个列表
first
取出第一个值
take(num)
取出num个值 返回driver端
foreachPartition
reduce
聚合数据 不过 这个是在driver端 不合适聚合大量的数据 适合聚合结果数据
countByKey
countByValue
三、持久化算子
cache
默认将数据存储在内存中
cache() = persist() = persist(StorageLevel.MEMORY_ONLY)
persist
可以手动指定持久化级别
MEMORY_ONLY
MEMORY_ONLY_SER
MEMORY_AND_DISK
MEMORY_AND_DISK_SER
“_2” 是由副本
尽量少使用DISK_ONLY级别
checkpoint
将数据直接持久化到指定的目录,当lineage 计算非常复杂,可以尝试使用checkpoint ,checkpoint还可以切断RDD的依赖关系
特殊场景使用checkpoint,对RDD使用checkpoint要慎用
checkpoint要指定目录,可以将数据持久化到指定的目录中,当application执行完成之后,这个目录中的数据不会被清除
checkpoint的执行流程
1.当sparkjob执行完成之后,Spark 会从后往前回溯,找到checkpointRDD做标记
2.回溯完成之后,Spark框架会重新启动一个job,计算标记的RDD的数据,放入指定的checkpoint目录中
3.数据计算完成,放入目录之后,会切断RDD的依赖关系,当SparkApplication执行完成之后,数据目录中的数据不会被清除
优化:对哪个RDD进行checkpoint,最好先cache下,这样回溯完成后再计算这个CheckpointRDD数据的时候可以直接在内存中拿到放指定的目录中
cache和persist的注意
1.cache,persist,checkpoint 都是懒执行,最小持久化单位是partition
2.cache和persist之后可以直接赋值给一个值,下次直接使用这个值,就是使用的持久化的数据
3.如果采用第二种方式,后面不能紧跟action算子
4.cache和persist的数据,当application执行完成之后会自动清除
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
官方解释:driver-memory可以设置driver最大堆内存
driver作用:
1)创建spark的上下文
2)划分RDD并生成有向无环图(DAGScheduler)
3)与spark中的其他组进行协调,协调资源等等(SchedulerBackend)
4)生成并发送task到executor(taskScheduler)
调优:
1) executor_cores*num_executors 不宜太小或太大!一般不超过总队列 cores 的 25%,比如队列总 cores 400,最大不要超过100,最小不建议低于 40,除非日志量很小。
2) executor_cores 不宜为1!否则 work 进程中线程数过少,一般 2~4 为宜。
3) executor_memory 一般 6~10g 为宜,最大不超过 20G,否则会导致 GC 代价过高,或资源浪费严重。
4) spark_parallelism 一般为 executor_cores*num_executors 的 1~4 倍,系统默认值 64,不设置的话会导致 task 很多的时候被分批串行执行,或大量 cores 空闲,资源浪费严重。
5) driver-memory 早前有同学设置 20G,其实 driver 不做任何计算和存储,只是下发任务与yarn资源管理器和task交互,除非你是 spark-shell,否则一般 1-2g 就够了。
博客来源:https://www.jianshu.com/p/b3d87df219e9
2.说到forEachPartition入库操作,就得顺带一提序列化陷阱。
使用forEachPartition对每个分区的数据进行存储操作,传入forEachPartition匿名类的所有参数对象都必须序列化,dataSource是一定传不了的,还想着少建立与数据库连接,此时为空指针,需要在匿名类内创建。还有日志也是打印不了的,可以传递些字符串或者自定义序列化过的bean等。
3.提高Spark并行度
①设置参数:
spark.default.parallelism=60 (应该为总executor-cores的2~3倍,官方推荐)
spark.sql.shuffle.partitions = 60
只有在shuffle操作之后生效;
②如果数据在HDFS上,增大block;
③如果数据是在关系数据库上,增加加载并行度,应该是有四种方式增大并行度;
④RDD.repartition,给RDD重新设置partition的数量;
⑤reduceByKey的算子指定partition的数量;
val rdd2 = rdd1.reduceByKey(_+_,10)
⑥val rdd3 = rdd1.join(rdd2) rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量。
参考博客:https://www.cnblogs.com/haozhengfei/p/e19171de913caf91228d9b432d0eeefb.html
4.hdfs错误
Caused by: java.io.IOException: Filesystem closed
原因:多个datanode在getFileSystem过程中,由于Configuration一样,会得到同一个FileSystem。如果有一个datanode在使用完关闭连接,其它的datanode在访问就会出现上述异常
解决办法:
在hdfs core-site.xml里把fs.hdfs.impl.disable.cache设置为true
5.dataFrame.write().mode("overwrite").text(hdfspath);
org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 6 columns.;
dataFrame只能保存一列数据,如果仍需要保存多列数据,则将多列数据合并成一列,再保存;
或者转换为RDD再保存:
dataFrame.toJavaRDD().saveAsTextFile(hdfsPath);
6.DataFrame超过200列(>200columns)无法缓存,超过8117列无法计算。
来源:https://issues.apache.org/jira/browse/SPARK-16664
https://blog.csdn.net/qq_40954793/article/details/83624195
http://127.0.0.1/layuimini/index.html#/page/welcome-2.html
npm i echarts echarts-liquidfill
+ echarts-liquidfill@3.1.0
+ echarts@5.2.1
npm ls echarts
npm ls echarts-liquidfill
React 代码的书写格式和以前的 JS 有很大的不同,下面通过对这段代码进行分析了解一下他。
以前使用 JavaScript 定义一个变量使用 var,ES6 加入了 const 关键字,用来定义一个常量:
现在,我们已经成功地使用 Router、Route 和 Link 实现了React页面跳转的功能.
-g:全局安装。 将会安装在C:\ Users \ Administrator \ AppData \ Roaming \ npm,并且写入系统环境变量;非全局安装:将会安装在当前定位目录;全局安装可以通过命令行任何地方调用它,本地安装将安装在定位目录的node_modules文件夹下,通过要求调用;
-S:即npm install module_name --save,写入package.json的dependencies ,dependencies 是需要发布到生产环境的,比如jq,vue全家桶,ele-ui等ui框架这些项目运行时必须使用到的插件就需要放到dependencies
-D:即npm install module_name --save-dev,写入package.json的devDependencies ,devDependencies 里面的插件只用于开发环境,不用于生产环境。比如一些babel编译功能的插件、webpack打包插件就是开发时候的需要,真正程序打包跑起来并不需要的一些插件。
-s {query}
后输入"关键词 要搜索的文件名"即可调出eveything在整个电脑上搜索文件(支持模糊匹配),除此之外还可以结合everything的过滤参数来实现定向搜索;如果需要在当前文件夹搜索的话,将参数换为
-s " """%path%""" {query} "
注:在当前目录搜索就需要用到上面说的第二种唤起方式。
如果需要搜索图片,将参数换为
-s pdf:{query}
Listary自带常用的一些Web搜索,比如bd + xxx就是百度搜索xxx,gg + xxx就是谷歌搜索xxx等,而通过分析URL可以加入自己常用的网址搜索,比如谷歌翻译英译中的URL是https://translate.google.cn/#view=home&op=translate&sl=auto&tl=zh-CN&text=,在后面接入xxx就是把英文xxx翻译为中文。对应Listaty可如此配置
英-中
https://translate.google.cn/#view=home&op=translate&sl=auto&tl=zh-CN&text={query}
中-英
https://translate.google.cn/#view=home&op=translate&sl=auto&tl=en&text={query}
输入"fy xxx"即自动打开谷歌翻译将xxx英译中
而b站的搜索为https://search.bilibili.com/all?keyword=,与之类似的可配置为
输入"bili xxx"即可自动打开B站网页搜索xxx
分析出URL变量便可以自定义Web的更多使用,当然也可以不需要参数直接打开特定网页,直接在URL输入对应网址即可
https://search.bilibili.com/all?keyword={query}
bk | 百度百科 | https://baike.baidu.com/item/{query}
wj | 维基百科 | https://zh.wikipedia.org/wiki/{query}
cd | 字典词典 | https://www.zdic.net/hans/{query}
zh | 知乎 | https://www.zhihu.com/search?type=content&q={query}
db | 豆瓣电影信息 | https://movie.douban.com/subject_search?search_text={query}
wp | 网盘搜索 | https://www.xalssy.com.cn/search/kw{query}
pdd | 盘多多搜索 | http://nduoduo.net/s/name/{query}
zz | 种子磁力搜索 | http://zhongzijidiso.xyz/list/{query}/1/0/0/
yk | 优酷 | https://so.youku.com/search_video/q_{query}
Iqy | 爱奇艺 | https://so.iqiyi.com/so/q_{query}
tx | 腾讯 | https://v.qq.com/x/search/?q={query}
eb 电子书URL:http://cn.epubee.com/books/?s={query}
wk | 百度文库 | https://wenku.baidu.com/search?word={query}
lm | 绿色软件 | http://www.xdowns.com/search.php?ac=search&keyword={query}
app | 安卓软件 | http://www.appchina.com/sou/?keyword={query}
repEnergyDysDF.describe("year" ).show()
这个方法可以动态的传入一个或多个String类型的字段名,结果仍然为DataFrame对象,用于统计数值类型字段的统计值,比如count, mean, stddev, min, max等。
这里列出的四个方法比较类似,其中
(1)first获取第一行记录
(2)head获取第一行记录,head(n: Int)获取前n行记录
(3)take(n: Int)获取前n行数据
(4)takeAsList(n: Int)获取前n行数据,并以List的形式展现
以Row或者Array[Row]的形式返回一行或多行数据。first和head功能相同。
take和takeAsList方法会将获得到的数据返回到Driver端,所以,使用这两个方法时需要注意数据量,以免Driver发生OutOfMemoryError
jdbcDF .where("id = 1 or c1 = 'b'" ).show()
jdbcDF .filter("id = 1 or c1 = 'b'" ).show()
还有一个重载的select方法,不是传入String类型参数,而是传入Column类型参数。可以实现select id, id+1 from test这种逻辑。
jdbcDF.select(jdbcDF( "id" ), jdbcDF( "id") + 1 ).show( false)
能得到Column类型的方法是apply以及col方法,一般用apply方法更简便。
jdbcDF .selectExpr("id" , "c3 as time" , "round(c4)" ).show(false)
val idCol1 = jdbcDF.apply("id")
val idCol2 = jdbcDF("id")
返回一个新的DataFrame对象,其中不包含去除的字段,一次只能去除一个字段。
jdbcDF.drop("id")
jdbcDF.drop(jdbcDF("id"))
jdbcDF.limit(3).show( false)
limit方法获取指定DataFrame的前n行记录,得到一个新的DataFrame对象。和take与head不同的是,limit方法不是Action操作。
(1)orderBy和sort:按指定字段排序,默认为升序
示例1,按指定字段排序。加个-表示降序排序。sort和orderBy使用方法相同
jdbcDF.orderBy(- jdbcDF("c4")).show(false)
// 或者
jdbcDF.orderBy(jdbcDF("c4").desc).show(false)
示例2,按字段字符串升序排序
jdbcDF.orderBy("c4").show(false)
jdbcDF .groupBy("c1" )
jdbcDF.groupBy( jdbcDF( "c1"))
(2)cube和rollup:group by的扩展
功能类似于SQL中的group by cube/rollup,略。
(3)GroupedData对象
该方法得到的是GroupedData类型对象,在GroupedData的API中提供了group by之后的操作,比如,
max(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最大值,只能作用于数字型字段
min(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的最小值,只能作用于数字型字段
mean(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的平均值,只能作用于数字型字段
sum(colNames: String*)方法,获取分组中指定字段或者所有的数字类型字段的和值,只能作用于数字型字段
count()方法,获取分组中的元素个数
stat方法可以用于计算指定字段或指定字段之间的统计信息,比如方差,协方差等。这个方法返回一个DataFramesStatFunctions类型对象。
下面代码演示根据c4字段,统计该字段值出现频率在30%以上的内容。在jdbcDF中字段c1的内容为"a, b, a, c, d, b"。其中a和b出现的频率为2 / 6,大于0.3
jdbcDF.stat.freqItems(Seq ("c1") , 0.3).show()
jdbcDF.explode( "c3" , "c3_" ){time: String => time.split( " " )}
-- 删除库
drop database if exists db_name;
-- 强制删除库
drop database if exists db_name cascade;
-- 删除表
drop table if exists employee;
-- 清空表
truncate table employee;
-- 清空表,第二种方式
insert overwrite table employee select * from employee where 1=0;
-- 删除分区
alter table employee_table drop partition (stat_year_month>='2018-01');
-- 按条件删除数据
insert overwrite table employee_table select * from employee_table where id>'180203a15f';
提交应用时,会将$SPARK_HOME/jars下的所有jar包打成一个zip包,上传到集群中。
“打zip上传”这个操作会在每次提交应用时执行,会有一点的性能损耗。
spark提供了spark.yarn.archive和spark.yarn.jars两个参数。可以将spark运行时需要的jar包缓存在HDFS上,无需每次运行任务的时候都进行分发。
如spark.yarn.archive=hdfs://cdh1/spark-jar.zip,直接从对应路径读取spark运行时需要的包。
yarn提供的jar包
在yarn-site.xml中会配置yarn.application.classpath,包含hadoop相关的一些包
<property>
<name>yarn.application.classpath</name>
<value> $HADOOP_CLIENT_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*
</value>
</property>
这些包也会在应用提交的时候被加载。
通过参数指定的jar包
提供了以下4个相关参数:
spark.executor.extraClassPath显式地将jar包注册到executor的classpath中
spark.driver.extraClassPath与executor配置项同理
spark.driver.userClassPathFirst=true
spark.executor.userClassPathFirst=true
通过extraClassPath指定jar包的方式和之前通过--jars差不多,只不过extraClassPath可以通过指定目录的方式来指定,如/cdh1/jars/*。
还有一点重要的是:extraClassPath可以通过配置userClassPathFirst来保证用户指定的jar包先被加载,这在解决冲突时是作用很大的。
————————————————
版权声明:本文为CSDN博主「upupfeng」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ifenggege/article/details/108164554
on Yarn的俩种模式
Yarn的俩种模式:一种为 client;一种为 cluster,可以通过- -deploy-mode 进行指定,也可以直接在 - -master 后面使用 yarn-client和yarn-cluster进行指定
俩种模式的区别:在于driver端启动在本地(client),还是在Yarn集群内部的AM中(cluster)
————————————————
版权声明:本文为CSDN博主「banana`」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Realoyou/article/details/80398424
Spark应用程序第三方jar文件依赖解决方案
第一种方式
操作:将第三方jar文件打包到最终形成的spark应用程序jar文件中
应用场景:第三方jar文件比较小,应用的地方比较少
第二种方式
操作:使用spark-submit提交命令的参数: --jars
要求:
1、使用spark-submit命令的机器上存在对应的jar文件
2、至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(例如:http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
1
2
3
## 配置参数:--jars JARS
如下示例:
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar
应用场景:要求本地必须要有对应的jar文件
第三种方式
操作:使用spark-submit提交命令的参数: --packages
复制代码
## 配置参数:--packages jar包的maven地址
如下示例:
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
## --repositories 为mysql-connector-java包的maven地址,若不给定,则会使用该机器安装的maven默认源中下载
## 若依赖多个包,则重复上述jar包写法,中间以逗号分隔
## 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中
复制代码
应用场景:本地可以没有,集群中服务需要该包的的时候,都是从给定的maven地址,直接下载
第四种方式
操作:更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
注意事项:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
复制代码
A.创建一个保存第三方jar文件的文件夹:
命令:$ mkdir external_jars
B.修改Spark配置信息
命令:$ vim conf/spark-env.sh
修改内容:SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
C.将依赖的jar文件copy到新建的文件夹中
命令:$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
复制代码
应用场景:依赖的jar包特别多,写命令方式比较繁琐,被依赖包应用的场景也多的情况下
备注:(只针对spark on yarn(cluster)模式)
spark on yarn(cluster),如果应用依赖第三方jar文件
最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
./spark-shell --master local[2] --jars C:\Users\admin\.m2\repository\mysql\mysql-connector-java\5.1.34\mysql-connector-java-5.1.34.jar
spark-shell --master yarn --deploy-mode client
spark-shell --master yarn --deploy-mode client --jars /usr/lib/hive/lib/mysql-connector-java-5.1.46.jar
--jars /app/mysql-connector-java-5.1.46.jar
sqlContext.sql("show databases")
spark.sql("show databases").show
spark.sql("show tables").show
select * from hs_spin.ext_wide_host_increment
sqlContext.sql("select * from hs_spin.ext_wide_host_increment limit 10").show()
sqlContext.sql("show databases").show
scala>val conf=new SparkConf().setAppName("SparkHive").setMaster("local") //可忽略,已经自动创建了
scala>val sc=new SparkContext(conf) //可忽略,已经自动创建了
scala>val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
scala>sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ")//这里需要注意数据的间隔符
scala>sqlContext.sql("LOAD DATA INPATH '/user/spark/src.txt' INTO TABLE src ");
scala>sqlContext.sql(" SELECT * FROM src").collect().foreach(println)
scala>sc.stop()
注意:使用,insert...select 往表中导入数据时,查询的字段个数必须和目标的字段个数相同,不能多,也不能少,否则会报错。但是如果字段的类型不一致的话,则会使用null值填充,不会报错。而使用load data形式往hive表中装载数据时,则不会检查。如果字段多了则会丢弃,少了则会null值填充。同样如果字段类型不一致,也是使用null值填充。
5.动态分区表的属性
使用动态分区表必须配置的参数 :
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能
set hive.exec.dynamic.partition.mode = nonstrict(默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段
动态分区相关的调优参数:
set hive.exec.max.dynamic.partitions.pernode=100 (默认100,一般可以设置大一点,比如1000)
表示每个maper或reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。
set hive.exec.max.dynamic.partitions =1000(默认值)
表示一个动态分区语句可以创建的最大动态分区个数,超出报错
set hive.exec.max.created.files =10000(默认) 全局可以创建的最大文件个数,超出报错。
在shell脚本中,需设置的参数:
set hive.exec.dynamic.partition=true; #开启动态分区,默认是false
set hive.exec.dynamic.partition.mode=nostrict; #开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
set hive.exec.max.created.files=1000000; #允许创建的最大文件数,当分区是2个或三个分区时,文件会被分成很多小文件,该设置就是将文件的最大数目设成100w;
/opt/spark/spark-2.1.1-bin-hadoop2.6/bin/spark-submit --class com.hangshu.test.TestToHive --master yarn --deploy-mode cluster /tmp/test/dataAnalys-1.0.jar
/opt/spark/spark-2.1.1-bin-hadoop2.6/bin/spark-submit --class com.hangshu.test.TestToHive --master yarn --deploy-mode client /tmp/test/dataAnalys-1.0.jar
spark-sql --master spark://node01:7077 --executor-memory 1g --total-executor-cores 2
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse
./spark-sql --master spark://L1:7077,L2:7077 --driver-class-path /home/hadoop/local-jars/mysql-connector-java-5.1.6.jar -e 'show tables;'
./spark-sql --master spark://L1:7077,L2:7077 --driver-class-path /home/hadoop/local-jars/mysql-connector-java-5.1.6.jar -f hive-sqls.sql
spark-shell --master spark://s101:7077 --jars /home/centos/fastjson-1.2.47.jar
/opt/spark/spark-2.1.1-bin-hadoop2.6/bin/spark-submit --class com.hangshu.test.TestToHive --master yarn --deploy-mode client \
--jars /opt/spark/spark-2.1.1-bin-hadoop2.6/jars/spark-catalyst_2.11-2.1.1.jar /tmp/test/dataAnalys-1.0.jar
/opt/spark/spark-2.1.1-bin-hadoop2.6/bin/spark-submit --class com.hangshu.test.TestToHive --master yarn --deploy-mode client /tmp/test/dataAnalys-1.0.jar
/opt/spark/spark-2.1.1-bin-hadoop2.6/bin/spark-submit --class com.hangshu.test.TestToHive --master local /tmp/test/dataAnalys-1.0.jar
spark-submit --class com.WordCount --master local /usr/local/spark/bin/spark-test-1.0-SNAPSHOT.jar
/tmp/test/dataAnalys-1.0.jar
org.apache.spark.sql.SparkSession
coalesce语法:
coalesce (expr_1, expr_2, …,expr_n),遇到非NULL值返回,如果没有非NULL值出现返回NULL
nvl语法:
NVL(expr_1, expr_2),如果expr_1为NULL,则返回expr_2,否则返回expr_1
ifnull语法:
ifnull(expr_1, expr_2),如果expr_1为NULL,则返回expr_2,否则返回expr_1
注:非NULL值为NULL,如果是'',' ','null','NULL'这些值一样返回它本身
nvl与ifnull相类似
例如:
spark-sql> select coalesce('NULL',2,1);
NULL
Time taken: 0.184 seconds, Fetched 1 row(s)
Spark SQL兼容Hive过程中,可以看出Spark SQL的整体架构中,已经预留出了不同数据源的扩展接口,不同数据源在适配过程中需要针对ExternalCatalog、BaseSessionStateBuilder、Analyzer和SparkPlanner做独立的数据源适配即可。
————————————————
版权声明:本文为CSDN博主「代码不会写」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/junerli/article/details/78654208
新建标签
Git 使用的标签有两种类型:轻量级的(lightweight)和含附注的(annotated)。
轻量级标签就像是个不会变化的分支,实际上它就是个指向特定提交对象的引用。
而含附注标签,实际上是存储在仓库中的一个独立对象,它有自身的校验和信息,包含着标签的名字,电子邮件地址和日期,以及标签说明,标签本身也允许使用 GNU Privacy Guard (GPG) 来签署或验证。
一般我们都建议使用含附注型的标签,以便保留相关信息;
当然,如果只是临时性加注标签,或者不需要旁注额外信息,用轻量级标签也没问题。
2 创建标签
[root@Git git]# git tag v1.0
3 查看已有标签
[root@Git git]# git tag
v1.0
[root@Git git]# git tag v1.1
[root@Git git]# git tag
v1.0
v1.1
4 删除标签
[root@Git git]# git tag -d v1.1
Deleted tag ‘v1.1’ (was 91388f0)
[root@Git git]# git tag
v1.0
5 查看此版本所修改的内容
[root@Git git]# git show v1.0
commit 91388f0883903ac9014e006611944f6688170ef4
Author: "syaving" <"819044347@qq.com">
Date: Fri Dec 16 02:32:05 2016 +0800
commit dir
diff –git a/readme b/readme
index 7a3d711..bfecb47 100644
— a/readme
+++ b/readme
@@ -1,2 +1,3 @@
text
hello git
+use commit
[root@Git git]# git log –oneline
91388f0 commit dir
e435fe8 add readme
2525062 add readme
从计算引擎上来看,三者都是SparkRDD计算引擎。从计算性能上来看,其实不会差非常多,都是取决于SparkRDD计算引擎。
Spark-SQL更多是开发Code中进行计算任务比较多,同时Saprk-SQL可以持久化到库表中方便第二次使用。
Hive on Spark,常规的数仓查询任务的,对外接口服务之类的。因为Hadoop生态群中的WEBUI界面非常丰富,所以直接通过HiveSQL查询将会非常方便。
Spark on Hive,使用Spark作为开发架构的,Hive作为数仓存储的场景中使用。
git tag -a v1.0.0
git log --decorate
git tag -a v0.9 85fc7e7
git log --oneline --decorate --graph
git tag
git tag -a <tagname> -m "runoob.com标签"
git tag -s <tagname> -m "runoob.com标签"
git tag -d v1.1
git show v1.0.0
version 1.0.0 done!
git tag -a v1.0.0 -m "version 1.0.0 done!"
git tag -d v1.0.0
git tag -a v1.10.3 -m "PC版本V1.10.3和小程序版本V1.0.35发布!"
SA的职位,全称为SystemAdministrator,中文翻译为“系统管理员”
RD一般指后端工程师
RD,即Research & Development,研发的意思,一般指研发工程师。
命令行界面(CLI) = 使用文本命令进行交互的用户界面
终端(Terminal) =TTY= 文本输入/输出环境
控制台(Console) = 一种特殊的终端
AssignerWithPeriodicWatermarks 周期性的生成watermark,生成间隔可配置,根据数据的eventTime来更新watermark时间
AssignerWithPunctuatedWatermarks 不会周期性生成watermark,只根据元素的eventTime来更新watermark。
当用EventTime和ProcessTime来计算时,元素本身都是不带时间戳的,只有以IngestionTime计算时才会打上进入系统的时间戳。
AssignerWithPunctuatedWatermarks(可以理解为每条数据都会产生水印,如果不想产生水印,返回一个null的水印)
AssignerWithPeriodicWatermarks(周期性的生成水印)
docker run -p 8080:8080 -p 50000:50000 -v jenkins_data:/var/jenkins_home jenkinsci/blueocean
docker exec -it 7f485bd95c3b /bin/bash 进入jenkins容器
cat /var/jenkins_home/secrets/initialAdminPassword
Maven Integration
Jenkins启动成功之后执行shll脚本
#!/bin/bash
#服务名称
SERVER_NAME=springboot
# 源jar路径,mvn打包完成之后,target目录下的jar包名称,也可选择成为war包,war包可移动到Tomcat的webapps目录下运行,这里使用jar包,用java -jar 命令执行
JAR_NAME=springboot-0.0.1-SNAPSHOT
# 源jar路径
#/usr/local/jenkins_home/workspace--->jenkins 工作目录
#demo 项目目录
#target 打包生成jar包的目录
JAR_PATH=/var/jenkins_home/workspace/springboot/target
# 打包完成之后,把jar包移动到运行jar包的目录--->work_daemon,work_daemon这个目录需要自己提前创建
JAR_WORK_PATH=/var/jenkins_home/workspace/springboot/target
echo "查询进程id-->$SERVER_NAME"
PID=`ps -ef | grep "$SERVER_NAME" | awk '{print $2}'`
echo "得到进程ID:$PID"
echo "结束进程"
for id in $PID
do
kill -9 $id
echo "killed $id"
done
echo "结束进程完成"
#复制jar包到执行目录
echo "复制jar包到执行目录:cp $JAR_PATH/$JAR_NAME.jar $JAR_WORK_PATH"
cp $JAR_PATH/$JAR_NAME.jar $JAR_WORK_PATH
echo "复制jar包完成"
cd $JAR_WORK_PATH
#修改文件权限
chmod 755 $JAR_NAME.jar
Nohub java -jar $JAR_NAME.jar
加nohub 指的是后台运行,或者使用nohub &
容器映射8081端口
1. 重启容器
systemctl restart docker
2. 清空未运行的容器
docker rm $(sudo docker ps -a -q)
docker run -p 8080:8080 -p 8081:8081 -p 50000:50000 -v jenkins_data:/var/jenkins_home jenkinsci/blueocean
docker export f299f501774c > hangger_server.tar
docker import - new_hangger_server < hangger_server.tar
docker save 0fdf2b4c26d3 > hangge_server.tar
docker save -o images.tar postgres:9.6 mongo:3.4
docker load < hangge_server.tar
特别注意:两种方法不可混用。
如果使用 import 导入 save 产生的文件,虽然导入不提示错误,但是启动容器时会提示失败,会出现类似"docker: Error response from daemon: Container command not found or does not exist"的错误。
1,文件大小不同
export 导出的镜像文件体积小于 save 保存的镜像
2,是否可以对镜像重命名
docker import 可以为镜像指定新名称
docker load 不能对载入的镜像重命名
3,是否可以同时将多个镜像打包到一个文件中
docker export 不支持
docker save 支持
4,是否包含镜像历史
export 导出(import 导入)是根据容器拿到的镜像,再导入时会丢失镜像所有的历史记录和元数据信息(即仅保存容器当时的快照状态),所以无法进行回滚操作。
而 save 保存(load 加载)的镜像,没有丢失镜像的历史,可以回滚到之前的层(layer)。
5,应用场景不同
docker export 的应用场景:主要用来制作基础镜像,比如我们从一个 ubuntu 镜像启动一个容器,然后安装一些软件和进行一些设置后,使用 docker export 保存为一个基础镜像。然后,把这个镜像分发给其他人使用,比如作为基础的开发环境。
docker save 的应用场景:如果我们的应用是使用 docker-compose.yml 编排的多个镜像组合,但我们要部署的客户服务器并不能连外网。这时就可以使用 docker save 将用到的镜像打个包,然后拷贝到客户服务器上使用 docker load 载入。
Docker load 之后镜像名字为none问题解决
例如,使用镜像ID打包的话导致解压的出来的镜像没有名字
docker save -o redis.tar 7864316753
因此,推荐使用镜像的名字进行打包,例如:
docker save -o redis.tar redis:5.0.2
此方式打包的镜像,解压出来就有镜像名称了
另外,附上重命名镜像的方法:
docker tag [镜像id] [新镜像名称]:[新镜像标签]
JVM的GC垃圾收集器
| 新生代GC策略 | 年老代GC策略 | 说明 | |
|---|---|---|---|
| 组合1 | Serial | Serial Old | Serial和Serial Old都是单线程进行GC,特点就是GC时暂停所有应用线程。 |
| 组合2 | Serial | CMS+Serial Old | CMS(Concurrent Mark Sweep)是并发GC,实现GC线程和应用线程并发工作,不需要暂停所有应用线程。另外,当CMS进行GC失败时,会自动使用Serial Old策略进行GC。 |
| 组合3 | ParNew | CMS | 使用-XX:+UseParNewGC选项来开启。ParNew是Serial的并行版本,可以指定GC线程数,默认GC线程数为CPU的数量。可以使用-XX:ParallelGCThreads选项指定GC的线程数。如果指定了选项-XX:+UseConcMarkSweepGC选项,则新生代默认使用ParNew GC策略。 |
| 组合4 | ParNew | Serial Old | 使用-XX:+UseParNewGC选项来开启。新生代使用ParNew GC策略,年老代默认使用Serial Old GC策略。 |
| 组合5 | Parallel Scavenge | Serial Old | Parallel Scavenge策略主要是关注一个可控的吞吐量:应用程序运行时间 / (应用程序运行时间 + GC时间),可见这会使得CPU的利用率尽可能的高,适用于后台持久运行的应用程序,而不适用于交互较多的应用程序。 |
| 组合6 | Parallel Scavenge | Parallel Old | Parallel Old是Serial Old的并行版本 |
| 组合7 | G1GC | G1GC | -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC #开启 -XX:MaxGCPauseMillis =50 #暂停时间目标 -XX:GCPauseIntervalMillis =200 #暂停间隔目标 -XX:+G1YoungGenSize=512m #年轻代大小 -XX:SurvivorRatio=6 #幸存区比例 |
| 目录/文件 | 说明 |
|---|---|
| build | 项目构建(webpack)相关代码 |
| config | 配置目录,包括端口号等。我们初学可以使用默认的。 |
| node_modules | npm 加载的项目依赖模块 |
| src | 这里是我们要开发的目录,基本上要做的事情都在这个目录里。里面包含了几个目录及文件:assets: 放置一些图片,如logo等。components: 目录里面放了一个组件文件,可以不用。App.vue: 项目入口文件,我们也可以直接将组件写这里,而不使用 components 目录。main.js: 项目的核心文件。 |
| static | 静态资源目录,如图片、字体等。 |
| test | 初始测试目录,可删除 |
| .xxxx文件 | 这些是一些配置文件,包括语法配置,git配置等。 |
| index.html | 首页入口文件,你可以添加一些 meta 信息或统计代码啥的。 |
| package.json | 项目配置文件。 |
| README.md | 项目的说明文档,markdown 格式 |
19.3 探索2-url
https://blog.csdn.net/lijingjingchn/category_8637886.html
https://blog.csdn.net/weixin_42348333/article/details/81747459
https://blog.csdn.net/yuanhaiwn/article/details/82781459
http://wuchong.me/blog/2018/11/09/flink-tech-evolution-introduction/
http://hbasefly.com/2016/10/29/hbase-regionserver-recovering/
https://www.ibm.com/blogs/china/?lnk=hpmls_bure_cnzh&lnk2=learn
https://www.cnblogs.com/smartloli/p/6685106.html
https://www.iteblog.com/archives/2417.html
https://segmentfault.com/a/1190000008129552
https://developer.aliyun.com/article/448900
https://www.cnblogs.com/qingyunzong/p/8692430.html
https://blog.csdn.net/lijingjingchn/article/details/83009002
https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html
https://www.jianshu.com/p/ab09eb36b32a
https://www.cnblogs.com/smartloli/p/9249259.html
https://blog.csdn.net/lijingjingchn/article/details/85289923
https://www.cnblogs.com/felixzh/p/9698073.html
https://www.jianshu.com/p/cddadb8b59c5
https://cloud.tencent.com/developer/article/1336562
https://blog.csdn.net/qq_35488412/article/details/78708493
https://blog.csdn.net/u012102306/article/details/51637366
https://blog.csdn.net/qq_21383435/article/details/82659947
http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-configurations-fair-scheduler/
https://blog.csdn.net/lijingjingchn/article/details/83012039
https://www.cnblogs.com/xing901022
https://www.cnblogs.com/tovin/p/3833985.html
https://www.jianshu.com/p/15cd9844c5a1
https://www.cnblogs.com/30go/p/8482854.html
https://www.cnblogs.com/tovin/p/4024733.html
https://www.cnblogs.com/zhengbin/p/5654805.html
-- 02
https://blog.csdn.net/yuexianchang/category_11166180.html
https://www.cnblogs.com/30go/archive/2021/10.html
https://www.cnblogs.com/tufujie/p/9413852.html
https://www.cnblogs.com/chenqionghe/p/10494868.html
https://www.cnblogs.com/xing901022/p/13975267.html
https://www.cnblogs.com/xing901022/p/13455513.html
https://mp.weixin.qq.com/s?__biz=MzU1NjY0NTQxNw==&mid=2247484245&idx=1&sn=08c08c3954eedaca4061d35c13ca6f9a&chksm=fbc0ae13ccb727051a330ff2227c047394f54453df22c4b42804eccbb67081f7a703468e26f5&scene=21#wechat_redirect
https://blog.csdn.net/u012102306/category_6266992.html?spm=1001.2014.3001.5482
https://cloud.tencent.com/developer/article/1337396?from=article.detail.1336631
https://www.cnblogs.com/smartloli/p/5560897.html
https://www.cnblogs.com/smartloli/p/14193432.html
https://www.cnblogs.com/smartloli/p/15334590.html
https://databricks.com/blog/category/engineering
https://www.cnblogs.com/qingyunzong/category/1202252.html
https://www.cnblogs.com/qingyunzong/p/8978661.html
https://www.cnblogs.com/qingyunzong/p/8973892.html
https://www.cnblogs.com/qingyunzong/p/8973857.html
https://www.cnblogs.com/qingyunzong/p/8973748.html
https://www.cnblogs.com/qingyunzong/p/8946679.html
https://www.cnblogs.com/qingyunzong/p/8946637.html
https://www.cnblogs.com/qingyunzong/p/8890483.html
https://echarts.apache.org/zh/download.html
https://www.cnblogs.com/xinhuaxuan/p/9256763.html
https://www.cnblogs.com/yifanSJ/p/9389903.html
https://www.cnblogs.com/tommyli/p/3338798.html
https://blog.csdn.net/qq_40954793/article/details/83624195
https://www.cnblogs.com/zhangruisoldier/p/8006099.html
https://www.cnblogs.com/tyblwmbs/p/10811631.html
https://www.cnblogs.com/carsonwuu/p/12402603.html
https://www.cnblogs.com/carsonwuu/p/11362107.html
https://www.cnblogs.com/carsonwuu/p/11352169.html
https://www.cnblogs.com/xjh713/p/7309426.html
https://www.jianshu.com/p/b3d87df219e9
https://www.cnblogs.com/carsonwuu/p/11207083.html
https://zhuanlan.zhihu.com/p/25353670?group_id=827655855632715776
https://www.cnblogs.com/chenrongping/p/6599795.html
https://www.cnblogs.com/xm0328/p/14066820.html
https://blog.csdn.net/lildkdkdkjf/article/details/107079486
https://www.cnblogs.com/penghq/p/10694197.html
https://www.cnblogs.com/awkflf11/p/9412344.html
https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
https://blog.csdn.net/wang_wbq/article/details/80231895
https://blog.csdn.net/naorenteng/article/details/108040387
https://www.cnblogs.com/yjyyjy/p/12869636.html
https://www.programcreek.com/scala/org.apache.spark.SparkFunSuite
https://www.programcreek.com/scala/?code=cisco%2Foraf%2Foraf-master%2Fsrc%2Ftest%2Fscala%2Forg%2Fapache%2Fspark%2Fml%2Ftree%2Fimpl%2FOptimizedDecisionTreeIntegrationSuite.scala
https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/hive/HiveExternalCatalog.html
https://www.cnblogs.com/share23/p/9768308.html
http://dblab.xmu.edu.cn/blog/1086-2/
https://zhuanlan.zhihu.com/p/113213420
https://www.cnblogs.com/guoleidd/p/12891542.html
https://gitee.com/ejlchina-zhxu/bean-searcher/tree/master/bean-searcher-demos/spring-boot-demo
https://searcher.ejlchina.com/
https://cloud.tencent.com/document/product/240/7092
https://www.cnblogs.com/weifeng1463/p/12034701.html
https://www.cnblogs.com/JetpropelledSnake/p/15089886.html
https://www.cnblogs.com/xinsen/p/10588767.html
https://cloud.tencent.com/developer/article/1708294
https://www.cnblogs.com/ronnieyuan/p/12580729.html
--03
https://cloud.tencent.com/developer/article/1708294
https://www.cnblogs.com/ronnieyuan/p/12580729.html
https://www.cnblogs.com/ronnieyuan/category/1580125.html
http://www.dockone.io/article/522
http://blog.yufeng.info/archives/tag/ulimit
chrome-extension://ibllepbpahcoppkjjllbabhnigcbffpi/http://images.linoxide.com/systemd-vs-sysVinit-cheatsheet.pdf
https://cloud.tencent.com/developer/news/304629
https://www.docker.com/blog/announcing-docker-enterprise-3-0-ga/
http://dockone.io/article/302
https://www.cnblogs.com/hanfan/p/12866994.html
https://blog.csdn.net/qq_38830964/article/details/114276328
https://clickhouse.com/docs/zh/getting-started/tutorial/#download-and-extract-table-data
https://www.cnblogs.com/traditional/p/15218693.html
https://blog.51cto.com/wujianwei/3034589
https://www.cnblogs.com/ming-blogs/p/10903408.html
https://my.oschina.net/piaoxianren/blog/4270893
https://www.cnblogs.com/Springmoon-venn/p/12544251.html
https://blog.csdn.net/zhaocuit/article/details/107122379
https://www.cnblogs.com/qingyunzong/p/8877140.html
https://www.cnblogs.com/yangxusun9/p/14473640.html
https://www.cnblogs.com/zhaoyanhaoBlog/p/11889627.html
https://www.cnblogs.com/ywjfx/p/14263718.html
https://blog.csdn.net/qq_37334150/article/details/113876408
https://nightlies.apache.org/flink/flink-docs-release-1.12/dev/table/streaming/dynamic_tables.html
https://blog.csdn.net/qq_43791724/article/details/121120063
https://www.cnblogs.com/Springmoon-venn/p/11403665.html
https://www.cnblogs.com/Springmoon-venn/p/11445023.html
https://blog.csdn.net/FBB360JAVA/article/details/103452748
https://blog.csdn.net/wudonglianga/article/details/121594858
https://blog.csdn.net/qqhjqs/category_9284317.html
https://www.cnblogs.com/cnblogszs/p/12796532.html
https://www.cnblogs.com/itlz/p/14327179.html
https://zhuanlan.zhihu.com/p/106697938
https://www.cnblogs.com/brian-sun/p/14372777.html
https://blog.csdn.net/love20991314/article/details/121474676
https://www.cnblogs.com/yyy-blog/p/11819302.html
https://www.pianshen.com/article/931538256/
https://www.cnblogs.com/wh984763176/p/13399538.html
https://www.cnblogs.com/jj1106/p/13171893.html
https://blog.csdn.net/weixin_34242509/article/details/87993541
https://www.cnblogs.com/lemon-le/p/8476626.html
19.4 docker命令
docker system df
docker system df -v
1.images的SIZE是磁盘大小,SHARED SIZE,是共享大小,CONTAINERS是启动容器的个数,如果是0就代表是没有使用的镜像。
2.Containers的size是修改层大小。
3.volume 的SIZE是所占空间大小,像"Mounts": bind这种挂载空间是没有计算在内的
docker system df --verbose
#镜像空间使用情况
docker system prune --help
docker system prune --all
docker system events
cat <<END> delel-image
#!/bin/bash
#删除过期镜像,保留最新5个版本
CDATE=`date '+%Y-%m-%d_%H:%M:%S'`
#######比如经常发版的关键字是"rabbitmq"
for service in `docker images | grep 'rabbitmq' | awk '{print $1}' |sort -u`
do
for i in `docker images | grep $service | awk '{print $2}' | awk -F"-" '{print $1}' | sort -u`
do
banben=`docker images | grep $service | awk '{print $2}'`
mem=`docker images | grep $service | awk '{print $2}' |wc -l`
done
#echo $banben
#echo $mem
if [[ $mem -gt 3 ]];then
arr=(${banben// /})
#保留同样类型的5个镜像
for(( j=3;j<${#arr[@]};j++)) do
docker rmi $service:${arr[j]}
#echo $service:${arr[j]}
echo "docker rmi $service:${arr[j]} 执行时间:$CDATE" >> /home/log_delete_images.log
done
fi
done
END
portainer
docker search portainer
docker pull portainer/portainer
docker pull 6053537/portainer-ce
docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock --name portainer --restart always portainer/portainer
docker run -d --name portainerUI -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock portainer/portainer
docker run -d --name portainerUI -p 9001:9000 -v /var/run/docker.sock:/var/run/docker.sock 6053537/portainer-ce
http://cwflink:9000/
admin/JwLwx@01529
http://cwflink:9001/
192.168.40.128
C:\Windows\System32\drivers\etc
删除所有已退出的容器
docker rm $(docker ps -q -f status=exited)
删除所有已停止的容器
docker rm $(docker ps -a -q)
删除所有正在运行和已停止的容器
docker stop $(docker ps -a -q)
docker rm $(docker ps -a -q)
删除所有容器,没有任何标准
docker container rm $(docker container ps -aq)
但是,在1.13及更高版本中,对于完整的系统和清理,我们可以直接使用以下命令,
docker system prune
所有未使用的容器,图像,网络和卷都将被删除。另外,单我们可以使用以下命令来清理组件:
docker container prune
docker image prune
docker network prune
docker volume prune

 浙公网安备 33010602011771号
浙公网安备 33010602011771号